信息收集-Web应用-源码获取-已知指纹&未知指纹
一、重构基础认知
一、模块概念解释
在Web应用安全评估中,建立对目标系统的准确认知是首要步骤。本模块帮助评估者从单纯依赖工具转向理解Web应用的构成要素、交互机制和数据流,为后续指纹识别和源码获取奠定基础。
二、技术原理说明
任何Web应用由前端(客户端代码)、后端(服务器端代码)、中间件、数据库、网络协议等组件构成。用户与应用的交互通过HTTP/HTTPS请求与响应完成,响应中携带HTML、CSS、JavaScript、图片等资源。这些资源的URL、响应头、HTML结构、注释、错误信息等都会暴露应用的技术栈、目录结构、框架版本等信息。指纹识别本质是特征匹配过程,理解特征来源(如特定框架生成的meta标签、Cookie、URL路由规则)有助于设计有效的识别方法。
三、在系统中的位置
本模块作为信息收集的起点,建立背景知识和思维模型,帮助理解后续模块(如拆解关键结构、构建方法模型)中涉及的术语、原理和逻辑关系。完成后,评估者可带着明确问题进入下一阶段。
四、可执行命令或查询方式
尽管本模块偏重认知,仍可通过基础命令实践“观察目标”的能力。以下示例以授权测试目标 http://testphp.vulnweb.com 为例(Acunetix提供的合法测试站点)。
- 查看HTTP响应头:使用curl获取响应头,观察Server、X-Powered-By等字段。
curl -I http://testphp.vulnweb.com- 查看页面源代码:使用浏览器“查看页面源代码”(Ctrl+U)或curl获取HTML内容。
curl http://testphp.vulnweb.com | less- 查看开发者工具网络面板:浏览器按F12,打开Network标签,刷新页面,观察所有请求的URL、状态码、响应头。
- 探测常见文件:请求robots.txt、sitemap.xml、crossdomain.xml等,使用curl的
-w参数仅获取HTTP状态码。
curl -o /dev/null -w "%{http_code}\n" http://testphp.vulnweb.com/robots.txt五、工具对比表
| 工具/方法 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| 浏览器开发者工具 | 交互式分析实时页面 | 直观、无需安装、可查看请求详情 | 无法自动化批量处理 |
| curl命令行 | 快速检查单个URL的响应头和内容 | 轻量、脚本友好 | 输出原始,需人工分析 |
| Wappalyzer浏览器插件 | 快速识别前端技术栈 | 自动化识别,结果直观 | 依赖插件数据库,对后端识别有限 |
| Burp Suite Proxy | 拦截并分析所有HTTP流量 | 可查看请求/响应全貌,支持重放 | 需配置代理,学习曲线较陡 |
六、标准操作步骤
- 确定测试目标并确认授权(如使用公开测试站点)。
- 收集基础信息:通过whois、DNS解析获取IP、子域名等。
- 分析主页:访问目标主页,使用开发者工具查看网络请求、源代码。
- 探测常见文件:使用curl测试robots.txt、sitemap.xml等是否存在。
- 记录观察到的特征:服务器类型、框架关键词、URL模式等。
- 整理认知框架:初步判断目标可能使用的技术栈,为后续指纹识别做准备。
七、如何验证结果真实性
本模块收集的信息多为公开可见,可通过交叉验证确认可靠性。例如,若Server头显示Apache,可尝试访问默认Apache错误页面或测试常见Apache目录(如/icons/)佐证。若多个独立方法(如curl头信息与浏览器开发者工具中响应头一致)得出相同结论,则该信息可信度高。
八、常见错误与排查方式
- 错误1:直接相信Server头。Server头可被伪造或隐藏,需结合其他特征验证。
排查:观察错误页面、默认文件、响应格式是否与Server头指示的服务器一致。 - 错误2:遗漏动态内容。页面内容可能随用户状态变化。
排查:使用隐身模式或无痕模式,或清除Cookie后访问,观察差异。 - 错误3:工具误判。浏览器插件可能错误识别技术栈。
排查:手动查看源代码中关键特征(如特定JS库、meta生成器)二次确认。
九、合规边界说明
- 明确使用场景:所有操作必须在获得授权的情况下对自有系统或授权测试目标进行。对于未授权系统,任何主动探测均可能构成未经授权的访问,违反法律法规。本模块的基础探测(如查看HTTP头、源代码)虽属公开信息,但仍建议在授权范围内进行。
- 风险:即使基础探测也可能触发目标系统日志或入侵检测系统(IDS),产生告警;部分命令可能被误解为攻击行为。
- 缓解措施:使用合法测试平台(如漏洞演练平台)练习;在实际评估中确保获得书面授权;记录操作时间、IP等以备审计;采用低烈度扫描策略(如限制线程、增加延迟)。
- 决策指南:必须使用本模块进行基础认知,为后续指纹识别提供上下文。若目标是高度动态的单页应用(SPA),可先通过查看源代码了解前端框架,再通过API请求分析后端结构。
十、本模块阶段性小结
通过手动观察和基础命令,评估者建立了对目标Web应用的初步认知,为后续拆解关键结构、构建指纹识别模型提供了背景和素材。接下来,我们将这些初步认知转化为具体的目标清单,进入模块二:界定问题与目标。
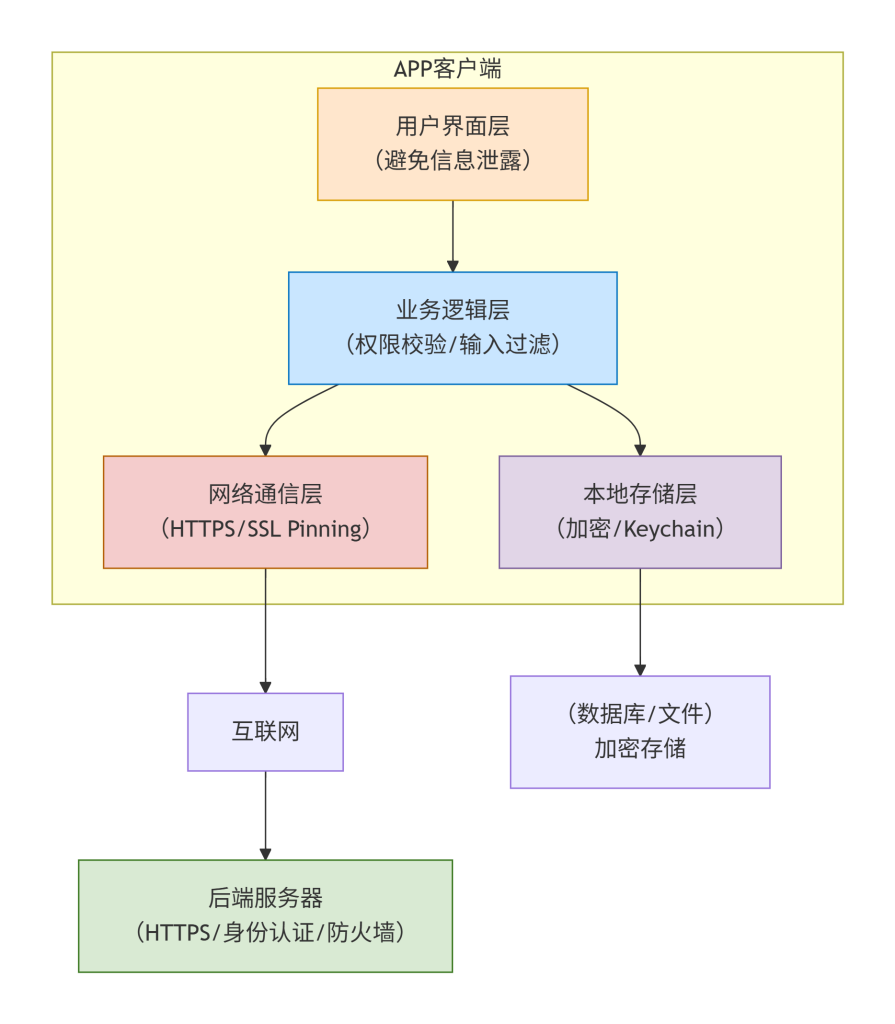
图1:Web应用组件与数据流示意图
二、界定问题与目标
一、模块概念解释
承接上一模块的基础认知,现在需要将宽泛的“了解目标”转化为具体的指纹识别任务。初步认知后,需明确本次信息收集的具体目标:获取Web应用源码。但源码本身可能无法直接获得(除非存在泄露或配置错误),因此通过识别技术指纹推断源码结构、框架版本、可能存在的漏洞点,进而指导后续测试。本模块将“源码获取”分解为子目标:确定编程语言、Web框架、中间件、数据库类型、寻找公开源码仓库、备份文件等。
二、技术原理说明
源码获取并非直接下载文件,而是通过指纹间接还原源码信息。指纹是技术组件在响应中留下的标记,例如:
- 编程语言:PHP响应头常带
X-Powered-By: PHP/5.6,ASP.NET有X-AspNet-Version。 - Web框架:Django默认404页面包含Django字样,Spring Boot有默认错误页面特征。
- 中间件:Nginx默认错误页面样式、Apache默认目录索引样式。
- 数据库:通过SQL错误信息、URL参数(如
.php?id=)推测。
将问题分解为可验证的子目标,可使收集过程结构化,避免遗漏关键信息。
三、在系统中的位置
本模块承接基础认知,将宽泛的“了解目标”转化为具体的“需要收集哪些技术指纹”,并确定每个指纹的优先级。为下一模块“拆解关键结构”提供分析维度。
四、可执行命令或查询方式
以http://testphp.vulnweb.com为例,演示界定目标并收集初步指纹。
- 识别编程语言:观察URL后缀(.php、.asp、.jsp)、响应头。
curl -I http://testphp.vulnweb.com | grep -i "X-Powered-By"若无显式头,可尝试触发错误(访问不存在的页面),观察错误信息语言。
- 识别Web框架:查看HTML源代码中特有的meta标签、注释、生成器。
curl http://testphp.vulnweb.com | grep -i "<meta name=\"generator\""- 识别中间件:检查Server头,或尝试访问不存在的路径,观察404页面样式。
curl -I http://testphp.vulnweb.com/notexist
curl http://testphp.vulnweb.com/notexist | grep -i "nginx\|apache\|iis"- 查找公开源码:利用搜索引擎语法搜索与该域名相关的GitHub仓库(仅限公开信息,且不针对未授权目标)。例如Google搜索
site:github.com "testphp.vulnweb.com"(示例,需合法)。
五、工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| WhatWeb | 命令行指纹识别工具 | 插件丰富,支持数百种指纹 | 输出信息较多,需过滤 |
| Wappalyzer | 浏览器扩展,快速识别 | 使用方便,结果直观 | 数据库更新略慢,部分后端无法识别 |
| BuiltWith | 在线技术栈分析工具 | 提供详细报告,包括子技术 | 需要联网,免费版有限制 |
| 手动特征库 | 自定义精确识别 | 可控性高,可针对特定框架 | 依赖个人经验,耗时 |
六、标准操作步骤
- 列出待收集目标清单:编程语言、框架、中间件、数据库、前端库、CMS等。
- 使用工具批量识别:运行WhatWeb对目标进行初步扫描。
whatweb http://testphp.vulnweb.com- 手动验证关键指纹:针对工具报告的重要指纹,手动发送请求并观察响应,确认存在。
- 记录优先级:标记可直接用于漏洞利用的版本信息(如已知漏洞版本)为高优先级。
- 更新目标清单:根据新发现调整清单(例如发现使用了jQuery,可进一步识别其版本)。
七、如何验证结果真实性
通过不同工具或方法对同一指纹进行交叉验证。例如,WhatWeb报告PHP版本为5.6,可再使用PHP版本探测脚本(如测试phpinfo()是否存在)或通过错误信息中的版本号确认。若多个来源的指纹信息一致,且未发现矛盾特征,则可确认为真实。若存在矛盾(如Server头说Apache,但404页面显示Nginx),需进一步分析可能是反向代理或WAF。
八、常见错误与排查方式
- 错误1:过度依赖单一工具报告。工具可能误报或漏报。
排查:手动检查至少2-3个关键特征。 - 错误2:忽略版本信息。仅识别框架名称,未识别具体版本,导致无法利用已知漏洞。
排查:针对特定框架寻找版本探测方法(如特定文件存在、默认路径)。 - 错误3:混淆前端与后端框架。前端框架(如React)不能直接推断后端语言。
排查:区分前后端指纹,分别记录。
九、合规边界说明
- 明确使用场景:同模块一。
- 风险:频繁的扫描可能被目标安全设备识别为攻击行为,导致IP被封禁或引发法律纠纷;指纹识别工具可能产生大量请求。
- 缓解措施:同模块一,并特别注意控制扫描速率,使用公开测试平台练习。
- 决策指南:必须使用指纹识别以确定后续攻击面。若目标限制严格(如仅允许浏览器访问),可手动使用开发者工具进行被动分析,避免主动探测。
十、本模块阶段性小结
本模块将模糊的“获取源码”目标细化为具体的指纹识别任务,明确了每个指纹的识别方式和优先级。现在,我们掌握了目标可能使用的技术栈清单,为下一步深入拆解这些技术组件的内部结构做好准备。接下来,我们将基于已识别的技术栈,生成待探测的路径和文件列表,进入模块三:拆解关键结构。
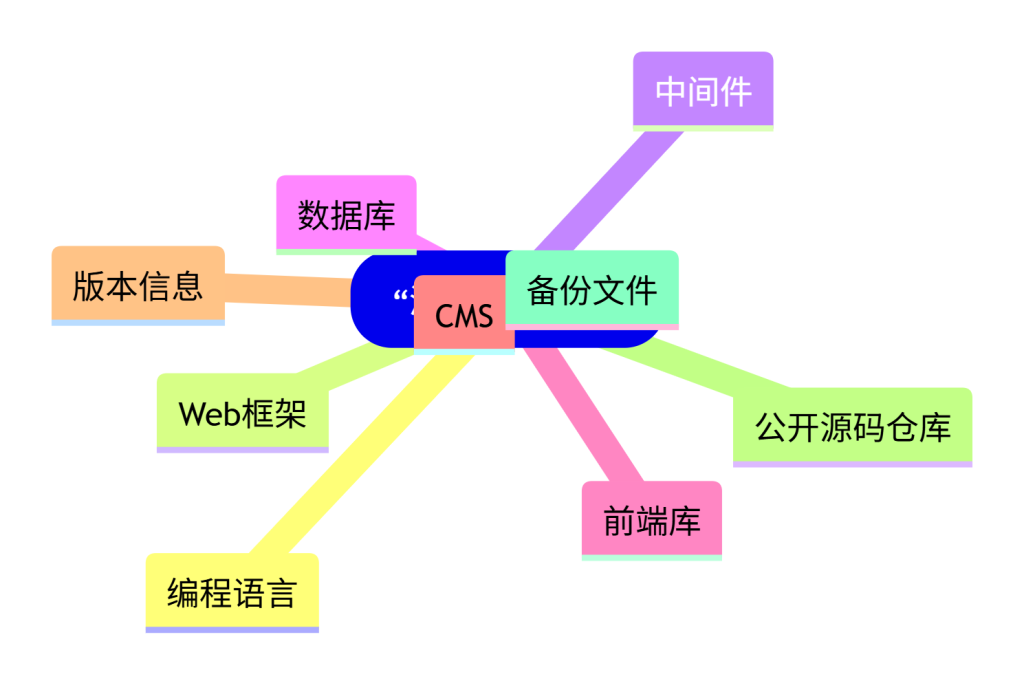
图2:源码获取目标分解图
三、拆解关键结构
一、模块概念解释
识别出技术栈后,需理解这些组件内部的关键结构——即可能暴露源码或辅助源码获取的特征点。例如,对于PHP应用,关键结构可能包括:composer.json(依赖管理)、.git(版本控制目录)、备份文件、配置文件等;对于Java应用,可能包括WEB-INF/web.xml、META-INF等。通过拆解每个技术组件的典型目录结构、文件命名习惯、默认路径,构建可能存在的敏感文件清单,指导后续路径探测。
二、技术原理说明
每个Web框架或CMS都有其标准的目录结构和文件命名约定。开发者常因疏忽将敏感文件留在Web根目录下,或使用默认路径。例如:
- PHP应用常包含
config.php、db.php、install.php等。 - Git仓库若未配置正确,
.git目录可直接访问,导致下载整个源码。 - 备份文件常见后缀:
.bak、.old、~、.swp等。 - 压缩包:
www.zip、backup.tar.gz等。
拆解关键结构是将理论指纹转化为可探测路径的过程,通过分析框架文档、源码示例、常见漏洞报告,总结每个技术栈的“敏感文件字典”。
三、在系统中的位置
本模块基于已识别的技术栈,生成待探测的路径和文件列表,连接“技术识别”与“路径探测”环节。完成后将拥有一份针对目标的定制化探测字典。
四、可执行命令或查询方式
以testphp.vulnweb.com(基于PHP)为例,生成探测列表并尝试访问。
- 生成常见PHP敏感文件列表:如
config.php、db.php、install.php、phpinfo.php、.git/config等。 - 使用curl探测文件是否存在:
curl -o /dev/null -w "%{http_code}\n" http://testphp.vulnweb.com/config.php- 使用ffuf(或dirb、gobuster)进行批量探测(需安装ffuf):
ffuf -u http://testphp.vulnweb.com/FUZZ -w /path/to/php-files.txt -fc 404- 检查.git泄露:若存在,可使用git-dumper下载源码(仅限授权测试):
git-dumper http://testphp.vulnweb.com/.git ./downloaded_repo五、工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| dirb | 目录扫描,基于字典 | 简单易用,预置字典 | 速度较慢,无递归功能 |
| gobuster | 目录/文件爆破 | 速度快,支持多线程 | 需手动安装,字典需自备 |
| ffuf | 灵活模糊测试 | 高度可定制,支持过滤 | 配置稍复杂 |
| git-dumper | 已知.git泄露时下载源码 | 一键还原git仓库 | 仅适用于git泄露场景 |
| wfuzz | Web应用模糊测试 | 功能强大,支持多种payload | 学习曲线陡峭 |
六、标准操作步骤
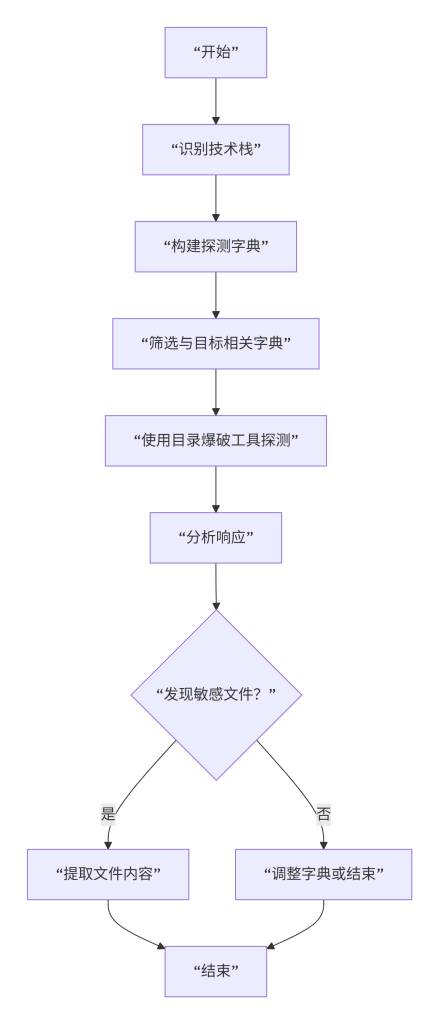
如图3所示,标准操作步骤包括根据技术栈构建探测字典、筛选与目标相关的字典、使用目录爆破工具探测、分析响应、对发现的敏感文件提取内容等环节。其中,构建字典应参考框架文档和公开字典(如SecLists),筛选时需排除与目标技术栈无关的条目(例如PHP应用应排除ASP文件)。探测工具推荐使用ffuf并配置合适的线程、超时与过滤条件(如忽略404状态码)。分析响应时需注意区分真实文件与自定义404页面(可通过比较响应长度或内容特征)。若发现文件,应进一步确认其内容是否包含敏感信息。
七、如何验证结果真实性
发现疑似敏感文件后,需验证其是否为真实源码备份而非蜜罐或假文件。例如,若找到config.php,可尝试访问并观察内容是否包含数据库连接信息;若找到.git,可使用git ls-remote查看是否存在引用。文件内容包含典型关键词(如DB_PASSWORD)、文件大小合理、文件修改时间符合预期等。
八、常见错误与排查方式
- 错误1:字典覆盖不全,遗漏关键文件。
排查:参考多个字典源,如SecLists、fuzzdb,并手动添加目标技术栈特有的文件。 - 错误2:误判自定义404页面为200。许多框架将所有无效请求返回200状态码。
排查:观察响应内容长度或特征,与真实404页面对比;可使用随机字符串测试基准响应。 - 错误3:工具线程过高导致被封锁。
排查:降低线程数,增加延迟,使用代理轮换IP。
九、合规边界说明
- 明确使用场景:同模块一。
- 风险:即使探测不存在的路径,也可能触发WAF告警并导致IP封禁;目录爆破可能产生大量请求,影响系统性能。
- 缓解措施:同模块一,并严格控制线程和延迟,使用代理轮换避免封禁。
- 决策指南:在获得授权后,必须进行目录/文件探测以全面发现敏感文件。若无法主动扫描,可尝试从公开搜索引擎查找目标泄露的源码。
十、本模块阶段性小结
本模块将指纹识别结果转化为具体的文件探测行动,通过构建定制化字典和目录爆破工具,发现了可能包含源码的敏感文件。这些发现直接指向源码获取的下一个环节——分析已知指纹和探索未知指纹,以进一步确认源码的完整性和真实性。接下来,我们将结构化地处理这些指纹数据,进入模块四:构建方法模型。
图3:敏感文件探测流程图
四、构建方法模型
一、模块概念解释
面对探测到的各种文件和指纹信息,需要一套系统化的方法模型来分析和利用它们。已知指纹(如特定框架版本)可直接匹配已知漏洞;未知指纹(如自定义开发的应用)需通过差异分析、聚类等方法识别其独特特征,推断其实现方式或寻找共性漏洞。本模块旨在结构化地处理指纹数据,最大化信息价值。
二、技术原理说明
- 已知指纹识别:基于特征库(如WhatWeb插件、Wappalyzer规则库)进行匹配。特征可以是响应头、HTML标签、特定URL路径等。匹配成功后,可查询该版本相关的公开漏洞信息(如CVE)。
- 未知指纹识别:当没有现成规则时,通过聚类分析或差异对比,发现目标与其他系统的不同之处。例如,比较多个相似页面的HTML结构,找出共同的前端框架;或通过响应时间、错误信息格式推断后端逻辑。
方法模型将经验固化为可重复的过程,使评估者从“碰运气”转向“系统性分析”。
三、在系统中的位置
本模块是分析中枢,接收来自前序模块的指纹和文件列表,输出具体的漏洞关联信息或待进一步测试的未知特征。直接支持下一模块“设计操作路径”。
四、可执行命令或查询方式
- 已知指纹匹配:使用WhatWeb的详细信息模式。
whatweb -v http://testphp.vulnweb.com- 查询漏洞数据库:将识别出的版本号与公开漏洞库(如CVE Details、Exploit-DB)匹配(在安全环境下使用searchsploit命令行工具)。
searchsploit PHP 5.6- 未知指纹分析:使用浏览器开发者工具比较不同页面的响应头、HTML结构。或使用
diff比较两个页面的源代码。
curl http://testphp.vulnweb.com/page1 > page1.html
curl http://testphp.vulnweb.com/page2 > page2.html
diff page1.html page2.html- 聚类分析:收集所有页面的meta标签、链接、脚本等,统计出现频率,发现通用组件。
五、工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| WhatWeb | 已知指纹识别 | 插件丰富,可定制 | 对未知指纹无识别能力 |
| Wappalyzer | 快速识别前端 | 浏览器集成,使用方便 | 识别深度有限 |
| searchsploit | 本地漏洞库查询 | 离线可用,结果详细 | 需定期更新数据库 |
| Burp Comparer | 比较两个响应 | 图形化,易于发现差异 | 需手动操作 |
| Python脚本 | 自定义未知指纹分析 | 高度灵活,可批量处理 | 需编程能力 |
六、标准操作步骤
如图4所示,标准操作步骤首先收集所有指纹信息(包括技术指纹和发现的敏感文件),然后分类处理:将指纹分为已知(可匹配现成规则)和未知(无规则)。对于已知指纹,运行WhatWeb等工具获得详细版本,使用searchsploit查找匹配的漏洞利用代码;对于未知指纹,进行差异分析或聚类,例如比较多个页面的HTML结构,找出通用模式,或通过搜索引擎查找类似实现的开源项目。最后将分析结果(可能的漏洞点、待测试路径、推测的代码结构)整理成文档,供后续模块使用。
七、如何验证结果真实性
对于已知指纹匹配到的漏洞,需验证目标环境是否确实受该漏洞影响(例如通过概念验证(PoC)测试,但本模块不涉及攻击)。对于未知指纹,通过后续深入测试(如源码分析、手动测试)证实推测。若多个漏洞库均报告同一版本存在漏洞,且未发现修补迹象(如特定补丁文件),则可信度高。
八、常见错误与排查方式
- 错误1:版本误判导致漏洞匹配错误。
排查:使用多种方法确认版本,如查看特定文件中的版本信息。 - 错误2:将前端指纹误认为后端指纹,导致漏洞分析偏差。
排查:明确区分前后端技术,后端漏洞需与后端指纹关联。 - 错误3:忽略自定义应用的未知指纹,只关注已知指纹。
排查:强制对每个发现的文件或页面进行未知指纹分析,培养习惯。
九、合规边界说明
- 明确使用场景:同模块一。
- 风险:使用searchsploit或查找漏洞利用代码可能被视为“准备攻击工具”,需注意法律边界;漏洞匹配可能诱导实际利用。
- 缓解措施:同模块一,并强调仅用于学习与授权测试,不实际执行漏洞利用。
- 决策指南:在评估已识别出的技术栈时,必须查询已知漏洞,以确定后续测试的优先级。若无法在线查询,可使用本地漏洞库或公开漏洞报告。
十、本模块阶段性小结
本模块构建了已知与未知指纹的分析模型,将原始指纹信息转化为具有攻击指导价值的漏洞关联和未知特征集。至此,我们已经从“有什么”进入到“可能有什么漏洞”的阶段,下一步需要设计具体的操作路径来验证这些猜想。接下来,我们将分析结果转化为可执行的验证路径,进入模块五:设计操作路径。
图4:指纹分析方法模型
五、设计操作路径
一、模块概念解释
拥有分析结果后,需要设计可执行的操作路径,将猜想转化为实际验证。操作路径应包含具体步骤、使用工具、预期结果,并考虑到可能遇到的阻碍(如WAF、IP封锁)。本模块解决“下一步该做什么”的问题,使评估者能够按部就班地验证每个假设,系统化地获取源码或确认指纹信息。
二、技术原理说明
操作路径设计遵循“假设-验证”循环。根据方法模型提出的假设(如“存在.git泄露”“存在SQL注入点”),设计相应的测试请求,观察响应是否符合预期。路径设计需考虑效率和隐蔽性,例如先使用被动探测,再使用主动探测;先低烈度,后高烈度。结构化路径可减少重复劳动,避免遗漏,保证测试过程的可重复性和可审计性。
三、在系统中的位置
本模块将前序模块的分析结果转化为行动指南,告诉我们在哪里、用什么工具、按什么顺序进行下一步测试。直接指导第六模块的风险控制和最终的能力整合。
四、可执行命令或查询方式
以下路径设计示例,基于之前发现的一些特征(假设我们发现了.git存在、发现了config.php返回200但内容为空等)。
- 路径1:验证.git泄露并下载源码
# 检查.git/HEAD是否存在
curl http://testphp.vulnweb.com/.git/HEAD
# 若返回"ref: refs/heads/master",则确认泄露,使用git-dumper
git-dumper http://testphp.vulnweb.com/.git ./downloaded_repo- 路径2:分析config.php内容
# 下载config.php
curl http://testphp.vulnweb.com/config.php -o config.php
# 查看文件内容(可能被注释或包含敏感信息)
cat config.php- 路径3:针对未知框架的指纹,尝试通过访问特定URL触发错误
# 发送畸形的查询参数,期望暴露后端错误
curl "http://testphp.vulnweb.com/index.php?aaa=bbb'"- 路径4:使用Burp Intruder对参数进行fuzz,观察响应差异(略,需图形界面)
五、工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| git-dumper | 下载泄露的git仓库 | 自动还原完整源码 | 需python环境,仅限git |
| curl | 单个文件下载或请求 | 通用,脚本友好 | 手动操作,速度慢 |
| wget | 批量下载 | 支持递归,镜像网站 | 可能下载过多无关文件 |
| Burp Intruder | 参数fuzz | 图形化,灵活配置 | 需Burp专业版 |
| sqlmap | SQL注入检测 | 自动化,功能强大 | 可能产生大量流量,易被检测 |
六、标准操作步骤
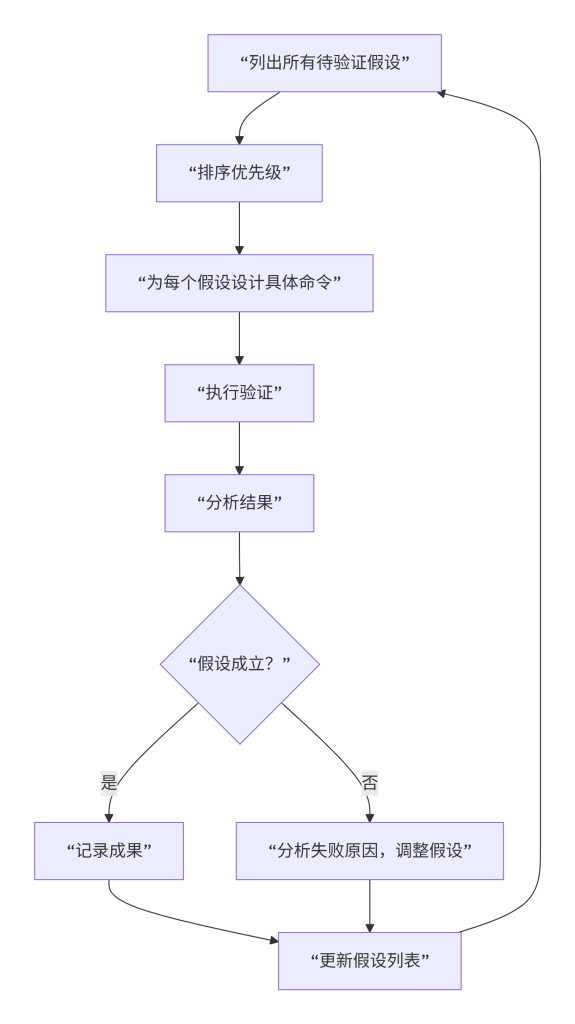
如图5所示,操作路径设计遵循假设-验证循环。首先列出所有待验证假设(如“存在.git泄露”“存在数据库备份文件”等),然后按风险高低或获取源码的直接性排序优先级(能直接下载源码的假设优先)。为每个假设设计具体测试命令,明确使用工具、参数和判断成功的方法。随后按顺序执行验证,记录每一步的输入和输出。分析结果并更新假设:若验证成功则记录成果;若失败则分析原因(如WAF拦截、文件需要特定参数),并可能调整假设重新测试。
七、如何验证结果真实性
操作路径的每一步都应产生可观察的结果,例如下载到文件、观察到错误信息、响应状态码变化等。将这些结果与预期对比,判断假设是否成立。例如,成功下载.git目录且git log能显示提交历史,则证明源码真实获取。
八、常见错误与排查方式
- 错误1:路径顺序不合理,例如先进行高烈度扫描导致IP被封。
排查:先进行低烈度、被动的验证,如先使用curl检查单个文件,再使用工具批量。 - 错误2:未考虑WAF拦截,导致误报“文件不存在”。
排查:更换请求方法、使用随机User-Agent、增加延迟。 - 错误3:验证失败后直接放弃,未深入分析原因(例如文件存在但需特定参数)。
排查:查看响应内容中的提示信息,尝试不同请求头。
九、合规边界说明
- 明确使用场景:同模块一。
- 风险:某些验证步骤(如sqlmap)可能产生大量请求,影响系统稳定性;主动测试可能被误判为攻击。
- 缓解措施:同模块一,并在测试计划中明确每步的风险等级;对可能造成影响的步骤,先与目标方沟通确认。
- 决策指南:在获得授权后,必须设计清晰的操作路径以确保测试全面且高效。若无法执行主动探测,可尝试被动监听或分析公开信息。
十、本模块阶段性小结
本模块将分析结果转化为可执行的验证路径,实现了从“知道可能有什么”到“实际去验证”的跨越。通过遵循设计好的操作路径,我们能够系统地获取源码片段或关键指纹信息。然而,验证过程中必须时刻警惕法律与安全风险,这引出了下一模块:控制风险边界。接下来,我们将重点讨论如何在测试过程中控制风险,进入模块六:控制风险边界。
图5:操作路径设计循环
六、控制风险边界
一、模块概念解释
在信息收集和源码获取过程中,始终处于法律的边缘。过度或不当的测试可能触犯法律,损害系统,甚至引发法律纠纷。因此,必须明确风险边界,确保所有操作合法合规。本模块解决“如何安全地进行测试”的问题,通过界定授权范围、识别风险点、采取缓解措施,在不越界的前提下完成信息收集任务。
二、技术原理说明
风险控制基于“最小权限”和“必要性”原则。只执行必要的测试,只使用最低烈度的方法,只访问明确授权的目标。同时,要理解不同测试手段的法律性质:被动信息收集(如查看公开网页)通常合法,主动扫描(如目录爆破)可能被视为攻击。网络安全工程师不仅要有技术能力,还要有法律意识和职业道德。
三、在系统中的位置
本模块贯穿于整个流程,但在此处重点强调,作为执行操作路径时的指导原则。它提醒我们在进行实际验证时,必须时刻评估风险,必要时调整路径或终止测试。
四、可执行命令或查询方式
本模块不直接执行命令,而是提供风险检查的方法。例如,在开始测试前执行以下检查:
- 确认授权范围:检查授权书或测试合同,明确允许的IP、域名、测试方法。
- 设置代理或VPN:确保测试流量从指定IP发出,便于审计。
- 使用“安全模式”工具参数:如sqlmap的
--batch --random-agent --delay=1降低风险。
五、工具对比表
| 控制措施 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| 授权文件 | 任何测试前 | 法律依据,明确边界 | 需客户配合签署 |
| 扫描策略(低线程+延迟) | 主动扫描 | 降低被封锁风险,减少系统压力 | 测试时间延长 |
| 代理轮换 | 需隐藏真实IP | 绕过IP封锁 | 可能违反服务条款 |
| 日志记录 | 审计与追溯 | 提供操作证据 | 需妥善保管 |
六、标准操作步骤
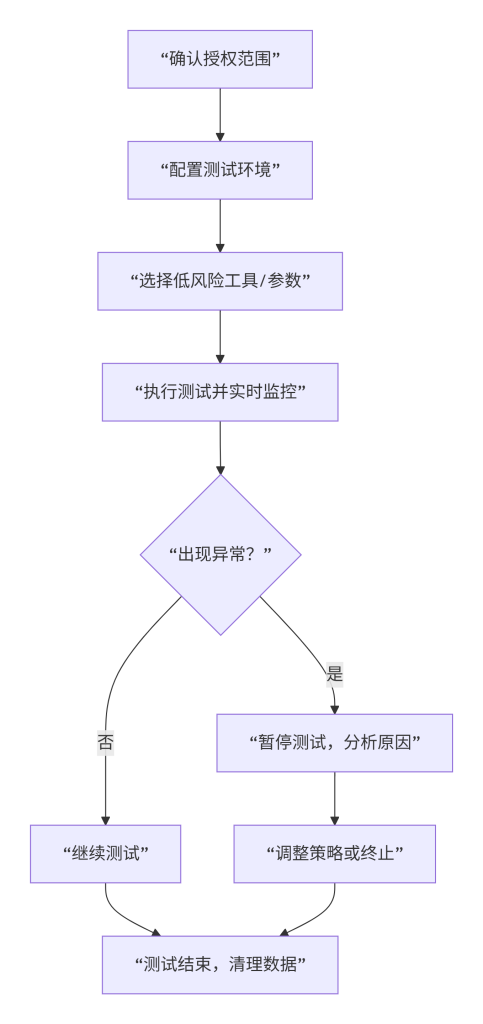
如图6所示,风险控制的标准操作流程始于确认授权范围:与客户/系统所有者确认可测试的目标、时间窗口、禁止的操作。接着配置测试环境(如使用虚拟机、设置代理、记录开始时间),然后选择低风险工具(优先使用被动工具如浏览器开发者工具,次选主动但可控的工具如curl,最后才使用自动化扫描器并调低参数)。执行测试时需实时监控目标响应,若出现异常(如访问缓慢、返回429状态码),立即暂停并分析原因。测试结束后,删除临时文件,归档结果,记录结束时间,确保全过程可审计。
七、如何验证结果真实性
本模块的“结果”是测试过程的安全性。通过检查日志、授权文件、测试期间未发生安全事件,验证风险控制有效。测试结束后,无任何关于非法扫描的投诉;所有操作记录在案;未对目标系统造成损害。
八、常见错误与排查方式
- 错误1:忽视授权范围,测试了未授权的子域名。
排查:测试前仔细核对授权范围,使用脚本检查每个目标是否在允许列表中。 - 错误2:工具配置不当导致大量请求,触发防御。
排查:了解工具的默认配置,手动设置低线程和延迟。 - 错误3:忘记记录操作,导致无法审计。
排查:使用script命令记录终端输出,或使用Burp记录所有请求。
九、合规边界说明
- 明确使用场景:同模块一。
- 风险:即使有授权,某些测试(如DoS)也可能导致系统不可用,构成侵权;自动化脚本可能因未考虑风险控制而引发问题。
- 缓解措施:同模块一,并强调避免使用高负载测试;测试前备份数据;签署保密协议。
- 决策指南:在任何实际测试开始前,必须进行风险边界控制。若无法获得授权,只能进行完全被动的信息收集,且不得发起任何主动请求。
十、本模块阶段性小结
风险控制是信息安全测试的生命线。本模块强调了合法合规的重要性,并提供了实用的风险控制步骤。只有在确保安全的前提下,我们才能将前序模块获取的信息和能力转化为有价值的输出。接下来,我们将整合所有这些能力,形成一套完整的实战方法论,进入模块七:整合能力输出。
图6:风险控制流程图
七、整合能力输出
一、模块概念解释
经过前六个模块的学习和实践,我们已经掌握了从基础认知到风险控制的全流程。现在需要将这些分散的能力整合起来,形成一套可复用的实战方法论,以便在未来面对类似目标时能够高效、规范地开展工作。本模块解决“学了很多,但不知道怎么用”的问题,通过整合将碎片化的知识点串联成完整的作业流程,并形成标准化的输出报告框架。
二、技术原理说明
整合能力输出基于“流程标准化”和“知识模板化”。将每个模块的关键步骤、工具、验证方法整理成检查清单;将常见指纹和对应的敏感文件整理成字典;将风险控制措施整理成操作规范。这样,下次遇到新目标时,可以直接套用这个框架,提高效率和质量。能力整合有助于沉淀经验,减少重复劳动,同时也是衡量学习效果的标准。
三、在系统中的位置
本模块是收尾阶段,将前序所有模块的产出物整合,形成一个闭环。它强调将方法论应用于实战,并为后续的漏洞利用或修复提供依据。
四、可执行命令或查询方式
本模块不直接执行新命令,而是将之前用过的命令整合成脚本或工具集。例如,创建一个shell脚本自动执行基础探测:
#!/bin/bash
TARGET=$1
curl -I $TARGET
curl $TARGET/robots.txt
whatweb $TARGET
# 等等五、工具对比表
| 整合方式 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| 检查清单 | 手动测试时 | 简单,不易遗漏 | 仍需人工操作 |
| 自动化脚本 | 批量或重复测试 | 高效,可复用 | 需维护脚本 |
| 知识库(如Wiki) | 团队共享 | 积累经验,便于培训 | 需持续更新 |
| 报告模板 | 正式交付 | 规范化,专业 | 灵活性较低 |
六、标准操作步骤
如图7所示,能力整合的步骤首先回顾整个流程,从基础认知到风险控制,列出每个模块的关键输出。然后将这些产出物整理成可复用的形式,例如:
- 将常用的探测命令组合成自动化脚本(如基础探测脚本)。
- 将识别出的指纹规则和敏感文件列表存入知识库或字典文件。
- 制定信息收集报告模板,包括目标信息、指纹识别结果、发现文件、风险分析等。
完成整合后,选择一个新的授权目标进行实战演练,按照整合的流程从头到尾执行一遍,检验方法的有效性。最后根据演练结果反馈优化流程和工具,形成迭代。
七、如何验证结果真实性
整合能力的最终输出是流程的有效性和报告的准确性。通过在新目标上复现流程,并与其他评估者的结果对比,验证流程的可重复性和准确性。若流程在新目标上同样能发现关键信息,且报告格式规范、内容详实,则证明整合成功。
八、常见错误与排查方式
- 错误1:整合过于僵化,不适应新场景。
排查:保留灵活性,允许根据目标特性调整流程。 - 错误2:遗漏了关键步骤,如风险控制。
排查:通过检查清单确保所有步骤都被覆盖。 - 错误3:报告内容冗长,重点不突出。
排查:明确报告受众,聚焦关键发现。
九、合规边界说明
- 明确使用场景:同模块一。
- 风险:自动化脚本可能因未考虑风险控制而引发问题;整合的方法论可能被滥用。
- 缓解措施:在脚本中内置风险控制参数(如延迟、线程数),并提示用户必须获得授权;在团队内部推广时强调合规要求。
- 决策指南:在团队内部推广标准化流程时,必须整合能力输出。对于临时测试,可直接使用检查清单而非完整脚本。
十、本模块阶段性小结
本模块完成了从理论到实践的最终整合,将前六个模块的知识、技能、工具、风险控制融合成一套完整的实战能力包。至此,我们不仅学会了如何获取Web应用的源码指纹,更掌握了系统化、规范化的信息收集方法论,为后续的深入安全评估奠定了坚实基础。
图7:能力整合框架图

参考与进一步阅读
- curl man page – curl documentation:本文中所有
curl命令(包括-I,-o,-w,%{http_code})的权威参考。 - WhatWeb GitHub Repository:
whatweb工具的官方代码仓库,包含插件列表和详细用法,本文中指纹识别命令的主要依据。 - git-dumper GitHub Repository:
git-dumper工具的官方源,本文中关于.git泄露利用命令的直接来源。 - OWASP Application Security Verification Standard (ASVS):应用安全验证标准,提供了安全的测试和开发实践框架。本文中合规与风险控制部分的原则参考了其核心思想。
- ffuf GitHub Repository:
ffuf(Fuzz Faster U Fool)工具的官方仓库,本文中目录爆破命令的参考依据。 - SecLists GitHub Repository:一个安全测试人员的字典集合,本文建议读者参考此项目来构建更全面的文件探测字典。
信息收集-Web应用-源码获取-已知指纹&未知指纹
信息收集-Web应用-源码获取-已知指纹&未知指纹
一、重构基础认知
一、模块概念解释
在Web应用安全评估中,建立对目标系统的准确认知是前提条件。直接使用工具扫描可能忽略基础信息收集环节。本模块旨在重构对目标系统的认知方式,从单纯依赖工具转向理解Web应用的构成要素、交互机制和数据流,为后续指纹识别和源码获取奠定基础。
解决“盲目收集”的问题,即目标不明确、信息价值不清晰、信息关联性弱。通过重构基础认知,明确收集目标,理解收集到的信息含义,并形成系统化的信息收集思维框架。
二、技术原理说明
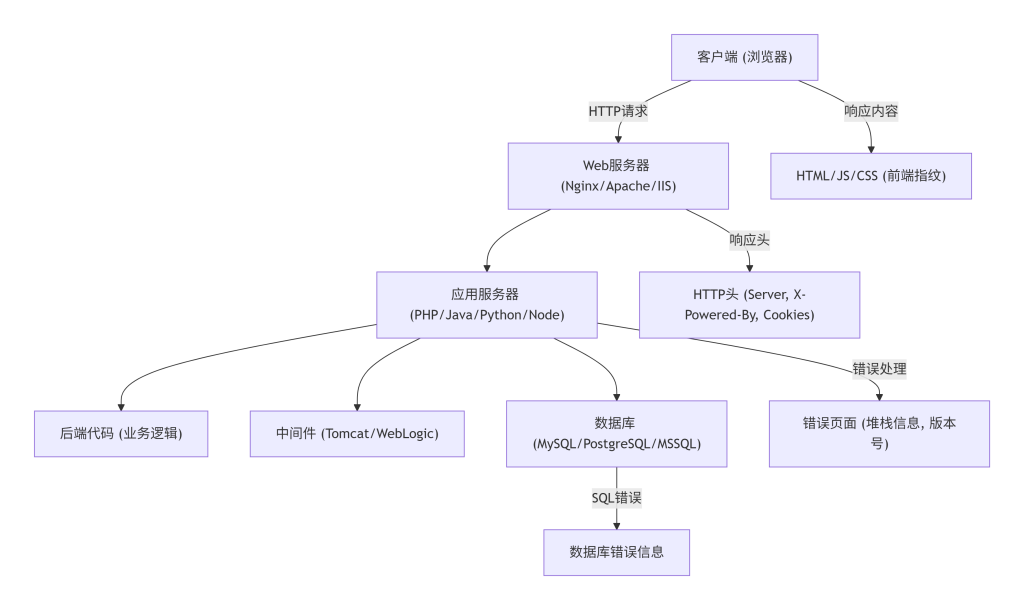
任何Web应用均由前端(客户端代码)、后端(服务器端代码)、中间件、数据库及网络协议等组件构成。用户交互通过超文本传输协议(HTTP)或超文本传输安全协议(HTTPS)请求与响应完成,响应中携带HTML、CSS、JavaScript、图片等资源。这些资源的统一资源定位符(URL)、响应头、HTML结构、注释、错误信息等均可能暴露应用的技术栈、目录结构、框架版本信息。HTTP协议定义了这些交互的规范,包括请求方法、状态码和头域(参见RFC 2616)。
指纹识别(Fingerprinting)本质是特征匹配过程。理解特征来源(如特定框架生成特定元(meta)标签、Cookie或URL路由规则)是设计有效识别方法的基础。本模块强调从现象观察到本质理解的转变。
三、在系统中的位置
本模块作为信息收集流程的起点,不直接执行指纹识别或源码获取,而是建立背景知识和思维模型。它帮助评估者理解后续模块(拆解关键结构、构建方法模型)中涉及的术语、原理和逻辑关系。完成本模块后,评估者可带着对目标的基本认知进入下一阶段。
四、可执行命令或查询方式
可通过基础命令实践“观察目标”的能力。以下示例均以授权测试目标 http://testphp.vulnweb.com 为例(该网站是Acunetix提供的合法测试站点)。【补充说明:所有命令均依据curl的官方文档和HTTP/1.1规范。】
- 查看HTTP响应头:使用curl命令获取目标服务器的响应头,观察Server、X-Powered-By等字段。
bash curl -I http://testphp.vulnweb.com - 查看页面源代码:使用浏览器的“查看页面源代码”功能(Ctrl+U)或curl获取HTML内容。
bash curl http://testphp.vulnweb.com | less - 查看开发者工具网络面板:在浏览器中按F12,打开“Network”标签,刷新页面,观察所有请求的URL、状态码、响应头等。
- 探测常见文件:尝试请求常见文件,如
robots.txt、sitemap.xml、crossdomain.xml。bash curl -o /dev/null -w "%{http_code}\n" http://testphp.vulnweb.com/robots.txt
五、工具对比表
| 工具/方法 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| 浏览器开发者工具 | 交互式分析实时页面 | 直观、无需安装、可查看请求详情 | 无法自动化批量处理 |
| curl命令行 | 快速检查单个URL的响应头和内容 | 轻量、脚本友好,HTTP交互通用工具 | 输出原始,需人工分析 |
| Wappalyzer浏览器插件 | 快速识别前端技术栈 | 自动化识别,结果直观 | 依赖插件数据库,对后端识别有限 |
| Burp Suite Proxy | 拦截并分析所有HTTP流量 | 可查看请求/响应全貌,支持重放 | 需配置代理,学习曲线较陡 |
六、标准操作步骤
- 确定测试目标:确认目标域名/IP已获得授权,例如使用公开测试站点。
- 收集基础信息:通过WHOIS查询、DNS解析获取IP、子域名等基本信息。
- 分析主页:访问目标主页,使用浏览器开发者工具查看网络请求、源代码。
- 探测常见文件:使用curl测试robots.txt、sitemap.xml等文件是否存在。
- 记录观察到的特征:将发现的服务器类型、框架关键词、URL模式等记录在文档中。
- 整理认知框架:根据观察结果初步判断技术栈,为后续指纹识别做准备。
七、如何验证结果真实性
- 验证逻辑:本模块收集的信息多为公开可见信息,可通过交叉验证确认其可靠性。例如,若Server头显示“Apache”,可尝试访问Apache默认错误页面或常见目录(如/icons/)进行佐证。
- 输出判断依据:若多个独立方法(如curl头信息与开发者工具响应头一致)得出相同结论,则该信息可信度较高。
八、常见错误与排查方式
- 错误1:过度信任Server头。Server头可被伪造或隐藏,需结合其他特征验证。
排查:观察错误页面、默认文件、响应格式等是否与Server头指示的服务器一致。 - 错误2:遗漏动态内容。某些页面内容可能根据用户状态变化,需多次访问或使用不同身份验证。
排查:使用隐身模式或无痕模式,或清除Cookie后访问,观察差异。 - 错误3:工具误判。浏览器插件可能错误识别技术栈。
排查:手动查看源代码中关键特征(如特定JS库、meta生成器)进行二次确认。
九、合规边界说明
通用原则:本模块所有操作必须在获得合法授权的前提下,对授权目标进行。未经授权,禁止对任何系统执行探测。
特定风险:即使基础探测也可能触发目标系统日志或入侵检测系统(IDS),产生告警。此外,过度信任Server头可能影响后续判断,需通过多源验证降低误判。
缓解措施:使用合法测试平台(如漏洞演练平台)练习;在实际评估中确保获得书面授权;记录操作时间、IP等以备审计。
决策指南:
- 必须使用:在任何评估开始前进行基础认知,避免后续指纹识别盲目。
- 替代方案:如果目标是高度动态的单页应用(SPA),可先通过查看源代码了解前端框架,再通过API请求分析后端结构。
十、本模块阶段性小结
本模块帮助评估者通过手动观察和基础命令建立对目标Web应用的初步认知。接下来,我们将基于这些观察结果,进一步明确信息收集的具体目标,即界定我们需要获取哪些技术指纹。
图1-1 Web应用组件与指纹来源结构图
二、界定问题与目标
一、模块概念解释
在初步认知之后,需明确本次信息收集的具体目标:获取Web应用的源代码。但源代码本身可能无法直接获得(除非存在泄露或配置错误),因此通过识别技术指纹来推断源码的结构、框架版本、可能存在的漏洞点,进而指导后续深入测试。
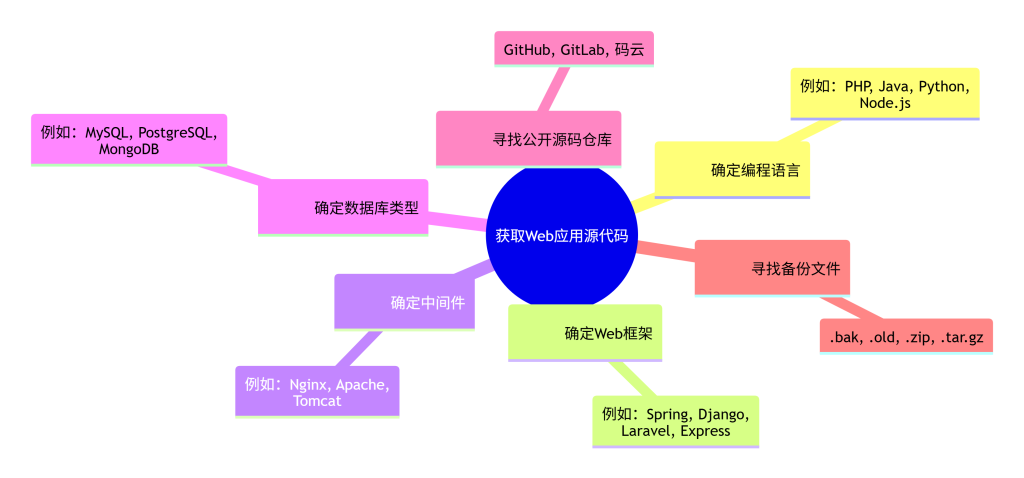
将“源码获取”分解为多个子目标:确定编程语言、确定Web框架、确定中间件、确定数据库类型、寻找公开源码仓库、寻找备份文件等,使收集过程结构化。
二、技术原理说明
源码获取并非直接下载文件(除非漏洞),而是通过指纹间接还原源码信息。指纹是技术组件在响应中留下的独特标记,例如:
- 编程语言:PHP在响应头中常带有
X-Powered-By: PHP/5.6,ASP.NET有X-AspNet-Version。 - Web框架:Django的默认404页面包含Django字样,Spring Boot有默认错误页面特征。
- 中间件:Nginx默认错误页面样式、Apache默认目录索引样式。
- 数据库:通过SQL错误信息、URL参数(如
.php?id=)推测。
将问题分解为多个可验证的子目标,可使收集过程结构化,避免遗漏关键信息。同时,每个子目标对应特定识别技术和工具,便于后续构建方法模型。
三、在系统中的位置
本模块承接基础认知,将宽泛的“了解目标”转化为具体的“需要收集哪些技术指纹”,并确定每个指纹的优先级(如直接决定漏洞利用的框架版本为高优先级)。它为下一模块“拆解关键结构”提供分析维度。
四、可执行命令或查询方式
仍以http://testphp.vulnweb.com为例,演示如何界定目标并收集初步指纹。
- 识别编程语言:观察URL后缀(.php、.asp、.jsp)、响应头。【补充说明:使用
-I参数仅获取头部,效率更高。依据:curl文档】bash curl -I http://testphp.vulnweb.com | grep -i "X-Powered-By"
若无显式头,可尝试触发错误,例如访问不存在的页面,观察错误信息语言。 - 识别Web框架:查看HTML源代码中特有的meta标签、注释、生成器。
bash curl http://testphp.vulnweb.com | grep -i "<meta name=\"generator\"" - 识别中间件:检查Server头,或尝试访问不存在的路径,观察404页面样式。
bash curl -I http://testphp.vulnweb.com/notexist curl http://testphp.vulnweb.com/notexist | grep -i "nginx\|apache\|iis" - 查找公开源码:利用搜索引擎语法搜索与该域名相关的GitHub仓库(注意仅限公开信息,且不针对未授权目标)。例如在Google中搜索
site:github.com "testphp.vulnweb.com"(此步仅为示例,实际需合法)。
五、工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| WhatWeb | 命令行指纹识别工具 | 插件丰富,支持数百种指纹 | 输出信息较多,需过滤 |
| Wappalyzer | 浏览器扩展,快速识别 | 使用方便,结果直观 | 数据库更新略慢,部分后端无法识别 |
| BuiltWith | 在线技术栈分析工具 | 提供详细报告,包括子技术 | 需要联网,免费版有限制 |
| 手动特征库 | 自定义精确识别 | 可控性高,可针对特定框架 | 依赖个人经验,耗时 |
六、标准操作步骤
- 列出待收集目标清单:编程语言、框架、中间件、数据库、前端库、CMS等。
- 使用工具批量识别:运行WhatWeb对目标进行初步扫描。
bash whatweb http://testphp.vulnweb.com - 手动验证关键指纹:针对工具报告的重要指纹,手动发送请求并观察响应,确认存在。
- 记录优先级:标记可直接用于漏洞利用的版本信息(如已知漏洞版本)为高优先级。
- 更新目标清单:根据新发现调整清单(例如发现使用了jQuery,可进一步识别其版本)。
七、如何验证结果真实性
- 验证逻辑:通过不同工具或方法对同一指纹进行交叉验证。例如,WhatWeb报告PHP版本为5.6,可再使用PHP版本探测脚本(如测试phpinfo()是否存在)或通过错误信息中的版本号确认。
- 输出判断依据:若多个来源的指纹信息一致,且未发现矛盾特征,则可确认为真实。若存在矛盾(如Server头说Apache,但404页面显示Nginx),需进一步分析可能是反向代理或WAF。
八、常见错误与排查方式
- 错误1:过度依赖单一工具报告。工具可能误报或漏报。
排查:手动检查至少2-3个关键特征。 - 错误2:忽略版本信息。仅识别了框架名称,未识别具体版本,导致无法利用已知漏洞。
排查:针对特定框架寻找版本探测方法(如特定文件存在、默认路径)。 - 错误3:混淆前端与后端框架。前端框架(如React)不能直接用于推断后端语言。
排查:区分前后端指纹,分别记录。
九、合规边界说明
通用原则:本模块所有操作必须在获得合法授权的前提下,对授权目标进行。未经授权,禁止对任何系统执行探测。
特定风险:频繁的扫描可能被目标安全设备识别为攻击行为,导致IP被封禁或引发法律纠纷。此外,某些主动探测(如触发错误页面)可能留下大量日志。
缓解措施:始终确保获得授权;控制扫描速率;使用公开测试平台练习;记录所有操作以备自查。
决策指南:
- 必须使用:在渗透测试或安全评估的侦察阶段,进行技术指纹识别以确定后续攻击面。
- 替代方案:若目标限制严格(如仅允许浏览器访问),可手动使用开发者工具进行被动分析,避免主动探测。
十、本模块阶段性小结
本模块将“获取源码”目标细化为具体的指纹识别任务,明确了每个指纹的识别方式和优先级。接下来,我们将基于已识别的技术栈清单,深入拆解技术组件的内部结构,找出可能暴露源码的敏感路径。
图2-1 源码获取目标分解思维导图
三、拆解关键结构
一、模块概念解释
识别出技术栈之后,需要理解这些组件内部的关键结构——即可能暴露源码或辅助源码获取的特征点。例如,对于PHP应用,关键结构可能包括:composer.json(依赖管理文件)、.git(版本控制目录)、备份文件、配置文件等;对于Java应用,可能包括WEB-INF/web.xml、META-INF等。
解决“知道是什么,但不知道哪里能找到源码”的问题。通过拆解每个技术组件的典型目录结构、文件命名习惯、默认路径,构建可能存在的敏感文件清单,指导后续路径探测。
二、技术原理说明
每个Web框架或CMS都有其标准的目录结构和文件命名约定。开发者常因疏忽将敏感文件留在Web根目录下,或使用默认路径。例如:
- PHP应用常包含
config.php、db.php、install.php等。 - Git仓库若未配置正确,
.git目录可直接访问,导致下载整个源码。 - 备份文件常见后缀:
.bak、.old、~、.swp等。 - 压缩包:
www.zip、backup.tar.gz等。
拆解关键结构是将理论指纹转化为可探测路径的过程。通过分析框架文档、源码示例、常见漏洞报告,总结每个技术栈的“敏感文件字典”,为后续路径爆破提供精准目标。
三、在系统中的位置
本模块基于已识别的技术栈,生成待探测的路径和文件列表。它连接了“技术识别”与“路径探测”两个环节。完成本模块后,将拥有一份针对目标的定制化探测字典。
四、可执行命令或查询方式
以testphp.vulnweb.com(基于PHP)为例,生成探测列表并尝试访问。
- 生成常见PHP敏感文件列表:如
config.php、db.php、install.php、phpinfo.php、.git/config等。 - 使用curl探测文件是否存在:
bash curl -o /dev/null -w "%{http_code}\n" http://testphp.vulnweb.com/config.php - 使用ffuf(或dirb、gobuster)进行批量探测(需安装ffuf):
bash ffuf -u http://testphp.vulnweb.com/FUZZ -w /path/to/php-files.txt -fc 404 - 检查.git泄露:若存在,可使用
git-dumper工具下载源码(仅限授权测试):bash git-dumper http://testphp.vulnweb.com/.git ./downloaded_repo
五、工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| dirb | 目录扫描,基于字典 | 简单易用,预置字典 | 速度较慢,无递归功能 |
| gobuster | 目录/文件爆破 | 速度快,支持多线程 | 需手动安装,字典需自备 |
| ffuf | 灵活模糊测试 | 高度可定制,支持过滤 | 配置稍复杂 |
| git-dumper | 已知.git泄露时下载源码 | 一键还原git仓库 | 仅适用于git泄露场景 |
| wfuzz | Web应用模糊测试 | 功能强大,支持多种payload | 学习曲线陡峭 |
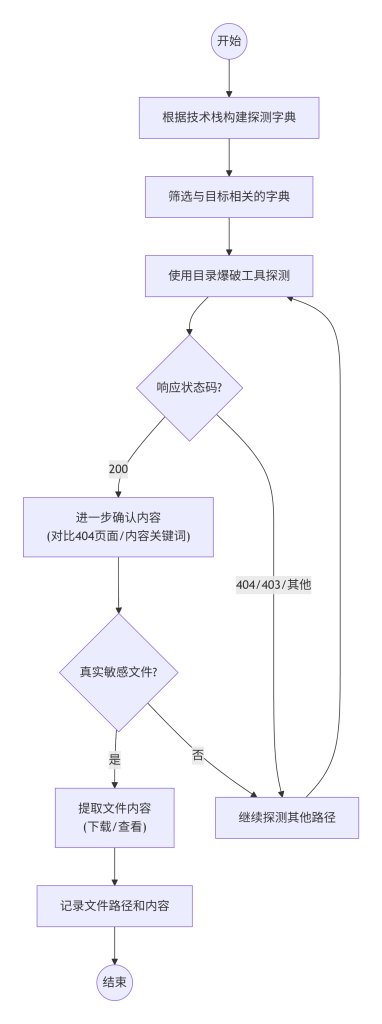
六、标准操作步骤
- 构建探测字典:根据技术栈,从已知框架的常见敏感文件列表(如SecLists项目中的相关字典)中选择。
- 筛选字典:例如PHP应用排除ASP文件。
- 使用目录爆破工具探测:设置合适的线程、超时、过滤条件(如忽略404)。
- 分析响应:对于200状态码,进一步确认是否为真实敏感文件(可能返回200但内容为空或为自定义404页面)。
- 提取内容:对发现的敏感文件进行内容提取,若为文本文件直接下载查看,若为二进制则使用工具分析。
图3-1 敏感文件探测决策流程图
七、如何验证结果真实性
- 验证逻辑:发现疑似敏感文件后,验证其是否为真实源码备份而非蜜罐或假文件。例如,若找到
config.php,观察内容是否包含数据库连接信息;若找到.git,使用git ls-remote查看是否存在引用。 - 输出判断依据:文件内容包含典型关键词(如
DB_PASSWORD)、文件大小合理、文件修改时间符合预期等。
八、常见错误与排查方式
- 错误1:字典覆盖不全。遗漏关键文件导致漏报。
排查:参考多个字典源,如SecLists、fuzzdb,并手动添加目标技术栈特有的文件。 - 错误2:误判自定义404页面为200。许多框架将所有无效请求返回200状态码。
排查:观察响应内容长度或特征,与真实404页面对比;可使用随机字符串测试基准响应。 - 错误3:工具线程过高导致被封锁。
排查:降低线程数,增加延迟,使用代理轮换IP。
九、合规边界说明
通用原则:本模块所有操作必须在获得合法授权的前提下,对授权目标进行。未经授权,禁止对任何系统执行探测。
特定风险:探测目录和文件属于主动扫描行为,即使探测不存在的路径,也可能触发WAF告警并导致IP封禁。
缓解措施:仅在授权范围内使用;使用低烈度扫描策略;记录所有操作。
决策指南:
- 必须使用:在获得授权后,为全面发现敏感文件,进行目录/文件探测。
- 替代方案:若无法主动扫描,可尝试从公开搜索引擎(如Google、GitHub)查找目标泄露的源码,但属于被动信息收集,效果有限。
十、本模块阶段性小结
本模块将指纹识别结果转化为具体的文件探测行动,通过构建定制化字典和目录爆破工具,发现了可能包含源码的敏感文件。接下来,我们将分析已知指纹和探索未知指纹,以进一步确认源码的完整性和真实性。
四、构建方法模型
一、模块概念解释
面对探测到的各种文件和指纹信息,需要一套系统化的方法模型来分析和利用它们。已知指纹(如特定框架的版本号)可以直接匹配已知漏洞;未知指纹(如自定义开发的应用)则需要通过差异分析、聚类等方法识别其独特特征,从而推断其实现方式或寻找共性漏洞。
解决“信息有了,但不知道如何利用”的问题。构建方法模型使评估者能够结构化地处理指纹数据:对已知指纹进行漏洞匹配,对未知指纹进行特征提取和比较,最大化信息价值。
二、技术原理说明
- 已知指纹识别:基于特征库(如WhatWeb插件、Wappalyzer规则库)进行匹配。特征可以是响应头、HTML标签、特定URL路径等。匹配成功后,可查询该版本相关的公开漏洞信息(如CVE)。
- 未知指纹识别:当没有现成规则时,通过聚类分析或差异对比,发现目标与其他系统的不同之处。例如,比较多个相似页面的HTML结构,找出共同的前端框架;或者通过响应时间、错误信息格式推断后端逻辑。
方法模型将经验固化为可重复的过程,使评估者能够从“碰运气”转向“系统性分析”,提高源码获取的成功率和准确性。
三、在系统中的位置
本模块是分析中枢,接收来自前序模块的指纹和文件列表,输出具体的漏洞关联信息或待进一步测试的未知特征。它直接支持下一模块“设计操作路径”,即根据分析结果制定下一步测试计划。
四、可执行命令或查询方式
- 已知指纹匹配:使用WhatWeb的详细信息模式。
bash whatweb -v http://testphp.vulnweb.com - 查询漏洞数据库:将识别出的版本号与公开漏洞库(如CVE Details、Exploit-DB)进行匹配(在安全环境下使用searchsploit命令行工具)。
bash searchsploit PHP 5.6
【补充说明:searchsploit是Exploit-DB的本地命令行搜索工具,广泛用于Kali Linux等渗透测试发行版中。依据:searchsploit官方文档。】 - 未知指纹分析:使用浏览器开发者工具比较不同页面的响应头、HTML结构。或使用工具如
diff比较两个页面的源代码。bash curl http://testphp.vulnweb.com/page1 > page1.html curl http://testphp.vulnweb.com/page2 > page2.html diff page1.html page2.html - 聚类分析:收集所有页面的meta标签、链接、脚本等,统计出现频率,发现通用组件。
五、工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| WhatWeb | 已知指纹识别 | 插件丰富,可定制 | 对未知指纹无识别能力 |
| Wappalyzer | 快速识别前端 | 浏览器集成,使用方便 | 识别深度有限 |
| searchsploit | 本地漏洞库查询 | 离线可用,结果详细 | 需定期更新数据库 |
| Burp Comparer | 比较两个响应 | 图形化,易于发现差异 | 需手动操作 |
| Python脚本 | 自定义未知指纹分析 | 高度灵活,可批量处理 | 需编程能力 |
六、标准操作步骤
- 收集所有指纹信息:整合之前模块识别出的所有技术指纹和发现的敏感文件。
- 分类处理:将指纹分为已知(可匹配现成规则)和未知(无规则)。
- 已知指纹分析:运行WhatWeb等工具获得详细版本,然后使用searchsploit查找匹配的漏洞利用代码。
- 未知指纹分析:对于未知特征如自定义错误页面、特定API路由,尝试通过对比多个页面找出通用模式,或通过搜索引擎查找类似实现的开源项目。
- 记录分析结果:将可能的漏洞点、待测试的路径、推测的代码结构整理成文档。
图4-1 指纹分析方法模型流程图
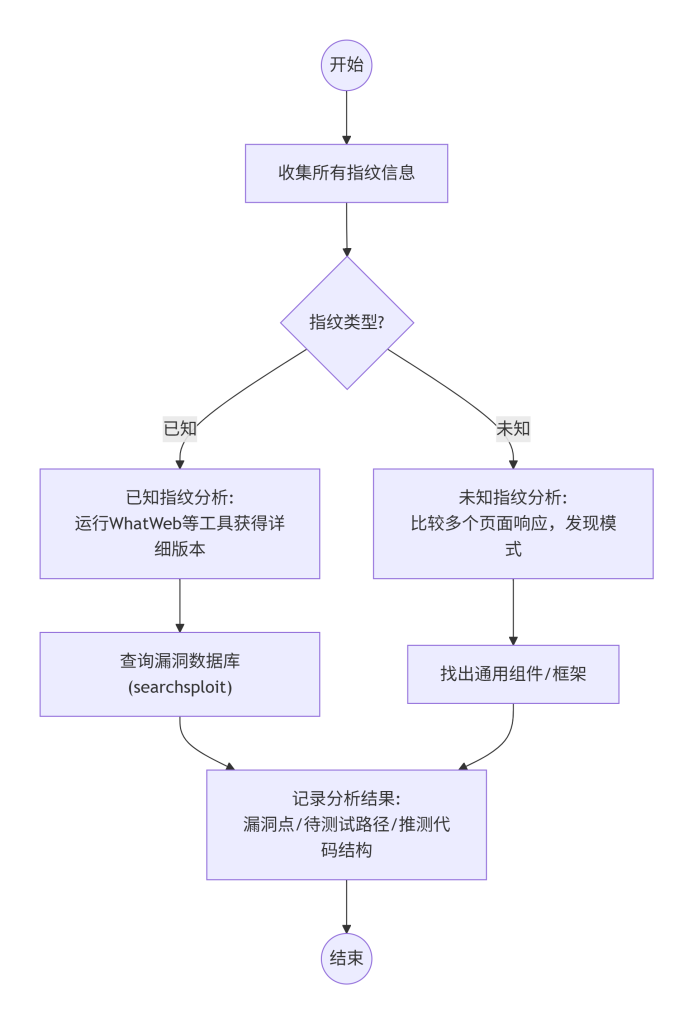
七、如何验证结果真实性
- 验证逻辑:对于已知指纹匹配到的漏洞,需验证目标环境是否确实受该漏洞影响(例如通过概念验证(PoC)测试,但本模块不涉及攻击)。对于未知指纹,通过后续深入测试(如源码分析、手动测试)来证实推测。
- 输出判断依据:若多个漏洞库均报告同一版本存在漏洞,且未发现修补迹象(如特定补丁文件),则可信度高。
八、常见错误与排查方式
- 错误1:版本误判导致漏洞匹配错误。
排查:使用多种方法确认版本,如查看特定文件中的版本信息。 - 错误2:将前端指纹误认为后端指纹,导致漏洞分析偏差。
排查:明确区分前后端技术,后端漏洞需与后端指纹关联。 - 错误3:忽略自定义应用的未知指纹,只关注已知指纹。
排查:强制对每个发现的文件或页面进行未知指纹分析,培养习惯。
九、合规边界说明
通用原则:本模块所有操作必须在获得合法授权的前提下,对授权目标进行。未经授权,禁止对任何系统执行探测。
特定风险:漏洞查询和匹配可能被视为“准备攻击工具”,需注意法律边界。使用searchsploit等工具仅限授权测试环境。
缓解措施:在授权测试环境中进行;仅用于学习目的;不实际执行漏洞利用。
决策指南:
- 必须使用:在评估已识别出的技术栈时,查询已知漏洞,以确定后续测试的优先级。
- 替代方案:若无法在线查询,可使用本地漏洞库或公开漏洞报告。
十、本模块阶段性小结
本模块构建了已知与未知指纹的分析模型,将原始指纹信息转化为具有攻击指导价值的漏洞关联和未知特征集。接下来,我们将设计具体的操作路径来验证这些猜想。
五、设计操作路径
一、模块概念解释
拥有分析结果后,需要设计一条可执行的操作路径,将猜想转化为实际验证。操作路径应包含具体步骤、使用工具、预期结果,并考虑到可能遇到的阻碍(如WAF、IP封锁)。
解决“下一步该做什么”的迷茫。有了操作路径,评估者可以按部就班地验证每个假设,系统化地获取源码或确认指纹信息。
二、技术原理说明
操作路径设计遵循“假设-验证”循环。根据方法模型提出的假设(如“存在.git泄露”“存在SQL注入点”),设计相应的测试请求,观察响应是否符合预期。路径设计需考虑效率和隐蔽性,例如先使用被动探测,再使用主动探测;先低烈度,后高烈度。
结构化路径可以减少重复劳动,避免遗漏,同时保证测试过程的可重复性和可审计性。它类似于渗透测试中的“测试用例”,确保每个潜在风险点都被覆盖。
三、在系统中的位置
本模块将前序模块的分析结果转化为行动指南,告诉我们在哪里、用什么工具、按什么顺序进行下一步测试。它直接指导第六模块的风险控制和最终的能力整合。
四、可执行命令或查询方式
以下路径设计示例,基于之前发现的一些特征(假设我们发现了.git存在、发现了config.php返回200但内容为空等)。
- 路径1:验证.git泄露并下载源码
# 检查.git/HEAD是否存在 curl http://testphp.vulnweb.com/.git/HEAD # 若返回"ref: refs/heads/master",则确认泄露,使用git-dumper git-dumper http://testphp.vulnweb.com/.git ./downloaded_repo - 路径2:分析config.php内容
# 下载config.php curl http://testphp.vulnweb.com/config.php -o config.php # 查看文件内容(可能被注释或包含敏感信息) cat config.php - 路径3:针对未知框架的指纹,尝试通过访问特定URL触发错误
# 发送畸形的查询参数,期望暴露后端错误 curl "http://testphp.vulnweb.com/index.php?aaa=bbb'" - 路径4:使用Burp Intruder对参数进行fuzz,观察响应差异
(略,需图形界面)
五、工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| git-dumper | 下载泄露的git仓库 | 自动还原完整源码 | 需python环境,仅限git |
| curl | 单个文件下载或请求 | 通用,脚本友好 | 手动操作,速度慢 |
| wget | 批量下载 | 支持递归,镜像网站 | 可能下载过多无关文件 |
| Burp Intruder | 参数fuzz | 图形化,灵活配置 | 需Burp专业版 |
| sqlmap | SQL注入检测 | 自动化,功能强大 | 可能产生大量流量,易被检测 |
六、标准操作步骤
- 列出待验证假设:如“存在.git泄露”“存在数据库备份文件”等。
- 按优先级排序:按风险高低或获取源码的直接性排序(如能直接下载源码的假设优先)。
- 设计具体命令:为每个假设设计具体命令,明确使用什么工具、什么参数、如何判断成功。
- 执行验证:按顺序逐一执行,记录每一步的输入和输出。
- 分析结果并更新假设:若验证成功则记录成果,若失败则分析原因并可能调整假设。
图5-1 假设-验证操作路径循环图
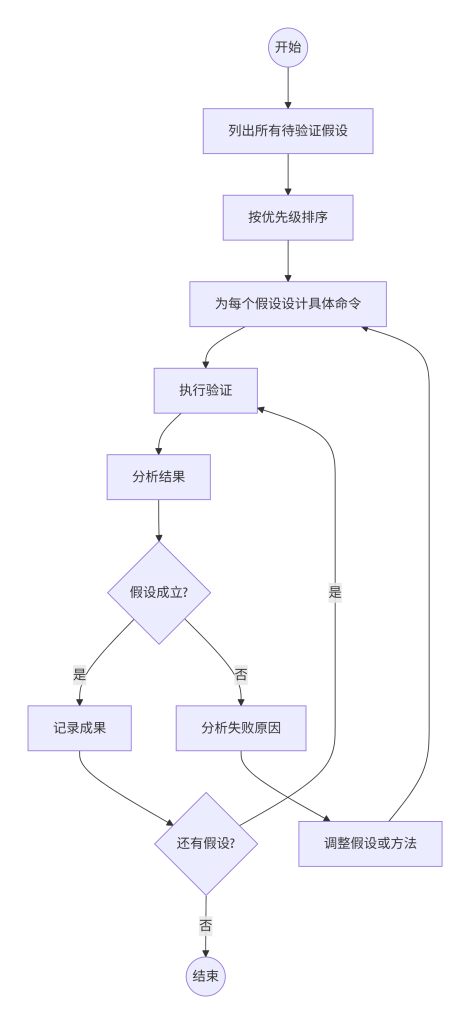
七、如何验证结果真实性
- 验证逻辑:操作路径的每一步都应产生可观察的结果,例如下载到文件、观察到错误信息、响应状态码变化等。将这些结果与预期对比,判断假设是否成立。
- 输出判断依据:例如,成功下载.git目录且
git log能显示提交历史,则证明源码真实获取。
八、常见错误与排查方式
- 错误1:路径顺序不合理,例如先进行高烈度扫描导致IP被封,影响后续测试。
排查:先进行低烈度、被动的验证,如先使用curl检查单个文件,再使用工具批量。 - 错误2:未考虑WAF拦截,导致误报“文件不存在”。
排查:更换请求方法、使用随机User-Agent、增加延迟。 - 错误3:验证失败后直接放弃,未深入分析原因(例如文件存在但需特定参数)。
排查:查看响应内容中的提示信息,尝试不同请求头。
九、合规边界说明
通用原则:本模块所有操作必须在获得合法授权的前提下,对授权目标进行。未经授权,禁止对任何系统执行探测。
特定风险:某些验证步骤(如sqlmap)可能产生大量请求,影响系统稳定性。主动测试可能触发漏洞,对系统造成破坏。
缓解措施:在测试计划中明确每步的风险等级;对可能造成影响的步骤,先与目标方沟通确认;使用安全测试专用的靶场练习。
决策指南:
- 必须使用:在获得授权后,设计清晰的操作路径以确保测试全面且高效。
- 替代方案:若无法执行主动探测,可尝试被动监听或分析公开信息。
十、本模块阶段性小结
本模块将分析结果转化为可执行的验证路径,实现了从“可能有什么”到“实际验证”的跨越。接下来,我们将重点控制验证过程中的法律与安全风险。
六、控制风险边界
一、模块概念解释
在信息收集和源码获取过程中,始终处于法律的边缘。过度或不当的测试可能触犯法律,损害系统,甚至引发法律纠纷。因此,必须明确风险边界,确保所有操作合法合规。
解决“如何安全地进行测试”的问题。通过界定授权范围、识别风险点、采取缓解措施,可以在不越界的前提下完成信息收集任务。
二、技术原理说明
风险控制基于“最小权限”和“必要性”原则。只执行必要的测试,只使用最低烈度的方法,只访问明确授权的目标。同时,理解不同测试手段的法律性质:被动信息收集(如查看公开网页)通常合法,主动扫描(如目录爆破)可能被视为攻击。
网络安全工程师不仅要有技术能力,还要有法律意识和职业道德。风险边界控制确保测试活动在合法范围内,保护自身和客户的安全。
三、在系统中的位置
本模块贯穿于整个流程,但在此处重点强调,作为执行操作路径时的指导原则。它提醒我们在进行实际验证时,必须时刻评估风险,必要时调整路径或终止测试。
四、可执行命令或查询方式
本模块不直接执行命令,而是提供风险检查的方法。例如,在开始测试前,执行以下检查:
- 确认授权范围:检查授权书或测试合同,明确允许的IP、域名、测试方法。
- 设置代理或VPN:确保测试流量从指定IP发出,便于审计。【补充说明:使用代理时应注意其安全性,避免通过不可信的代理发送敏感数据。】
- 使用“安全模式”工具参数:如sqlmap的
--batch --random-agent --delay=1降低风险。
五、工具对比表
| 控制措施 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| 授权文件 | 任何测试前 | 法律依据,明确边界 | 需客户配合签署 |
| 扫描策略(低线程+延迟) | 主动扫描 | 降低被封锁风险,减少系统压力 | 测试时间延长 |
| 代理轮换 | 需隐藏真实IP | 绕过IP封锁 | 可能违反服务条款,需特别谨慎 |
| 日志记录 | 审计与追溯 | 提供操作证据 | 需妥善保管 |
六、标准操作步骤
- 确认授权范围:与客户/系统所有者确认可测试的目标、时间窗口、禁止的操作。
- 配置测试环境:使用虚拟机或专用测试机,设置好代理,记录开始时间。
- 选择低风险工具:优先使用被动工具(如浏览器开发者工具),次选主动但可控的工具(如curl),最后才使用自动化扫描器(如sqlmap)并调低参数。
- 实时监控:观察目标响应,若出现异常(如访问缓慢、返回429状态码),立即暂停。
- 定期汇报:向相关方通报测试进展,确保透明。
- 结束清理:删除临时文件,归档结果,记录结束时间。
图6-1 风险控制流程图
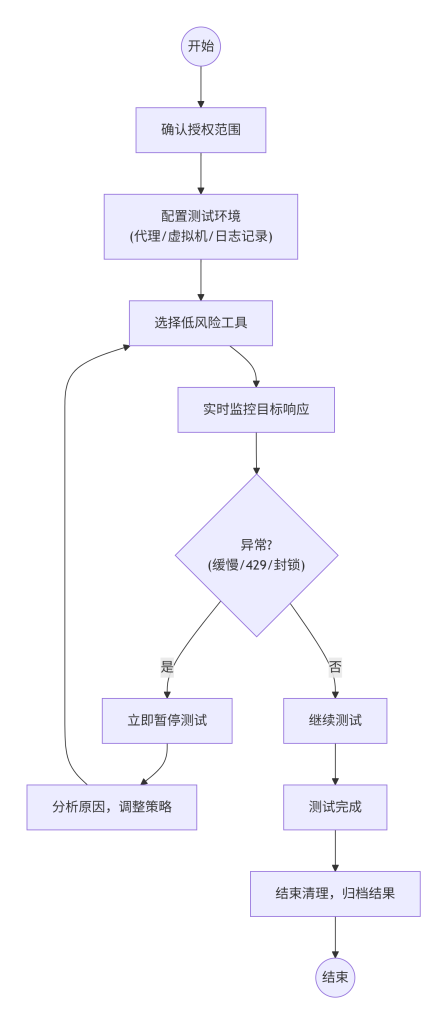
七、如何验证结果真实性
- 验证逻辑:本模块的“结果”是测试过程的安全性。通过检查日志、授权文件、测试期间未发生安全事件,验证风险控制有效。
- 输出判断依据:测试结束后,无任何关于非法扫描的投诉;所有操作记录在案;未对目标系统造成损害。
八、常见错误与排查方式
- 错误1:忽视授权范围,测试了未授权的子域名。
排查:测试前仔细核对授权范围,使用脚本检查每个目标是否在允许列表中。 - 错误2:工具配置不当导致大量请求,触发防御。
排查:了解工具的默认配置,手动设置低线程和延迟。 - 错误3:忘记记录操作,导致无法审计。
排查:使用script命令记录终端输出,或使用Burp记录所有请求。
九、合规边界说明
通用原则:本模块所有操作必须在获得合法授权的前提下,对授权目标进行。未经授权,禁止对任何系统执行探测。
特定风险:即使有授权,某些测试(如DoS)也可能导致系统不可用,构成侵权。自动化工具可能因配置不当造成破坏。
缓解措施:避免使用高负载测试;测试前备份数据;签署保密协议;在脚本中内置风险控制参数(如延迟、线程数)。
决策指南:
- 必须使用:在任何实际测试开始前,进行风险边界控制。
- 替代方案:若无法获得授权,只能进行完全被动的信息收集,且不得发起任何主动请求。
十、本模块阶段性小结
风险控制是信息安全测试的生命线。本模块强调了合法合规的重要性,并提供了实用的风险控制步骤。接下来,我们将整合所有能力,形成一套完整的实战方法论。
七、整合能力输出
一、模块概念解释
经过前六个模块的学习和实践,已经掌握了从基础认知到风险控制的全流程。现在需要将这些分散的能力整合起来,形成一套可复用的实战方法论,以便在未来面对类似目标时能够高效、规范地开展工作。
解决“学了很多,但不知道怎么用”的问题。通过整合,将碎片化的知识点串联成完整的作业流程,并形成标准化的输出报告框架。
二、技术原理说明
整合能力输出基于“流程标准化”和“知识模板化”。将每个模块的关键步骤、工具、验证方法整理成检查清单;将常见指纹和对应的敏感文件整理成字典;将风险控制措施整理成操作规范。这样,下次遇到新目标时,可以直接套用这个框架,提高效率和质量。
能力整合有助于沉淀经验,减少重复劳动,同时也是衡量学习效果的标准。最终输出可以是完整的测试报告、自动化脚本、知识库等。
三、在系统中的位置
本模块是收尾阶段,将前序所有模块的产出物整合,形成一个闭环。它强调将方法论应用于实战,并为后续的漏洞利用或修复提供依据。
四、可执行命令或查询方式
本模块不直接执行新命令,而是将之前用过的命令整合成脚本或工具集。例如,创建一个shell脚本自动执行基础探测:
#!/bin/bash
TARGET=$1
curl -I $TARGET
curl $TARGET/robots.txt
whatweb $TARGET
# 等等五、工具对比表
| 整合方式 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| 检查清单 | 手动测试时 | 简单,不易遗漏 | 仍需人工操作 |
| 自动化脚本 | 批量或重复测试 | 高效,可复用 | 需维护脚本 |
| 知识库(如Wiki) | 团队共享 | 积累经验,便于培训 | 需持续更新 |
| 报告模板 | 正式交付 | 规范化,专业 | 灵活性较低 |
六、标准操作步骤
- 回顾整个流程:从基础认知到风险控制,列出每个模块的关键输出。
- 整理指纹数据库:将收集到的已知指纹规则、未知指纹特征整理成表格。
- 编写自动化脚本:将常用的探测命令组合成脚本,便于快速启动。
- 制定报告模板:设计信息收集报告的结构,包括目标信息、指纹识别结果、发现文件、风险分析等。
- 进行实战演练:选择一个新的授权目标,按照整合的流程从头到尾执行一遍,检验方法有效性。
- 反馈优化:根据演练结果调整流程和脚本,形成迭代。
图7-1 能力整合步骤流程图
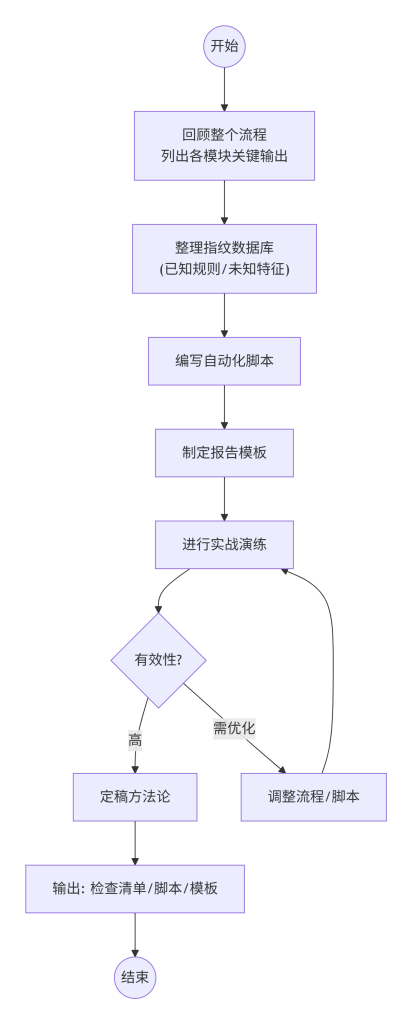
图7-2 信息收集全流程整合框架图
七、如何验证结果真实性
- 验证逻辑:整合能力的最终输出是流程的有效性和报告的准确性。通过在新目标上复现流程,并与其他评估者的结果对比,验证流程的可重复性和准确性。
- 输出判断依据:若流程在新目标上同样能发现关键信息,且报告格式规范、内容详实,则证明整合成功。
八、常见错误与排查方式
- 错误1:整合过于僵化,不适应新场景。
排查:保留灵活性,允许根据目标特性调整流程。 - 错误2:遗漏了关键步骤,如风险控制。
排查:通过检查清单确保所有步骤都被覆盖。 - 错误3:报告内容冗长,重点不突出。
排查:明确报告受众,聚焦关键发现。
九、合规边界说明
通用原则:本模块所有操作必须在获得合法授权的前提下,对授权目标进行。未经授权,禁止对任何系统执行探测。
特定风险:自动化脚本可能因未考虑风险控制而引发问题。分享整合的方法论时,需强调授权前提。
缓解措施:在脚本中内置风险控制参数(如延迟、线程数),并提示用户必须获得授权;在知识库中明确合规要求。
决策指南:
- 必须使用:在团队内部推广标准化流程时,整合能力输出。
- 替代方案:对于临时测试,可直接使用检查清单而非完整脚本。
十、本模块阶段性小结
本模块完成了从理论到实践的最终整合,将前六个模块的知识、技能、工具、风险控制融合成一套完整的实战能力包。至此,我们掌握了系统化、规范化的信息收集方法论,为后续的深入安全评估奠定坚实基础。
参考与进一步阅读
- curl documentation: 本文中所有
curl命令用法的主要参考来源,详细说明了-I,-i,-v,-H等参数的具体行为。 - IETF RFC 2616 – Hypertext Transfer Protocol — HTTP/1.1: HTTP/1.1协议的官方规范,定义了响应头(如
Server)、状态码(如200、404)和HTTP交互的基本原理,为理解指纹来源提供底层依据。 - Git-Dumper GitHub Repository: 工具
git-dumper的官方仓库,本文中关于检测和利用.git泄露的命令与原理均基于此项目。 - Exploit-DB / searchsploit Manual:
searchsploit工具的官方文档来源,本文中关于本地漏洞库搜索的命令(如searchsploit -m)和最佳实践均参考于此。 - WhatWeb Official Website: 指纹识别工具 WhatWeb 的官方网站,提供了其插件机制、识别原理和详细用法,是“已知指纹识别”部分的核心工具依据。