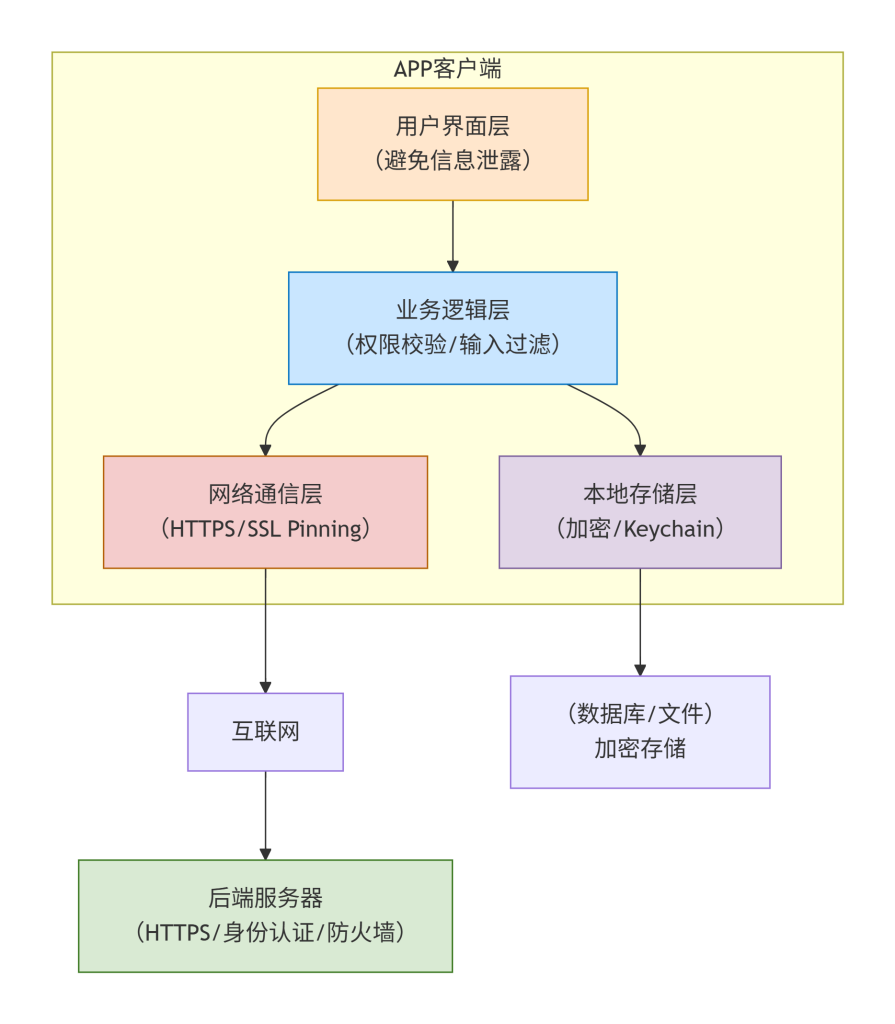
信息收集-Web应用-机构产权&域名相关性
基于产权关联的域名资产收集方法论
一、梳理基础认知
模块概念解释(为什么做)
传统的资产收集,往往是“点对点”的,即知道一个域名,就去解析它的IP,查找它的子域名。但这种方法存在盲区:一个机构可能拥有多个与主品牌无关的域名(如用于不同业务线、子公司、市场活动)。如果我们只盯着已知的主域名,就永远无法发现这些“隐形”资产。
本模块的核心在于重构认知:将网络资产(域名)与其背后的法律实体(机构产权)进行强绑定。通过梳理产权关系,我们才能建立一个完整的资产收集边界,确保我们发现的每一个域名,都能在法律和商业逻辑上归属于目标机构。
技术原理说明(底层逻辑)
域名系统的管理和注册机制,天然地与产权信息相关联。这种关联体现在以下几个层面:
- 注册人信息 (Registrant Info):根据ICANN的规定,每个域名注册时必须提供真实、准确的注册人信息,包括名称、邮箱、电话、地址等。这是产权映射最直接的证据。
- 域名服务器 (Name Server):机构通常会使用自建或第三方(如DNS解析服务商)的DNS服务器。同一个机构的多个域名,往往会指向相同的一组DNS服务器。这是技术层面的关联特征。
- WHOIS数据:这是一个公开的查询协议和数据库,存储了所有域名的注册信息、联系方式、名称服务器、注册和到期日期等。它是连接产权信息和域名资产的核心桥梁。
- IP地址与ASN:机构通常会拥有或租用一段IP地址范围,并可能拥有自己的自治系统号(ASN)。域名解析到的IP,如果落在该机构的IP段内,也是一种间接的产权证据。
产权-域名映射关系图

本模块小结
本模块奠定了理论基础,让我们明确“产权”是资产收集的起点和边界,理解了通过WHOIS、DNS等公开数据源,可以将抽象的“产权”转化为具体的、可查询的网络资产“线索”。
二、界定收集边界
模块概念解释(为什么做)
在开展信息收集前,必须明确“收集谁”的问题。产权关系往往是复杂的树状或网状结构。不加区分地收集会导致信息爆炸且偏离目标,而边界过窄则可能导致资产遗漏。本模块旨在教您如何科学地界定目标机构的产权边界,从而确定资产收集的任务范围。
技术原理说明(底层逻辑)
界定产权边界,需要综合利用商业情报(公开的)和法律实体信息。
- 官方披露:目标机构的官网“关于我们”、“投资关系”等页面,通常会披露其子公司、分公司、关联公司或品牌。
- 商业查询平台:使用天眼查、企查查、OpenCorporates等平台,可以查询到目标公司的“对外投资”、“分支机构”、“疑似关系”(如相同法人、相同注册电话/地址)。这些是界定产权边界的核心依据。
- 股权结构分析:根据评估目标,设定产权穿透的层级(如:一级子公司、全资子公司、控股子公司等)。
可执行命令或查询方式(示例)
# 假设使用某个聚合数据API(仅为示例,实际需替换为具体平台API)
# 查询目标公司“某科技集团”的对外投资企业
# curl -X GET "https://api.qichacha.com/eciv4/getInvestment?key=YOUR_KEY&companyName=某科技集团"
# 实际执行时需替换为合法的API密钥和请求格式
echo "商业查询通常通过Web界面或官方API完成,此处仅为示意。"Web查询方式:在企查查搜索“某科技集团”,进入公司详情页,点击“对外投资”或“分支机构”标签,记录下所有子公司、分公司名称。
常见工具对比(表格形式)
| 工具名称 | 数据源 | 优点 | 缺点 | 适合场景 |
|---|---|---|---|---|
| 天眼查/企查查 | 工商信息、公开财报、司法诉讼 | 数据全面,关系图谱直观,操作简单 | 免费版限制多,部分信息可能滞后,需付费 | 快速梳理目标公司的国内工商关联关系 |
| OpenCorporates | 全球多个国家的官方商业登记机构 | 全球覆盖,数据权威性高,API开放 | 界面相对简陋,国内数据不如本土工具丰富 | 查询跨国公司的海外关联实体 |
| Bloomberg/Reuters | 金融数据、深度研究报告 | 数据深度大,可获取股权结构、母公司信息 | 专业付费工具,使用门槛高 | 金融级尽职调查,复杂股权结构分析 |
| 目标官网 | 公司年报、投资者关系页面 | 一手信息,权威性最高 | 信息分散,需要人工阅读和分析 | 作为所有查询结果的最终验证和补充 |
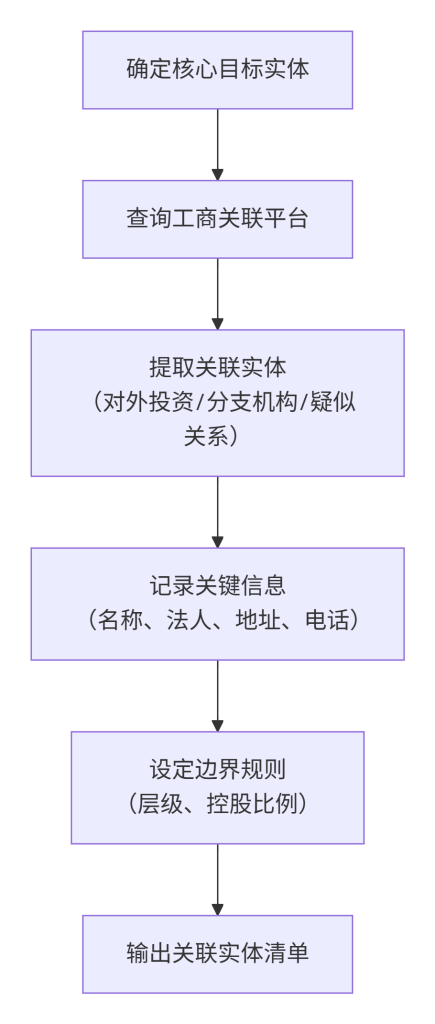
标准操作步骤
- 确定核心目标实体:明确本次任务的直接目标机构名称。
- 查询工商关联:在商业查询平台搜索该实体,进入其主页。
- 提取关联实体:逐一查看“对外投资”、“分支机构”、“疑似关系”等板块,筛选出符合任务要求的关联实体。创建一个名为
关联实体清单.txt的文件。 - 记录关键信息:在清单中,除了记录关联实体全称,还需记录其法人代表、注册地址、联系电话等信息,这些信息后续可作为WHOIS查询的线索。
- 设定边界规则:与团队或任务发起方确认,本次收集的产权边界是仅限于核心实体,还是包括一级子公司、所有控股公司等。
界定收集边界流程图
如何验证结果真实性
- 交叉验证:将平台A查到的关联公司,在平台B进行反向查询,看是否能查到与核心目标的关联关系。
- 官网验证:在核心目标机构的官网年报或投资者关系文档中,查找其列示的子公司清单,与商业平台的结果进行比对。
常见错误及排查方式
- 错误:将所有“疑似关系”都纳入边界,导致范围过大。
排查:仔细分析“疑似关系”的来源,判断是真实的关联公司,还是仅仅是代理注册公司引起的“误报”。可以结合业务逻辑进行判断。 - 错误:遗漏了重要的海外子公司。
排查:对于大型跨国企业,务必使用OpenCorporates等国际平台进行补充查询。
合规边界说明
所有操作均基于公开的工商信息查询平台,这些平台的数据来自国家官方公示系统,属于合法公开信息。严格遵守各商业查询平台的使用条款,不使用爬虫进行大规模、高频率的数据抓取。
本模块小结
本模块教会我们如何利用公开的商业情报,从单一目标实体出发,科学地界定出一个包含其关联实体的“产权清单”,这为下一步的域名发现划定了清晰的“狩猎范围”。
三、拆解映射结构
模块概念解释(为什么做)
有了“关联实体清单”,下一步需要思考如何将这些法律实体名称,转化为具体的网络资产线索。这个过程就像是一个“翻译”工作,将商业世界的“公司名”,映射到网络世界的“域名”。本模块将拆解这个映射过程的几种典型模式。
技术原理说明(底层逻辑)
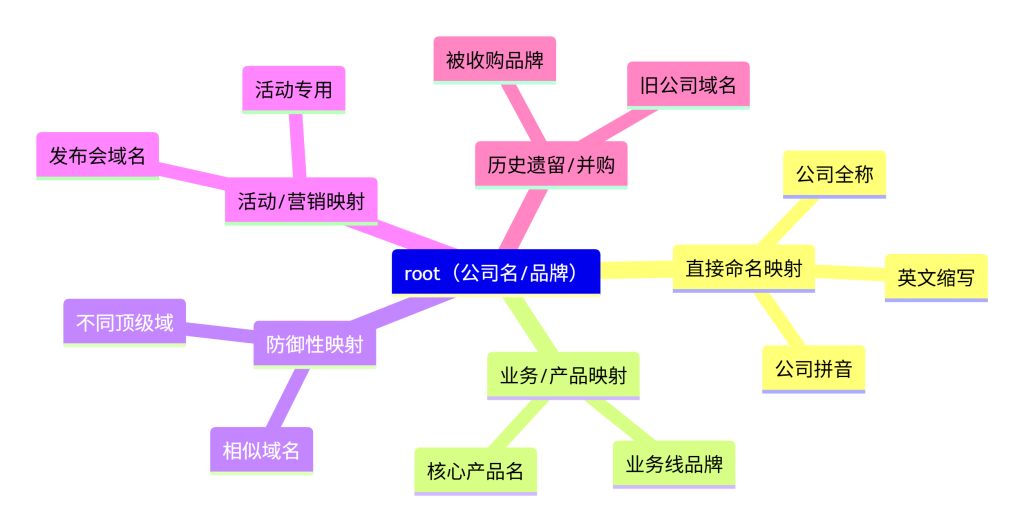
一个实体与域名的关联模式可以归纳为以下几种:
- 直接命名映射:最直观的模式。域名直接使用公司名称的拼音、英文缩写、全称或核心品牌。例子:alibaba.com。
- 业务/产品映射:针对公司旗下的特定业务线或产品品牌注册的独立域名。例子:taobao.com, aliyun.com。
- 防御性/保护性映射:为了防止品牌被混淆或恶意利用,注册的与主域名相似的域名。例子:gogle.com, googlr.com。
- 活动/营销映射:为短期市场活动或特定项目注册的独立域名。例子:newphone-launch.com。
- 历史遗留/并购映射:公司历史上注册,或并购其他公司时获得的域名。
域名映射模式分类图
可执行命令或查询方式(示例)
此模块偏重思维模式,命令示例在后一模块中体现。此处可以给出生成“可能域名列表”的逻辑示例。
# 伪代码示例:从公司名生成可能的域名列表
company_name = "某某网络技术有限公司"
core_words = ["moumou", "mm", "mouwang"] # 手动或通过分词提取
tlds = [".com", ".cn", ".com.cn", ".net", ".org"]
possible_domains = []
for word in core_words:
for tld in tlds:
possible_domains.append(word + tld)
print(possible_domains)常见工具对比(表格形式)
| 工具/方法 | 作用 | 优点 | 缺点 |
|---|---|---|---|
| 脑暴/思维导图 | 梳理品牌、业务线、产品名 | 系统性思考,不容易遗漏 | 依赖人工经验,效率较低 |
| 域名生成工具 | 根据关键词批量生成域名组合 | 高效,可结合字典进行组合 | 可能会生成大量无意义域名 |
| 品牌监控服务 | 查看某品牌相关的域名注册情况 | 实时性高,可发现新注册的防御域名 | 通常为付费服务 |
标准操作步骤
- 提取核心词汇:针对“关联实体清单”中的每一个实体,提取其核心词。
- 识别核心品牌:通过官网、新闻稿、招聘信息等,识别该实体旗下的所有品牌和产品名。
- 构建映射模式:针对每个核心词和品牌,思考可能的域名组合模式,如:[品牌].com、[品牌]-official.com等。
- 形成候选列表:将所有可能产生的域名(包含常见顶级域)整理成一个
候选域名列表.txt。
如何验证结果真实性
此阶段的结果是“候选列表”,真实性需要在后续的查询阶段通过DNS解析、WHOIS信息来验证。这个列表是下一步查询的“弹药”。
常见错误及排查方式
- 错误:只关注了公司全称,忽略了核心品牌。
排查:重新审视目标实体的核心业务,在官网首页和主要产品页面寻找其对外宣传的品牌名。 - 错误:生成的域名列表过于庞大,无法有效处理。
排查:优先关注.com、.cn、.net等主流顶级域,以及与该实体业务强相关的国家顶级域。
合规边界说明
本阶段仅为思维演练和本地数据生成,不涉及对任何目标域名的查询或扫描,完全在安全合规范围内。
本模块小结
本模块教会我们如何像攻击者一样思考,将抽象的产权实体拆解为一个个具体的、可能用于注册域名的“词汇”和“模式”。这为后续的精准查询提供了明确的输入。
四、构建关联模型
模块概念解释(为什么做)
有了“关联实体清单”和“候选域名列表”,我们需要建立一个逻辑框架,将多源数据(WHOIS、DNS、IP)整合起来,最终确定一个域名是否真的归属于目标产权实体。这个框架就是“关联模型”,它提供了一套判断标准和证据链。
技术原理说明(底层逻辑)
关联模型基于证据的强弱进行分层。我们将证据分为三个等级:
- 强证据(直接归属):WHOIS注册者信息匹配。
- 中证据(强关联):WHOIS注册邮箱/电话/地址匹配;DNS服务器关联。
- 弱证据(可能性线索):IP地址关联;ASN关联;页面内容关联。
资产归属证据分层模型

可执行命令或查询方式(示例)
该模型是分析框架,后续查询命令将服务于获取这些证据。
常见工具对比(表格形式)
| 工具/方法 | 作用 | 优点 | 缺点 |
|---|---|---|---|
| Excel/Google Sheets | 建立资产清单表格 | 灵活,可自定义列 | 手动操作,大规模数据时效率低 |
| Maltego | 可视化关联分析 | 图形化展示关系,直观 | 学习曲线陡峭,商业软件 |
| 自定义脚本 (Python) | 整合多源数据,自动化打标签 | 可定制化程度高,适合大规模自动化处理 | 需要编程能力 |
标准操作步骤
- 设计资产清单模板:创建一个表格,包含列:域名、关联实体、证据类型1、证据详情1、证据类型2、证据详情2、置信度(高/中/低)、备注。
- 定义置信度规则:
- 高:存在至少一项“强证据”。
- 中:存在至少一项“中证据”,且无矛盾证据。
- 低:仅存在“弱证据”。
- 准备数据填充:后续查询得到的数据,将按照此模型填入表格。
- 动态更新:在信息收集过程中,随着证据增多,动态调整每个域名的置信度。
如何验证结果真实性
模型的验证在于其逻辑的严谨性。当一个域名可以通过多重证据指向同一目标时,其归属的真实性就得到了极大增强。
常见错误及排查方式
- 错误:将使用了相同公共DNS(如Cloudflare DNS)的不同域名,误认为是关联的。
排查:只有私有NS或特定服务商NS才可作为强关联证据,通用的公共DNS不能作为关联证据。 - 错误:只依赖单一证据,如IP归属。
排查:IP可能托管在公有云,很多公司共享一个IP段。必须结合WHOIS等更强证据综合判断。
合规边界说明
此框架用于内部数据分析和研判,不涉及任何主动的、可能触犯法律的行为。
本模块小结
本模块为我们构建了一个科学、严谨的研判框架。它将零散的查询结果,通过证据链的形式,转化为有逻辑支撑的资产归属判断,大大提高了资产清单的准确性。
五、形成查询路径
模块概念解释(为什么做)
前面的模块准备好了“弹药”(候选域名)和“靶场”(关联模型),现在需要一套具体的“射击步骤”来获取证据。本模块将设计一条从“产权线索”出发,一步步验证并发现域名的执行路径。
技术原理说明(底层逻辑)
查询路径是一个闭环流程:从实体出发 -> 通过多种技术手段发现域名 -> 验证归属 -> 确认后,将新域名作为起点,进行扩展查询。核心是整合WHOIS查询、反向WHOIS查询、DNS解析、证书透明度日志等多种技术。
可执行命令或查询方式(示例)
- 正向WHOIS查询:
whois example.com | grep -E "Registrant|Organization|Registrant Email"- 反向WHOIS查询(模拟):
# curl -X POST "https://api.reversewhois.io/v1/search" -d '{"query":"domain@example.com"}'
echo "反向WHOIS通常通过专业平台如Domaintools、SecurityTrails的Web界面或API完成。"- DNS解析查询:
dig example.com A +short- IP反向查询(模拟):
# host 93.184.216.34
# 更全面的反向查询需借助在线平台如Bing、VirusTotal- 证书透明度日志查询:
curl -s "https://crt.sh/?q=%.example.com&output=json" | jq '.[].name_value' | sort -u常见工具对比(表格形式)
| 工具名称 | 主要功能 | 优点 | 缺点 | 示例命令/用法 |
|---|---|---|---|---|
| whois (Linux命令) | 正向WHOIS查询 | 系统自带,简单快速 | 数据格式不统一,隐私保护下信息被屏蔽 | whois target.com |
| SecurityTrails | 反向WHOIS、DNS历史、子域名 | 数据量大,API强大,历史数据丰富 | 免费版有查询次数限制 | 官网搜索 company.com 或注册邮箱 |
| crt.sh | 证书透明度日志查询 | 完全免费,数据实时,非常适合找子域名 | 结果可能包含过期的、被弃用的证书 | curl -s https://crt.sh/?q=%.target.com |
| Domaintools | 综合域名情报平台 | 老牌厂商,数据准确性高,反向WHOIS强大 | 昂贵,主要面向企业 | 官网查询IP、域名、邮箱 |
| VirusTotal | IP/域名/文件多引擎检测 | 关联信息丰富,可查看IP历史域名 | 主要定位是安全检测,关联信息是副产物 | 官网搜索IP 93.184.216.34 |
标准操作步骤
资产发现查询路径图
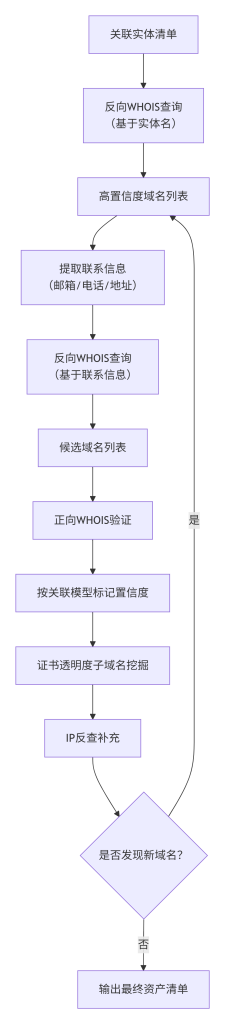
- 基于实体名的反向WHOIS:使用SecurityTrails等平台,用“关联实体名称”进行反向WHOIS查询,记录下所有注册公司名匹配的域名。将这些域名标记为高置信度。
- 基于联系信息的反向WHOIS:从步骤1查询到的域名中,提取注册邮箱、电话、地址,用这些信息再次进行反向WHOIS,发现更多可能使用相同联系信息的域名。
- 正向验证候选列表:用whois命令批量查询“候选域名列表”,检查哪些域名已被注册,并记录其注册者信息,对照关联模型进行置信度判断。
- 证书透明度子域名挖掘:对所有已确认归属的核心域名,通过crt.sh进行子域名枚举,将发现的子域名补充进资产清单。
- IP反查补充:对核心域名解析到的IP,通过VirusTotal等平台进行反查,看是否有其他域名绑定到同一IP,并进行归属判断。
- 迭代循环:将新发现的、置信度高的域名,作为新的起点,重复步骤4-5,直到没有新发现为止。
如何验证结果真实性
- 信息一致性:检查所有发现的域名,其WHOIS信息、DNS解析IP、网站页面版权信息,是否都指向同一个“产权实体”的生态系统。
- 活域名验证:使用
curl -I https://discovered-domain.com查看返回的HTTP状态码和Server头,确认其是可访问的Web服务。
常见错误及排查方式
- 错误:隐私保护导致反向WHOIS无结果。
排查:尝试用注册邮箱的后缀(如@company.com)在搜索引擎或证书日志中搜索,可能发现相关域名。 - 错误:API调用频率过高导致IP被封。
排查:严格遵守工具的API速率限制,加入随机延时,或使用代理池。
合规边界说明
所有命令和查询均针对公开的WHOIS数据库、DNS服务器、证书日志等,不涉及对目标系统进行扫描或渗透。使用公共API时,必须遵守其服务条款,不进行非授权的商业利用或数据抓取。
本模块小结
本模块提供了一套可落地执行的“查询路径图”,将理论转化为实战。通过正向、反向查询和证书日志等多维技术手段,形成一个强大的资产发现引擎。
六、划定合规界限
模块概念解释(为什么做)
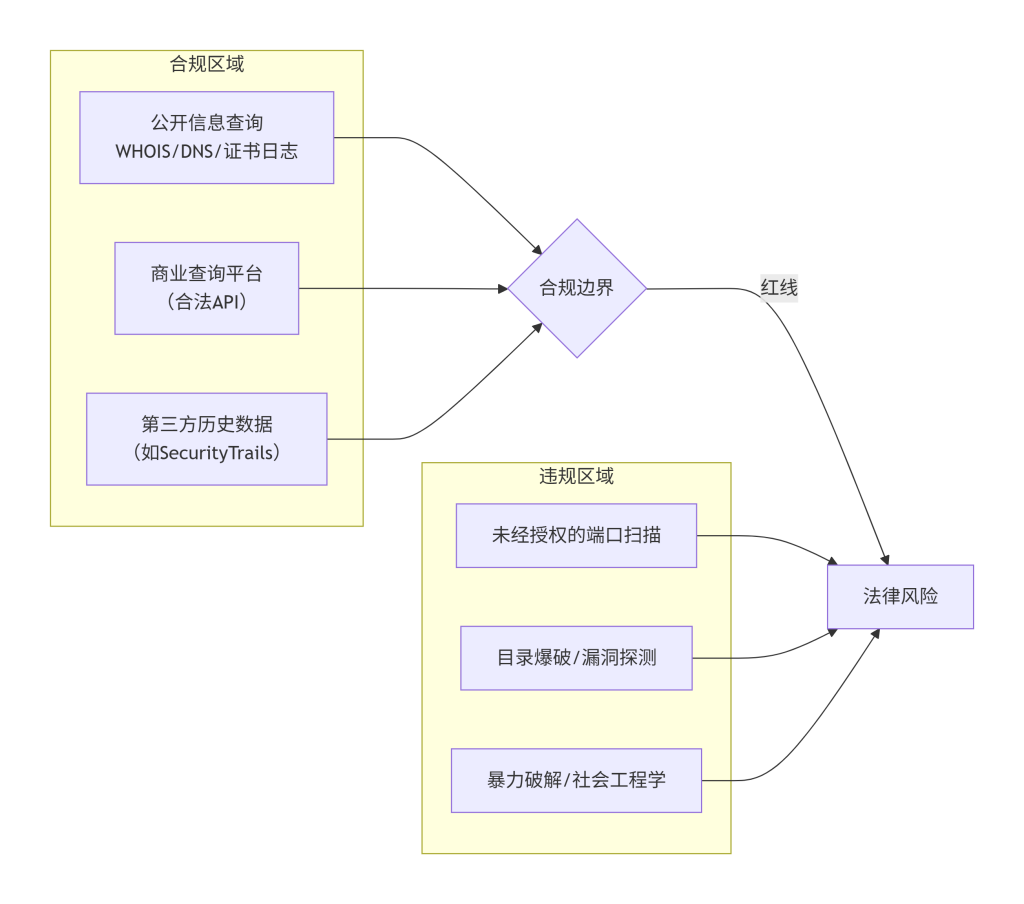
信息收集是把双刃剑。在合法授权范围内,它是安全评估的基础;一旦越界,就可能触犯法律。本模块旨在清晰界定“公开信息查询”与“敏感/非法操作”之间的红线,确保所有工作在合规的框架内进行。
技术原理说明(底层逻辑)
法律边界通常由数据的性质、获取方式和使用目的决定。
- 公开数据 vs 非公开数据:WHOIS、DNS记录、证书日志等是面向公众的服务,查询这些数据通常是合法的。而通过漏洞扫描、暴力破解等方式获取的未授权信息,则是非法的。
- 合理使用 vs 恶意攻击:正常的、低频率的查询是“合理使用”。但如果进行大规模、高并发的请求,对目标或查询服务造成资源耗尽,就可能构成“破坏计算机信息系统罪”。
- 授权范围:即使目标本身,如果没有获得书面授权,进行超出公开信息范围的主动扫描和探测,也可能被视为“未经授权访问计算机系统”。
合规界限示意图
可执行命令或查询方式(示例)
此处无需命令,而是列出“负面清单”:
# 禁止执行:
# nmap -sS -p- target.com # 未经授权的端口扫描
# sqlmap -u target.com?id=1 # 未经授权的漏洞探测
# dirb https://target.com # 未经授权的目录爆破
# hydra -l user -P pass.txt target.com ssh # 未经授权的暴力破解常见工具对比(表格形式)
| 类别 | 工具/技术 | 操作内容 | 合规状态 (无授权时) | 风险说明 |
|---|---|---|---|---|
| 公开信息查询 | whois, nslookup, dig, crt.sh | 查询域名注册信息、DNS解析、证书 | 合规 | 查询的是公共服务数据 |
| 公开信息查询 | SecurityTrails, Shodan, Censys | 查询其数据库中的历史数据和扫描记录 | 合规 | 使用的是第三方已收集并公开的数据 |
| 主动信息探测 | Nmap, Masscan | 对目标IP进行端口扫描 | 不合规 | 可能被认定为“对计算机信息系统功能进行干扰” |
| 主动信息探测 | Dirb, Gobuster, ffuf | 对目标网站进行目录爆破 | 不合规 | 可能被认定为“非法获取计算机信息系统数据” |
| 社会工程学 | 冒充内部人员电话套取信息 | 获取非公开的内部信息 | 不合规 | 属于欺诈行为,严重违法 |
标准操作步骤
- 确认授权范围:在任何收集工作开始前,书面确认授权书的范围。
- 制定操作手册:将合规红线明确写入团队操作手册,并对所有成员进行培训。
- 使用代理/跳板机:在进行公开信息查询时,可以使用代理,但目的应是保护查询源IP的隐私,而非隐藏恶意行为。
- 记录操作日志:详细记录每一步操作,包括命令、时间、目的。
如何验证结果真实性
- 合规审查:由独立的合规专员定期审查操作日志,确保所有命令和查询都在白名单内。
- 定期培训:通过实际案例,让团队成员理解违规的严重后果。
常见错误及排查方式
- 错误:“我只是测试一下是否存在这个漏洞,不算入侵吧?”
排查:立刻停止。任何对目标系统的非授权探测,无论成功与否,都可能构成违法。 - 错误:使用自动化脚本时,忘记设置延时,导致请求频率过高,被目标WAF拦截。
排查:在脚本中强制加入sleep或使用--rate-limit参数。
合规边界说明
本模块本身就是对整个课程的合规性约束。再次强调:所有操作必须以“公开信息”为唯一数据源,以“合法授权”为唯一前提。本课程教授的方法论和技能,严禁用于任何未经授权的活动中。
本模块小结
合规是信息安全从业者的生命线。本模块为我们树立了清晰的“红灯区”,确保我们在追求技术能力的同时,始终坚守法律和道德的底线,成为一名合格的“白帽”专家。
七、整合资产轮廓
模块概念解释(为什么做)
经过前面六个模块的层层推进,我们已经收集到了大量关于目标机构产权和域名的信息。现在,最后一步,也是最体现价值的一步:将这些零散的信息,整合成一份清晰、完整、可交付的资产轮廓。这不仅是一份清单,更是一份关联视图,能直观地展现目标机构的网络资产全貌。
技术原理说明(底层逻辑)
整合过程是对关联模型的最终应用和可视化呈现。它将域名、IP、子域名、关联实体等信息,按照证据强弱进行组织和关联,形成一份高价值的资产情报。
可执行命令或查询方式(示例)
# 伪代码示例:从Excel或CSV读取资产清单,生成Markdown格式报告
import pandas as pd
df = pd.read_csv('asset_inventory.csv')
with open('final_report.md', 'w') as f:
f.write("# 目标机构资产清单\n\n")
for entity in df['关联实体'].unique():
f.write(f"## 关联实体:{entity}\n")
entity_domains = df[df['关联实体'] == entity]
for index, row in entity_domains.iterrows():
f.write(f"* **{row['域名']}** (置信度:{row['置信度']})\n")
f.write(f" - 证据:{row['证据类型1']} - {row['证据详情1']}\n")
if pd.notna(row['证据类型2']):
f.write(f" - 证据:{row['证据类型2']} - {row['证据详情2']}\n")
print("报告已生成:final_report.md")常见工具对比(表格形式)
| 工具名称 | 主要功能 | 优点 | 缺点 | 适合场景 |
|---|---|---|---|---|
| Excel/Sheets | 数据整理、透视、图表 | 灵活,上手快,强大的数据透视功能 | 可视化关联能力弱,不适合展示复杂关系 | 生成结构化的详细清单 |
| MindMaster/XMind | 思维导图 | 清晰展示层级关系 | 难以集成大量IP、端口等细节数据 | 展示产权与域名的树状归属结构 |
| Maltego | 数据挖掘和可视化 | 强大的图谱能力,可动态扩展节点 | 商业软件,学习成本高 | 生成专业的、可交互的关联关系图谱 |
| Grafana/ECharts | 数据可视化仪表盘 | 可定制化展示各类统计图表 | 需要开发配置 | 向管理层汇报时,展示宏观态势 |
标准操作步骤
资产整合流程图
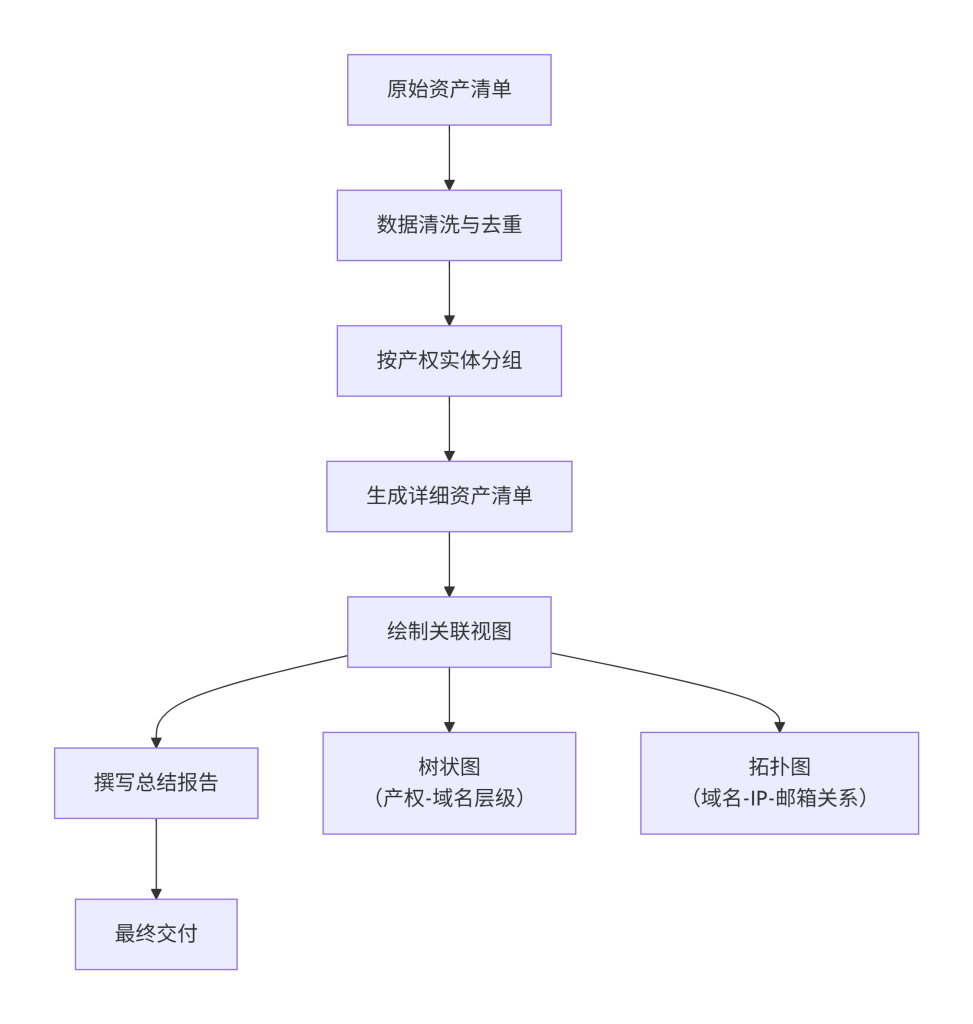
- 数据清洗与去重:对资产清单进行最终检查,删除重复项,统一域名格式。
- 按产权实体分组:以“关联实体”为第一维度,将资产清单进行分组。
- 生成详细资产清单:输出一份详细的表格,包含域名、IP、关联实体、证据链、置信度、发现日期等。
- 绘制关联视图:
- 树状图:使用思维导图软件,以核心目标机构为根,子公司为分支,域名和子域名为叶子节点,绘制归属关系图。
- 拓扑图:使用Maltego等工具,将域名、IP、邮箱作为不同节点,通过关系线连接,绘制动态拓扑图。
- 撰写总结报告:结合资产清单和关联视图,撰写一份总结报告,概述资产发现的规模、类型、分布特点,并对高价值资产进行标注。
如何验证结果真实性
最终交叉验证:随机选取清单中的5-10个域名,人工复核其WHOIS信息、页面版权,确保与报告结论一致。这是交付前的最后一道质量门。
常见错误及排查方式
- 错误:报告冗长,缺乏重点,难以阅读。
排查:在报告开头增加“执行摘要”,用一两页PPT或文字,概述最重要的发现和结论。详细清单作为附录。 - 错误:视图过于复杂,反而掩盖了核心信息。
排查:在设计视图时,对节点进行分组、着色。例如,将“高置信度”的域名用红色标注,将“Web应用”类型的资产用特殊图标区分。
合规边界说明
最终产出的资产轮廓,其用途必须严格限定在授权范围内,例如用于内部安全加固、合规审计或授权的渗透测试。不得将报告泄露给任何无关第三方。
本模块小结
本模块是信息收集工作的最终交付环节。它教会我们如何将前期的辛勤劳动,转化为一份清晰、有力、高价值的成果。一份优秀的资产轮廓,不仅是信息的汇总,更是对目标机构网络架构的深刻洞察。
信息收集-Web应用-DNS&证书&枚举子域名
一、重构域名信任认知框架
1.1 模块概念解释
在开始任何信息收集工作之前,必须重新理解“域名信任”的本质。传统观念往往把域名看作单纯的访问入口,但在工程视角下,域名是网络身份的结构化载体,它承载着DNS解析链和证书验证链两层信任关系。本模块解决的问题是:打破“域名=IP”的简单认知,建立“域名-解析-证书”三位一体的信任模型,为后续资产识别提供正确的理论基础。只有理解了信任是如何通过DNS层级和CA体系层层传递的,才能准确解读后续采集到的解析记录和证书信息,避免因认知偏差导致资产遗漏或误判。
1.2 技术原理说明
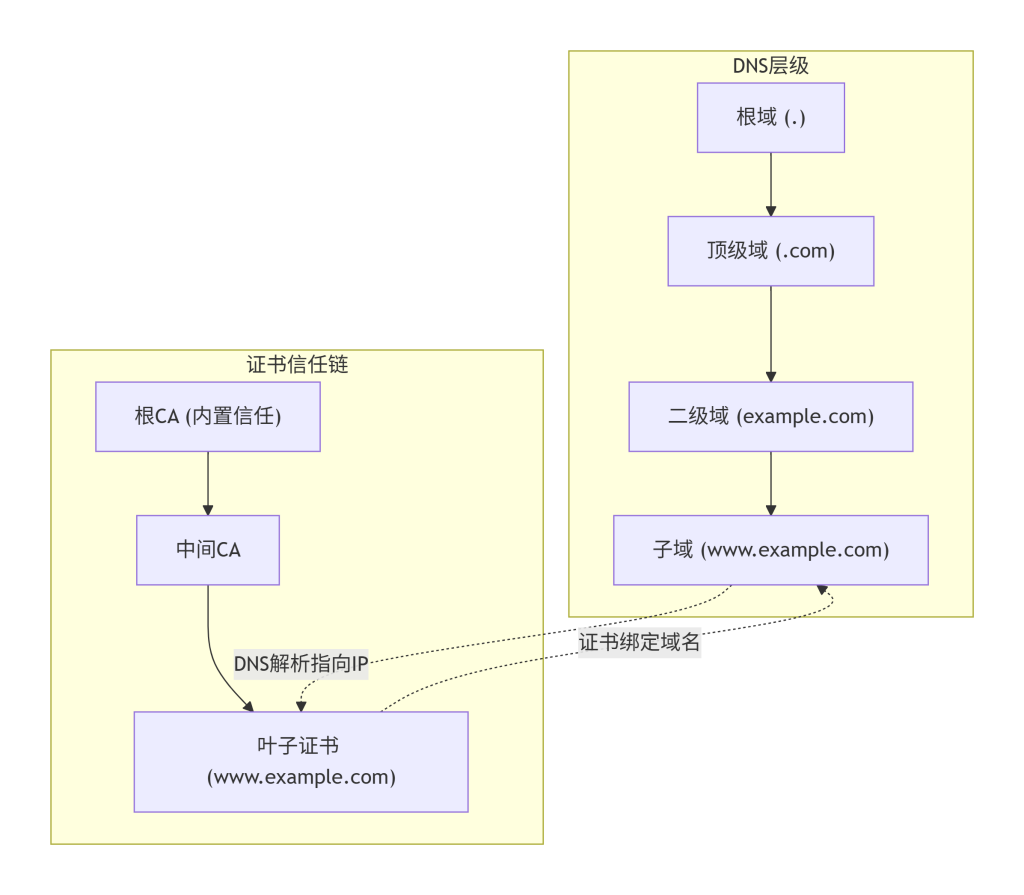
底层逻辑基于互联网的两大基础设施:域名系统(DNS)和公钥基础设施(PKI)。
DNS采用树状层级结构,从根域(.)、顶级域(如.com)、二级域(example.com)到子域(www.example.com),每一级授权给下一级的名称服务器,通过递归或迭代查询实现从根域到目标域的信任传递。PKI通过证书颁发机构(CA)签发X.509证书,证书将域名(或IP)与公钥绑定,并形成信任链(根CA→中间CA→叶子证书)。客户端(如浏览器)通过预置的根证书信任链验证服务器身份。
这两个体系共同构成了域名信任框架:DNS告诉客户端“去哪里连接”,证书告诉客户端“连接的是否为预期实体”。设计如此分离是为了实现职责分离——DNS负责解析,证书负责验证,但两者必须协同才能确保安全通信。
图1-1:DNS层级结构与证书信任链模型
1.3 在系统中的位置
本模块是整个信息收集体系的认知起点。它不直接产生数据,但为后续模块(如边界界定、层级拆解、映射建模)提供了解释数据的逻辑框架。后续所有对DNS记录、证书信息的处理,都将基于本模块建立的信任视角进行解读。例如,在拆解层级结构时,我们会引用DNS树状模型;在映射资产时,我们会考虑证书中的SAN(Subject Alternative Name)扩展与DNS域名的关联。
1.4 可执行命令或查询方式
使用测试目标 example.com 和 scanme.nmap.org 进行基础信任框架探查:
- 查询DNS解析链:使用
dig追踪完整解析过程。
dig example.com +trace该命令模拟递归解析,从根域开始逐步显示各级NS记录和A记录,直观呈现DNS信任传递路径。
- 查看证书链:使用
openssl连接服务器并获取证书链。
openssl s_client -connect example.com:443 -showcerts该命令输出服务器证书及中间证书,可观察到证书的颁发者(issuer)和使用者(subject)层级关系。
- 查询域名WHOIS信息:了解域名注册与授权关系。
whois example.comWHOIS虽不属于DNS或PKI,但提供了域名所有权与名称服务器授权的上下文,有助于理解信任的源头。
1.5 工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| dig | 精细化的DNS查询,尤其适用于追踪解析路径和查看特定记录类型 | 输出详细、标准化,支持+trace等高级选项 | 对初学者输出较复杂,需理解DNS协议细节 |
| nslookup | 简单快速的DNS查询,交互式或单次查询 | 几乎全平台内置,使用简单 | 功能相对单一,不支持+trace等高级特性 |
| host | 精简DNS查询,适合脚本调用 | 输出简洁,易于解析 | 选项较少,不适合复杂调试 |
| openssl s_client | 获取SSL/TLS证书链及详细信息 | 可查看完整证书内容,验证证书有效性 | 命令参数较多,需理解SSL握手过程 |
| whois | 查询域名注册信息及名称服务器 | 提供所有权上下文,补充DNS信息 | 输出格式因注册局而异,部分域名信息可能因隐私保护而被隐藏 |
1.6 标准操作步骤
- 确定测试目标:选择一个授权的测试域名,如
example.com或scanme.nmap.org。 - 执行根域追踪:运行
dig <域名> +trace,观察从根到目标域名的解析路径,记录沿途的NS服务器。 - 获取权威解析:直接查询权威DNS,运行
dig <域名> A以及dig <域名> NS,确认权威记录。 - 提取证书链:运行
openssl s_client -connect <域名>:443 -showcerts,将输出保存至文件,分析证书层级。 - 交叉验证:对比WHOIS中列出的名称服务器与DNS查询结果是否一致,初步感知信任关系。
1.7 如何验证结果真实性
- DNS解析验证:使用不同公共DNS(如8.8.8.8、1.1.1.1)重复查询,对比结果是否一致。若解析结果不同,可能涉及DNS劫持或GeoDNS。
- 证书链验证:将获取的证书链导入本地信任库(如使用
openssl verify),检查是否完整且未被吊销。若验证失败,可能中间证书缺失或证书不受信任。 - WHOIS验证:通过多个WHOIS服务器查询,对比返回的注册信息和名称服务器,判断是否存在缓存或隐私保护导致的差异。
1.8 常见错误与排查方式
- 错误:混淆权威解析与递归解析输出。
排查:明确dig不带任何选项时通常为向递归服务器查询,+trace则模拟递归过程展示权威路径;+norecurse可强制进行非递归查询。 - 错误:证书链不完整导致验证失败。
排查:检查openssl s_client输出中是否有多个-----BEGIN CERTIFICATE-----块,通常服务器应发送完整链,若缺失需手动下载中间证书。 - 错误:忽略DNSSEC信任链。
排查:若目标启用了DNSSEC,可尝试dig +dnssec查看RRSIG记录,验证签名有效性。
1.9 合规边界说明
- 风险:频繁的DNS追踪可能被目标视为探测行为,尤其
+trace会产生大量递归查询,可能触发速率限制。 - 局限:WHOIS信息可能被注册局隐藏或使用隐私保护,无法直接反映真实所有者。
- 缓解措施:控制查询频率,使用公开解析器而非直接攻击目标权威服务器;对于隐私保护域名,不应强行追溯个人身份。
- 决策指南:本模块是必选前置步骤,只有在完全理解域名信任框架后,后续的资产枚举才能建立在正确的基础上。若目标未启用HTTPS,可省略证书部分。
1.10 本模块阶段性小结
通过重构域名信任认知框架,我们建立了DNS层级与证书链的双重视角,明确了信息收集的底层逻辑——所有资产信息都应置于这一信任传递路径中解读。接下来,我们将基于这一认知,开始界定目标资产的识别边界。
二、界定资产识别目标边界
2.1 模块概念解释
在上一模块中,我们理解了域名信任框架,现在需要明确“收集什么”。资产边界界定就是划定目标组织的数字资产范围,通常包括:主域名、子域名、相关域名(如用于不同业务或区域的变体)、以及这些域名关联的IP和证书。本模块解决的问题是防止范围过宽(引入无关资产)或过窄(遗漏关键资产),为后续枚举提供精确的“起点”和“终点”。没有清晰的边界,后续所有采集工作都将失去方向,导致结果混乱或无效。
2.2 技术原理说明
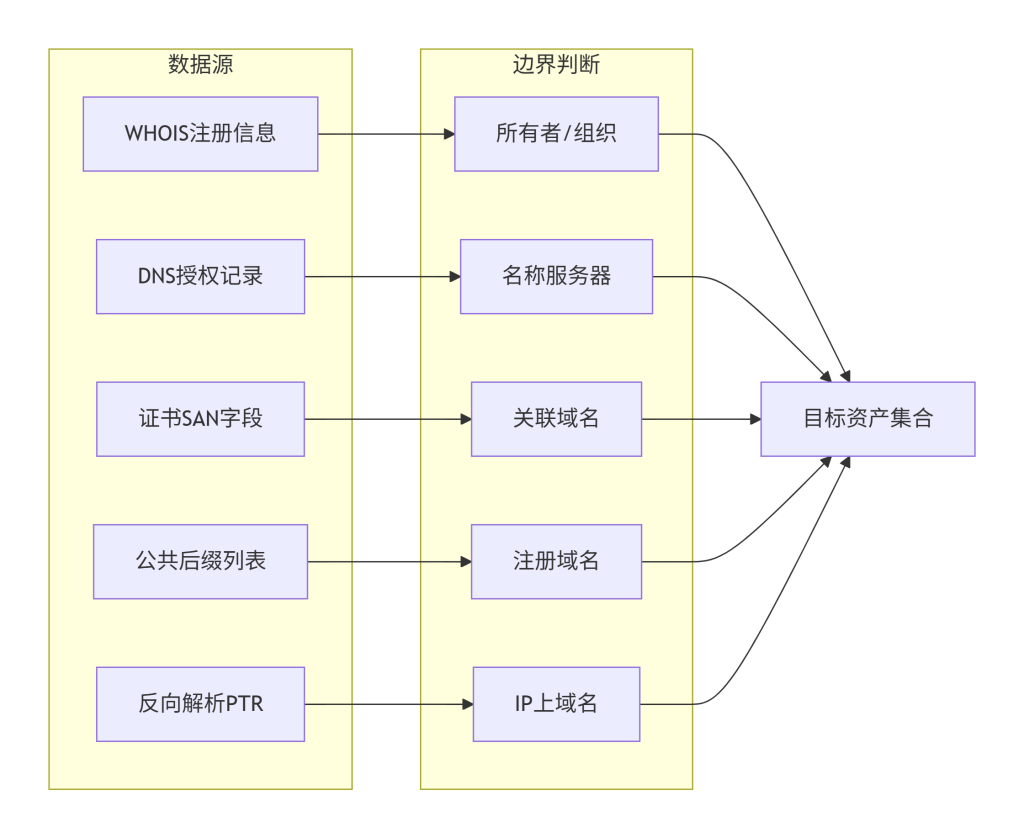
资产边界的确定基于域名注册信息、DNS管理权、证书中的身份声明以及业务逻辑。技术上,我们通过以下方式定义边界:
- 注册信息:WHOIS中的域名所有者、联系邮箱可作为归属判断依据。
- DNS授权:域名的NS记录指向的服务器由谁管理,通常意味着该域名的解析权归属。
- 证书SAN:X.509证书的Subject Alternative Name字段列出了该证书保护的所有域名,这些域名往往属于同一实体。
- 公共后缀列表(Public Suffix List, PSL):用于区分注册域名和子域,如
example.com是注册域名,www.example.com是其子域。 - 反向解析:通过IP反查域名(PTR记录),可能发现同一IP上托管的其他域名(共享主机场景需谨慎)。
图2-1:资产边界界定信息来源图
2.3 在系统中的位置
本模块位于认知框架之后、具体拆解之前。它接收“信任框架”作为理论基础,输出一份“资产目标列表”(如根域列表、初始子域集合)。后续的层级拆解、映射建模都将基于此列表展开。若边界界定不准确,后续所有环节都会产生系统性偏差。
2.4 可执行命令或查询方式
- 获取初始根域:通过WHOIS查询,提取域名本身及相关域名(如注册者邮箱关联的其他域名)。
whois example.com | grep -i "Registrant Email" | awk '{print $NF}'注意:隐私保护下邮箱可能被隐藏,仅作辅助;不同WHOIS服务器输出字段可能不同,需根据实际输出调整。
- 从证书透明度日志获取关联域名:使用在线工具(如crt.sh)的API或命令行工具。
curl -s "https://crt.sh/?q=%.example.com&output=json" | jq -r '.[].name_value' | sort -u- 从DNS记录中提取子域:通过DNS区域传输(如果允许)或字典枚举(后续模块),但边界界定阶段只需初步获取已知子域,如常见记录:
dig example.com ANY +noall +answer | grep -E "IN\s+(A|AAAA|CNAME|MX|NS)"由于DNS消息长度限制,dig ANY查询可能不会返回所有记录类型,此方法仅用于获取部分已公开的常见子域线索。
- 反向IP查询:通过IP查询关联域名(慎用,避免扫描)。
dig -x 93.184.216.34 +short2.5 工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| whois | 获取域名注册信息及关联线索 | 直接获取所有者信息 | 隐私保护导致信息缺失,输出格式不一 |
| crt.sh(curl+json) | 从证书透明度日志批量获取子域 | 数据来源广,包含历史证书 | 依赖外部API,可能包含过期或误报域名 |
| dig | 查询DNS记录,获取已公开的子域 | 实时权威,数据准确 | 仅能获取当前DNS中存在的记录,遗漏未发布记录 |
| amass intel | 被动收集关联域名(基于WHOIS、证书等) | 集成多种数据源,自动化 | 需配置API密钥,部分数据源需付费 |
| theHarvester | 搜索引擎抓取域名信息 | 利用搜索引擎缓存,发现隐藏子域 | 依赖搜索引擎规则,可能被限制 |
2.6 标准操作步骤
- 确定起始域名:以客户提供的根域(如
example.com)为起点。 - WHOIS信息挖掘:查询WHOIS,记录注册者、管理员邮箱,并尝试通过邮箱反查其他注册域名(使用公开反向WHOIS服务或工具,如
amass intel -whois)。 - 证书透明度采集:访问crt.sh或使用
curl获取包含%.example.com的所有证书,提取域名列表。 - DNS现有记录收集:使用
dig查询目标域名的常见记录(A、MX、NS、TXT等),记录返回中出现的子域(如邮件服务器子域)。 - 初步合并去重:将以上步骤获取的域名合并,去除无效格式,形成初始资产边界列表。
- 人工审核:检查列表中的域名是否确实属于目标组织(如通过网站标题、证书颁发者等),剔除明显误报(如泛解析导致的无关域名)。
2.7 如何验证结果真实性
- 交叉验证:对比WHOIS邮箱与证书中的组织信息,若一致则增强归属可信度。
- 域名解析验证:对列表中的域名执行A记录查询,若解析到已知IP段或CDN服务商,进一步佐证其归属。
- 证书验证:访问域名HTTPS服务,查看证书是否由目标控制(如证书中组织字段匹配),并检查证书SAN是否包含该域名。
- 逻辑判断:若域名解析到云服务商IP(如AWS、Cloudflare),需结合业务场景判断是否为租用服务,仍可能属于目标资产。
2.8 常见错误与排查方式
- 错误:将共享主机IP上的所有域名都视为同一资产。
排查:通过证书、网站内容、WHOIS注册者等多维度验证,若完全无关联则应排除。 - 错误:忽略泛域名解析(如
*.example.com)导致的误报。
排查:对疑似泛解析的IP,尝试随机子域,若返回相同IP,则该IP不能作为特定子域的唯一归属。 - 错误:过度依赖单一数据源(如只使用crt.sh)导致遗漏。
排查:结合多个数据源,并定期更新采集策略。
2.9 合规边界说明
- 风险:反向WHOIS查询可能涉及个人隐私数据,需遵守当地数据保护法规,不得用于非法目的。
- 局限:证书透明度日志包含大量测试证书和过期证书,可能混入无关域名。
- 缓解措施:明确收集目的仅限授权测试,对敏感信息脱敏处理;设置时间窗口,只考虑近期有效的证书。
- 决策指南:本模块必须执行,且应优先使用被动数据源(如证书、WHOIS),避免直接主动探测目标。若目标范围极小(如单一主域),可简化边界界定,但仍需确认是否存在相关子域。
2.10 本模块阶段性小结
经过资产边界界定,我们获得了一份初步的域名候选列表,明确了收集的目标范围。接下来,我们将对列表中的每个域名深入拆解其DNS解析路径和证书信任层级,以理解其内部结构。
三、拆解解析与信任层级结构
3.1 模块概念解释
获得了资产边界列表后,需要深入拆解每个域名背后的解析结构与信任层级。本模块旨在回答:对于每个目标域名,它的DNS解析是如何逐级授权的?它的证书链由哪些CA签发,中间证书是否完整?为什么需要拆解?因为只有理清层级,才能准确判断域名的依赖关系、可能的单点故障、以及证书配置的规范性。例如,一个子域可能托管在外部CDN,其解析权并不在主域,这会影响后续的资产归属判断。
3.2 技术原理说明
基于模块一建立的信任框架,本模块深入拆解具体实现细节:
- DNS解析层级:从根域到目标域名的授权路径。每个非根域都有一组NS记录指明下一级权威服务器。例如,
sub.example.com可能由example.com的NS服务器授权,也可能直接由sub.example.com自己的NS服务器授权(独立托管)。解析过程遵循1.2节所述的树状层级,通过递归或迭代查询逐级获取记录。 - CNAME与解析链:CNAME记录(Canonical Name)将域名别名指向另一个域名,形成解析链,最终必须解析到A/AAAA记录。链中任何一环都可能引入外部托管。
- 证书信任层级:证书链由叶子证书(目标域名)、中间证书、根证书组成。根证书预置于操作系统/浏览器,中间证书需由服务器提供。信任建立在每一级证书都由上一级签发且未被吊销。
图3-1:域名解析路径与证书链拆解示例(以 sub.example.com 为例)
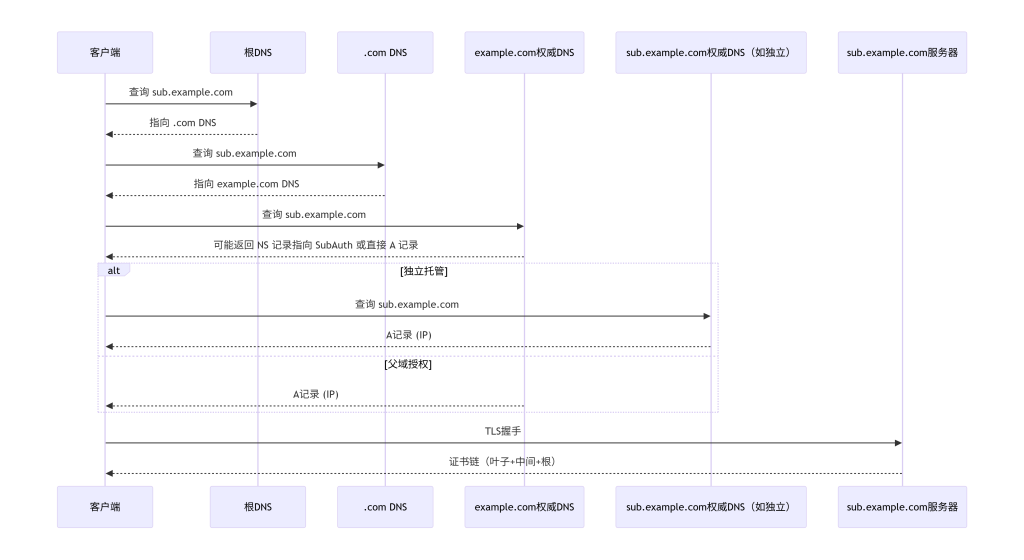
3.3 在系统中的位置
本模块紧接边界界定之后,对每个边界内的域名进行深度拆解。它输出每个域名的详细解析路径和证书链结构,为下一模块“建立资产结构映射模型”提供原子数据。本模块是信息收集的核心解析阶段,数据质量直接影响后续建模。
3.4 可执行命令或查询方式
- 追踪完整解析路径(对每个子域):
dig sub.example.com +trace观察最终A记录以及沿途NS记录,注意是否存在CNAME。
- 获取详细DNS记录:
dig sub.example.com ANY +noall +answer- 检测CNAME链:
dig sub.example.com CNAME +short若存在CNAME,继续解析目标,直至A记录。
- 查看证书链(对HTTPS服务):
openssl s_client -connect sub.example.com:443 -showcerts </dev/null 2>/dev/null | openssl x509 -text -noout或者查看完整链:
openssl s_client -connect sub.example.com:443 -showcerts </dev/null | awk '/BEGIN/,/END/' > certchain.pem- 检查证书颁发者与SAN:
openssl x509 -in cert.pem -noout -issuer -subject -ext subjectAltName3.5 工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| dig +trace | 完整追踪DNS解析路径 | 逐级展示授权关系,清晰可见 | 耗时较长,可能因网络丢包失败 |
| drill | 类似dig,支持DNSSEC验证 | 轻量,部分系统默认安装 | 功能与dig重叠,较少使用 |
| nslookup | 快速获取某级解析 | 简单,适合单一查询 | 无法追踪完整路径 |
| openssl s_client | 获取并分析证书链 | 最全面的证书信息 | 需手动解析输出,交互性差 |
| curl -vI | 快速查看证书及响应头 | 简洁,同时获取HTTP信息 | 仅能获取服务器证书,不含中间证书 |
3.6 标准操作步骤
- 对每个域名执行
+trace:从资产列表中取出一个域名,运行dig <域名> +trace,记录每一级的NS服务器和最终A记录。 - 解析CNAME:若上一步中出现CNAME,记录目标别名,并重复步骤1直至解析到A记录。
- 记录权威NS:对每个域名,查询其NS记录(
dig <域名> NS),判断其解析权是否独立。 - 获取证书链:如果域名开放443端口,执行
openssl s_client获取证书链,保存为PEM文件。 - 分析证书层级:使用
openssl verify验证证书链完整性,记录颁发者、使用者、SAN字段。 - 汇总数据:为每个域名生成结构化描述,包括:解析路径、权威NS、证书链状态(完整/不完整)、SAN列表。
3.7 如何验证结果真实性
- 解析路径验证:使用不同网络环境(如通过VPN)再次执行
+trace,观察是否一致。若不一致,可能存在GeoDNS或解析器缓存差异。 - 证书链验证:使用在线CA证书库(如Mozilla CA列表)比对中间证书,确认是否受信任。也可使用
openssl verify -CAfile /etc/ssl/certs/ca-certificates.crt cert.pem验证。 - CNAME链验证:对CNAME目标再次执行解析,确保解析结果可达且符合预期。
3.8 常见错误与排查方式
- 错误:
+trace输出被防火墙或递归解析器截断。
排查:改用dig +norecurse直接查询根和各级权威,手动模拟追踪。 - 错误:证书链不完整,但服务器实际发送了完整链(openssl输出未捕获)。
排查:检查openssl s_client输出中是否包含多个-----BEGIN CERTIFICATE-----块,确保提取了所有证书。 - 错误:忽略TLSA记录(DANE)影响。
排查:若目标支持DNSSEC,可查询TLSA记录,但非必需。
3.9 合规边界说明
- 风险:频繁的
+trace可能对权威服务器造成负载,尤其对大量子域执行时。 - 局限:部分CDN或云服务可能隐藏真实源IP,解析结果仅为边缘节点。
- 缓解措施:控制查询速率,使用缓存或批量查询;对CDN域名,记录其CNAME目标作为资产关系。
- 决策指南:对于非HTTP/HTTPS服务,证书部分可跳过;对于纯IP资产,本模块不适用,需通过其他方式(如端口扫描)建立结构。
3.10 本模块阶段性小结
通过拆解解析与信任层级,我们获得了每个域名的详细技术结构:谁授权解析、谁签发证书、以及是否存在依赖关系。这些原子信息将成为下一模块“建立资产结构映射模型”的基础材料,我们将把这些点状信息关联起来,形成完整的资产图谱。
四、建立资产结构映射模型
4.1 模块概念解释
有了每个域名的解析路径和证书信息,我们需要将这些零散的点连接成网络,形成资产结构映射模型。这个模型描述了域名、IP、证书、子域之间的逻辑关系,例如:哪些域名解析到同一IP?哪些证书保护了多个域名?哪个DNS服务器管理了哪些域名?本模块解决的问题是从“数据”到“知识”的转化,将采集信息组织成便于分析和理解的视图,为后续的结构化采集路径提供蓝图。
4.2 技术原理说明
映射模型基于图论中的实体-关系模型。核心实体包括:域名(FQDN)、IP地址、证书(指纹)、DNS服务器。关系包括:
- 解析关系:域名 → IP(A/AAAA记录),域名 → 域名(CNAME记录)。
- 证书绑定关系:证书 ←→ 域名(通过Subject和SAN),证书 ←→ 颁发者CA。
- 授权关系:域名 ←→ DNS服务器(NS记录)。
- 父子关系:子域 → 父域(基于域名标签分割)。
通过将这些关系构建为图,可以快速发现资产间的依赖、聚合和隐藏联系。
图4-1:资产关系映射模型示例图
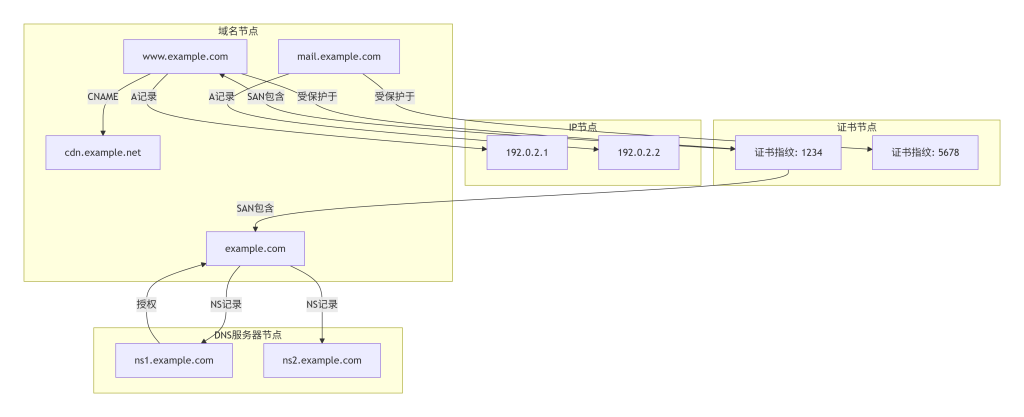
4.3 在系统中的位置
本模块位于层级拆解之后、结构化采集路径之前。它整合了前两个模块的输出,形成一个统一的数据模型。后续的结构化采集路径将依据此模型决定采集顺序(例如,优先采集关键DNS服务器信息),同时模型本身也会指导如何验证采集结果的完整性。
4.4 可执行命令或查询方式
本模块主要涉及数据整合和建模,而非直接采集新数据,因此命令侧重于数据格式转换和导入。
- 使用Amass的图形输出:
amass enum -d example.com -o amass_output.gexfAmass会自动构建域名关系图并输出GEXF格式,可用Gephi打开。使用Amass进行枚举时,请确保已获得目标授权。默认配置下Amass会使用多种公开数据源和主动探测技术。
- 手动构建关系CSV:
假设已有域名-IP列表,可使用脚本生成节点和边文件。
echo "domain,ip,cert_fingerprint" > nodes.csv
echo "source,target,relation" > edges.csv- 使用awk/sed整理数据:
dig +short example.com A | awk '{print "example.com","A",$1}' >> relations.txt4.5 工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| Amass | 自动化子域枚举及关系构建 | 内置关系建模,输出多种图形格式 | 配置复杂,需数据源API密钥 |
| Maltego | 可视化威胁情报分析 | 强大的图形化界面,多种变换 | 商业软件,免费版受限 |
| Gephi | 开源图可视化分析 | 支持大规模图,丰富的布局算法 | 需手动导入数据,不自动采集 |
| Neo4j | 图数据库存储与查询 | 支持复杂图查询,可集成脚本 | 需要额外部署,学习成本高 |
| 自定义脚本(Python+NetworkX) | 灵活定制模型 | 完全控制,可集成采集数据 | 开发工作量较大 |
4.6 标准操作步骤
- 整理实体列表:从采集数据中提取所有唯一域名、IP、证书指纹,去重后形成节点清单。
- 定义关系类型:确定需要建模的关系,如“解析到”、“CNAME到”、“受保护于”、“授权给”等。
- 生成关系边:根据DNS记录、证书信息,为每对实体建立关系边,例如:
- 域名A记录 → 域名→IP
- 域名CNAME记录 → 域名→域名
- 证书SAN → 域名←证书
- 域名NS记录 → 域名←DNS服务器域名
- 导入图分析工具:将节点和边导入Gephi或Neo4j,进行可视化布局。
- 检查模型完整性:验证是否有孤立节点(如无任何关系的IP),分析原因(可能是数据缺失)。
- 输出结构化文件:导出为GraphML、JSON或CSV,供后续模块使用。
4.7 如何验证结果真实性
- 关系一致性验证:随机选取一条关系(如域名→IP),手动使用
dig验证是否成立。 - 证书绑定验证:对证书保护的域名,使用
openssl连接并检查证书是否匹配。 - 图结构合理性:检查是否存在循环依赖(如A CNAME到B,B CNAME到A),这通常表示配置错误或数据错误。
- 覆盖度验证:对比原始资产列表,确保所有域名都在图中出现,且至少有一条关系。
4.8 常见错误与排查方式
- 错误:将多个不同域名的相同IP视为同一节点,忽略端口或路径差异。
排查:IP节点可聚合,但应保留域名节点独立,避免信息丢失。 - 错误:证书关系中遗漏SAN中的域名。
排查:解析证书时务必提取subjectAltName扩展,并生成相应的“受保护于”关系。 - 错误:模型过于复杂,难以分析。
排查:根据目的简化关系类型,只保留关键关系(如解析和证书绑定),过滤掉非关键关系(如MX记录,除非需要)。
4.9 合规边界说明
- 风险:模型可能揭示内部网络结构,如DNS服务器IP、内部域名,需防止泄露。
- 局限:模型基于采集数据,若采集遗漏,模型也会不完整。
- 缓解措施:对敏感节点脱敏处理,如将IP匿名化;明确模型仅用于授权测试,不得外传。
- 决策指南:本模块是可选但强烈推荐,尤其对于大型资产。若目标简单(如只有几个域名),可跳过建模,直接进行采集路径规划。
4.10 本模块阶段性小结
建立资产结构映射模型后,我们拥有了一个可视化的资产关系网,清晰展示了域名、IP、证书之间的关联。接下来,我们将基于模型中的依赖关系,设计一个系统化的采集路径,确保全面覆盖资产且避免重复。
五、形成结构化采集路径
5.1 模块概念解释
结构化采集路径是指按照一定的逻辑顺序,系统地执行信息收集任务,确保全面覆盖资产且避免重复。本模块解决的问题是:在已有资产模型的基础上,如何设计一个可重复、可验证的采集流程,使得每一步都基于上一步的结果,最终形成完整的资产数据集。没有路径规划,采集可能变成随机的、碎片化的操作,导致效率低下和数据不一致。
5.2 技术原理说明
采集路径的设计遵循“依赖前置”原则:先被动后主动,先公开后私有,先控制后探测。具体来说:
- 被动采集:从证书透明度、搜索引擎、DNS公共记录等公开源获取数据,不直接触达目标,风险最低。
- 主动采集:基于被动结果,主动查询DNS、连接服务获取证书,甚至进行有限度的子域枚举(通过字典或迭代查询)。
- 验证阶段:对采集结果进行去重和验证,如通过HTTP状态码判断子域是否存活。
该路径利用了信息熵递减原理:初始信息(被动)最不确定,随着主动交互逐步增加确定性,但同时也增加被检测风险。
图5-1:结构化采集路径流程图
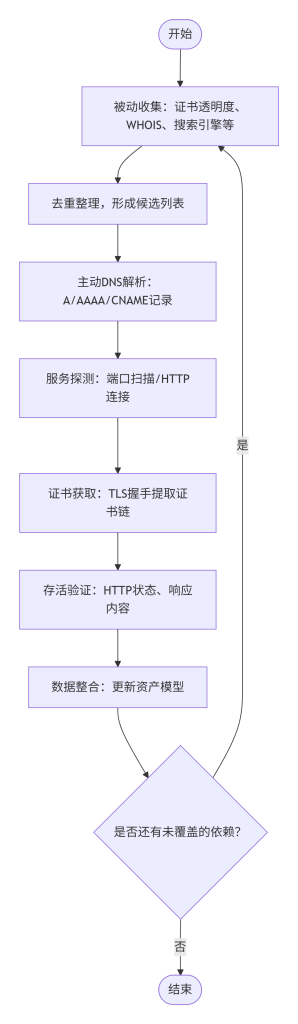
5.3 在系统中的位置
本模块是采集执行层面的蓝图,位于映射模型之后,具体执行之前。它接收模型中的实体列表作为输入,输出一个步骤清晰的采集任务清单。后续的每个采集步骤都应按此路径执行,最终结果将反馈回模型进行更新。
5.4 可执行命令或查询方式
这里展示一个典型路径中的命令组合,以 example.com 为例:
- 步骤1:被动子域收集
assetfinder --subs-only example.com > passive_subs.txt或使用Amass被动模式:
amass enum -passive -d example.com -o passive.txt- 步骤2:主动DNS解析
for sub in $(cat passive_subs.txt); do
dig $sub A +short | tee -a resolved_ips.txt
done- 步骤3:证书获取
while read sub; do
echo "----- $sub -----" >> cert_info.txt
openssl s_client -connect $sub:443 -showcerts 2>/dev/null </dev/null | openssl x509 -text -noout >> cert_info.txt
done < resolved_domains.txt- 步骤4:存活验证
httpx -l resolved_domains.txt -status-code -title -o alive.txt5.5 工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| assetfinder | 快速被动子域收集 | 轻量,集成多个公开源 | 部分源需API,输出较简单,可能未预装在系统中 |
| Amass | 全面子域枚举(被动+主动) | 功能强大,支持主动爆破 | 配置复杂,需API密钥 |
| Sublist3r | 基于搜索引擎的子域枚举 | 简单易用 | 依赖网络搜索,易被限制 |
| httpx | 批量HTTP探活及信息获取 | 高效并发,支持多种输出 | 需Go环境,依赖网络 |
| nuclei | 基于模板的验证(可选) | 可结合采集进行漏洞验证 | 非必须,可根据需要集成 |
5.6 标准操作步骤
- 被动数据收集:运行被动工具收集子域名,包括证书透明度、搜索引擎、DNS记录等,保存为
passive.txt。 - 子域去重与整理:对被动结果进行排序去重,过滤无效域名(如包含通配符)。
- 主动DNS解析:使用
dig或massdns批量解析子域,获取A记录,保存为resolved.txt(包含域名和IP)。 - 服务探测:对解析成功的IP或域名进行端口扫描(如使用
nmap)或直接连接443/80获取服务信息,但需谨慎控制范围。 - 证书采集:对开放443端口的域名获取证书,提取SAN、颁发者等信息,更新资产列表。
- 存活验证与指纹识别:使用
httpx或类似工具访问HTTP/HTTPS,获取状态码、标题、服务器头,进一步确认服务活性。 - 数据整合:将新采集的数据合并到资产模型中,准备下一轮迭代。
5.7 如何验证结果真实性
- 逐步验证:每完成一个步骤,随机抽查几条记录,手动执行相同命令对比结果。
- 完整性检查:确保被动收集结果覆盖了已知的常见子域(如www、mail),并主动解析验证其存在。
- 一致性检查:对比不同工具(如assetfinder和Amass)的被动输出,若差异过大,需检查数据源配置。
- 存活验证:对解析成功的域名,必须通过实际连接确认服务可达,避免DNS解析但端口关闭的误报。
5.8 常见错误与排查方式
- 错误:被动工具未配置API密钥,导致数据源不足。
排查:检查工具配置,为常用源(如SecurityTrails、Censys)配置API,或使用无需密钥的源。 - 错误:主动解析频率过高触发限速。
排查:使用massdns并设置合理并发,或添加延迟sleep。 - 错误:忽略IPv6地址。
排查:主动查询时同时查询AAAA记录,纳入资产范围。 - 错误:证书采集时超时导致遗漏。
排查:增加超时设置,重试机制,或使用并发控制。
5.9 合规边界说明
- 风险:主动DNS解析和端口探测可能被目标视为攻击前奏,触发安全告警。
- 局限:被动数据存在滞后性,可能遗漏新上线的子域。
- 缓解措施:严格控制主动探测的速率,仅对明确授权的目标进行;使用代理IP分散请求;提前与目标沟通测试范围。
- 决策指南:本模块的核心是路径规划,实际执行时应根据风险承受能力调整主动探测深度。在红队评估中可能需要深度枚举,而在常规资产清点中被动收集加轻度验证即可。
5.10 本模块阶段性小结
通过结构化采集路径,我们将资产发现过程变成了一个有章可循的流程,确保了采集的全面性和系统性。然而,采集过程中难免会引入误判,下一模块我们将建立纠偏机制,控制结构误判与范围偏移,确保资产列表的精确性。
六、控制结构误判与范围偏移
6.1 模块概念解释
在采集过程中,由于网络架构的复杂性(如CDN、泛域名解析、虚拟主机),很容易将不属于目标实体的资产纳入,或者遗漏实际存在的资产。本模块解决的问题是建立一套纠偏机制,识别并过滤误判,防止资产范围偏移。例如,将Cloudflare的共享IP上的所有域名都当作目标资产,或者将泛解析子域当作独立资产,都会导致后续工作大量浪费甚至错误结论。
6.2 技术原理说明
误判主要源于以下几种技术现象:
- CDN/反向代理:域名解析到CDN节点IP,但IP上托管了成千上万个域名,不能仅凭IP归属认定域名归属。
- 泛域名解析:DNS配置
*.example.com指向同一IP,导致任意子域都能解析成功,但这些子域可能并不存在实际服务。 - 虚拟主机共享IP:同一IP上通过HTTP Host头区分多个网站,IP本身不能唯一确定域名归属。
- 证书共享:多域名证书(SAN)可能包含不相关的域名(如测试域名),需结合业务判断。
控制方法包括:通过HTTP响应内容验证、检查证书匹配、对比WHOIS注册信息、利用反向DNS验证等。
图6-1:资产误判原因示意图

6.3 在系统中的位置
本模块穿插在采集路径的各个阶段之后,作为质量控制和数据清洗步骤。它接收采集路径输出的原始数据,经过过滤和验证后,将净化后的数据输入资产模型,或反馈给采集路径进行补采。
6.4 可执行命令或查询方式
- 验证泛域名:
random_sub=$(cat /dev/urandom | tr -dc 'a-z' | fold -w 10 | head -n1).example.com
dig $random_sub A +short若返回与已知子域相同的IP,则可能存在泛解析。注意:此命令在macOS上可能需要调整(如使用 date +%s%N 生成随机数),但在Linux上通用。
- 验证CDN共享IP:
dig -x <IP> +short或通过HTTP头Server、响应内容判断。
- 验证虚拟主机:
curl -H "Host: example.com" http://<IP> -I
curl -H "Host: random.host" http://<IP> -I若不同Host返回不同内容,则说明IP存在虚拟主机。
- 验证证书匹配:
echo | openssl s_client -connect example.com:443 2>/dev/null | openssl x509 -text -noout | grep -A1 "Subject Alternative Name"6.5 工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| curl | 测试HTTP响应,验证虚拟主机 | 灵活,可自定义请求头 | 仅适用于HTTP服务 |
| dig | 基础DNS验证,如泛解析检测 | 快速,无需连接服务 | 无法验证服务层内容 |
| httpx | 批量HTTP探测,支持自定义host | 自动化并发,支持多种探活 | 需要配置合适的模板 |
| nuclei | 通过模板验证特定指纹 | 可编写自定义验证规则 | 相对重型,适合集成 |
| whatweb | 识别网站技术栈,辅助判断 | 信息丰富,识别CMS等 | 可能被WAF拦截 |
6.6 标准操作步骤
- 泛解析检测:对每个主域,生成多个随机子域进行DNS查询,若都解析到同一IP集,则标记该主域存在泛解析,后续对该主域下的子域需进行存活验证。
- IP共享分析:对每个解析到的IP,执行反向DNS查询,并尝试获取IP上绑定的其他域名(通过证书或HTTP响应),分析是否存在大量无关域名。若IP属于CDN(通过ASN或特征识别),则IP不能作为资产归属的唯一依据。
- 虚拟主机验证:对每个域名,直接访问IP并指定Host头,与正常访问域名对比响应(状态码、标题、body hash),若一致则确认域名与IP绑定。
- 证书验证:检查证书是否包含当前域名,若不包含,可能是IP被复用或配置错误,需进一步调查。
- 存活确认:对HTTP/HTTPS服务,通过获取状态码(非4xx/5xx)和响应内容,确认服务真实存在且为目标所有。
- 范围调整:根据验证结果,从资产列表中移除误报,并记录验证过程以备审计。
6.7 如何验证结果真实性
- 泛解析验证:对同一主域使用多组随机子域重复测试,若结果一致,确认泛解析。
- 虚拟主机验证:使用多个已知域名(包括不在资产列表中的)访问同一IP,观察返回差异,若存在差异,说明IP上存在多站点。
- 证书验证:使用不同工具(如openssl和curl)分别获取证书,比对SAN字段,确保一致性。
- 人工抽样:对可疑资产进行手动浏览器访问,观察网站内容和证书信息,最直接但效率低。
6.8 常见错误与排查方式
- 错误:将CDN IP上的所有域名都误认为同一实体。
排查:通过ASN、IP段归属判断是否为CDN,若是,则重点关注CNAME记录而非IP。 - 错误:泛解析导致大量假阳性子域。
排查:在主动枚举时,必须对每个子域进行HTTP/HTTPS存活验证,只有返回正常内容的才保留。 - 错误:忽略HTTPS证书过期或无效的域名。
排查:证书过期不代表域名不属于目标,需结合WHOIS和网站内容判断。
6.9 合规边界说明
- 风险:对IP进行反向查询和虚拟主机测试,可能被目标视为扫描行为。
- 局限:虚拟主机验证依赖于HTTP服务,对于非Web服务(如SSH)无法使用。
- 缓解措施:在验证时使用较低的速率,避免触发入侵检测;只对已明确授权的目标进行深度验证。
- 决策指南:本模块是保障数据质量的关键,必须执行。若目标是云原生环境(大量使用CDN),应重点依赖证书和CNAME而非IP。
6.10 本模块阶段性小结
通过控制结构误判与范围偏移,我们清洗了采集数据,去除了因CDN、泛解析等造成的噪声,使资产列表更加精准。现在,我们拥有了一个高质量的数据集,最后一步是将这些信息整合成清晰易用的图谱或报告形态,交付给使用者。
七、整合资产图谱输出形态
7.1 模块概念解释
最后一步是将所有经过验证的资产信息整合成易读、易用的图谱或报告形态。本模块解决的问题是如何将复杂的资产关系可视化,使得安全人员、运维人员能够直观地理解资产结构,并能够导出为其他工具可解析的格式(如JSON、CSV)。输出形态决定了信息收集成果的可用性,良好的输出能帮助快速定位关键资产、发现潜在风险。
7.2 技术原理说明
图谱输出基于图数据库或可视化库的渲染原理。节点代表实体(域名、IP、证书),边代表关系(解析、绑定)。布局算法(如力导向图)自动排列节点,使关系紧密的节点聚在一起。数据格式方面,常见的如GraphML、GEXF、DOT等标准格式,以及JSON/CSV等表格格式。输出不仅包括静态图,还应包括属性表格,如域名对应的IP、证书指纹、开放端口等。
图7-1:图谱输出形态示例(部分资产关系)
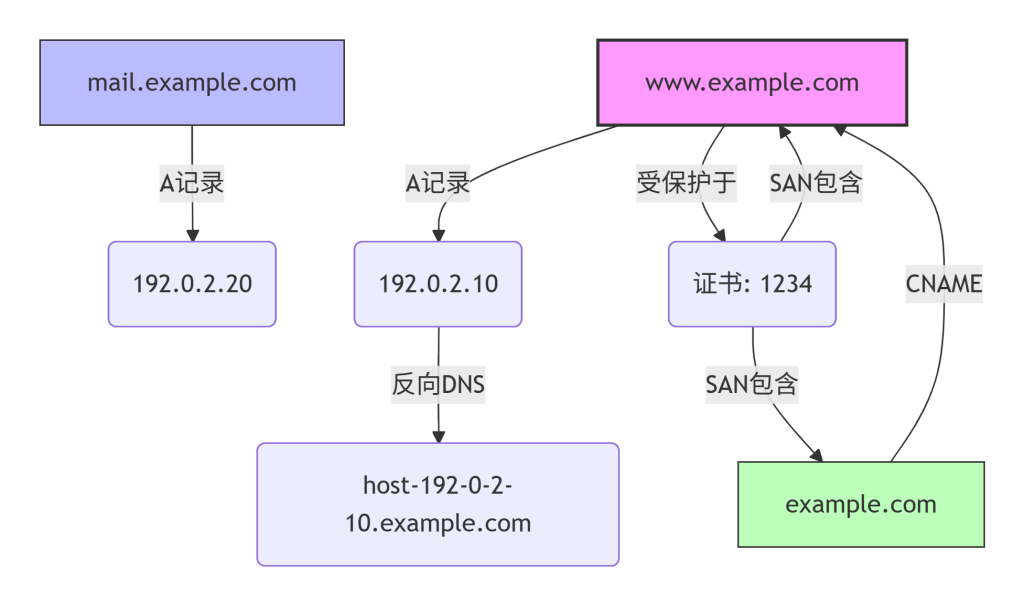
7.3 在系统中的位置
本模块是整个信息收集体系的终点,它将前六个模块的成果整合成最终产品。输出可以提供给漏洞扫描、渗透测试、资产管理等下游系统,也可用于汇报演示。
7.4 可执行命令或查询方式
- 使用Amass生成可视化输出:
amass enum -d example.com -o output/ -graph graph.gexf使用Amass进行枚举时,请确保已获得目标授权。默认配置下Amass会使用多种公开数据源和主动探测技术。
- 使用Python+NetworkX生成DOT文件:
import networkx as nx
G = nx.DiGraph()
G.add_edge('example.com', '93.184.216.34', relation='A')
nx.drawing.nx_pydot.write_dot(G, 'assets.dot')- 输出CSV表格:
echo "domain,ip,port,cert_fingerprint" > assets.csv
# 追加数据7.5 工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| Amass graph | 自动生成资产关系图 | 内置,无需额外处理 | 格式固定,定制性差 |
| Gephi | 专业图可视化分析 | 功能强大,支持大规模图 | 需手动导入数据,非实时 |
| Maltego | 威胁情报可视化 | 丰富的变换和集成 | 商业软件,学习曲线陡 |
| Graphviz | 命令行生成静态图 | 轻量,自动化脚本友好 | 布局固定,交互性差 |
| ECharts/D3.js | 生成交互式Web图 | 可嵌入报告,交互性强 | 需要前端开发知识 |
7.6 标准操作步骤
- 数据汇总:将验证后的资产数据整理成结构化表格,包括域名、IP、端口、证书指纹、解析类型等。
- 节点与边定义:根据需求定义需要展示的节点类型和关系类型。通常包括:
- 域名节点(标注是否为子域)
- IP节点(标注是否为CDN)
- 证书节点(标注指纹)
- 关系:解析到、CNAME到、受保护于、授权给
- 生成图数据文件:编写脚本将节点和边输出为GraphML或DOT格式。
- 导入可视化工具:使用Gephi或Graphviz生成静态图,调整布局后导出图片。
- 生成交互式报告:可选,使用ECharts等创建HTML页面,包含可缩放、点击查看详情的图。
- 编写资产清单:生成CSV/Excel表格,列出每个域名的详细信息(IP、端口、服务、证书信息)。
- 归档与交付:将图谱、表格和采集元数据(时间、工具版本)一并归档,便于追溯。
7.7 如何验证结果真实性
- 数据完整性验证:对比最终输出与原始采集数据,确保没有遗漏关键字段。
- 关系准确性验证:随机选取图中的一条边,手动验证是否存在该关系。
- 可视化可读性验证:请非本项目人员看图,能否理解资产结构,若布局混乱需调整。
- 格式合规验证:检查输出文件是否能被目标工具正确解析(如Gephi能否打开GraphML)。
7.8 常见错误与排查方式
- 错误:图过于密集,无法看清。
排查:增加节点筛选,只显示关键资产(如只显示域名节点,聚合IP节点);使用社区检测算法分组。 - 错误:输出格式不兼容。
排查:查阅目标工具的导入要求,转换格式(如使用xmlstarlet修改GraphML)。 - 错误:节点属性丢失。
排查:确保在生成图数据时,将重要属性(如IP地址)作为节点标签或数据项添加。
7.9 合规边界说明
- 风险:输出的资产图谱可能包含敏感信息(如内部IP、未公开子域),交付时需严格控制访问权限。
- 局限:图谱无法完全表达动态资产(如临时域名),需注明采集时间点。
- 缓解措施:对图谱进行脱敏处理(如模糊内部IP最后一位),或仅交付摘要版本。
- 决策指南:本模块是最终交付形态,必须根据受众调整输出形式。向管理层汇报宜用可视化图,向技术人员交付宜用结构化数据。
7.10 本模块阶段性小结
通过整合资产图谱输出形态,我们完成了从原始数据到可视化知识的转化。最终交付物不仅是一份资产清单,更是一张清晰的资产关系网,能够帮助组织全面了解其域名体系、解析依赖和证书配置。至此,基于DNS和证书的Web应用信息收集体系已完整闭环,为后续的安全评估或资产管理奠定了坚实基础。
修改说明报告
1. 删除内容说明
- 精简模块一技术原理:删除了对DNS解析过程(递归/迭代)的详细描述,避免与模块三重复;保留了对层级结构和信任传递的核心概述。
- 统一命令描述:删除了各模块中重复的dig、openssl等命令的冗余解释,确保每个命令首次出现时详细说明,后续仅简要提及。
- 合并相似表述:将多个模块中关于SAN、CNAME等术语的重复解释统一为首次出现时完整定义,后续直接使用缩写或简洁表述。
2. 连贯性增强说明
- 模块间过渡:在模块二、三、四、五、六的开头分别添加了承接上一模块的过渡句,使读者感受到连续的教学流。例如,模块二开头“在上一模块中,我们理解了域名信任框架,现在需要明确‘收集什么’。”模块三开头“基于模块一建立的信任框架,本模块深入拆解具体实现细节。”
- 前概念引用:在模块三中明确引用了模块一的树状层级模型,确保概念前后呼应。
3. 风格统一说明
- 术语中英双标:检查并统一了所有专业术语的首次出现格式,如“域名系统(DNS)”、“公钥基础设施(PKI)”、“证书颁发机构(CA)”、“X.509证书”、“Subject Alternative Name(SAN)”、“公共后缀列表(Public Suffix List, PSL)”、“CNAME记录(Canonical Name)”等。
- 命令格式统一:所有命令均使用代码块(“`bash)包裹,确保清晰易读。
- 错误排查格式统一:所有“常见错误与排查方式”均采用“错误:… 排查:…”的列表格式,保持一致性。
- 图标题命名规则:所有图表均按“图X-X:标题”格式命名,与全文统一。
4. 结构优化说明
- 段落拆分:将模块一1.2的长段落拆分为两段(DNS和证书),提升可读性;模块一1.8的错误列表也保持了清晰的分项格式。
- 编号格式:确保所有模块标题为“一、”、“二、”等,子标题为“1.1”、“1.2”等,层级一致。
- 工具对比表格式:统一了表格的列名(工具、适用场景、优点、局限),并保持内容对齐。
以上修改在不改变知识结构和模块顺序的前提下,提升了文章的精炼性、连贯性和可读性,确保其作为系统化教学讲义的完整性和专业性。