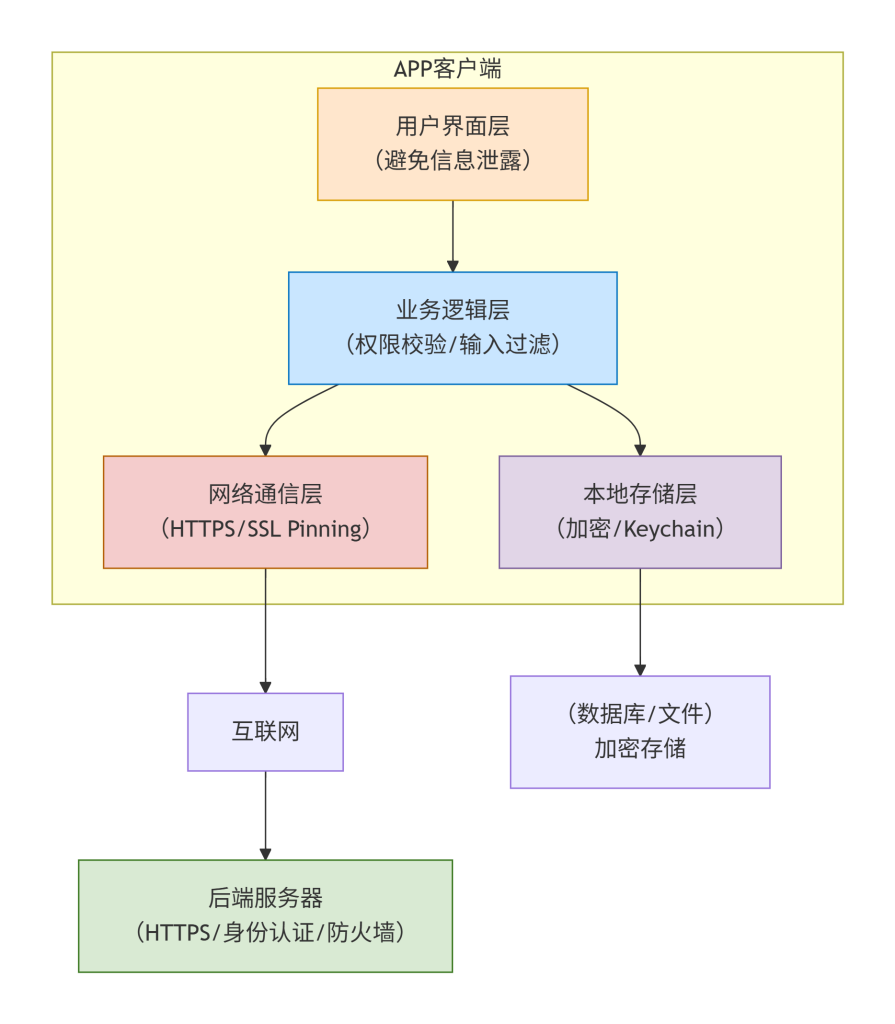
信息收集-Web应用-架构分析&指纹识别
一、网络技术栈认知重构
1.1 模块概念解释
网络技术栈认知重构,是从信息收集角度重新梳理 Web 应用(Web Application)所依赖的技术组件及其在交互过程中呈现信息的方式。其目的在于帮助工程师理解典型 Web 应用的技术层次构成、各层次特征暴露位置,以及这些特征为何可用于识别。该模块解决“识别什么”和“信息从哪来”的问题,为后续技术指纹识别建立基础认知框架。
1.2 技术原理说明
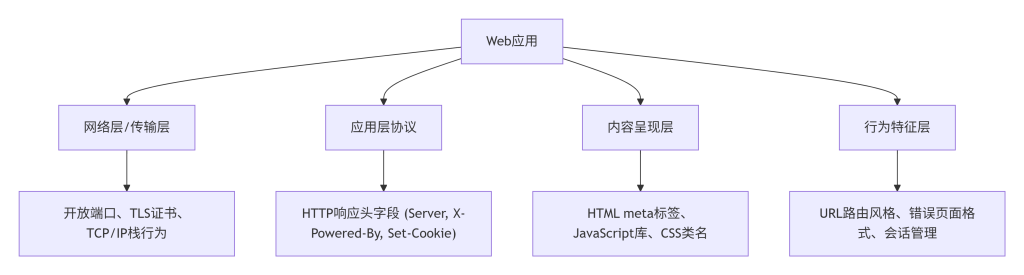
Web 应用基于 TCP/IP 协议栈(TCP/IP Protocol Stack),上层使用 HTTP/HTTPS 协议通信。客户端请求时,服务器响应中包含由不同技术组件生成的信息:
- 网络层与传输层:开放端口、TLS 证书、TCP/IP 协议栈行为可反映操作系统、中间件类型。
- 应用层协议:HTTP 响应头中的
Server、X-Powered-By、Set-Cookie等字段直接暴露 Web 服务器、后端语言、应用框架信息。 - 内容呈现层:HTML 文档中的
<meta>标签、JavaScript 库特征、CSS 类名、特定注释等可揭示前端框架、CMS、第三方服务。 - 行为特征层:URL 路由风格、错误页面格式、会话管理方式等隐含技术信息。
该设计初衷是便于调试和兼容性,但也为技术识别提供了数据来源。理解信息产生原理,才能有目的地采集分析。【补充说明:HTTP 响应头的定义和行为参考 HTTP/1.1 标准(IETF RFC 9110)】
图1-1:Web技术栈层次与信息暴露示意图
1.3 在系统中的位置
本模块作为 Web 应用架构分析的起点,不直接进行数据采集,而是构建对 Web 技术栈的整体认知框架。后续模块“探查目标与任务确立”将基于此模型设定具体目标,“应用架构层次拆解”则细化各层次识别点。因此,本模块位于最前端,为后续步骤提供理论支撑。
1.4 可执行命令或查询方式
以安全测试目标 example.com 和 httpbin.org 为例,演示查看技术信息的命令:
# 查看HTTP响应头,重点关注Server、X-Powered-By等字段
curl -I https://example.com
# 查看完整HTTP响应,包括头部和主体(主体包含HTML特征)
curl -s https://httpbin.org/ | head -n 20
# 使用浏览器开发者工具(F12)的“网络”标签,刷新页面查看请求/响应详情
# 使用openssl获取TLS证书信息,可能暴露服务器软件
openssl s_client -connect example.com:443 -servername example.com 2>/dev/null | openssl x509 -text | grep -E "Subject:|Issuer:|DNS:"【补充说明:curl -I 发送 HEAD 请求获取头部,curl -s 启用静默模式。openssl s_client 测试 SSL/TLS 连接,管道至 openssl x509 -text 解析并输出证书详细信息。依据:curl man page;OpenSSL Documentation。】
1.5 工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| 浏览器开发者工具 | 手工快速分析前端特征 | 图形化、实时查看DOM、网络请求、Cookie | 难以自动化,不适合批量处理 |
| curl | 命令行获取原始响应 | 轻量、脚本化、可定制请求头 | 需手动解析输出,对JavaScript渲染内容无效 |
| wget | 下载整个页面或递归分析 | 可递归获取资源,支持镜像 | 功能偏重下载,特征提取需额外处理,与curl定位不同 |
| openssl | 获取TLS证书细节 | 能发现Web服务器类型、证书发行者 | 仅适用于HTTPS站点,信息有限 |
1.6 标准操作步骤
- 打开目标站点:在浏览器中访问
http://httpbin.org。 - 打开开发者工具:按F12,切换到“网络(Network)”标签,刷新页面。
- 查看响应头:点击第一个请求(通常为文档本身),在“响应头(Response Headers)”部分记录
server、access-control-allow-origin等字段。 - 查看页面源码:右键查看页面源代码,搜索
<meta、<script>等标签,寻找框架标识(如csrf-token、_ga)。 - 使用 curl 获取头信息:在终端执行
curl -I https://httpbin.org,对比与浏览器中看到的信息。 - 整理观察信息:列出可能的技术组件(如 gunicorn、Python、某些 JavaScript 库)。
1.7 如何验证结果真实性
验证逻辑:对于公开测试站点,可通过查阅官方文档或已知技术栈进行比对。例如,httpbin.org 官方文档说明其基于 Python + Gunicorn。若响应头中出现 server: gunicorn/19.9.0,且响应体包含 Python 风格输出,则可确认观察结果与真实技术栈一致。
判断依据:多个独立来源(响应头、页面内容、TLS 证书)指向同一技术时,真实性高。若出现矛盾(如声称 Apache 但页面包含 IIS 注释),需进一步分析。
1.8 常见错误与排查方式
- 错误1:仅依赖
Server头判断技术栈。Server头可被修改或隐藏,且只反映 Web 服务器,不反映后端语言或框架。 - 排查:结合其他特征,如 Cookie 名(
PHPSESSID暗示 PHP,JSESSIONID暗示 Java)、URL 后缀(.php、.asp)。 - 错误2:将 CDN 或代理特征误认为源站特征。例如,
Server: cloudflare表示使用 CloudFlare CDN,并非真实源站。 - 排查:尝试直接连接源站 IP(需先通过 DNS 解析或历史数据获得),或使用非标准端口绕过代理。
- 错误3:忽略动态渲染内容。某些单页应用(SPA)初始 HTML 中几乎无特征,需分析 JavaScript 加载后的 DOM。
- 排查:使用浏览器开发者工具的元素面板查看最终渲染后的 DOM 树,或使用 Headless 浏览器(如 Puppeteer)获取动态内容。
1.9 合规边界说明
- 使用场景:仅用于对自有系统、已获授权的测试目标或公开测试站点(如
example.com、httpbin.org)进行学习研究。 - 网络安全视角:
- 风险:未经授权对目标进行探查可能违反法律法规或服务条款。即使仅使用
curl,也可能被日志记录并视为扫描行为。 - 局限:仅凭外部信息无法完全确定技术栈,可能存在误判,需结合内部文档或授权测试进一步验证。
- 缓解措施:始终在授权范围内操作,使用测试域名或本地环境;遵守
robots.txt;设置合理请求频率,避免对目标造成压力。 - 本模块决策指南:
- 适用场景:需要初步了解一个授权目标的技术构成,以规划深入测试时。
- 替代方案:若已拥有目标的技术文档或代码权限,则无需通过外部探查。
1.10 本模块阶段性小结
本模块完成了对 Web 应用技术层次的认知重构,明确了各层次可能暴露的信息源。理解外部服务通过协议、内容、行为透露技术组成,是后续探查动作的基础。下一模块将正式确立探查目标,将认知转化为具体任务清单。
二、探查目标与任务确立
2.1 模块概念解释
探查目标与任务确立,是指在技术信息收集前,明确从目标 Web 应用中获取的具体技术信息,并将这些信息组织为可操作的任务。其解决“需要得到什么”的问题,例如确定 Web 服务器类型、后端编程语言、前端框架、数据库类型、中间件版本等。确立任务后,后续拆解和方法建模才能有的放矢。
2.2 技术原理说明
探查任务确立基于一个核心逻辑:目标对外提供服务时需遵循公开协议(如 HTTP),而协议实现细节因技术栈不同存在差异。通过设计特定查询(如发送特定 HTTP 请求、探测特定端口、分析特定响应模式)可推断内部技术构成。这一过程类似黑盒测试,从有限外部响应中最大程度还原内部构造。设计探查任务时需考虑:
- 信息类型:静态信息(响应头、HTML)和动态信息(特定路径响应、错误信息)。
- 探查深度:从端口开放到应用层细节,分层递进。
- 任务优先级:信息获取难易度不同,需设定优先级。
图2-1:探查目标确立流程图
2.3 在系统中的位置
在完成技术栈理论认知后,本模块将理论转化为具体目标。它为接下来的“应用架构层次拆解”提供待拆解的维度(前端、后端、数据库等),并为“组件识别方法建模”定义需要识别的组件列表。因此,本模块起到承上启下作用,将认知转化为实际任务。
2.4 可执行命令或查询方式
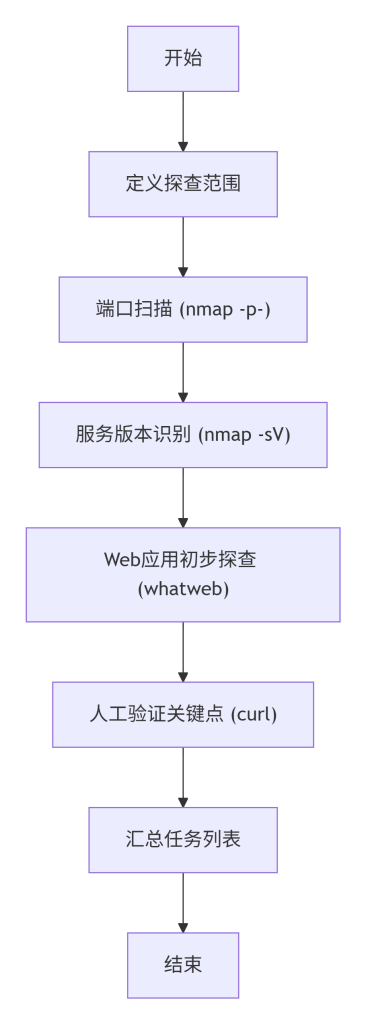
以安全测试目标 scanme.nmap.org 和 httpbin.org 为例,展示确立探查目标并执行初步扫描的命令:
# 端口扫描,确定开放服务(为后续应用层探查准备)
nmap -p- --min-rate 1000 scanme.nmap.org
# 服务版本探测,获取更详细的服务信息
nmap -sV -p 80,443 scanme.nmap.org
# HTTP服务指纹探测,使用whatweb进行综合识别
whatweb http://scanme.nmap.org
# 检查特定路径是否存在(如/robots.txt,/phpinfo.php)
curl -I http://scanme.nmap.org/robots.txt【补充说明:nmap -p- 扫描 1-65535 所有 TCP 端口,--min-rate 1000 控制发包速率不低于 1000 包/秒。-sV 用于版本探测。whatweb 是 Web 指纹识别工具。依据:Nmap Reference Guide;Whatweb GitHub Repository。】
2.5 工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| nmap | 端口扫描与服务版本识别 | 功能强大、社区支持好、脚本丰富 | 扫描速度较慢(全端口),可能被IDS检测 |
| masscan | 大规模端口扫描 | 极速,适合互联网范围扫描 | 结果可能不准确,功能单一 |
| whatweb | Web应用指纹识别 | 识别准确,插件丰富,可定制 | 仅针对Web服务,不涉及底层网络 |
| telnet/netcat | 手动探测服务 Banner | 简单直接,可用于验证 | 需人工交互,不适合批量 |
2.6 标准操作步骤
按照图2-1的探查目标确立流程,各步骤具体命令如下:
- 定义探查范围:确定目标域名(如
scanme.nmap.org)和 IP(如有)。 - 端口扫描:
nmap -p- scanme.nmap.org - 服务版本识别:
nmap -sV -p 80,443 scanme.nmap.org - Web应用初步探查:
whatweb http://scanme.nmap.org - 人工验证关键点:使用 curl 访问常见路径,如
curl -I http://scanme.nmap.org/robots.txt - 汇总任务列表:根据初步探查结果,列出需要深入确认的组件(例如:观察到 Apache/2.4.7,需进一步确认 PHP 版本)。
2.7 如何验证结果真实性
验证逻辑:对于测试目标 scanme.nmap.org,可查阅 Nmap 官方文档或论坛,了解其已知配置。实际上,scanme.nmap.org 运行 Apache 和一些基本服务。对比 nmap 版本探测结果与已知信息,若一致则说明探查有效。对于其他目标,可使用多个工具交叉验证,例如 whatweb 和 nmap 的 http-server-info 脚本结果应相互印证。
判断依据:若多个工具均报告同一版本信息,且人工检查响应头也能看到类似字段,则真实性较高。若出现不一致,需检查网络中间设备(如负载均衡)是否干扰响应。
2.8 常见错误与排查方式
- 错误1:忽略非标准端口上的 Web 服务,如 8080、8443 可能运行另一套 Web 应用。
- 排查:对所有开放端口尝试 HTTP 请求,使用 nmap 的
-sV自动识别,或脚本批量连接测试。 - 错误2:过度依赖自动化工具,错过重要细节。例如 whatweb 可能无法识别某些定制化框架。
- 排查:结合手动分析,使用浏览器访问,查看源代码,寻找自定义标识。
- 错误3:将负载均衡或反向代理标识误认为真实后端。例如
Server: nginx可能是反向代理,真实后端为 Apache。 - 排查:尝试访问不存在路径,观察 404 错误页面特征;或使用 HTTP/1.0、不同 Host 头绕开代理(在授权范围内)。
2.9 合规边界说明
- 使用场景:本模块涉及的端口扫描和服务探测仅适用于已获明确授权的系统,或使用公共测试目标(如
scanme.nmap.org)。 - 网络安全视角:端口扫描在某些地区被视为攻击前兆,可能触发法律纠纷。即使对
scanme.nmap.org,也应遵守其使用条款(通常允许扫描)。nmap 版本探测基于已知签名,对定制化服务可能失效,产生误报。 - 缓解措施:始终从授权目标开始;设置扫描速率限制(
--max-rate);使用更隐蔽的扫描方式(如-sS半连接扫描)以减少日志记录,但需确保在授权范围内。 - 本模块决策指南:
- 适用场景:需要系统性地了解一个未知 Web 应用的技术构成,且已获授权时。
- 替代方案:若目标已提供技术文档,则无需主动扫描,可直接进入组件识别验证阶段。
2.10 本模块阶段性小结
本模块明确了要从目标 Web 应用中收集的技术信息,并通过端口扫描和初步指纹识别获得初步清单。该清单成为后续深入拆解和分析的输入。下一模块将把清单映射到具体应用架构层次上,以便有条理地进行识别。
三、应用架构层次拆解
3.1 模块概念解释
应用架构层次拆解,是指将完整 Web 应用按技术职能划分为若干层次,例如前端层、后端层、数据层、中间件层、操作系统层,并针对每一层分析可能暴露的特征信息。其解决“如何系统化组织识别任务”的问题,避免零散收集特征而遗漏重要组件。通过层次化拆解,可确保覆盖所有可能的技术组件,并理解各层之间的依赖关系。
3.2 技术原理说明
现代 Web 应用普遍采用分层架构,每一层承担不同职责,且通常由不同技术实现:
- 前端层(客户端):负责用户界面与交互,包括 HTML/CSS/JavaScript 框架(如 React、Vue、Angular)、UI 库、静态资源服务器等。特征出现在 HTML 结构、JavaScript 变量、CSS 类名、Source Map 等。
- 后端层(服务器端):处理业务逻辑,包括编程语言(PHP、Java、Python、Node.js 等)、Web 框架(Django、Spring、Rails 等)、应用服务器(Tomcat、uWSGI 等)。特征出现在响应头(如
X-Powered-By)、Cookie(如JSESSIONID)、URL 路由模式、错误页面等。 - 数据层:存储和管理数据,包括数据库系统(MySQL、PostgreSQL、MongoDB 等)、缓存系统(Redis、Memcached)、搜索引擎(Elasticsearch)。特征可能通过 SQL 错误信息、特定端口暴露、API 响应格式等泄露。
- 中间件层:提供通用服务,包括 Web 服务器(Nginx、Apache)、消息队列(RabbitMQ)、反向代理/负载均衡(HAProxy)。特征出现在
Server头、响应头添加字段(如Via)、特定 HTTP 行为。 - 操作系统层:底层系统环境(Linux、Windows)。特征可通过 TTL 值、TCP/IP 栈行为、TLS 指纹、文件路径风格(Windows 反斜杠 vs Linux 正斜杠)等推断。
每一层的技术选择都会在交互过程中留下痕迹,层次拆解就是将痕迹归类,以便后续针对性地建立识别规则。
图3-1:应用架构层次拆解图

3.3 在系统中的位置
在确定探查目标清单后,本模块将清单中的每一项技术归类到相应架构层次,形成层次化的“待识别项”列表。这为后续“组件识别方法建模”提供了清晰维度:需要为每一层设计识别方法。因此,本模块是任务分解的关键步骤。
3.4 可执行命令或查询方式
以 httpbin.org 为例,演示从各层次提取特征的命令:
# 前端层:查看页面源码中的JavaScript库和框架特征
curl -s https://httpbin.org | grep -i "script\|library\|framework"
# 后端层:查看响应头,寻找后端语言标记
curl -I https://httpbin.org | grep -i "x-powered-by\|server"
# 数据层:尝试触发数据库错误(仅限授权测试),例如通过注入特殊字符,但此处仅做概念演示
# 对httpbin.org的特定端点发送非法参数,观察错误响应
curl -s "https://httpbin.org/get?param='"
# 中间件层:查看Server头和Via头
curl -I https://httpbin.org | grep -i "server\|via"
# 操作系统层:通过TTL值推测(使用ping)
ping -c 1 httpbin.org | grep ttl【补充说明:ping 命令的 TTL 值可作为推断操作系统的参考之一,Linux 默认起始 TTL 通常为 64,Windows 为 128。依据:Linux ping man page。】
3.5 工具对比表
| 工具 | 适用层次 | 优点 | 局限 |
|---|---|---|---|
| curl | 前端/后端/中间件 | 通用性强,可获取原始数据 | 需人工解析特征 |
| 浏览器开发者工具 | 前端 | 可视化查看DOM、网络请求、控制台 | 不易自动化 |
| nmap脚本(如http-headers, http-title) | 后端/中间件 | 自动化提取常见信息 | 脚本覆盖面有限 |
| wappalyzer浏览器插件 | 全层次 | 一键识别,集成度高 | 依赖浏览器,可能漏报 |
| whatweb | 全层次 | 命令行工具,插件丰富 | 部分识别需更新指纹库 |
3.6 标准操作步骤
- 收集原始数据:使用 curl 获取目标首页的完整响应头和响应体,保存为文件。
- 前端层分析:
- 查看 HTML 头部,寻找
<meta name="generator"等标签。 - 搜索
<script>标签,提取 src 属性中的库名(如jquery.min.js、vue.js)。 - 查看 DOM 结构中的
data-属性或特定类名(如react-root)。
- 后端层分析:
- 查看响应头中的
Server、X-Powered-By、X-AspNet-Version等字段。 - 检查 Cookie,如
PHPSESSID、JSESSIONID、ASP.NET_SessionId。 - 访问常见的特定路径(如
.git、/.env)或扩展名(.php、.asp),观察响应。
- 数据层分析:
- 尝试输入特殊字符(如单引号)到参数中,观察是否返回数据库错误。
- 检查开放的端口(如 3306、27017)是否对外暴露。
- 中间件层分析:
- 查看
Server头细节,确定具体软件及版本。 - 检查
Via、X-Cache等头部,判断是否存在反向代理。
- 操作系统层分析:
- 使用
ping获取 TTL 值,初步判断系统(Windows TTL≈128,Linux≈64)。 - 分析错误页面中的路径分隔符(
\或/)。
- 汇总层次特征:将各层观察到的特征填入层次分析表。
3.7 如何验证结果真实性
验证逻辑:对于每一层识别出的特征,应寻找至少两个独立证据。例如,后端语言是 PHP 的证据包括:X-Powered-By: PHP/7.4、Cookie 中包含 PHPSESSID、URL 中出现 .php 后缀、错误页面显示 PHP 语法错误。如果只有单一证据,可能是误报(如 CDN 伪造的头部)。
判断依据:交叉验证各工具结果,并参考已知技术栈(如官方文档)。对于测试目标,可主动构建测试环境验证特征与技术的对应关系。
3.8 常见错误与排查方式
- 错误1:混淆前端框架与后端框架。例如,React 是前端框架,但服务端渲染也可能产生类似特征。
- 排查:检查特征出现上下文,是在 HTML 源码中(服务端输出)还是动态渲染(需执行 JS)。
- 错误2:忽略隐藏层,如使用了 API 网关,网关本身可能改变响应头。
- 排查:尝试直接连接后端 IP(需先获得授权和网络可达性)。
- 错误3:数据层识别过度依赖错误信息,但现代应用可能自定义错误页面,不暴露数据库细节。
- 排查:使用更高级的技术,如时间盲注(仅限于授权测试),或分析 API 响应的一致性。
3.9 合规边界说明
- 使用场景:仅适用于已授权测试或公开测试环境。主动触发错误信息可能违反服务条款,应谨慎。
- 网络安全视角:尝试 SQL 注入等行为即使是为了指纹识别,也可能被视为攻击,导致法律责任。通过错误信息推断数据库类型不一定准确,因为错误可能来自应用层而非数据库。
- 缓解措施:在授权范围内明确允许的测试方法;优先使用非侵入式方法(如分析端口、响应头);使用专门的教学环境(如 Damn Vulnerable Web Application)练习。
- 本模块决策指南:
- 适用场景:需要全面了解目标的技术架构,以便进行后续安全评估或兼容性测试时。
- 替代方案:若目标是内部系统,可直接查阅设计文档,无需通过外部探测。
3.10 本模块阶段性小结
应用架构层次拆解使工程师能系统审视 Web 应用的技术构成,将零散特征归类到前端、后端、数据、中间件、操作系统等层次,形成层次分明的识别任务。接下来,将针对每一层构建具体的组件识别方法,将特征转化为可匹配的规则。
四、组件识别方法建模
4.1 模块概念解释
组件识别方法建模,是指构建一套基于多源数据的、逻辑严谨的技术组件识别框架。其解决“如何准确从特征数据中识别出具体技术组件及其版本”的问题。该模型通常包含特征采集、特征提取、规则匹配、置信度评估等环节。建模的目的是使识别过程可重复、可扩展,并能处理模糊或冲突的信息。
4.2 技术原理说明
组件识别本质是模式匹配问题。每个技术组件(如 Apache、Nginx、Django)在运行时会产生一组独特的特征(指纹)。这些特征可表现为:
- 确定性特征:如响应头中的
Server: Apache/2.4.41,直接给出组件名和版本。 - 概率性特征:如 Cookie 名称
_ga通常与 Google Analytics 相关,但非 100% 确定。 - 复合特征:多个特征组合可显著提高准确性,例如同时匹配
X-Powered-By: PHP/7.4和PHPSESSID,则 PHP 的置信度极高。
识别方法建模的核心是建立特征库(指纹库),并设计匹配算法。常用方法有:
- 正则表达式匹配:对响应头、HTML 内容进行正则搜索。
- 关键字哈希:快速匹配常见组件名称。
- 版本提取算法:从特定位置提取版本号并进行范围判断。
- 机器学习分类:适用于特征复杂、不易手工定义规则的情况,但在 Web 指纹领域仍以规则为主。
模型设计需平衡准确率与召回率,避免规则过于宽泛(导致误报)或过于严格(导致漏报)。
图4-1:组件识别方法建模流程图
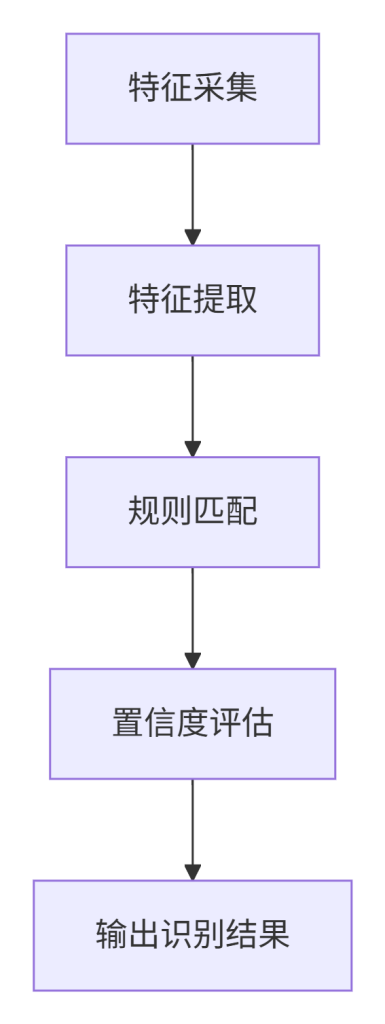
4.3 在系统中的位置
在层次拆解之后,需要为每一层的每个潜在组件建立识别规则。本模块构建这些规则,形成可执行的识别逻辑。后续的“信息采集流程制定”将利用这套逻辑对采集数据进行匹配。因此,本模块是整个指纹识别系统的核心引擎。
4.4 可执行命令或查询方式
演示如何编写简单指纹规则并使用脚本进行匹配(以 Python 为例,使用测试目标 httpbin.org):
# 1. 采集目标响应
curl -s -I -X GET https://httpbin.org > headers.txt
curl -s https://httpbin.org > body.txt
# 2. 使用grep模拟规则匹配(简单的正则)
# 匹配Server头包含gunicorn
grep -i "server: gunicorn" headers.txt
# 3. 编写简单Python脚本进行复合匹配 (fingerprint.py)# fingerprint.py 示例内容
import re
with open('headers.txt') as f:
headers = f.read().lower()
with open('body.txt') as f:
body = f.read().lower()
def check_fingerprint(component, rules):
score = 0
for rule in rules:
if re.search(rule, headers) or re.search(rule, body):
score += 1
return score
# 定义PHP指纹规则
php_rules = ['x-powered-by: php', 'phpsessid', r'\.php\b']
php_score = check_fingerprint('php', php_rules)
print(f'PHP 置信度: {php_score}/{len(php_rules)}')4.5 工具对比表
| 工具/方法 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| 手动编写正则 | 小规模定制化识别 | 灵活、可精细控制 | 维护成本高,需熟悉特征 |
| 开源指纹库(如 Wappalyzer apps.json) | 通用Web指纹识别 | 社区维护,覆盖广 | 不一定适配特定目标,更新滞后 |
| 专用指纹识别框架(如 Recog) | 需要结构化指纹管理 | 格式统一,易于扩展 | 学习曲线,需集成到现有流程 |
| 机器学习分类器 | 特征模糊、难以定义规则时 | 可自动学习特征 | 需大量标注数据,解释性差 |
4.6 标准操作步骤
按照图4-1的建模流程,各步骤具体操作如下:
- 确定待识别组件列表:根据层次拆解,列出可能存在的组件(如 Apache、Nginx、PHP、MySQL 等)。
- 收集组件指纹特征:
- 查阅官方文档、社区知识库、已有指纹库(如 Wappalyzer 的 apps.json)。
- 在测试环境中安装对应组件,观察其产生的特征。
- 收集公开的指纹数据(如来自 Netcraft、BuiltWith)。
- 设计特征规则:
- 每条规则应包含:组件名称、特征类型(header/html/cookie)、匹配模式(正则/字符串)、权重。
- 示例:
{ "name": "jQuery", "type": "script", "pattern": "jquery[-.]([\\d.]+)\\.js", "version_group": 1 }
- 实现匹配引擎:
- 编写脚本或使用现有工具,加载规则,对目标响应数据进行匹配。
- 支持组合规则,计算置信度。
- 测试与调优:
- 使用已知技术栈的测试目标验证规则准确性。
- 调整规则权重,减少误报/漏报。
- 文档化:记录每条规则的来源、测试结果、更新日期。
4.7 如何验证结果真实性
验证逻辑:针对每个识别出的组件,至少应有两条以上独立特征支持。例如,识别出 Nginx,特征可包括:Server: nginx、404 页面包含 nginx、特定错误号 413 Request Entity Too Large 的响应格式等。对于版本号,应检查是否存在版本提取特征,并与其他特征(如特定漏洞的响应)交叉验证。
判断依据:若仅有一条特征匹配,则标记为“待确认”;若两条及以上,则认定为高置信度。最终可通过人工验证或查阅文档确认。
4.8 常见错误与排查方式
- 错误1:规则过于宽泛,导致误报。例如,用
php匹配响应头中的PHP,但可能出现在注释中。 - 排查:限定匹配位置,例如只匹配响应头或特定 HTML 标签内;使用词边界
\b。 - 错误2:规则过于严格,导致漏报。例如,要求精确版本号,但目标可能自定义版本或隐藏。
- 排查:使用不包含版本号的通用规则作为备用,并设置置信度降级。
- 错误3:忽略特征的可伪造性。例如,
X-Powered-By可轻易修改或删除。 - 排查:不依赖可伪造特征,结合更隐蔽的特征(如特定 URL 路径、Cookie 生成算法)。
4.9 合规边界说明
- 使用场景:建模过程本身不涉及对目标的操作,属于知识构建。但采集指纹特征时,需访问测试环境或合法公开数据。
- 网络安全视角:若使用未经授权的第三方指纹库,可能存在版权或数据合规问题。任何规则库都无法覆盖所有可能的组件和版本,需持续更新。
- 缓解措施:使用开源、合规的数据源;建立自己的测试环境,避免依赖不可靠来源。
- 本模块决策指南:
- 适用场景:需要自动化识别大量目标,或需要保证识别结果可重复性时。
- 替代方案:若只是临时手动分析一两个目标,可直接使用现有工具(如 whatweb)而不自行建模。
4.10 本模块阶段性小结
组件识别方法建模将经验转化为可执行规则,是技术指纹识别走向工程化的关键一步。通过建立特征库和匹配算法,可系统化地从原始响应中提取技术信息。接下来,需制定完整的信息采集流程,将这些方法应用到实际数据采集中,实现从目标到识别结果的全过程。
五、信息采集流程制定
5.1 模块概念解释
信息采集流程制定,是指设计一套从目标 Web 应用中获取原始数据(如 HTTP 响应、端口信息、证书等)的系统化步骤,以便后续进行组件识别。其解决“如何高效、全面地获取用于指纹识别的数据”的问题。流程通常包括被动信息收集和主动信息收集两种方式,并考虑数据清洗、去重、存储等环节。
5.2 技术原理说明
信息采集可按与目标交互的程度分为两类:
- 被动信息收集:不直接向目标发送请求,而是通过第三方渠道获取信息。例如:
- 搜索引擎缓存(Google、Bing)
- 公开存档(Archive.org)
- 证书透明度日志(crt.sh)
- DNS 记录(DNSdumpster)
被动收集的优势是无痕、安全,但信息可能过时或不完整。 - 主动信息收集:直接向目标发送各类探测请求,获取实时响应。例如:
- 端口扫描
- HTTP 请求(各种方法、路径、参数)
- TLS 握手
主动收集能获得最新数据,但可能留下日志,且需注意请求频率。
流程制定需结合两种方式,先被动后主动,先广泛后精细,以减少对目标的影响并提高效率。
图5-1:信息采集流程图(被动+主动)
5.3 在系统中的位置
本模块位于方法建模之后,综合实践之前。它将前序构建的识别方法应用于实际数据获取,为最终的技术栈还原提供原始素材。同时,流程中定义的采集深度和广度将直接影响后续识别的完整性和准确性。
5.4 可执行命令或查询方式
以 example.com 和 scanme.nmap.org 为例,展示被动与主动采集的命令:
# 被动收集:查询证书透明度日志(使用curl调用crt.sh API)
curl -s "https://crt.sh/?q=%.example.com&output=json" | jq .
# 被动收集:查询DNS记录
dig example.com ANY +short
nslookup example.com
# 主动收集:HTTP基本请求(使用httpx批量探测常见路径)
echo "http://example.com" | httpx -paths /robots.txt -status-code -content-length
# 主动收集:使用nmap扫描端口
nmap -p 80,443,8080 scanme.nmap.org
# 主动收集:使用whatweb获取指纹
whatweb -a 3 http://scanme.nmap.org【补充说明:crt.sh 是证书透明度日志查询网站,提供公共 API。httpx 是多功能 HTTP 工具包,用于探活和路径探测。jq 用于处理 JSON 数据。依据:crt.sh 官方网站;httpx GitHub Repository;jq Manual。】
5.5 工具对比表
| 工具 | 采集类型 | 优点 | 局限 |
|---|---|---|---|
| crt.sh (curl) | 被动(证书) | 数据丰富,可发现子域名 | 需解析JSON,结果可能包含过期证书 |
| theHarvester | 被动(搜索引擎、PGP等) | 集成多种源,可获取邮箱、子域 | 依赖外部源可用性,可能被封 |
| dnsrecon | 被动/主动(DNS) | DNS枚举、区域传送检查 | 区域传送通常被禁止 |
| nmap | 主动(端口、服务) | 功能强大,脚本丰富 | 扫描时间长,易被发现 |
| httpx | 主动(HTTP探活) | 快速并发探测,支持多种协议 | 需先知道端口,可能漏掉非标准服务 |
| gau | 被动+主动(获取已知URL) | 从多个源收集历史URL | 输出可能包含大量噪声 |
5.6 标准操作步骤
按照图5-1的信息采集流程,各步骤具体操作如下:
- 确定采集目标:明确目标域名/IP 列表,并确认测试授权。
- 被动信息收集:
- 使用 crt.sh 查询目标域名证书,获取子域名列表:
curl -s "https://crt.sh/?q=%.example.com&output=json" | jq . - 使用搜索引擎搜索
site:example.com收集公开页面。 - 使用 theHarvester 等工具收集邮箱、子域等。
- 查询 DNS 记录(A、MX、TXT、NS 等):
dig example.com ANY +short
- 主动信息收集(基础层):
- 对目标 IP 进行端口扫描,识别开放端口及服务:
nmap -sV scanme.nmap.org - 对发现的 Web 端口进行 HTTP 探活,获取响应头与状态码:
httpx -path / -status-code
- 主动信息收集(应用层):
- 使用 httpx 或自定义脚本,对常见 Web 路径(如
/admin、/api、/backup)进行模糊测试(需注意频率):ffuf -u http://example.com/FUZZ -w wordlist.txt - 获取每个有效路径的完整响应(头+主体)。
- 获取 TLS 证书详细信息(若使用 HTTPS):
openssl s_client -connect example.com:443
- 数据清洗与存储:
- 去除重复响应,合并相同 URL 的数据。
- 将响应头、响应体、端口信息、证书信息等存入结构化存储(如 JSON 文件、数据库)。
- 数据质量检查:确保采集的数据覆盖所有预期层次,必要时补充采集。
5.7 如何验证结果真实性
验证逻辑:通过对比被动与主动数据的一致性,以及多源数据的交叉印证。例如,crt.sh 发现的子域名应能通过 DNS 解析并返回有效响应;端口扫描发现的 Web 服务应能通过 HTTP 请求验证。若某子域名在被动收集中存在但在主动探测中无响应,可能是已下线或需特殊端口。
判断依据:所有采集的数据应能复现。选取若干关键数据进行手工验证,确保工具采集无误。对于测试目标,可参考官方文档确认数据完整性。
5.8 常见错误与排查方式
- 错误1:被动收集依赖的外部源不稳定或返回过期数据。
- 排查:使用多个源交叉验证,并关注数据的时间戳。
- 错误2:主动收集时请求频率过高,触发目标防护机制(如 WAF 封 IP)或导致服务不稳定。
- 排查:设置合理的延迟(–delay),使用代理池轮换 IP(需授权),或降低并发。
- 错误3:数据存储混乱,丢失关联信息(如哪个响应对应哪个 URL)。
- 排查:建立明确的目录结构或数据库表,每条记录包含源 URL、时间戳、请求头等信息。
5.9 合规边界说明
- 使用场景:信息采集必须在授权范围内进行。对于公共测试目标,应遵守其条款(如 scanme.nmap.org 允许扫描)。
- 网络安全视角:主动收集可能被目标视为恶意扫描,导致 IP 被封甚至法律追责。即使是被动收集,过度使用 API 也可能违反服务条款。被动收集可能无法获得最新数据,主动收集可能被检测。
- 缓解措施:在授权合同中明确采集方法;使用测试专用目标;设置采集速率限制;优先使用被动方式。
- 本模块决策指南:
- 适用场景:需要获取最新、最全面的目标数据以进行后续分析时。
- 替代方案:若只需已知的少量信息,可直接使用浏览器访问,无需系统化采集。
5.10 本模块阶段性小结
信息采集流程制定将理论方法转化为实际操作,通过被动和主动结合的方式,系统化地获取目标多维度数据。这些数据将成为后续组件识别的输入。在正式执行采集前,必须先明确探查边界和风险控制策略,确保流程合法、安全。下一模块将重点讨论这些合规与风险问题。
六、探查边界与风险控制
6.1 模块概念解释
探查边界与风险控制,是指在执行技术探查前,界定哪些行为允许,哪些禁止,并采取相应措施降低对目标系统的负面影响和法律风险。其解决“如何确保探查行为合法、合规、安全”的问题。核心内容包括:获取授权、界定测试范围、设置扫描速率、识别误判风险、制定应急计划等。
6.2 技术原理说明
从技术层面,任何主动探测都会在目标系统留下痕迹,可能被日志记录、触发入侵检测系统、耗尽资源或导致服务异常。从法律层面,未经授权的扫描可能违反计算机安全法规(如中国的《网络安全法》、美国的 CFAA)。因此,风险控制需从技术和法律两个维度设计:
- 技术风险控制:
- 速率限制:控制请求频率,避免 DoS。
- 扫描策略:先轻量后深度,避免突发大量请求。
- 白名单机制:仅对授权 IP/域名进行测试。
- 法律风险控制:
- 书面授权:获取目标所有者明确的测试许可。
- 范围限定:在授权范围内操作,不得越界。
- 数据保护:对收集到的数据保密,不泄露敏感信息。
此外,还需考虑指纹识别本身的误判风险,避免将误判结果作为最终结论,造成后续决策失误。
图6-1:探查边界与风险控制流程
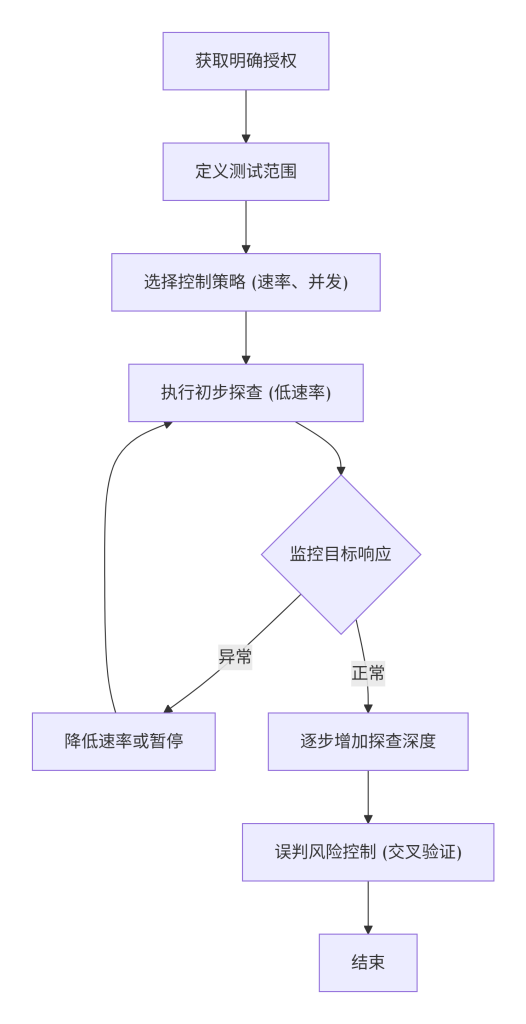
6.3 在系统中的位置
本模块位于信息采集流程之前,是任何实际探查活动的前置条件。它确保前序所有模块的理论和方法能在合法、安全的前提下应用于真实目标。同时,它也贯穿整个探查过程,需动态调整控制策略。
6.4 可执行命令或查询方式
展示如何在主动扫描中应用速率控制和范围限定(以 nmap 和 httpx 为例):
# nmap 速率控制:--max-rate 10 表示每秒最多发送10个包
nmap -p 80,443 --max-rate 10 scanme.nmap.org
# nmap 仅扫描指定IP,避免超出范围
nmap -iL target.txt --excludefile exclude.txt
# httpx 并发控制:-t 10 表示10个并发线程
echo "http://example.com" | httpx -t 10 -path / -status-code
# 使用--delay控制请求间隔(nmap可用,httpx不支持,可用ffuf代替)
ffuf -u http://example.com/FUZZ -w wordlist.txt -p 0.5 # 延迟0.5秒【补充说明:nmap 的 --max-rate 控制最大发包速率,--scan-delay 可控制请求间隔。ffuf 的 -p 参数用于设置请求延迟。依据:Nmap Reference Guide;ffuf GitHub Repository。】
6.5 工具对比表
| 控制项 | 工具/方法 | 优点 | 局限 |
|---|---|---|---|
| 速率限制 | nmap –max-rate, –min-rate | 精细控制发包速率 | 对某些扫描模式可能不适用 |
| 并发控制 | httpx -t, ffuf -t | 控制并发数,减轻目标压力 | 并发不等于速率,仍需结合延迟 |
| 请求间隔 | ffuf -p, nmap –scan-delay | 精确控制每个请求间隔 | 降低扫描速度 |
| 范围限定 | nmap -iL, –exclude | 明确指定目标,避免越界 | 需预先准备列表 |
| 授权记录 | 无命令,靠文档 | 法律依据 | 需人工维护 |
6.6 标准操作步骤
按照图6-1的风险控制流程,各步骤具体操作如下:
- 获取明确授权:
- 与目标所有者签订测试合同或获得书面许可,明确测试范围、时间、方法。
- 对于公共测试目标,确认其使用条款允许主动扫描。
- 定义测试范围:
- 确定允许测试的 IP 段、域名列表。
- 列出禁止测试的资产(如生产数据库、敏感接口)。
- 选择控制策略:
- 根据目标的重要性和网络环境,设定合理的请求速率(如每秒 10-50 个包)。
- 决定使用代理轮换或固定 IP(通常固定 IP 更易获得授权)。
- 执行初步探查:
- 先使用低速率、非侵入式方法(如 ping、traceroute)确认网络连通性。
- 再逐步增加探查深度,并持续监控目标响应状态。
- 监控与调整:
- 在扫描过程中观察目标是否出现异常(响应变慢、返回错误),如有则立即降低速率或暂停。
- 记录所有请求日志,便于事后审计。
- 误判风险控制:
- 对识别出的技术组件,使用多个工具或方法交叉验证。
- 对于不确定性高的结果,标记为“需人工确认”。
6.7 如何验证结果真实性
验证逻辑:风险控制的有效性可通过以下方式验证:
- 速率控制是否生效:检查扫描日志,确认请求间隔是否符合设定值。
- 是否越界:对比扫描目标列表与授权范围,确认无超出。
- 对目标影响:扫描前后对比目标服务的响应时间、可用性,无明显变化则控制有效。
判断依据:若扫描过程中未触发目标警报(如 WAF 拦截)、未导致服务不可用,且所有操作均在授权范围内,则风险控制成功。
6.8 常见错误与排查方式
- 错误1:认为获得授权后就无需速率控制。即使授权,过度扫描仍可能导致服务异常,损害信任。
- 排查:始终设定合理速率,并准备应急联系方式,以便出现问题时立即停止。
- 错误2:忽略第三方服务的影响。例如,使用了 CDN 的目标,扫描 CDN 节点不会影响源站,但可能触发 CDN 的 DDoS 防护。
- 排查:了解目标架构,针对源站 IP 进行扫描;或事先通知 CDN 服务商(如有可能)。
- 错误3:误判风险只关注技术层面,忽略法律层面。例如,收集到的数据可能包含个人隐私,存储不当会违规。
- 排查:对收集的数据进行脱敏处理,并遵守数据保护法规。
6.9 合规边界说明
- 使用场景:任何对非公开系统的主动探查都必须事先获得授权。本模块强调的边界控制仅适用于授权测试。
- 网络安全视角:即使有授权,也可能因操作失误导致越界访问。例如,解析出的子域名指向未授权 IP。授权本身不能完全免除责任,仍需遵循行业最佳实践。
- 缓解措施:在测试计划中明确“若发现超出范围的资产,立即停止并报告”。
- 本模块决策指南:
- 适用场景:所有涉及主动探查的活动开始前,必须进行边界与风险控制设计。
- 替代方案:若仅使用被动收集且不涉及任何主动请求,风险较小,但仍需注意数据合规。
6.10 本模块阶段性小结
探查边界与风险控制是专业安全工程师的必备素养。它不仅保护目标系统免受意外损害,也保护测试者自身免受法律风险。在明确风险控制措施后,可安全进入综合实践环节,将前序所有知识和流程整合起来,对一个授权目标进行完整的技术栈还原。
七、技术栈还原综合实践
7.1 模块概念解释
技术栈还原综合实践,是指将前六个模块的理论、方法和流程综合运用,对一个真实的授权测试目标进行端到端的技术栈逆向还原,并输出完整的分析报告。其解决“如何将碎片化的知识整合成完整的实战能力”的问题。通过本模块演练,工程师能熟练掌握从信息收集到技术识别的全过程。
7.2 技术原理说明
技术栈还原的核心原理是“多源信息融合”。单一来源信息可能存在误差或缺失,通过结合端口扫描、HTTP 响应分析、TLS 证书、DNS 记录、被动数据等多种数据源,并对同一组件进行多重验证,可最大程度还原真实情况。例如,要确定后端语言是 Python,可从以下证据中综合判断:
- 响应头
X-Powered-By: Python/3.8 - URL 路由风格为
/api/v1/resource(常见 RESTful 框架) - 错误页面包含
Django调试信息 - Cookie 包含
csrftoken - 某个特定路径返回 404 时,页面包含
<title>Page not found (404)</title>(Django 默认模板) - 被动收集中发现项目使用
pip的依赖文件泄露
综合实践就是运用这些线索,通过逻辑推理和工具辅助,形成高置信度的结论。
图7-1:技术栈还原综合实践流程图
7.3 在系统中的位置
本模块是整个课程体系的终点,将所有前置模块串联起来。它既是知识检验,也是技能训练。通过本模块,工程师将建立起完整的工程化思维,为后续渗透测试、安全开发或运维工作打下坚实基础。
7.4 可执行命令或查询方式
以授权测试目标 scanme.nmap.org 为例,演示综合实践中的关键命令(注意:实际使用时需确保授权):
# 1. 被动收集:查询证书日志
curl -s "https://crt.sh/?q=%.scanme.nmap.org&output=json" | jq .
# 2. DNS信息
dig scanme.nmap.org ANY +short
# 3. 端口扫描
nmap -p- --min-rate 1000 scanme.nmap.org
# 4. 服务版本探测
nmap -sV -p 80,9929,31337 scanme.nmap.org
# 5. Web指纹识别
whatweb -a 3 http://scanme.nmap.org
# 6. 深入HTTP分析
curl -I http://scanme.nmap.org
curl -s http://scanme.nmap.org | grep -i "meta\|script"
# 7. 目录枚举(低速率)
ffuf -u http://scanme.nmap.org/FUZZ -w /usr/share/wordlists/dirb/common.txt -p 0.2 -t 5
# 8. TLS证书获取(如果443开放)
openssl s_client -connect scanme.nmap.org:443 -servername scanme.nmap.org 2>/dev/null | openssl x509 -text【补充说明:nmap -p- 扫描所有端口,--min-rate 1000 设置最小发包速率。ffuf 的 -p 和 -t 分别控制延迟和并发。所有命令均应在授权范围内使用。依据:Nmap Reference Guide;ffuf GitHub Repository;crt.sh 官方网站。】
7.5 工具对比表
| 工具 | 应用阶段 | 作用 | 与其他工具的协作 |
|---|---|---|---|
| crt.sh | 被动收集 | 发现子域名 | 为端口扫描提供更多目标 |
| dig/nslookup | 被动收集 | 获取DNS记录 | 确认域名解析,辅助子域验证 |
| nmap | 主动收集 | 端口与服务探测 | 输出开放端口,为后续HTTP探测提供入口 |
| whatweb | 主动收集 | 初步Web指纹 | 快速获得概览,指导深入分析 |
| ffuf | 主动收集 | 目录/文件枚举 | 发现隐藏路径,可能暴露更多特征 |
| curl | 主动收集 | 手动验证 | 获取原始响应,用于规则匹配 |
| openssl | 主动收集 | TLS证书分析 | 获取服务器证书细节 |
7.6 标准操作步骤
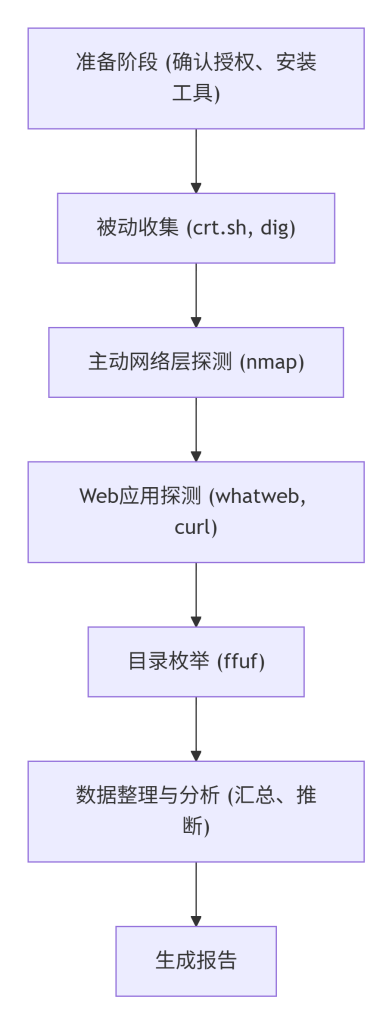
按照图7-1的综合实践流程,各步骤具体操作如下:
- 准备阶段:
- 确认目标
scanme.nmap.org的授权(查阅其官网,允许扫描)。 - 准备测试机环境,安装所需工具(nmap, whatweb, ffuf, curl, jq 等)。
- 创建项目目录,用于存储所有输出。
- 被动信息收集:
- 运行
curl -s "https://crt.sh/?q=%.scanme.nmap.org&output=json" | jq . > crt.json。 - 运行
dig scanme.nmap.org ANY +short > dns.txt。 - 分析输出,注意子域名(如
www.scanme.nmap.org)、CNAME、TXT 记录等。
- 主动网络层探测:
- 运行
nmap -p- --min-rate 1000 scanme.nmap.org -oN nmap_allports.txt。 - 查看结果,记录开放端口:22, 80, 9929, 31337 等。
- 对开放端口进行服务版本探测:
nmap -sV -p 22,80,9929,31337 scanme.nmap.org -oN nmap_versions.txt。
- Web应用探测:
- 对 80 端口运行
whatweb -a 3 http://scanme.nmap.org > whatweb.txt。 - 手动使用
curl -I http://scanme.nmap.org查看响应头。 - 使用
curl -s http://scanme.nmap.org | grep -i "meta\|script"提取关键内容。 - 对 443 端口(若开放)执行 TLS 分析:
openssl s_client -connect scanme.nmap.org:443 -servername scanme.nmap.org 2>/dev/null | openssl x509 -text > cert.txt。
- 目录枚举:
- 使用 ffuf 对 80 端口进行低速率目录枚举:
ffuf -u http://scanme.nmap.org/FUZZ -w /usr/share/wordlists/dirb/common.txt -p 0.2 -t 5 -o ffuf.json。 - 分析结果,注意状态码 200、403、301 的路径,并手动访问验证。
- 数据整理与分析:
- 将各工具输出汇总到一张表格中,按层次归类。
- 应用组件识别方法,对每个层次进行技术推断。
- 前端:查看 whatweb 是否识别出前端库。
- 后端:从响应头、错误页面推断(可能为 Apache 默认页面)。
- 操作系统:从 TTL(ping 得到 64)推断 Linux。
- 交叉验证:例如,nmap 报告 Apache 版本,whatweb 报告 Apache,响应头也显示 Apache,则一致。
- 生成报告:
- 编写报告,包含:目标信息、采集方法、各层次识别结果、置信度评估、证据截图/命令输出。
- 对不确定的组件进行说明,并给出建议(如需要内部确认)。
7.7 如何验证结果真实性
验证逻辑:对于 scanme.nmap.org,可查阅 Nmap 官方文档,确认其运行的服务。实际上,scanme.nmap.org 运行 Apache、SSH 及一些测试服务。将分析结果与公开信息对比,若基本一致,则验证成功。
判断依据:
- 各工具输出一致(如都报告 Apache/2.4.7)。
- 人工检查响应头、页面内容与 Apache 默认特征相符。
- 没有出现相互矛盾的证据。
7.8 常见错误与排查方式
- 错误1:忽略非标准端口上的服务。例如,端口 9929 可能运行 nping echo 服务,但并非 Web 服务。
- 排查:对所有端口进行协议识别,不假设 80/443 是唯一的 Web 端口。
- 错误2:过度依赖自动化工具,漏掉人工发现的细节。例如,ffuf 可能没找到隐藏目录,但手动查看 robots.txt 发现
/secret。 - 排查:在自动化后,务必进行人工抽查,特别是常见敏感路径。
- 错误3:未对结果进行交叉验证,导致误判。例如,若 CDN 返回了错误的
Server头。 - 排查:尝试直接连接 IP(若授权允许),或使用其他方法(如 HTTP/2 指纹)辅助判断。
7.9 合规边界说明
- 使用场景:本实践必须基于授权目标进行。
scanme.nmap.org明确允许扫描,是合法目标。 - 网络安全视角:即使目标允许扫描,大规模目录枚举仍可能被视为攻击,建议控制速率。综合实践可能无法 100% 还原所有技术细节,尤其是内部组件(如数据库类型)。
- 缓解措施:在报告中明确指出不确定性,并建议通过内部文档或授权深度测试进一步确认。
- 本模块决策指南:
- 适用场景:需要全面了解目标技术栈以进行安全评估或兼容性测试时,且已获授权。
- 替代方案:若目标已提供详细技术文档,则无需进行此综合实践。
7.10 本模块阶段性小结
通过技术栈还原综合实践,完整演练了从信息收集到技术识别的全过程,将前六个模块的知识融会贯通。工程师不仅学会操作工具,更重要的是掌握了系统化分析方法和风险控制意识。这种能力是从事 Web 安全、运维开发、架构设计等工作的重要基础。至此,整个“Web 应用架构分析与指纹识别”的工程化教学模块结束。
参考与进一步阅读
- curl man page:本文中所有
curl命令的语法和参数依据。该手册详细说明了-I、-s、-k等选项的用法。 - Nmap Reference Guide:本文中
nmap端口扫描、服务版本探测(-sV)、速率控制(--min-rate,--max-rate)等技术细节的来源。该指南由 Nmap 官方维护,涵盖了所有扫描技术和脚本用法。 - OpenSSL Documentation:本文中
openssl s_client和x509命令用于 TLS 证书获取和解析的依据。OpenSSL 官方文档提供了所有子命令和参数的完整说明。 - crt.sh Certificate Search:本文中被动收集证书信息所使用的
crt.sh在线服务。该网站提供了通过域名、指纹等查询证书透明日志的接口。 - ffuf – Fuzz Faster U Fool GitHub Repository:本文中目录枚举工具
ffuf的官方仓库,包含了-p(延迟)、-t(线程)等参数的详细说明和使用示例。 - Wappalyzer GitHub Repository:本文工具对比表中提到的 Wappalyzer 指纹识别工具的开源仓库,包含其指纹规则(
apps.json)的定义方式。 - Whatweb GitHub Repository:本文中使用的
whatweb指纹识别工具的官方仓库,提供了插件开发和使用的详细文档。 - httpx GitHub Repository:本文中用于 HTTP 探活的
httpx工具的官方仓库,说明了其多协议支持和并发控制机制。 - IETF RFC 9110 – HTTP Semantics:本文 1.2 节中关于 HTTP 响应头定义和行为的技术原理依据。该文档是当前 HTTP/1.1 和 HTTP/2 的语义标准。
- IETF RFC 1035 – Domain Names:本文 DNS 查询相关命令(
dig,nslookup)的底层协议标准,提供了域名系统实现的技术背景。
信息收集-Web应用-架构分析&WAF&蜜罐
认知基础重构
模块概念解释
信息收集初期,一个常见的思维陷阱是陷入点状思维,仅关注单个IP、端口或页面,而忽略了Web应用作为完整系统的整体架构。本模块旨在帮助您建立系统性的架构认知,深入理解Web应用中DNS、CDN、负载均衡、Web服务器、应用框架、数据库、缓存、WAF、蜜罐等核心组件间的交互逻辑。只有从全局视角出发,后续收集到的信息才能被正确关联和解读,避免因孤立的数据点而做出错误判断。
技术原理说明
Web应用在本质上是一个多层、多组件的分布式系统,其底层通信逻辑遵循一条完整的“请求-响应”链。防护设备(如WAF)和欺骗防御系统(如蜜罐)通常以串联或旁路的方式部署于此链路中。这种设计旨在平衡性能、可用性与安全性:WAF部署于流量入口,负责过滤恶意请求;蜜罐则模拟真实服务,用于诱捕和分析攻击者行为。深刻理解每个组件在请求链中的位置,是我们日后通过外部特征推断其内部存在的基础。
在系统中的位置
本模块作为整个课程的起点,旨在构建信息收集所必需的思维框架。后续所有模块,包括问题定义、结构拆解、方法模型、操作路径等,都将以此系统性认知为基石。通过学习本模块,您将初步形成“架构视角”,从而能够将日后收集到的零散数据点,有效地组织成一幅完整的目标架构视图。
可执行命令或查询方式
本模块侧重于认知构建,但我们可以通过一些简单的命令行工具来初步感受组件间的交互过程。例如,使用dig观察DNS解析过程,或使用curl -I观察响应头中可能暴露的组件信息。以下命令以安全测试目标example.com和httpbin.org为例:
# 观察DNS解析,查看A记录、CNAME等,用于推断CDN或负载均衡的存在
dig example.com A
# 使用curl查看响应头,识别Server字段、Set-Cookie等潜在的技术指纹
curl -I https://example.com
# 访问httpbin.org,观察其响应头中的特征(如Via头可能指示代理或CDN)
curl -I https://httpbin.org工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
dig | DNS查询,分析域名解析路径 | 标准DNS工具,结果详细,支持多种记录类型 | 仅限DNS层信息,无法直接推断上层组件 |
curl | HTTP请求,分析响应头/响应体 | 灵活,可模拟各种请求方法,查看详细交互 | 单次请求,无法自动化批量收集 |
nslookup | 简单DNS查询 | Windows/Linux通用,操作简单 | 信息量较少,不如dig灵活 |
browser DevTools | 浏览器开发者工具,观察网络请求 | 图形化界面,可查看完整请求链、Cookies、缓存 | 依赖图形环境,不便于脚本化 |
标准操作步骤
- 选择测试目标:例如,
example.com。 - 执行DNS查询:使用
dig获取该域名的A记录、CNAME、NS记录,分析是否存在CDN(如CNAME指向CDN域名)。 - 分析HTTP响应头:使用
curl -I发送HEAD请求,记录并关注Server、X-Powered-By、Set-Cookie等字段。 - 探测常见路径:尝试访问如
/robots.txt等常见文件,观察响应内容是否包含技术架构线索。 - 利用浏览器工具:使用浏览器开发者工具刷新页面,观察“网络”标签页中的资源加载域名,判断是否涉及多个子域或第三方CDN。
- 初步信息整理:将收集到的信息整理为简单的组件列表(例如:DNS服务商、Web服务器类型、是否使用CDN)。
如何验证结果真实性
- 验证逻辑:通过多种工具(如
dig与nslookup)对比DNS解析结果是否一致;通过curl与浏览器开发者工具对比响应头信息是否相同。对于推断出的组件,可进一步查找公开资料(如官方文档)来确认其默认特征。 - 输出判断依据:例如,若响应头中包含
Server: nginx,则可初步推断Web服务器为Nginx;若解析出CNAME指向example.com.cdn.cloudflare.net,则可推断使用了Cloudflare CDN(此处仅作逻辑说明,非绝对)。
常见错误与排查方式
- 错误:仅凭单一请求头中的
Server字段就确定整个技术栈,忽略了WAF可能修改或隐藏Server头的情况。 - 排查:使用不同的请求方法(如POST)或访问非标准路径,观察
Server头是否变化;结合多个特征(如Cookie名、响应体特定内容)进行交叉验证。 - 错误:将CDN节点的IP误认为是源站IP。
- 排查:使用多地DNS解析服务或查询历史DNS记录,判断是否存在多个IP且归属于不同的ASN;尝试直接访问IP的80/443端口,观察响应内容是否与通过域名访问时一致。
合规边界说明
- 网络安全视角:本模块仅涉及公开可获取的信息(DNS、HTTP头),不涉及主动扫描或漏洞探测,风险较低。但仍需注意,过于频繁的DNS查询可能被视为侦察行为,某些组织的监控策略可能会记录此类活动。
- 风险:无直接攻击风险,但大量查询可能触发CDN或WAF的速率限制机制。
- 缓解措施:合理控制查询频率,或使用公开的DNS解析服务(如
8.8.8.8),避免直接向目标权威DNS服务器发送大量请求。 - 决策指南:
- 必须用:在信息收集开始前,应通过本模块建立对目标架构的初步认知,以指导后续的深入探测工作。
- 替代:若目标明确为单一静态站点且技术栈已知,可跳过本模块中的某些操作步骤,但系统性思维仍需保留。
本模块小结
本模块引导您从点状思维转向系统思维。通过理解Web应用各组件的交互逻辑,为后续的架构信息收集奠定了坚实的认知基础。借助简单的DNS和HTTP查询,我们已经可以初步勾勒出目标的技术轮廓。接下来,我们将进入下一模块,明确信息收集阶段的具体问题与目标,将抽象的认知转化为可执行的任务。
问题与目标明确
模块概念解释
在信息收集阶段,另一个常见问题是漫无目的地收集数据,导致效率低下或遗漏关键信息。本模块的核心任务,就是帮助您界定清晰的信息收集目标:识别Web应用的技术栈(编程语言、框架、中间件)、发现网络拓扑(负载均衡、CDN)、检测安全防护组件(WAF、IPS)以及识别欺骗防御系统(蜜罐)等。只有明确了“要找什么”,后续选择的方法和进行的操作才能做到有的放矢。
技术原理说明
信息收集的底层逻辑是“暴露面分析”。任何Web应用在提供服务时,都会不可避免地暴露一些信息,如响应头中的Server字段、错误页面的堆栈信息、Cookie的命名规范、URL的结构特征等。攻击者或安全测试人员正是利用这些“信息泄漏”来推断内部架构。同时,作为防护手段的WAF和蜜罐,也会在交互过程中留下独特的指纹(如WAF的拦截页面、蜜罐的响应延迟特征)。因此,在目标明确后,我们需要有针对性地收集这些暴露信息,以回答以下核心问题:
- 应用使用了哪些技术组件?
- 各组件的版本是否存在已知漏洞?
- 是否存在WAF,其类型及规则强度如何?
- 是否存在蜜罐,如何区分真实服务与欺骗服务?
在系统中的位置
本模块承接上一模块“认知基础重构”,将抽象的系统认知转化为具体、可执行的信息收集目标。它明确了在接下来的“关键结构拆解”中需要重点关注的要素,以及后续“方法模型建立”需要解决的问题。没有清晰的目标,任何操作路径都将是盲目的。
可执行命令或查询方式
在目标明确之后,我们可以通过一些简单的探测命令来验证目标的响应特征,为后续的深入分析提供线索。例如:
# 测试目标是否对恶意请求有特殊响应(可能暴露WAF的存在)
curl -I "https://httpbin.org/?id=1'"
# 检查常见管理后台路径是否存在,其响应可能暴露应用类型
curl -I https://example.com/admin
# 使用wafw00f工具初步检测WAF(需预先安装)
wafw00f https://example.com工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
curl | 手动测试特定请求 | 灵活,可构造任意请求头/参数 | 效率低,不适合批量测试 |
wafw00f | 自动检测WAF类型 | 专门针对WAF指纹识别,结果较为准确 | 只能识别WAF,无法检测蜜罐 |
whatweb | 识别Web技术栈 | 插件丰富,能识别CMS、框架、服务器等 | 可能被WAF拦截,产生误报 |
nmap + 脚本 | 扫描开放端口与服务 | 综合性强,可结合NSE脚本检测特定服务信息 | 扫描行为易被检测,可能触发报警 |
标准操作步骤
- 列出问题清单:明确本次信息收集需要解决的具体问题(例如:Web服务器类型是什么?是否存在WAF?是否存在蜜罐?)。
- 快速技术识别:使用
whatweb对httpbin.org进行快速识别,观察输出中包含的服务器、框架等信息。 - WAF初步检测:使用
wafw00f检测目标是否受WAF保护,并记录检测到的WAF类型(如有)。 - 手动触发验证:使用
curl手动构造一个可疑请求(如SQL注入Payload),观察响应状态码、内容长度或内容本身是否发生变化,以此判断是否存在WAF拦截。 - 检查蜜罐特征:访问一些常见的蜜罐特征路径(如
/wp-admin但响应为200且内容可疑),记录任何异常情况。 - 整理初步信息:将收集到的初步信息整理为目标列表,并与最初的问题清单进行对比,明确下一步需要深入挖掘的信息点。
如何验证结果真实性
- 验证逻辑:对于工具的输出,可以通过多次测试或更换工具进行交叉验证。例如,
wafw00f检测到某款WAF后,可以手动模拟该WAF的已知拦截特征(如发送特定恶意请求),观察是否确实被拦截,以此确认WAF的存在。 - 输出判断依据:例如,手动发送请求
/?id=1 AND 1=1返回正常页面,而/?id=1 AND 1=2返回异常,这更可能是应用自身的逻辑差异,而非WAF拦截;若请求中包含单引号'时返回403页面,且响应体中包含特定WAF的名称,则WAF的检测结果可信度较高。
常见错误与排查方式
- 错误:将应用自身返回的错误页面(如500内部错误)误判为WAF拦截。
- 排查:对比正常请求与错误请求的响应内容。如果错误页面包含应用框架的堆栈跟踪信息,则属于应用错误;如果响应是一个风格统一的拦截页面(如“您的请求已被拦截”),则很可能来自WAF。
- 错误:依赖单一工具检测WAF,忽略了WAF可能被配置为“仅记录”模式(即只记录攻击日志,不进行拦截)。
- 排查:使用多种不同类型的Payload进行测试,观察是否在某些情况下响应会有所不同;同时,结合其他信息(如Cookie中是否包含WAF的特定标识)进行综合判断。
合规边界说明
- 网络安全视角:本模块涉及的探测行为(如发送包含SQL注入关键词的请求)可能会被目标WAF识别为攻击行为,从而触发警报。在授权测试中,应提前知会相关人员,或使用
httpbin.org这类公开测试平台进行练习。 - 风险:未经授权对真实目标发送包含恶意Payload的请求属违法行为。本课程中的所有命令示例,仅限在授权环境或公开测试平台使用。
- 缓解措施:严格控制探测的力度,避免使用高危Payload(如联合查询);优先使用专用的测试域名或本地搭建的测试环境。
- 决策指南:
- 必须用:在渗透测试或安全评估中,必须首先明确信息收集的目标,否则后续工作将失去方向,效率低下。
- 替代:对于技术栈已明确的内部评估项目,可以跳过部分识别步骤,但仍需确认是否存在WAF或其配置是否发生变化。
本模块小结
通过本模块的学习,您学会了如何将系统认知转化为明确的问题清单和可执行的任务。这帮助您掌握了利用工具和手动测试,初步识别Web应用技术栈与防护措施的方法。现在,我们已经清楚了要寻找什么。接下来,我们将进入关键结构拆解模块,深入剖析Web应用的各个层次,细化每个组件的特征提取方法。
关键结构拆解
模块概念解释
Web应用的结构可以按照其功能层次进行拆解,每一层都拥有其特有的信息暴露特征。本模块将详细解构这些要素,阐明各层次之间的关系,帮助您在后续的探测工作中能够按图索骥,从不同层面系统地收集信息,并将它们有效地关联起来。
技术原理说明
其底层逻辑是“分层协议栈”与“组件指纹”的结合。
- 网络层通过IP地址、开放端口、TLS证书等暴露信息。
- 传输层可通过负载均衡算法产生的特定行为(如会话保持Cookie)来推断。
- 应用层则通过HTTP头、URL结构、Cookie命名规范、HTML注释、静态资源路径等方式暴露技术栈。
- 数据层可以通过数据库特有的错误信息、默认端口的开放情况来识别。
- 安全层组件(WAF、蜜罐)拥有其独特的响应特征,如WAF拦截页面的特定HTML内容、蜜罐的响应延迟模式或交互的一致性等。
这些特征之所以存在,是因为各组件在协议栈中处于不同位置,且为了完成其功能必须遵循特定的协议,从而产生了可供观测的指纹。
在系统中的位置
本模块是后续“方法模型建立”和“操作路径形成”的重要前置知识。只有深入了解各层次的结构和特征后,才能设计出有针对性的探测方法和操作步骤。它将之前较为模糊的目标(如“识别WAF”)具体化为可操作的检测项(如“寻找WAF拦截页面中的关键词”)。
可执行命令或查询方式
我们可以通过具体的命令来拆解各层信息,仍以httpbin.org为例:
# 网络层:使用nmap扫描开放端口(需在授权范围内)
nmap -p 80,443 httpbin.org
# 应用层:查看响应头中的Server字段
curl -I https://httpbin.org
# 应用层:查看TLS证书信息(可能暴露组织或部门名称)
openssl s_client -connect httpbin.org:443 2>/dev/null | openssl x509 -text | grep "Subject:"
# 数据层:尝试访问可能的数据库管理接口
curl -I https://httpbin.org/phpmyadmin
# 安全层:使用wafw00f检测WAF
wafw00f https://httpbin.org工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
nmap | 端口扫描与服务识别 | 功能强大,可探测开放端口、服务版本 | 扫描行为明显,易触发IDS/IPS |
masscan | 大规模端口扫描 | 扫描速度极快,适合全网范围探测 | 准确性相对较低,可能出现漏报 |
openssl s_client | 分析TLS证书 | 可获取证书的详细信息(颁发者、SAN等) | 需手动解析输出,不够直观 |
whatweb | Web应用指纹识别 | 自动识别CMS、JS库、Web服务器等 | 识别过程可能受WAF干扰 |
wafw00f | WAF检测 | 专门用于检测WAF类型 | 对于新型或定制的WAF可能漏报 |
标准操作步骤
- 网络层收集:在授权范围内,使用
nmap -sS -p 1-1000 scanme.nmap.org扫描常见端口,记录开放端口及其背后的服务。 - 传输层分析:检查是否存在负载均衡的迹象。例如,多次请求
https://example.com,观察响应头中是否有Via、X-Cache等字段,或Set-Cookie中是否有BIGipServer这类负载均衡器特有的Cookie。 - 应用层探测:
- 使用
whatweb https://example.com获取技术栈的概览信息。 - 使用
curl -I记录所有响应头信息。 - 查看HTML源代码(
curl https://example.com),分析其中的注释、JavaScript路径等,以推断前端框架。
- 使用
- 数据层探测:尝试访问常见的数据库管理路径(如
/phpmyadmin、/adminer)或在可能存在SQL注入点的参数后添加引号,观察错误信息中是否暴露了数据库类型。 - 安全层识别:
- 运行
wafw00f https://example.com检测WAF类型。 - 手动构造一个恶意请求(如
/?id=1' OR '1'='1),观察响应是否为拦截页面,并记录该拦截页的特征(标题、HTML内容关键字)。 - 检查蜜罐特征,如响应时间异常(所有请求延迟几乎相同)、交互过于完美(所有不存在的路径都返回相同内容)、Cookie命名异常等。
- 运行
- 信息汇总:将各层收集到的信息记录在表格中,初步建立起目标的层次结构图。
如何验证结果真实性
- 验证逻辑:不同层次的信息应能相互印证。例如,应用层检测到Apache,数据层错误信息提示MySQL,这是一个合理的技术栈组合;若应用层检测到Nginx,但响应头中同时出现了IIS的
Server字段,则可能存在WAF修改或负载均衡转发。对于WAF,可以通过发送一个明显恶意的请求(如/?id=<script>)来观察是否触发拦截,并结合工具的输出进行确认。 - 输出判断依据:例如,TLS证书中的组织字段应与目标的公开信息一致;一个包含
<!DOCTYPE html><title>WAF Block</title>特征的拦截页面,可以作为WAF存在的直接证据。
常见错误与排查方式
- 错误:将CDN的缓存节点误认为是负载均衡器。
- 排查:CDN通常拥有多个遍布全球的IP地址,而负载均衡器通常位于同一数据中心。可以通过多地Ping的方式,观察IP地址是否随地理位置变化来判断是否为CDN。
- 错误:进行应用层识别时,只关注
Server头,而忽略了X-Powered-By、X-AspNet-Version等可能被隐藏或遗忘的头信息。 - 排查:使用
curl -v显示所有响应头信息,并尝试使用不同的User-Agent发起请求,观察响应头是否会发生变化。 - 错误:将蜜罐误判为真实服务。
- 排查:蜜罐通常不提供完整的应用功能。可以尝试进行一些交互操作(如表单提交),观察其业务逻辑是否合理;或者对比不同路径的响应时间,蜜罐可能对所有路径都返回相同的内容。
合规边界说明
- 网络安全视角:端口扫描(尤其是全端口扫描)可能被视为具有攻击性的行为,在进行授权测试前,必须获得客户的书面许可。虽然TLS证书信息是公开的,但大规模批量收集仍可能违反目标网站的服务条款。
- 风险:未经授权进行扫描可能引发法律纠纷,或触发目标的反制措施(如IP封禁)。
- 缓解措施:建议优先使用本地搭建的测试环境或公开的测试平台(如
scanme.nmap.org、httpbin.org)进行练习。在真实的授权测试中,应严格控制扫描速率,避免对目标业务造成影响。 - 决策指南:
- 必须用:在进行全面的安全评估时,必须对各层结构进行拆解,否则可能会遗漏隐藏在非标准端口或组件中的安全漏洞。
- 替代:如果评估范围仅限于Web应用本身(而非网络基础设施),可以跳过网络层扫描,直接进行应用层的识别工作。
本模块小结
通过对Web应用进行分层拆解,我们系统地梳理了从网络到安全各层面的潜在信息暴露面,并掌握了相应的探测命令和工具。这些结构化的信息为我们下一阶段建立方法模型提供了丰富的素材。
方法模型建立
模块概念解释
当我们拥有了经过拆解的结构要素后,接下来需要一套系统的方法论,来指导我们高效、准确地收集这些架构信息。本模块将介绍四种核心的方法模型:主动探测、被动监听、公开信息搜集、错误诱导分析。每种方法都有其适用的场景和固有的局限性,学习者需要根据目标类型和测试阶段,灵活选择合适的策略组合。方法模型的建立,将使我们的信息收集工作从随机的测试转变为有策略的侦察。
技术原理说明
- 主动探测:通过向目标发送精心构造的请求,并根据其响应差异来推断内部组件。其原理在于,不同的组件对特定输入的处理方式不同(例如,WAF会拦截恶意请求,而应用则不会)。优点是直接、可控;缺点是可能触发防御机制。
- 被动监听:通过分析正常的流量(如浏览器访问产生的数据、公开可用的数据)来获取信息,整个过程不主动向目标发送任何请求。其原理是,组件信息可能隐含在响应头、HTML注释、JS文件或Cookie中。优点是无痕、安全;缺点是获取的信息量有限。
- 公开信息搜集:利用搜索引擎、代码托管平台、历史存档网站等公开资源,挖掘与目标架构相关的线索。其原理是,开发或运维人员可能在无意中暴露了技术栈信息(如在GitHub上泄露了配置文件)。优点是信息量大;缺点是需要一定的搜索技巧,且可能涉及隐私边界。
- 错误诱导分析:通过故意触发错误(如访问不存在的路径),观察目标返回的错误页面中是否泄露了堆栈信息或数据库类型。其原理是,默认的错误处理机制可能会暴露内部路径、版本号等敏感信息。优点是能直接获取内部细节;缺点是可能被WAF拦截,或目标应用已自定义了错误页面。
在系统中的位置
本模块位于“关键结构拆解”之后,“操作路径形成”之前。它的作用是将前一步拆解出的各个要素,与具体的信息收集方法一一对应起来,为后续制定详细的操作步骤提供坚实的理论依据。例如,识别WAF可以结合主动探测(发送恶意请求)和被动监听(分析拦截页特征)两种方法。
可执行命令或查询方式
以下命令分别演示了不同方法的应用:
# 主动探测:使用curl发送一个包含SQL注入特征的可疑请求,观察WAF是否会拦截
curl -I "https://httpbin.org/anything?q=1' UNION SELECT NULL--"
# 被动监听:使用浏览器访问目标,在开发者工具的“网络”标签中,查看所有响应头和Cookie,记录下Server、X-Powered-By等信息
# 公开信息搜集:使用搜索引擎的特定语法进行搜索,例如 site:example.com inurl:phpinfo.php
# 错误诱导分析:访问一个不存在的路径,观察404页面是否暴露了服务器信息
curl https://httpbin.org/nonexistent工具对比表
| 方法 | 工具示例 | 优点 | 局限 |
|---|---|---|---|
| 主动探测 | curl, nmap, sqlmap(仅检测模式) | 可控性强,可定向获取特定信息 | 易触发防御系统,可能被记录日志 |
| 被动监听 | 浏览器DevTools, Wireshark | 无痕操作,不产生任何安全风险 | 只能获取到已经暴露的信息 |
| 公开信息搜集 | Google, GitHub, Shodan | 可能发现意想不到的敏感信息 | 依赖搜索引擎的更新,信息可能过时 |
| 错误诱导分析 | curl, Burp Suite | 可获取应用内部路径和版本信息 | 可能被自定义的错误页面所掩盖 |
标准操作步骤
- 确定目标范围:明确本次要收集的组件清单(如WAF类型、数据库版本)。
- 选择方法组合:根据目标特点制定策略。例如,先进行被动监听(访问首页、登录页),记录所有响应头和静态资源信息;再进行主动探测(发送几个常见的恶意Payload),观察是否会触发WAF;最后尝试错误诱导(访问不存在的路径),分析其404页面。
- 执行主动探测:使用
curl逐个测试常见的WAF绕过Payload(如大小写变异、编码混淆),并记录每次请求的响应状态码和内容长度变化。 - 执行公开信息搜集:在Google中尝试搜索
intitle:"index of" "phpinfo.php" site:example.com,以发现可能泄露的文件。 - 执行错误诱导:访问一个随机生成的不存在的路径,如
/asdf1234.php,观察响应内容中是否包含Apache、Nginx或PHP等版本信息。 - 进行交叉验证:将主动探测得到的WAF类型,与从公开信息中可能提及的该目标使用的防护服务进行对比,确认其一致性。
- 记录方法有效性:在最终的报告中,注明每种方法获取到的信息及其置信度。
如何验证结果真实性
- 验证逻辑:当多种不同的方法都指向同一个信息时,该信息的可信度就非常高。例如,主动探测发现了WAF拦截行为,被动监听中拦截页的HTML特征与某款知名WAF一致,同时公开信息中也提到该目标使用了这款WAF,那么结论就非常可靠。
- 输出判断依据:例如,主动探测时发送
/?id=1'返回了403状态码,且响应体中包含ModSecurity字样,可以判断为ModSecurity WAF;同时,被动监听中响应头的Server字段为Apache,两者相互印证。
常见错误与排查方式
- 错误:主动探测时使用了过于明显的攻击Payload,导致WAF封禁了IP,影响后续所有测试。
- 排查:优先使用低风险的Payload(如一个单独的引号
')进行测试。如果触发了拦截,应暂停探测,或更换代理IP,或(在授权测试中)及时通知管理员。 - 错误:进行公开信息搜集时,误将第三方测试网站的缓存内容当作目标本身的信息。
- 排查:仔细验证信息来源的时效性和域名,确保其为官方域名或可信的存档服务。
合规边界说明
- 网络安全视角:主动探测可能被目标视为攻击行为,尤其是在使用自动化工具时。公开信息搜集也可能无意中访问到非公开数据(如GitHub上的私有仓库泄露),需注意法律边界。
- 风险:未经授权的主动探测可能导致法律责任;公开信息搜集可能违反目标网站的服务条款。
- 缓解措施:所有操作必须在明确的授权范围内进行;优先使用公开测试平台进行练习。对于真实目标,若无书面许可,应仅限于被动监听和公开信息搜集。
- 决策指南:
- 必须用:在专业的渗透测试中,必须结合多种方法,因为单一方法无法覆盖所有的信息维度。
- 替代:如果已经明确知道目标的技术栈,且无需确认细节,可以减少主动探测的强度,侧重于被动监听。
本模块小结
本模块为您建立了四种核心的信息收集方法模型,使您能够根据不同的场景灵活选择策略。方法模型的建立,将前期的理论知识转化为了可操作的行动指南。在下一模块,我们将基于这些方法,形成一套具体的、一步步的操作路径。
操作路径形成
模块概念解释
拥有了方法模型后,我们需要将它们组织成一个系统化的探测流程,这便是操作路径。本模块将为您制定一条从信息收集开始到结束的完整步骤,涵盖域名解析、端口扫描、服务识别、目录探测、WAF指纹识别、蜜罐识别等关键环节,确保每一步都有明确的目的和输出,避免重复劳动或关键信息遗漏。这条操作路径的设计遵循 “由外向内、由浅入深” 的原则,即先从风险最低的信息开始收集,再逐步深入。
技术原理说明
操作路径的底层逻辑是 “信息增益”和 “风险控制” 的平衡。我们从最外层、最不容易触发防御的信息开始(如DNS、证书);然后逐步深入到可能触发IDS的端口扫描、可能被日志记录的服务识别、可能触发WAF规则的目录探测;最后才是可能引发反制的WAF指纹和蜜罐识别。每一步的结果都将用于调整后续策略。例如,一旦发现WAF的存在,后续探测就需要降低速率、使用更隐蔽的Payload。这种设计旨在最大化信息收集效率的同时,最小化被目标阻断的风险。
在系统中的位置
本模块是“方法模型建立”的具体化产物,它将方法论转化为一系列可执行的步骤序列。它直接指导您进行实际操作,并为后续的“风险与边界控制”提供了具体的上下文。本模块的输出,将是下一模块(风险控制)的输入,也是最终“能力整合输出”的数据来源。
可执行命令或查询方式
以下是一个简化的操作路径示例,目标为example.com:
# Step 1: DNS 信息收集
# 注意:dig ANY 查询在实际中常被递归服务器限制,更可靠的方式是逐一查询常见记录类型。
dig example.com A +noall +answer
dig example.com MX +noall +answer
dig example.com TXT +noall +answer
# Step 2: 基于DNS结果,使用nmap扫描常见端口(需授权)
nmap -sS -p 80,443,8080,8443 example.com
# Step 3: Web服务识别
whatweb https://example.com
# Step 4: WAF检测
wafw00f https://example.com
# Step 5: 目录枚举(使用dirb,注意控制速率)
dirb https://example.com /usr/share/wordlists/dirb/common.txt -r -z 100
# Step 6: 蜜罐特征检测(如检查响应一致性)
for path in / /admin /login /wp-admin; do
curl -s -o /dev/null -w "%{http_code} %{time_total}\n" https://example.com$path
done【补充说明】:使用dig ANY查询在实际中常被递归服务器限制,返回结果可能不完整。更可靠的方式是逐一查询常见记录类型(A、AAAA、MX、TXT等),此行为依据为IETF RFC 9619对DNS查询的规范。
工具对比表(针对路径中的步骤)
| 步骤 | 工具 | 作用 | 替代工具 |
|---|---|---|---|
| DNS收集 | dig | 获取A/AAAA/CNAME/MX等记录 | nslookup, host |
| 端口扫描 | nmap | 发现开放端口及服务 | masscan, rustscan |
| Web指纹 | whatweb | 识别Web技术栈 | Wappalyzer(浏览器插件) |
| WAF检测 | wafw00f | 检测WAF类型 | identywaf |
| 目录枚举 | dirb | 发现隐藏目录和文件 | gobuster, ffuf |
| 蜜罐检测 | curl | 分析响应时间/内容一致性 | 自定义Python脚本 |
标准操作步骤
Web应用架构信息收集操作路径流程图

- 信息收集准备:确定目标域名(如
example.com),记录开始时间,并再次确认授权范围。 - 第一步:基础信息收集:
- 使用
dig分别查询DNS的A、CNAME、MX等记录。 - 若目标支持HTTPS,使用
openssl s_client获取TLS证书信息。
- 使用
- 第二步:端口扫描:
- 运行
nmap -sS -p 1-1000 -T4 --open target.com(注意:-T4可能过快,可根据网络状况和风控要求降为-T3,并考虑使用--max-rate进一步控制速率)。 - 记录所有开放的端口及其对应的常见服务(如80/http, 443/https)。
- 运行
- 第三步:服务指纹识别:
- 对每一个开放的Web服务端口,使用
whatweb http://target.com:port进行技术栈识别。 - 使用
curl -I收集Web服务的响应头,重点关注Server、X-Powered-By、Set-Cookie等字段。
- 对每一个开放的Web服务端口,使用
- 第四步:WAF识别:
- 运行
wafw00f https://target.com,记录其输出结果。 - 手动发送几个简单的可疑请求(如
/?id=1'),观察是否触发拦截,并记录拦截页面的特征。
- 运行
- 第五步:目录枚举(可选):
- 使用
gobuster dir -u https://target.com -w /usr/share/wordlists/dirb/common.txt -t 10 -z 1000。 - 根据上一步是否发现WAF,动态调整线程数(
-t)和延迟(-z),避免对目标造成过大压力。
- 使用
- 第六步:蜜罐特征检查:
- 编写一个简单的循环脚本,访问多个不同的路径,记录每个请求的HTTP状态码和响应时间,分析是否存在异常模式(例如,所有路径都返回相同内容,或响应时间恒定且极短)。
- 数据整理:将以上各步骤的输出结果汇总到一个统一的表格中,并标记每条信息的来源和可信度。
如何验证结果真实性
- 验证逻辑:操作路径中的每一步都应能被复现或通过其他方式交叉验证。例如,端口扫描的结果可以与在线服务(如Shodan)的历史数据进行粗略对比;WAF识别的结果可以通过手动发送Payload来验证;目录枚举发现的路径可以通过手动访问来确认其是否真实存在。
- 输出判断依据:如果目录枚举工具报告某个路径返回200状态码,但手动访问发现页面内容是WAF的“访问被拒绝”页面,那么该目录枚举结果很可能是假阳性——实际路径可能不存在,而是WAF对所有不存在的路径返回了统一的拦截页面。
常见错误与排查方式
- 错误:端口扫描使用默认的较高速率(如
-T4)导致网络丢包,从而漏掉了一些实际上开放的端口。 - 排查:降低扫描速率(如
-T3)重新扫描,或使用masscan等不同的工具进行验证。 - 错误:目录枚举时线程数设置过高,导致源IP被WAF封禁。
- 排查:使用代理池轮换IP,或等待IP解封后,在后续探测中增加请求延迟(如使用
-z参数)。 - 错误:将负载均衡器的Cookie(如
BIGipServer)误认为是WAF的指纹。 - 排查:查看Cookie的值的格式。负载均衡器的Cookie通常包含经过编码的服务器IP或端口信息,而WAF的Cookie可能包含会话ID或安全标记。
合规边界说明
- 网络安全视角:目录枚举、端口扫描等主动探测行为,很可能违反目标网站的服务条款,尤其是在未经授权的情况下。在授权测试中,必须提前与客户确认允许的探测深度和速率。
- 风险:目录枚举可能会发现一些敏感文件(如配置文件备份)。如果下载并查看这些文件的内容,可能涉及数据泄露的风险。
- 缓解措施:所有探测活动应在测试环境中进行模拟。若在授权测试中发现了敏感文件,应立即向客户报告,而不应擅自下载或查看其内容。
- 决策指南:
- 必须用:在进行全面的渗透测试时,应当执行此操作路径,以全面了解目标的攻击面。
- 替代:如果测试范围仅限于Web应用的业务逻辑(而非底层基础设施),可以跳过端口扫描和目录枚举,直接进入应用层测试。
本模块小结
本模块将前序的方法论转化为了一个清晰、可执行的操作路径。这条路径从外到内、从低风险到高风险,确保了信息收集工作的系统性和安全性。您可以按照此路径逐步操作,以获得全面且准确的目标架构信息。在操作过程中,需要时刻注意潜在的风险,下一模块我们将专门探讨如何控制这些风险。
风险与边界控制
模块概念解释
在信息收集过程中,主动探测行为可能会触发目标的安全防御机制(如WAF拦截、蜜罐记录),甚至导致测试IP被封禁,引发法律后果。本模块旨在帮助您识别这些防御系统的干扰,设定安全的探测边界。通过学习速率控制、流量伪装、授权确认等技术,确保信息收集过程始终在合法、合规、可控的范围内进行,避免对目标造成计划外的负面影响。
技术原理说明
防御系统(WAF、IPS、蜜罐)的核心原理是基于规则匹配或行为分析来识别恶意流量。
- WAF 通常会检测请求中是否包含攻击特征(如SQL注入的关键字),一旦匹配即进行拦截。
- 蜜罐 则会记录攻击者的所有行为,并可能返回精心构造的虚假信息来迷惑攻击者。
因此,我们的探测行为必须考虑以下几点: - 速率控制:过高的请求频率会被视为扫描或自动化攻击,从而触发目标的速率限制机制。
- 特征隐藏:通过使用随机的User-Agent、在请求间加入延迟、对Payload进行变异(如大小写转换、URL编码)等方法,可能绕过一些简单的检测规则。
- 边界设定:在测试开始前,必须明确哪些操作是允许的(如授权范围内的探测),哪些是绝对不能触碰的红线(如漏洞利用、数据篡改)。
- 法律边界:未经授权,对任何非公开目标进行主动探测,都可能触犯当地法律法规。
在系统中的位置
虽然本模块在课程中被安排在操作路径之后进行阐述,但在实际探测中,风险控制意识应贯穿始终。它强调在进行每一步操作前,都必须考虑其可能带来的风险。只有确保数据未被防御系统“污染”,我们才能基于这些数据生成准确可靠的目标架构视图,这也是下一模块“能力整合输出”的前提。
可执行命令或查询方式
风险控制主要通过配置工具的参数和敏锐观察目标的反馈来实现。例如:
# 控制nmap扫描速率(--max-rate 10 表示每秒最多发送10个数据包)
nmap -sS -p 1-1000 --max-rate 10 example.com
# 使用curl时随机化User-Agent(使用-A参数)
curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36" -I https://example.com
# 目录枚举时增加延迟(-z 1000 表示延迟1000毫秒)
gobuster dir -u https://example.com -w wordlist.txt -t 1 -z 1000
# 使用代理轮换(需提前配置好代理池)
curl -x http://proxy:port https://example.com工具对比表(风险控制相关功能)
| 工具 | 控制功能 | 优点 | 局限 |
|---|---|---|---|
nmap | --max-rate, --scan-delay | 可以精确控制网络层的发包速率 | 对应用层(HTTP)的请求速率控制,需配合其他工具 |
curl | --limit-rate, -A, -x | 可以灵活控制单个请求的头信息、速率和代理 | 仅能控制单个请求,不适用于大规模自动化扫描 |
gobuster | -t(线程数)、-z(延迟毫秒) | 内置延迟控制参数,简单易用 | 延迟单位为毫秒,需要根据网络情况合理设置 |
ffuf | -t、-p(延迟) | 支持多种延迟策略(如随机延迟),功能强大 | 配置相对复杂 |
Burp Suite | Intruder模块的Throttle | 图形化界面,可直观地配置请求延迟和线程数 | 依赖图形界面,不便于无头环境下的自动化集成 |
标准操作步骤
风险控制与自适应调整流程图
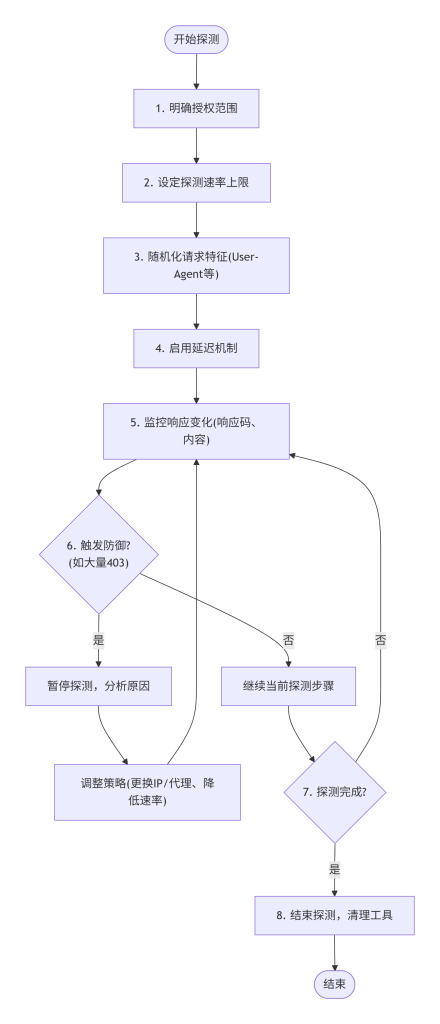
- 明确授权范围:在开始任何探测前,务必确认目标是否在授权范围内,以及客户允许的探测深度(如是否允许目录枚举、端口扫描)。
- 设定探测速率:根据目标的重要性和网络状况,设定一个合理的速率上限。例如,端口扫描不超过10包/秒,目录枚举不超过1请求/秒。
- 随机化请求特征:使用随机的User-Agent、Referer等HTTP头,避免所有请求的模式过于单一,易于被识别为扫描器。
- 启用延迟机制:在使用的工具中配置请求间的延迟参数,如
gobuster -z 2000(2秒延迟)。 - 监控响应变化:在探测过程中,密切关注响应的状态码和内容是否发生突然变化(如所有请求都返回403)。一旦出现异常,应立即暂停,分析是否被封禁。
- 使用代理或VPN(可选):如需隐藏真实IP,可以使用合规的代理或VPN,但需注意代理服务的稳定性,避免因代理故障导致数据丢失。
- 记录被拦截情况:如果触发了WAF拦截,应详细记录拦截页的特征,这有助于后续分析,并指导我们调整策略(如更换Payload、进一步降低速率)。
- 结束探测后清理:所有探测任务完成后,应停止所有工具,确保没有残留的进程在后台运行。
如何验证结果真实性
- 验证逻辑:通过对比“正常访问”(如使用常规浏览器访问)与“探测访问”的响应,可以判断是否存在防御干扰。例如,如果探测时所有请求都返回403,而用浏览器访问却完全正常,则说明我们的IP很可能被封禁或触发了WAF规则。
- 输出判断依据:如果在探测过程中,响应码从200突然转变为403,且响应体内容变为一个典型的WAF拦截页面,则可以确认为触发了防御。此时,之前获取的探测结果可能已被“污染”(如目录枚举的结果可能不准确),需要在报告中特别说明。
常见错误与排查方式
- 错误:探测速率过快导致IP被封禁,却未能及时察觉,后续的所有请求都被拦截,导致误以为目标服务无响应。
- 排查:使用一个备用IP(如手机热点)或通过代理重新尝试访问目标,确认目标服务是否仍然正常。如果备用IP可以访问,则证实原IP已被封禁。
- 错误:使用了默认或过于老旧的User-Agent,被WAF轻易地识别为扫描器。
- 排查:使用当前主流浏览器的User-Agent,并准备一个列表进行随机轮换,避免使用那些众所周知与黑客工具关联的User-Agent。
- 错误:目录枚举时,WAF对某些敏感路径(如
/admin)返回了一个假的200状态码(实际上是其拦截页面),导致误判该路径真实存在。 - 排查:手动访问这些被报告为存在的路径,仔细对比其页面内容与目标应用首页或正常页面是否一致。如果页面内容包含“拦截”、“拒绝”等关键词,则为假阳性。
合规边界说明
- 网络安全视角:风险控制不仅仅是技术问题,更是法律和职业道德的体现。未经授权的主动探测,即使速率控制得再好,也可能触犯《网络安全法》等相关法规,带来严重的法律后果。
- 风险:即使在授权测试中,过度的探测也可能导致目标业务中断,造成实际的经济损失,测试方需为此承担责任。
- 缓解措施:始终在授权范围内谨慎操作;与客户明确测试的时间窗口和紧急联系人;在测试环境中充分演练后再对真实目标进行操作;若有权限,探测前做好目标系统的备份。
- 决策指南:
- 必须用:在任何形式的主动探测中,都必须应用风险控制措施,这是专业安全测试人员的基本素养。
- 替代:如果只需要收集被动信息(如DNS、证书),则无需进行严格的风险控制,但仍需遵守基本的法律边界。
本模块小结
本模块强调了信息收集过程中风险控制的重要性,并提供了具体的技术手段和操作流程。学习者应当养成“先定边界,后行探测”的职业习惯,确保每一次测试活动都在合法合规的框架内进行。经过严格的风险控制,我们收集到的信息将更加可靠。接下来,我们将进入最后一个模块,把这些经过验证的信息整合成最终的架构视图,并规划后续的测试工作。
能力整合输出
模块概念解释
信息收集的最终目的,并非仅仅获得一堆零散的数据点,而是要形成对目标架构的全面、深入的理解,并基于此规划后续的测试或评估策略。本模块将整合前六个模块所收集的多源信息(包括DNS、端口、技术栈、WAF类型、蜜罐特征等),生成一份结构化的架构视图(如拓扑图、组件清单)。同时,我们将根据这份视图识别出的薄弱点或关键组件,规划下一步的测试方向(例如,针对特定版本组件的漏洞利用、或寻找绕过WAF的策略)。能力整合输出的完成,标志着信息收集阶段的正式结束,以及深入测试阶段的开始。
技术原理说明
整合过程的底层逻辑是 “关联分析” 和 “决策支持” 。来自不同来源的信息可能会相互印证,也可能相互矛盾。我们需要通过逻辑推理,剔除干扰信息,还原出最接近真实的架构。例如,如果主动探测发现了WAF,被动监听中拦截页的特征又与某款知名WAF吻合,那么WAF的类型就可以被确认。如果TLS证书中的组织信息与DNS解析出的IP所属的ASN不符,则很可能涉及CDN或云托管服务。整合后的视图能帮助我们快速定位关键资产(如管理后台、数据库接口)和潜在弱点(如过时的组件版本、可能存在绕过的WAF规则)。后续的规划则遵循 “攻击面最大化” 原则,优先测试那些暴露面大且可能存在脆弱性的组件。
在系统中的位置
本模块是整个“信息收集-架构分析”课程的收尾之作,同时也是后续渗透测试(或安全评估)工作的起点。它将之前收集到的所有零散数据点串联起来,形成有价值的知识,为下一阶段的漏洞挖掘、权限提升等任务提供决策依据。至此,信息收集阶段的工程闭环正式完成。
可执行命令或查询方式
信息整合本身不涉及新的探测命令,但我们可以通过编写一些简单的脚本来辅助数据整理。例如,编写Shell脚本从各工具的输出中提取关键字段:
#!/bin/bash
# 示例脚本:提取wafw00f结果中的WAF名称
wafw00f https://example.com 2>/dev/null | grep "is behind" | awk '{print $NF}'
# 示例脚本:提取whatweb结果中的服务器信息
whatweb https://example.com --log-verbose=tmp.log && cat tmp.log | grep "Server"对于最终的架构图绘制,更高级的做法是使用绘图工具(如draw.io、Visio)进行手工绘制。
工具对比表(信息整合工具)
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| 文本编辑器/Excel | 手工整理少量数据 | 灵活,上手快,适合小型项目 | 效率低,难以处理和分析大量数据 |
jq | 处理JSON格式的工具输出 | 可实现自动化数据提取,适合编写脚本 | 需要工具支持JSON格式输出,且需学习jq语法 |
grep/awk | 从文本日志中提取信息 | 快速、简单,无需额外安装 | 对复杂的结构化文本处理能力有限 |
| 思维导图软件 | 绘制架构图、组件关系图 | 直观清晰,便于团队交流和汇报 | 无法自动生成,需手工绘制和更新 |
| Dradis/Maltego | 专业渗透测试信息管理平台 | 集成多种工具输出,可自动进行数据关联 | 学习成本高,部分高级功能可能需要付费 |
标准操作步骤
信息整合与规划流程图
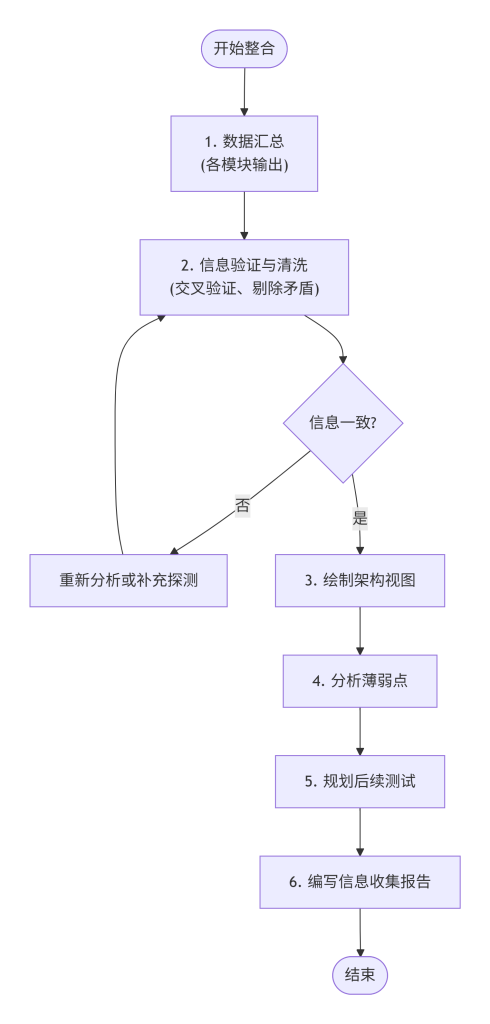
- 数据汇总:将前六个模块中记录的所有信息,整理到一份统一的文档中,内容包括但不限于:
- DNS解析结果(A、CNAME、MX等)
- 开放的端口及其服务版本
- Web技术栈(Web服务器、编程语言、框架)
- WAF检测结果(类型、拦截页特征)
- 蜜罐的可疑特征
- 目录枚举发现的敏感路径
- 错误信息中泄露的细节
- 信息验证与清洗:剔除相互矛盾的信息,并对置信度较低的推测进行标注。例如,如果
whatweb检测到Apache,但curl显示的Server头为Cloudflare,则两者都应保留,并说明可能存在CDN。 - 绘制架构视图:使用图表工具,绘制出一份清晰的分层架构图,应包含:
- 外层:DNS、CDN、负载均衡器
- 中间层:Web服务器、WAF
- 内层:应用服务器、数据库、缓存系统
- 欺骗层:蜜罐(标注为可疑)
- 分析薄弱点:结合绘制的视图,标注出可能存在漏洞的组件,例如:版本过低的Apache、未授权的管理界面、可能绕过WAF的特定路径等。
- 规划后续测试:基于薄弱点分析,制定下一步的具体测试计划,例如:
- 对特定端口上的服务进行漏洞扫描。
- 针对识别出的WAF类型,研究并尝试绕过技巧。
- 尝试访问发现的管理后台,进行弱口令测试。
- 若确认存在蜜罐,调整后续的交互策略,避免被详细记录。
- 编写信息收集报告:将最终的整合结果和后续测试计划,整理成一份正式的报告,供团队或客户审阅。
如何验证结果真实性
- 验证逻辑:整合后的架构视图应当是一个自洽的整体,能够解释我们在探测过程中观察到的所有现象。例如,如果视图中包含WAF,那么它应该能解释为什么某些请求会被拦截;如果包含CDN,则应能解释为什么多地Ping的结果会不一致。最后,可以通过一个简单的测试来验证视图的准确性:比如,预期某个端口是数据库,在授权环境下尝试连接,看是否返回了数据库的典型特征。
- 输出判断依据:如果所有的信息都能在视图中找到其合理的位置,并且没有逻辑矛盾,那么这份视图的可信度就非常高。后续的测试结果如果与视图的预测一致,则将进一步验证其正确性。
常见错误与排查方式
- 错误:在进行信息整合时,忽略了WAF可能会隐藏真实的
Server头,从而导致误判应用服务器为CDN或WAF本身。 - 排查:综合分析多个请求头。例如,
Server头为cloudflare,但X-Powered-By头却显示为PHP,那么真实服务器很可能是Apache或Nginx,而CDN(Cloudflare)位于其前端。 - 错误:将蜜罐返回的虚假信息当成了真实的组件(例如,蜜罐模拟返回了一个PHP版本号)。
- 排查:蜜罐通常无法完美模拟一个完整应用的所有功能。可以尝试进行更深度的交互(如表单提交、状态保持),看其业务逻辑是否能连贯执行。如果所有路径都返回近乎相同的内容,则高度怀疑是蜜罐。
- 错误:目录枚举发现了大量路径,但未能有效区分哪些是真实的应用路径,哪些是WAF返回的假阳性响应。
- 排查:手动访问那些可疑的路径,查看页面的标题、内容是否与目标应用的核心业务相关。毫不相关的内容,很可能是WAF或蜜罐的虚假响应。
合规边界说明
- 网络安全视角:信息整合本身不产生新的安全风险。但整合后的视图可能包含高度敏感的信息(如数据库的内网IP、管理后台的真实路径),必须妥善保管,严防泄露。
- 风险:如果这份详细的架构视图落入恶意攻击者手中,将成为他们极佳的攻击蓝图。
- 缓解措施:对最终的报告进行加密存储,并严格限制访问权限,仅对必要的授权人员开放。在报告中,可以对关键的内部IP和敏感路径进行脱敏处理。
- 决策指南:
- 必须用:在专业的渗透测试服务中,进行信息整合与后续规划是必不可少的环节,否则整个测试过程将失去方向,变得盲目而低效。
- 替代:对于时间紧迫的快速安全评估,可以适当简化整合过程,但至少也应产出一份关键资产清单。
本模块小结
本模块完成了信息收集阶段的最后一步,也是最为关键的一步——将零散的数据整合为有价值的架构知识,并以此规划未来的行动。至此,我们走完了从建立系统性认知、明确目标、结构化拆解、掌握科学方法、遵循规范操作、执行严格风险控制,到最终整合输出的全过程。通过这一套完整的工程化流程,您已经具备了独立完成Web应用架构信息收集阶段工作的专业能力。下一阶段,我们将进入漏洞探测与利用的领域,但那将是另一门课程的主题了。
参考与进一步阅读
- IETF RFC 9619 – In the DNS, QDCOUNT Is (Usually) One: 本文中DNS查询行为与协议基础的主要依据。
- WAFW00F Official Repository: 本文中WAF检测工具
wafw00f的命令示例与功能说明来源。 - OWASP Web Application Firewall: Web应用防火墙(WAF)定义与技术原理的权威参考。
- PortSwigger Burp Suite Documentation: 本文中负载均衡Cookie识别、风险控制功能(Intruder Throttle)及错误诱导分析的参考依据。
- curl man page: 本文中所有
curl命令的语法、参数(-I,-A,-x,--limit-rate)及行为描述的技术参考。 - Nmap Network Scanning Official Documentation: 本文中
nmap端口扫描、速率控制(--max-rate)及安全测试实践的技术依据。 - IETF RFC 1035 – Domain Names – Implementation and Specification: DNS基础协议的核心规范,与RFC 9619共同构成DNS查询的理论基础。
- curl Official Website: 本文中
curl工具的灵活性与基础用法描述的来源。 - Nmap Reference Guide: 本文中
nmap工具功能、扫描技术与安全注意事项的权威参考。
信息收集-Web应用-架构分析&框架组件识别
一、重构应用架构认知前提
1. 模块概念解释
进行技术探查前,首先需要理解目标应用并非一个 monolithic(单体)黑色盒子,而是一个由多种服务组件、通过网络协议进行信息交换的分布式系统。本模块解决“看什么”和“在哪儿看”的问题,目标是将视角从“单一主机”切换到“分布式应用架构”,为后续特征识别建立正确坐标系。它明确了探查的底层逻辑:我们是在理解一个由各种组件构成的生态系统,而非攻击一台机器。
2. 技术原理说明
现代 Web 应用架构基于分层和微服务设计理念。在网络七层模型(OSI 模型)中,HTTP/HTTPS(应用层)是表象,但其底层依赖 TCP/IP(传输层)的端口通信、DNS(应用层)的域名解析,以及可能的 CDN(内容分发网络)、负载均衡器等中间件。其核心是“请求-响应”模型:客户端发送请求,经过网络到达服务端,服务端的各个组件(如 Web 服务器、应用框架、数据库)协同处理,最终返回响应。探查即通过构造特定请求,观察和分析响应中的特征,逆向推导出背后组件的构成。
3. 在系统中的位置
此模块是整个探查流程的基石,位于所有操作之前。它不直接产生可执行命令,而是建立一套思维模型。后续的“界定目标”、“解析特征”等模块,均在此认知前提下展开。没有这个前提,后续探查将缺乏系统性,难以形成有效体系。
4. 可执行命令或查询方式
虽然没有直接的探查命令,但可以通过基础命令实践“组件分离”的观察视角。例如,使用 dig 观察域名解析,可以看到应用架构中的第一个组件:DNS。
# 观察一个域名背后的IP地址,思考是否有多个IP(负载均衡或CDN)
dig example.com
# 跟踪一个HTTP请求的完整网络路径
# Linux 或 macOS 系统
traceroute example.com
# Windows 系统
tracert example.com这些命令有助于理解一个简单的 example.com 背后可能涉及复杂的网络路径和多台物理/虚拟设备。
5. 工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
dig / nslookup | DNS 解析查询,探查域名背后的IP和记录类型 | 标准协议工具,信息准确,几乎所有系统预装 | 仅限DNS层,无法看到应用层组件 |
traceroute / tracert | 网络路径追踪,探查中间网络节点 | 直观展示网络路径,帮助理解网络拓扑 | 结果可能因防火墙或ICMP屏蔽而不完整 |
| 浏览器开发者工具 (F12) | 分析前端HTTP请求与响应,观察资源加载 | 图形化界面,信息全面,能直观看到请求头、响应头、Cookie等 | 局限于客户端可见的交互,无法探测服务端配置 |
curl | 命令行HTTP请求工具,精细控制请求细节 | 灵活强大,可自定义请求头、方法、Body,便于脚本化 | 需要一定的命令行基础,对HTTPS证书处理需要额外参数 |
6. 标准操作步骤
- 选择一个目标:以一个你拥有或有权测试的Web应用为例,如本地测试站点
test.local,或公开测试站httpbin.org。 - 打开浏览器开发者工具:按F12,切换到“网络 (Network)”标签。
- 访问目标并观察:在浏览器地址栏输入
http://httpbin.org并回车。观察开发者工具中捕获的请求列表。 - 分析第一个请求:点击第一个请求(通常是文档本身),查看“请求头 (Request Headers)”和“响应头 (Response Headers)”。
- 思考组件:响应头中的
Server字段(如果有)可能揭示了Web服务器软件。页面渲染出的复杂功能(如表单提交、数据查询)暗示了后端应用框架和数据库的存在。
7. 如何验证结果真实性
验证逻辑:此阶段不验证具体组件的“真实性”,而是验证“应用由多组件构成”这个认知模型的真实性。
判断依据:观察到的现象是否可以用多组件模型来解释。例如,看到一个登录页面,不应简单归结为“这是台Linux服务器”,而应推断为“这很可能是一个由前端页面、后端API(处理登录逻辑)和数据库(存储用户凭证)构成的系统”。这种推断是后续步骤的基础。
8. 常见错误与排查方式
- 错误:将Web应用等同于Web服务器。
- 排查:提醒自己Web服务器只是入口。动态内容、样式、图片、API接口均由不同组件或服务提供。尝试禁用浏览器中的JavaScript,观察页面功能是否缺失,这有助于区分前端和后端组件的职责。
9. 合规边界说明
- 使用场景:本模块仅用于建立内部知识体系和思维训练,不涉及任何实际目标系统的扫描或探测。
- 网络安全视角:风险在于,若运维人员缺乏“分布式”视角,可能错误配置安全策略(如只保护Web服务器而忽略后端API或数据库访问控制)。缓解措施是进行全面的资产盘点。
- 决策指南:在学习任何新应用架构时,建议首先进行此思维重构。这是所有后续分析工作的前提,无替代方案。
10. 本模块阶段性小结
我们从单一主机的固有思维中走出,建立了应用由多组件构成的认知模型。现在明确了应在哪些维度(网络、协议、组件)上观察。接下来,我们将这种宏观认知转化为具体的探查目标,学习如何界定探查的范围和重点。
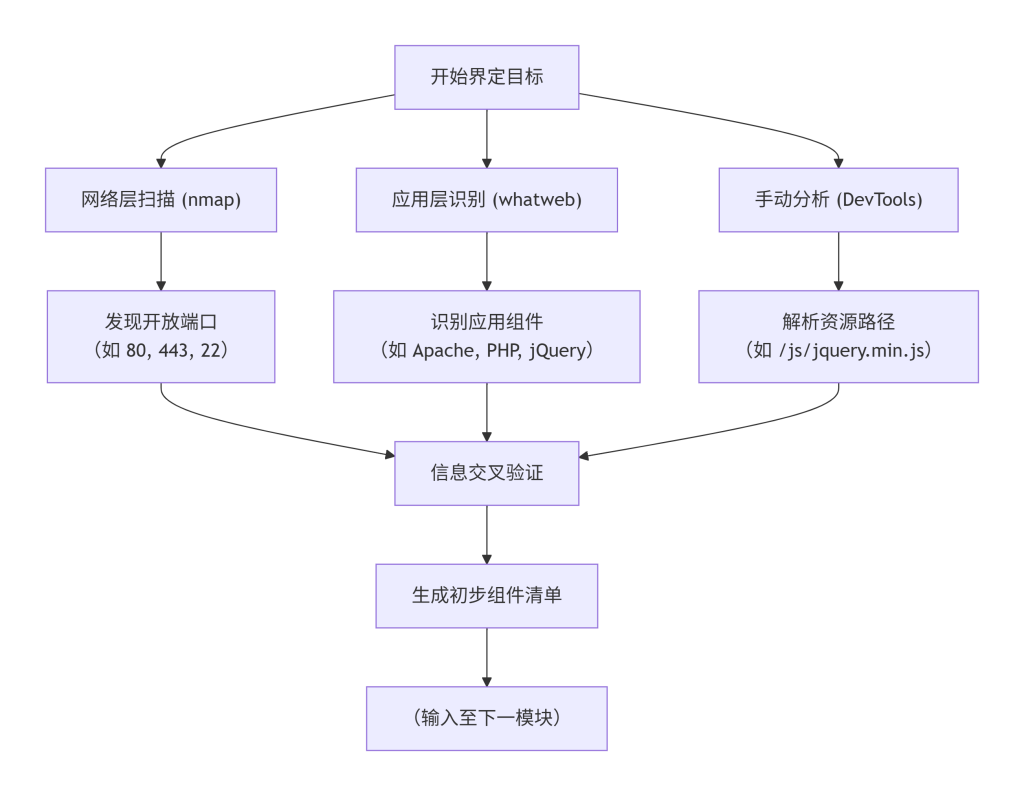
二、界定探查目标与范围
1. 模块概念解释
承接上一模块对应用架构的认知重构,现在我们需要将宏观视角转化为可操作的任务清单。面对复杂应用架构,不可能也无必要对所有组件进行同等深度探查。本模块的核心任务是“划定边界”,即明确需要识别的组件类型(如 Web 服务器、中间件、开发框架、数据库、API 网关等)及其在应用服务中的具体角色。这有助于聚焦资源,避免在海量信息中迷失方向,确保后续探查高效且有针对性。
2. 技术原理说明
典型 Web 应用请求流程如下:客户端 -> (CDN) -> (负载均衡器) -> Web 服务器 -> 应用框架 -> 数据库。链条上的每个环节都是潜在的探查目标。技术原理在于,不同组件在请求-响应生命周期中扮演不同角色,因此它们留下的“指纹”分布在不同的数据层面。例如,Web 服务器的指纹常在响应头的 Server 字段,而应用框架的指纹可能藏在 Cookie 的格式、特定的 URL 路径或 HTML 注释中。界定目标即根据目的(如安全评估、兼容性测试、资产梳理),选择链条上最关心的环节。
3. 在系统中的位置
本模块紧接在“重构认知”之后,是将宏观认知转化为具体操作清单的第一步。它告知“解析特征”模块应解析哪些组件的特征,并为后续“构建识别模型”提供输入项,起到承上启下的“过滤器”作用。
4. 可执行命令或查询方式
在此阶段,通过初步信息收集命令帮助“界定范围”,而非深入识别。
# 使用 curl 查看响应头,初步判断存在哪些组件(如 Server, Set-Cookie 等)
curl -I http://httpbin.org
# 使用 nmap 对目标进行端口扫描,发现开放了哪些服务(不仅仅是80/443)
# scanme.nmap.org 是官方提供的合法测试目标
nmap -p- scanme.nmap.org
# 使用 whatweb 进行初步的、宽泛的应用识别,它会列出它认为存在的组件
whatweb http://httpbin.org通过观察这些命令的输出,可以列出一个初步的“组件清单”,例如:可能有一个 Web 服务器(nginx),可能有一个 Python 框架(通过 httpbin 的响应特征),可能还有别的端口(如 22/ssh)运行着其他服务。这就是初步界定的探查目标范围。
5. 工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
curl -I | 快速查看HTTP响应头,识别Web服务器和 Cookies | 简单快速,几乎无处不在 | 信息量有限,无法探测深层框架和组件 |
nmap | 端口扫描,发现目标主机上所有开放的TCP/UDP端口 | 网络层发现的利器,能绘制出服务的“暴露面” | 速度较慢(尤其是全端口扫描),无法识别应用层具体版本 |
whatweb | 应用层指纹识别,主动探测Web应用及其组件 | 自动化程度高,插件丰富,能识别大量CMS、框架、库 | 可能产生误报,对自定义应用的识别能力弱 |
wappalyzer (浏览器插件) | 被动分析,在浏览网页时识别所使用的技术栈 | 方便快捷,结果直观,不影响目标服务器 | 仅分析客户端可见内容,无法探测服务端配置 |
6. 标准操作步骤
- 设定目标:假设目标为全面了解
http://test.local测试应用的技术栈。 - 网络层范围界定:执行
nmap -sV -T4 test.local。-sV参数尝试探测服务版本,帮助确认开放端口上运行的服务类型(如Apache httpd,MySQL)。 - 应用层范围界定:执行
whatweb http://test.local或使用 Wappalyzer 访问该站点。记录所有被识别出的组件,无论置信度高低。 - 手动分析补充:在浏览器中打开开发者工具,查看所有加载的资源(JS, CSS, 图片)。这些资源的路径有时会暴露所使用的框架或库(如
/static/js/jquery.min.js暗示 jQuery 库)。 - 形成初始清单:综合以上信息,列出接下来需要重点探查的组件清单,例如:[Web服务器: Apache?, 后端语言: PHP?, 前端库: jQuery, 数据库: MySQL?]。
7. 如何验证结果真实性
验证逻辑:通过不同来源、不同类型的信息进行交叉验证,判断初步清单的合理性。
判断依据:
nmap发现80端口开放,服务是 Apache。这与whatweb报告的Apache吻合,提高可信度。whatweb报告了PHP,同时curl查看页面 URL 可能包含.php后缀,这也是一种交叉验证。- 若
nmap未发现3306端口开放,但初步清单里却有 MySQL,则需要思考:数据库是否在内网不对外暴露?或判断有误?这指引了下一步探查方向。
8. 常见错误与排查方式
- 错误:范围定得过大或过小。过大导致信息过载,过小导致遗漏关键组件。
- 排查:遵循“先宽后窄”原则。先用
nmap -p-扫所有端口,再用-sV深入探测。若发现某个预期组件(如数据库)未出现在初始清单中,需考虑网络隔离或服务隐藏的可能性。
9. 合规边界说明
- 使用场景:本模块的操作应用于你拥有合法授权的系统,或明确允许测试的公共目标(如
scanme.nmap.org)。 - 网络安全视角:风险在于,未经授权的端口扫描可能被视为攻击前奏或恶意行为,触发目标系统的入侵检测系统(IDS)或防火墙告警。缓解措施是严格在授权范围内操作,并使用适当的扫描速率(如
nmap -T2)以减少侵扰性。 - 决策指南:当需要了解一个未知系统的“暴露面”时,建议执行此模块。若已通过其他方式获得准确的资产清单,则可跳过此步骤,直接进行深入识别。
10. 本模块阶段性小结
我们学会了如何从混沌信息中梳理出一份需要深入探查的组件清单。现在明确了要查什么:Web 服务器、框架、数据库等。有了目标之后,下一个关键问题是:这些组件各自会留下怎样的“指纹”?下一模块将深入解析服务组件的特征结构。
探查范围界定过程示意图
三、解析服务组件特征结构
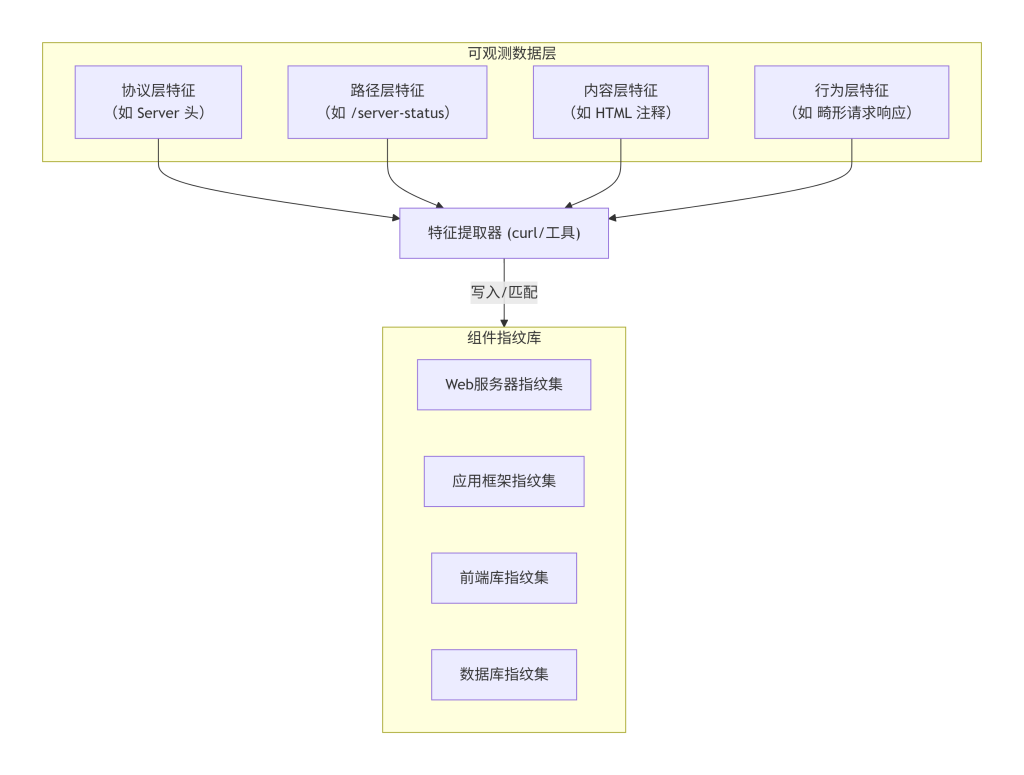
1. 模块概念解释
明确了探查目标后,需要回答一个核心问题:一个服务组件“长什么样”?即通过什么方式来“认出”它?本模块专门拆解各类组件可被观测的、独特的“指纹”特征。这些特征具体存在于网络协议交互的各个层面中,例如特定的响应头、URL 路径、HTML 代码结构、会话 Cookie 格式等。理解这些特征的来源和位置,是准确识别组件的前提。
2. 技术原理说明
服务组件在设计和实现时,会遵循特定规范或使用特定库/框架,这些“特定性”不可避免地会暴露在与其交互的网络流量中。技术原理可归纳为“实现差异的必然暴露”。
- 协议层特征:如 HTTP/1.1 vs HTTP/2,
Server头,X-Powered-By头等,是组件在协议交互中主动声明或被动暴露的。 - 路径与文件特征:许多框架或 CMS(内容管理系统)在安装后,会在特定路径下遗留特定文件(如
readme.html,phpinfo.php,wp-login.php)。访问这些路径,若得到预期响应,即可确认组件。 - 内容特征:HTML 源代码中的特定注释(
<!-- /wordpress -->)、JavaScript/CSS 文件的特定路径(/wp-content/)、特定格式的 Cookie(如.ASPXAUTH暗示 ASP.NET)等,都是组件的“烙印”。 - 行为特征:对特定输入(如畸形请求)的响应方式,也可作为特征,但通常用于更深度的研究,标准探查中较少使用。
3. 在系统中的位置
本模块是“特征识别方法”的基础原料库。它将“探查目标”(如 Web 服务器)与“可观测现象”(如 Server: nginx)关联起来。后续的“构建识别模型”,本质上是对此原料库中的特征进行提取、归纳和匹配。
4. 可执行命令或查询方式
此阶段通过构造特定请求来“提取”特征。
# 1. 提取响应头特征
curl -I http://httpbin.org/anything
# 2. 提取特定路径特征 (检查是否存在 favicon.ico,有时其hash值可识别框架)
curl -s -o /dev/null -w "%{http_code}" http://httpbin.org/favicon.ico
# 3. 提取HTML内容中的特征
curl -s http://httpbin.org/ | grep -i "generator" # 查找 generator 元标签
# 4. 提取Cookie特征
curl -I -c - http://httpbin.org/cookies/set?name=value # -c - 会输出Cookie信息5. 工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
curl | 精细提取特定请求的响应头和 Body 内容 | 灵活,可精确控制请求,易于脚本化分析 | 手动分析效率低,不适合批量提取 |
| 浏览器开发者工具 | 图形化分析页面结构、网络请求、Cookie、存储 | 直观展示,便于查看 DOM 结构和资源依赖 | 不适合自动化,依赖图形界面 |
| Burp Suite (Repeater) | 手动分析和重放请求,观察不同输入下的响应变化 | 专业的 HTTP 分析工具,可拦截、修改、重放请求 | 功能强大但学习曲线较陡,需配置代理 |
| 专用指纹识别工具 (如 wappalyzer-cli) | 批量、自动化提取和匹配常见特征 | 内置大量特征库,效率高 | 对未知或自定义组件的特征提取能力为零 |
6. 标准操作步骤
- 选定目标组件:以之前清单中的“Web 服务器”为例。
- 提取协议层特征:使用
curl -I http://test.local,重点关注Server头。bash curl -I http://test.local # 假设输出: Server: Apache/2.4.41 (Ubuntu) - 提取内容层特征:使用
curl -s http://test.local/ | grep -i "apache",查找页面中是否包含 apache 的默认页面或标识。 - 提取路径层特征:尝试访问一些常见的 Web 服务器状态页,如
/server-status(Apache) 或/nginx_status(Nginx)。bash curl -o /dev/null -w "%{http_code}\n" http://test.local/server-status # 若返回 200 或 403(而非 404),说明该路径存在,这是一个辅助特征。 - 记录特征:将所有观察到的特征(
Server头、特定路径的响应码、页面内的特定字符串)记录下来,形成该组件的特征向量。
7. 如何验证结果真实性
验证逻辑:单一特征可能被伪造或误读,多个独立来源的特征相互印证,可大大提高判断的置信度。
判断依据:
- 强特征:
Server: Apache/2.4.41是直接证据。 - 弱特征:
/server-status返回403 Forbidden(存在但禁止访问)是较弱证据,因管理员可能自定义路径。 - 综合判断:若
Server头是 Apache,/server-status返回非 404,且默认页面包含 Apache 字样,则可高置信度确认。
8. 常见错误与排查方式
- 错误:过度依赖单一特征,尤其是容易被伪造的
Server头。 - 排查:不要仅看
Server头。很多管理员会修改它以“隐藏”信息。此时需通过其他特征(如路径、文件、特定页面的 HTML 结构)综合判断。例如,即使Server头被改成Microsoft-IIS/8.5,若其响应大小写敏感行为(如/index.php和/index.Php返回不同结果)是 Linux 系统的特征,就可能存在矛盾。
9. 合规边界说明
- 使用场景:在获得授权后,对自己的应用或测试目标进行技术栈分析,用于漏洞管理、版本合规性检查或性能优化。
- 网络安全视角:风险在于,特征分析的过程本身是在收集目标系统信息,这些信息可能被恶意利用。但特征暴露是系统运行的客观事实,完全的“信息隐藏”在技术上是困难的。缓解措施是,对于生产系统,最小化暴露信息,如关闭不必要的
Server头或错误详情。 - 决策指南:当需要精确确认某个组件的具体版本时,建议执行此模块。若只需粗略了解,可使用自动化工具(如 whatweb)代替手动提取。
10. 本模块阶段性小结
现在,我们有了“组件特征清单”,知道每个组件会留下哪些痕迹。但面对未知应用,需系统化方法将这些特征组织成可复用的识别模型。下一模块将构建特征识别方法模型。
组件特征来源分层模型
四、构建特征识别方法模型
1. 模块概念解释
拥有大量“组件特征”(如 Server: nginx 是 nginx 的特征,/wp-content/ 是 WordPress 的特征)后,需要一套系统化的方法来组织、匹配和判断这些特征。本模块的目标是从“手工作坊”式的逐个特征比对,升级为“工业化”的模型化识别。我们将学习如何构建可扩展的、高效的“指纹库”和匹配逻辑,使识别过程自动化、标准化。
2. 技术原理说明
特征识别方法模型的核心是“模式匹配”。其底层逻辑是将“组件”与一组“特征规则”进行关联。典型识别模型包含两部分:
- 指纹库 (Fingerprint Database):一个结构化的数据存储,其中每条记录代表一个组件,并包含一个或多个特征规则。每条规则定义了“在什么位置(如 HTTP 头、HTML 内容、特定 URL 路径)”,“匹配什么模式(如正则表达式、字符串、状态码)”。
- 匹配引擎 (Matching Engine):程序逻辑,接收从目标系统采集的原始数据(响应头、HTML、文件列表等),遍历指纹库中的规则。当一条规则被匹配时,给对应组件增加“置信度分数”。最后,根据总分或匹配到的关键规则,判断目标上运行了哪些组件及可能版本。
3. 在系统中的位置
本模块是整个探查流程的“大脑”和“心脏”。它将“特征结构”(模块三)转化为可执行的识别逻辑。其输出(识别结果)是后续“操作流程”(模块五)的直接输入。没有这个模型,探查活动将停留在零散、非结构化的水平。
4. 可执行命令或查询方式
本模块不直接产生命令,而是理解现有工具背后的逻辑。通过分析现成的指纹识别工具(如 whatweb 或 Wappalyzer)的输出来理解其模型。
# 使用 whatweb 并启用详细输出,观察其匹配过程
whatweb --verbose http://httpbin.org你将看到类似输出(简化版):
WhatWeb report for http://httpbin.org
Status : 200 OK
Title : httpbin.org
IP : 54.xxx.xxx.xxx
Country : UNITED STATES, US
Plugins Detected:
[ Cookies ] : 有 _ga, _gid 等,可能使用了Google Analytics。
[ HTTPServer ] : 有 gunicorn
[ ... ]这里的每个 [ Plugin ] 本质上是一组特征规则。whatweb 的匹配引擎将采集到的数据与这些规则一一比对,最终汇总出检测到的插件。
5. 工具对比表
| 工具/模型 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| WhatWeb | 主动式、命令行下的 Web 指纹识别 | 插件数量庞大,匹配逻辑灵活(支持正则、版本号提取),结果详细 | 速度相对较慢,可能产生较多误报 |
| Wappalyzer | 被动式、浏览器扩展或 API 调用 | 结果简洁明了,与浏览器集成好,适合快速浏览时使用 | 覆盖范围相对 WhatWeb 小,深度不够 |
| BuiltWith | 在线/API 服务,专注于技术栈分析 | 数据全面,能识别很多第三方服务、分析工具、CDN 等 | 依赖其云端数据库,有隐私风险,部分功能付费 |
| 自建指纹库 + 匹配脚本 | 针对特定内部应用或框架进行定制化识别 | 高度可控,精准匹配内部特有组件 | 开发成本高,需持续维护指纹库 |
6. 标准操作步骤(以理解 WhatWeb 的模型为例)
- 选择目标:
http://test.local - 运行基础识别:
whatweb http://test.local,获取概要报告。 - 启用详细模式:
whatweb --verbose http://test.local > whatweb_verbose.log,将详细输出保存到文件。 - 分析日志:打开日志文件,寻找
[:]标记。每个被检测到的插件名后面,通常会跟着匹配到的具体特征。例如:HTTPServer [ : Apache (2.4.41) ] : Apache: Server header: Apache/2.4.41 (Ubuntu)
这行日志揭示了HTTPServer插件的识别过程:它匹配到了Server头中的字符串,并从中提取了版本号2.4.41。 - 归纳模型:通过此分析,理解 WhatWeb 的模型:它有一个名为
HTTPServer的插件,包含一条规则:“检查响应头中Server字段的值,若包含Apache,则报告HTTPServer组件,并尝试用正则表达式Apache/([\d.]+)提取版本号。”
7. 如何验证结果真实性
验证逻辑:验证识别模型的准确性,需通过“已知样本”测试。
判断依据:
- 正样本测试:在已知运行 Apache 的测试机上运行
whatweb,看能否正确识别出 Apache 及其版本。若正确,说明模型中的 Apache 指纹规则有效。 - 负样本测试:在已知运行 Nginx 的测试机上运行
whatweb,确保不误报为 Apache。若误报,说明规则区分度不够,需优化。 - 交叉验证:将
whatweb的识别结果与模块三手动提取的特征对比,看是否一致。
8. 常见错误与排查方式
- 错误:模型过拟合或欠拟合。即指纹规则过于严格(一点小差异就匹配不上)或过于宽泛(把其他组件也匹配进来)。
- 排查:当发现误报或漏报时,需调整指纹库规则。例如,若
Server: Apache被改成Server: Custom-Server,依赖Server头的模型就会失效。此时需在模型中增加新规则,如检查/manual路径是否存在(Apache 的常见文档路径)。
9. 合规边界说明
- 使用场景:构建和维护内部资产指纹库,用于自动化资产发现和版本管理,是 DevSecOps 实践中的一环。
- 网络安全视角:风险在于,一个过于精确和强大的指纹库若落入攻击者手中,会成为高效攻击的帮凶。因此,指纹库本身是需要保护的敏感资产。缓解措施是,对指纹库的访问进行严格权限控制。
- 决策指南:当需要定期、自动化地对大规模资产进行技术栈盘点时,建议构建或引入此类特征识别模型。若只是偶尔、临时地分析一两个站点,使用现成自动化工具即可,无需自建模型。
10. 本模块阶段性小结
我们完成了探查能力的“大脑”建设,理解了如何系统化地组织和匹配特征。现在有了思维模型和工具,接下来需将其串联成一套标准化的、可重复执行的探查操作流程。下一模块将制定从采集到验证的完整路径。
特征识别模型架构图

五、形成探查操作流程路径
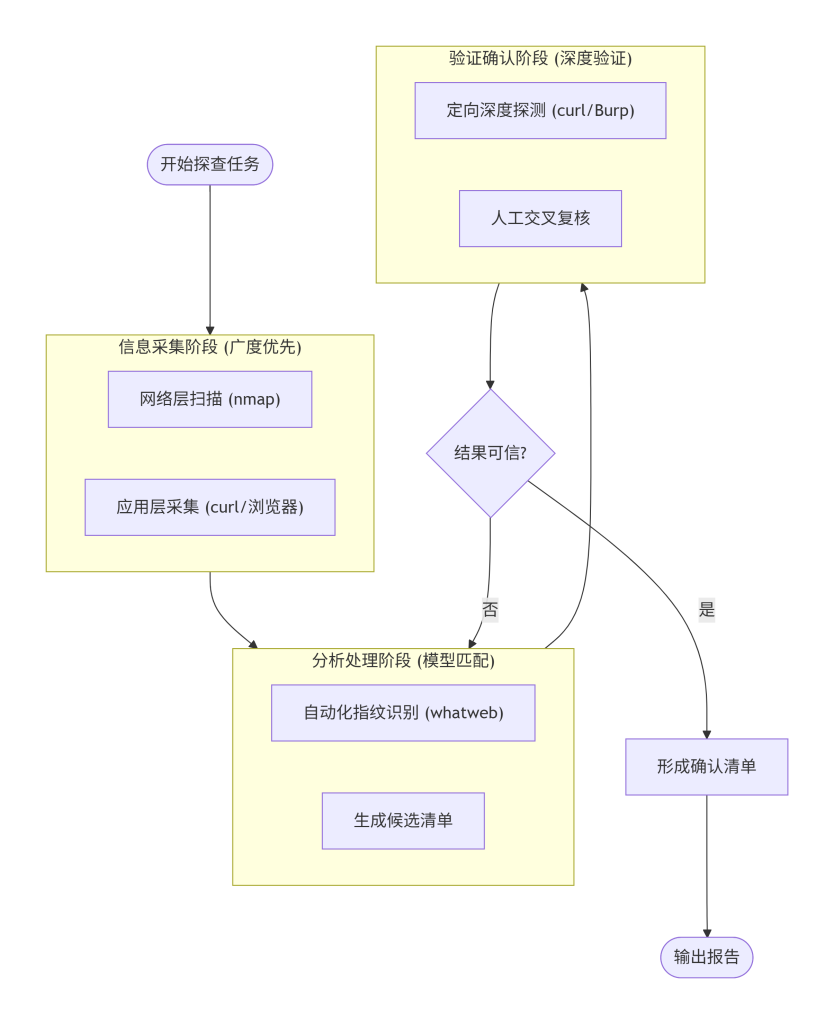
1. 模块概念解释
本模块解决“如何一步步做”的问题。在前几个模块中,我们分别学习了认知、目标、特征和模型。现在需要将这些零散的“知识点”和“工具点”串联成一个连贯的、闭环的工程化操作流程。该流程将指导你从接到探查任务开始,到最终拿到可靠结果为止,每一步做什么、用什么工具、如何决策,均有章可循。
2. 技术原理说明
标准探查流程遵循“信息采集 -> 分析处理 -> 验证确认”的闭环逻辑。其底层原理是逐步收敛的决策树。
- 信息采集阶段:通过被动(如监听网络流量)或主动(如发送探测包)方式,获取目标系统的原始响应数据。广度优先,目标是“尽可能多地获取”。
- 分析处理阶段:将原始数据输入“特征识别模型”(模块四),利用指纹库进行模式匹配,将数据转化为“候选组件列表”。此时可能有多个候选,且置信度不一。
- 验证确认阶段:针对“候选组件列表”中置信度不高或关键的组件,进行定向的、深度的二次探测,使用模块三中学到的手工提取特征方法,对自动化结果进行人工核实,最终形成高置信度的“确认组件清单”。
3. 在系统中的位置
本模块是整个课程的操作核心,是前三个模块(认知、目标、特征)知识的综合运用,也是后两个模块(风险控制、结果整合)的实践基础。它将理论知识落地为可执行的动作,是连接“知道”和“做到”的桥梁。
4. 可执行命令或查询方式
将整个流程串起来,形成一套连贯的命令序列。
# 1. 信息采集阶段
# 1.1 端口扫描 (广度)
nmap -p- --min-rate 1000 -oN nmap_ports.txt test.local
# 1.2 服务版本探测 (深度)
nmap -sV -p $(grep open nmap_ports.txt | cut -d'/' -f1 | tr '\n' ',') -oN nmap_versions.txt test.local
# 1.3 基础Web信息采集 (使用curl或httpx)
curl -I http://test.local > curl_headers.txt
curl -s http://test.local > curl_body.html
# 2. 分析处理阶段
# 2.1 运行自动化指纹识别
whatweb -a 3 http://test.local > whatweb_result.txt
# 2.2 使用工具分析HTML (例如,提取所有引用的JS/CSS)
grep -Eoi 'src="[^"]+"|href="[^"]+"' curl_body.html | grep -E '\.js|\.css' > resources.txt
# 3. 验证确认阶段
# 3.1 针对 whatweb 报告的疑似 Apache 版本,验证 /server-status
curl -o /dev/null -w "HTTP Code: %{http_code}\n" http://test.local/server-status
# 3.2 针对 whatweb 报告的疑似 PHP,验证 phpinfo() 文件
curl -L http://test.local/phpinfo.php | grep -i "php version" || echo "phpinfo.php not found"
# 3.3 验证发现的 JS 库版本 (例如,检查 jquery.js 的内容)
curl -s http://test.local/static/jquery.min.js | head -n 55. 工具对比表
| 流程阶段 | 推荐工具 | 备选工具 | 核心任务 |
|---|---|---|---|
| 信息采集 (网络层) | nmap | masscan (极速扫描), rustscan (高效) | 发现开放端口和服务 |
| 信息采集 (应用层) | curl, httpx | Burp Suite (手动), Chrome DevTools | 获取响应头、HTML、资源列表 |
| 分析处理 | whatweb, wappalyzer-cli | 自写 Python 脚本 (结合 requests 和 re 库) | 自动化指纹匹配,生成候选清单 |
| 验证确认 | curl, Burp Suite Repeater | 浏览器手动访问 | 针对候选清单进行人工核实,排除误报 |
6. 标准操作步骤
- 任务接收与范围确认:明确目标为
test.local,确认拥有测试授权。 - 网络层信息采集:执行
nmap -p- -sV -T4 test.local -oA nmap_testlocal,将结果保存。 - 应用层信息采集:在浏览器中访问
http://test.local,打开开发者工具,查看网络请求。同时使用curl保存首页 HTML 和响应头。 - 自动化分析:运行
whatweb -a 3 http://test.local,记录其输出。 - 初步结果整理:将
nmap的-sV结果和whatweb的结果合并,形成初步组件清单,标注置信度(高/中/低)。 - 深度验证:针对清单中的每个组件,尤其是置信度为“中”的,使用
curl构造特定请求(如访问特定路径、检查特定文件 hash)进行验证。例如,若whatweb报告可能为 Drupal,则尝试访问/CHANGELOG.txt。 - 结果确认与记录:将验证后的结果更新到清单,并记录验证过程和判断依据。最终输出一份《test.local 应用技术栈分析报告》。
7. 如何验证结果真实性
验证逻辑:整个流程的最终结果需通过“可复现的、多角度的证据链”证明其真实性。
判断依据:
- 证据链:最终结论不能孤立。例如,结论为“Apache 2.4.41”。证据链应包括:
nmap -sV报告了 Apache 2.4.41,curl -I的Server头与之匹配,且/server-status路径存在且返回 403,与 Apache 默认行为一致。 - 可复现性:相同条件下重复执行步骤 3-6,应能得到相同或相近结论。
- 逻辑一致性:所有组件的结论应逻辑自洽。例如,识别出后端是 ASP.NET,但
Server头却是nginx,并不矛盾,可能 nginx 是反向代理,背后是 IIS,反而揭示更复杂架构。
8. 常见错误与排查方式
- 错误:跳过验证确认阶段,完全信任自动化工具结果。
- 排查:当后续操作(如漏洞利用)基于错误识别结果失败时,应回溯至此流程。重新执行步骤 6,手动验证工具输出。例如,若
whatweb报告了错误的 CMS 版本,导致后续利用的 EXP 无效,手动验证版本文件(如readme.html)即可发现问题。
9. 合规边界说明
- 使用场景:此流程应用于开发环境测试、内部资产盘点,以及获得授权的渗透测试项目中。
- 网络安全视角:风险在于,流程中的主动扫描(特别是
nmap全端口扫描和whatweb的 aggressive 模式-a 3)可能对老旧或脆弱系统造成压力,甚至引发拒绝服务。缓解措施是,在非生产环境或业务低峰期进行,并根据目标重要性调整扫描速率和强度。 - 决策指南:当需要全面、系统地了解应用的技术构成时,建议遵循此流程。若只需快速确认已知信息(如验证某个组件版本),可跳过采集阶段,直接执行验证步骤。
10. 本模块阶段性小结
我们拥有了一套完整的、可重复的探查操作流程。通过此流程,可以系统地获取应用的技术栈信息。但在实际操作中,可能遇到各种干扰因素,如 WAF(Web 应用防火墙)、扫描速率限制,以及法律授权边界。下一模块将解决如何控制这些风险,确保探查活动的安全与合规。
标准化探查操作流程闭环图
六、控制探查活动风险边界
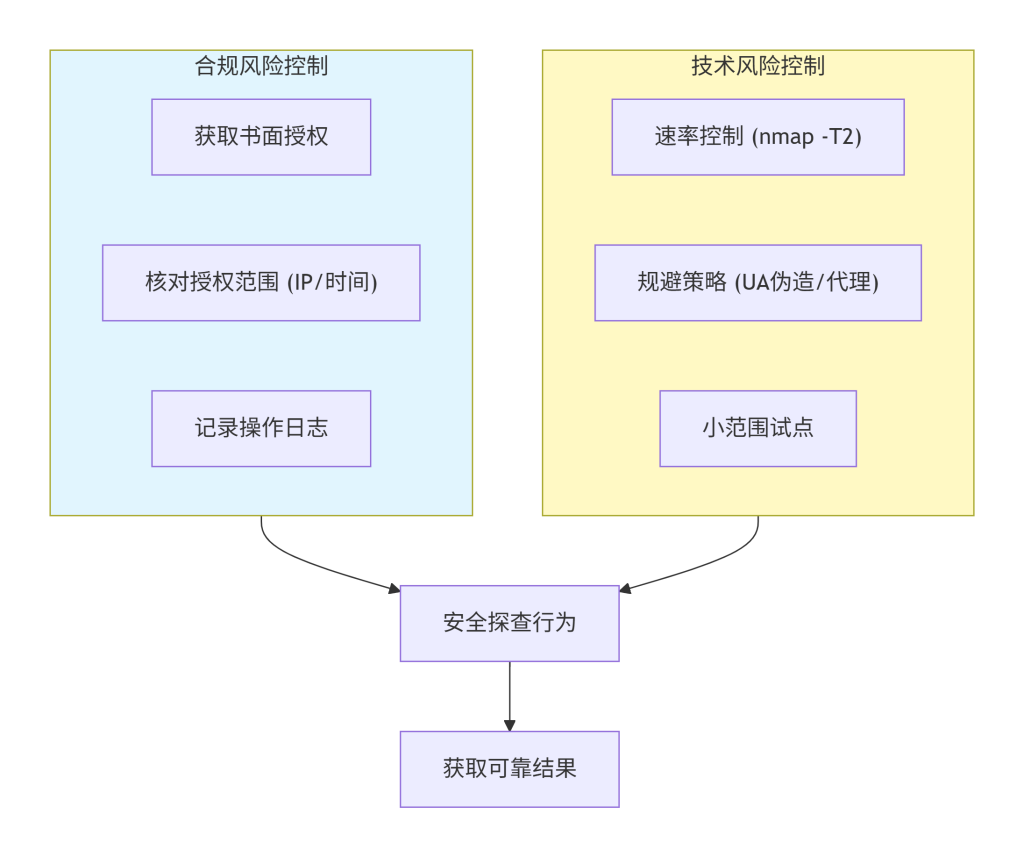
1. 模块概念解释
探查活动如同在未知海域航行,既有暗礁(技术干扰),也有领海基线(法律边界)。本模块的核心任务是识别并管理探查过程中可能遇到的各种风险,包括技术层面的风险(如触发防护系统、影响业务稳定性),以及合规层面的风险(如越权操作、法律纠纷)。目的是确保探查活动在可控、安全、合法的范围内进行。
2. 技术原理说明
风险控制的原理基于“最小干预”和“授权确认”。
- 技术风险控制:核心是“速率控制”和“规避策略”。主动扫描会产生大量流量和请求,可能被 IDS/IPS(入侵检测/防御系统)检测为攻击,或耗尽目标资源。因此,需控制发包速率(如
nmap -T2),必要时使用代理或分布式扫描分散流量。同时,识别并绕过简单的 WAF 规则,避免因触发封锁而导致后续请求被拒绝。这并非为了攻击,而是为了在授权范围内完成完整评估。 - 合规风险控制:核心是“授权书”和“边界确认”。所有探查活动必须有明确的、书面的授权,明确授权范围(哪些 IP、哪些端口、哪些时间段)。这是区分安全评估与网络犯罪的唯一界限。
3. 在系统中的位置
本模块是一个“安全护栏”和“质量控制环”,贯穿于整个探查流程始终。它不产生直接探查结果,但指导和约束所有探查行为。从模块二的“界定范围”开始,到模块五的“操作流程”,均需在本模块的风险控制原则下进行。
4. 可执行命令或查询方式
此处的命令演示如何“控制”风险,而非“造成”风险。
# 1. 技术风险控制:限制扫描速度 (使用 nmap 的 -T 参数和 --max-rate)
# -T0 (偏执的) 到 -T5 (疯狂的),通常 -T2 (礼貌的) 或 -T3 (普通的) 用于常规评估
nmap -sV -T2 --max-rate 50 scanme.nmap.org
# 2. 技术风险控制:使用伪造的 User-Agent 以减少被WAF封锁的概率 (curl)
curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36" -I http://test.local
# 3. 技术风险控制:通过代理进行扫描,隐藏真实源IP (nmap)
# 假设有一个 SOCKS5 代理在 127.0.0.1:1080
# nmap 本身不支持 SOCKS,但可使用 proxychains
# proxychains nmap -sT -Pn -p 80,443 test.local
# 4. 合规风险控制:在开始任何工作前,将授权书和范围定义写在项目记录中 (无命令,此为流程)
echo "Authorization received for scanning test.local from 2024-01-01 to 2024-01-31. Scope: 10.0.0.0/24, ports 1-65535." > authorization_record.txt5. 工具对比表
| 控制类型 | 工具/方法 | 优点 | 局限 |
|---|---|---|---|
| 扫描速率控制 | nmap -T<0-5>, --max-rate | 内置于nmap,简单有效 | 对时间敏感的扫描(如漏洞扫描)效果差 |
| 源IP隐藏 | proxychains + 代理 | 可有效隐藏真实IP,绕过基于IP的封锁 | 配置复杂,可能降低扫描速度,部分协议不支持 |
| User-Agent 伪造 | curl -A, wget -U | 简单,能绕过最基础的 WAF 检查 | 无法绕过基于行为分析的 WAF |
| 延迟/抖动 | nmap --scan-delay <time> | 使扫描流量更像人工访问,降低 IDS 告警概率 | 极大增加扫描时间 |
| 授权管理 | 书面授权书、邮件确认 | 法律层面的唯一有效凭证 | 无法控制技术风险,依赖于人的合规意识 |
6. 标准操作步骤
- 获取并确认授权:进行任何扫描前,必须获得目标系统所有者或管理员的明确书面授权,并仔细核对授权范围(IP、域名、测试时间)。
- 制定风险控制计划:根据目标重要性(生产环境、测试环境),选择扫描速率。对生产系统,采用
-T2或--max-rate 50;对测试环境,可采用更快的-T4。 - 配置规避策略:在
curl或扫描器配置中,设置合理的User-Agent,避免使用默认的、易被识别的 UA。 - 小范围试点:不要一开始就对整个 IP 段大规模扫描。先选取一个 IP 或端口进行探测,观察目标反应,确认未触发封锁或告警后,再逐步扩大范围。
- 持续监控:扫描过程中,监控扫描工具的反馈。若出现大量超时或连接拒绝,可能触发了目标防护,应立即暂停扫描,分析原因。
- 记录所有操作:详细记录扫描的起止时间、使用的命令、扫描的目标范围,以备合规审查。
7. 如何验证结果真实性
验证逻辑:验证风险控制措施是否有效,并非看“是否成功攻击”,而是看“是否成功避开防御且完成了任务”。
判断依据:
- 速率控制有效:扫描结束后,检查目标服务器的访问日志。若请求间隔均匀且频率较低,未形成明显访问峰值,说明速率控制有效。
- 规避策略有效:若整个扫描过程中,未触发任何来自目标系统的“访问被拒绝”或“IP被封”提示,且成功获取了所需信息,说明当前规避策略暂时有效。
- 合规性验证:有明确的授权记录,且扫描记录(IP、时间)完全在授权范围之内。
8. 常见错误与排查方式
- 错误:过度依赖技术规避,而忽视合规授权。
- 排查:一旦收到目标系统的投诉或警告,应立即停止所有活动。首要检查授权书。若无授权,一切技术讨论均无意义。若有授权,应联合法务与对方沟通,明确授权的合法性。
- 错误:扫描速率设置过低,导致扫描时间过长,影响项目进度。
- 排查:平衡风险与效率。若项目紧急且目标非核心系统,可适当提高速率,或采用分布式扫描,用多台机器分担任务。
9. 合规边界说明
- 使用场景:所有涉及向目标系统发送非正常业务流程产生的数据包的行为,均需执行本模块的风险控制流程。
- 网络安全视角:风险是双向的。对目标系统的侵入性测试是风险;对我们自身而言,未经授权的扫描行为也使我们面临法律风险和职业声誉风险。缓解措施是严格遵守“授权为先”原则。
- 决策指南:
- 何时必须用?:任何时候,只要探查活动可能对目标系统造成影响(包括产生日志),或在非你 100% 拥有的网络/系统上进行。
- 何时可放宽?:当目标是你完全拥有和控制的本地虚拟机,且与外界网络隔离时,可适当放宽风险控制(如使用
-T5),但仍建议保持良好的记录习惯。
10. 本模块阶段性小结
在学会“如何做”之后,我们又掌握了“如何安全、合规地做”。风险控制确保了探查活动的专业性和负责任。现在,我们能够安全、系统地获取关于应用架构的准确信息。下一模块将整合探查结果与策略输出,将信息转化为决策。
探查活动双向风险控制模型
七、整合探查结果与策略输出
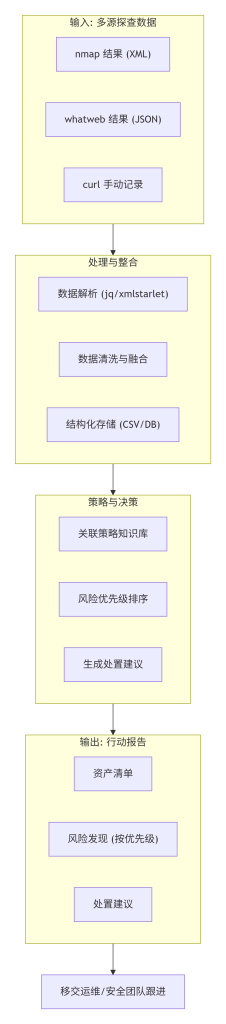
1. 模块概念解释
探查的最终目的并非得到一份技术清单,而是指导后续决策和行动。本模块的核心任务是将前六个模块产生的零散信息(端口、服务、版本、框架、中间件)进行整合、清洗、结构化,形成有商业价值的“应用技术栈清单”。更重要的是,将这份清单与特定的“后续行动策略”关联,例如:发现过期组件版本应升级,发现不安全配置应加固,发现未知开放端口应核查。将“信息”转化为“决策”,完成工程闭环。
2. 技术原理说明
本模块的核心是“信息关联”与“策略映射”。其底层逻辑是一个决策支持系统。
- 信息结构化:将探查结果(如
nmap的 XML 输出、whatweb的 JSON 输出)解析并存储到统一数据库中。每条记录应包含:组件名称、版本、发现位置(IP/URL)、置信度、发现时间等。 - 策略映射:建立“组件-策略”知识库。例如,知识库定义:“若 Apache 版本 < 2.4.50,则建议升级”。当探查结果中有 Apache 2.4.41 时,系统自动关联出“升级”策略。
- 优先级排序:并非所有问题均需立即处理。根据资产的业务重要性、组件的风险等级(如高危漏洞、是否暴露在公网),对关联出的策略进行优先级排序,生成可执行的行动路线图。
3. 在系统中的位置
本模块是整个探查流程的终点,也是后续所有安全或运维工作的起点。它完成了从“数据”到“信息”再到“知识”的升华,为漏洞管理、配置管理、攻击面管理等提供精准输入。
4. 可执行命令或查询方式
此阶段更多涉及数据处理和报告生成。
# 1. 将 nmap 结果转换为可处理的格式 (例如 XML)
nmap -sV -oX nmap_results.xml test.local
# 2. 使用工具解析 XML 并提取关键信息 (使用 Python 脚本或命令行工具如 xmlstarlet)
# 使用 xmlstarlet 提取开放的端口和服务
xmlstarlet sel -t -m "//port[state/@state='open']" -v "concat(@portid, '/', service/@name)" -n nmap_results.xml
# 3. 将 whatweb 的结果以 JSON 格式输出,便于程序解析
whatweb --log-json=whatweb_results.json http://test.local
# 4. 模拟一个简单的策略关联 (伪代码,需用 Python 等实现)
# 假设我们有一个 vulnerability_db.json 包含版本漏洞信息
# python -c "
# import json
# with open('nmap_results.xml') as f: ...
# # 伪逻辑: 若端口80服务是apache,版本2.4.41,则在vuln_db中查找对应风险
# print('Apache 2.4.41 存在多个已知漏洞,建议升级至 2.4.50 以上')
# "
# 5. 生成最终报告
echo "生成 Markdown 或 HTML 格式的整合报告,包含资产清单、风险等级、处置建议。"5. 工具对比表
| 工具/方法 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| 手动整理 (Excel/记事本) | 临时、小规模、一次性的探查任务 | 简单直观,无需学习新工具 | 效率低,易出错,无法自动化,不适合规模化 |
nmap + grep/awk | 快速从文本输出中提取信息 | 快速,利用现有命令行工具 | 处理复杂的 XML/JSON 能力弱,逻辑表达能力有限 |
专业解析工具 (xmlstarlet, jq) | 从结构化数据 (XML, JSON) 中提取信息 | 强大,专为数据解析设计,适合脚本化 | 需要学习新的命令语法 |
| 安全运营平台/资产管理平台 (如 Archery, CMDB) | 企业级、持续化的资产管理与风险跟踪 | 自动化、可视化、流程化,可与漏洞库联动 | 部署和维护成本高,适用于大型组织 |
| 自写脚本 (Python + Pandas) | 定制化分析、复杂数据关联、报告生成 | 最灵活,可满足任何定制化需求 | 开发成本高,对编程能力有要求 |
6. 标准操作步骤
- 数据汇总:收集模块五中产生的所有原始数据文件:
nmap_ports.txt,nmap_versions.xml,whatweb_result.json,curl_headers.txt。 - 数据结构化:使用 Python 脚本(或
jq+xmlstarlet)将所有数据解析,合并到一个统一表格中。例如,CSV 文件,列名包括:IP,端口,协议,服务名,服务版本,Web服务器,应用框架,前端库等。 - 数据清洗与去重:处理不同工具间可能出现的矛盾信息(如版本不一致)。例如,若
nmap报告的 Apache 版本是 2.2.22,而whatweb报告的是 2.2.22 (Ubuntu),应以更详细的whatweb结果为准,并记录矛盾点。 - 关联风险与策略:将清洗后的清单与预定义的策略知识库(可以是简单的
if-else列表或漏洞数据库)进行比对。例如:若 (服务名 == 'openssh' and 版本 < '7.5') 则 输出 "建议升级 OpenSSH"若 (Web服务器 == 'Apache' and 版本 in list_of_vulnerable_versions) 则 输出 "建议 Apache 打补丁或升级"
- 生成整合报告:将最终结构化清单和关联出的策略建议,整理成易读的报告。报告应包含:执行摘要、详细资产清单、风险发现(按严重性排序)、具体处置建议。
- 结果存档与移交:将原始数据、处理脚本、最终报告一并存档,并移交给相关团队(如运维、开发、安全)跟进处理。
7. 如何验证结果真实性
验证逻辑:验证最终输出的报告是否准确反映目标系统的真实情况,且提出的策略是否合理。
判断依据:
- 准确性验证:随机抽取报告中的 3-5 条关键信息,回到目标系统上,使用模块三的手动验证方法复核。若全部匹配,则报告准确度较高。
- 策略合理性验证:与系统管理员或开发人员开会评审报告中的处置建议。例如,建议升级某个库,但该库可能因兼容性问题无法升级。此讨论本身即能验证策略在特定业务环境下的合理性。最终策略需结合业务实际调整。
8. 常见错误与排查方式
- 错误:只罗列数据,不提供策略。报告仅是一份技术清单,未告知读者“这代表什么风险”及“接下来该怎么做”。
- 排查:在报告编写阶段,强制为每个发现的组件或版本思考其业务或安全含义。即使无自动化策略库,也应在报告中加入“备注”或“建议”列,写下人工判断的初步意见。
- 错误:忽略结果的上下文。例如,报告了一个开放的 Redis 数据库端口,但未说明它是绑在公网 IP 上还是内网 IP 上,导致策略建议失准(公网应强制下线,内网则可能只需加固访问控制)。
9. 合规边界说明
- 使用场景:本模块适用于任何需要将技术发现转化为业务决策的场景,如安全风险评估报告、系统上线前安全检查、季度资产盘点报告。
- 网络安全视角:风险在于,一份详细、准确的报告本身就是高度敏感信息。若报告泄露,等于为攻击者提供了一份详尽的“攻击路线图”。因此,报告的存储、传输和分发必须严格遵守数据保密规定,进行加密和权限控制。
- 决策指南:
- 何时必须用?:在任何需要向非技术人员(如管理层、客户)汇报探查成果时,建议进行整合与策略输出。在需要驱动后续加固或修复工作时,也必须执行此步骤。
- 何时可跳过?:若探查活动仅作为个人技术练习,或用于临时调试自己的程序,那么只需原始数据即可,无需整合输出。
10. 本模块阶段性小结
至此,我们完成了整个“应用服务探查能力”的闭环。从建立认知框架开始,学会界定目标、解析特征、构建模型、形成流程、控制风险,最终将信息整合为可指导行动的策略。这七项能力不仅教会了工具使用,更重要的是塑造了作为安全工程师或运维开发人员的专业思维方式——一种系统性、工程化、负责任的解决问题的方法。希望这套方法论能成为你技术工具箱中的核心支柱。
探查结果整合与策略输出流程
参考与进一步阅读
- Nmap Reference Guide: 本文中所有
nmap命令(端口扫描、版本探测、扫描速率控制)的主要依据。 - curl Documentation: 本文中所有
curl命令(查看响应头、提取特征、User-Agent 伪造)的官方参考。 - WhatWeb Project: 本文中
whatweb指纹识别工具及其详细模式分析的功能来源。 - IETF RFC 1035 – Domain Names – Implementation and Specification: DNS 基础协议(
dig命令)的权威定义。 (核心行为自 1987 年以来未发生重大变化) - RFC 9619 – In the DNS, QDCOUNT Is (Usually) One: DNS 协议最新更新,确认了
dig等查询行为的协议标准。 - Proxychains Project: 本文中通过代理隐藏源 IP 的
proxychains工具来源。建议读者访问官方最新文档以确认当前环境兼容性。