信息收集-Web应用-JS提取分析-人工&插件*项目
Web前端代码信息深度挖掘
一、重构代码价值认知
1. 模块概念解释
在Web安全测试中,前端代码(HTML、CSS、JavaScript)常被低估,测试人员往往直接进行动态扫描或手动测试,而忽略静态代码中蕴含的丰富信息。前端代码不仅是页面渲染逻辑,还可能泄露后端接口、业务逻辑、硬编码凭证、调试信息、注释中的敏感内容。系统化审视前端代码,可在测试早期发现潜在攻击面,为后续深入测试提供方向。
2. 技术原理说明
前端代码是浏览器执行的客户端程序,其源代码对任何用户可见(通过“查看源代码”或开发者工具)。由于Web架构的设计,客户端必须获取代码才能渲染和执行,因此攻击者或安全测试人员可利用这一特性,通过静态分析获取以下信息:
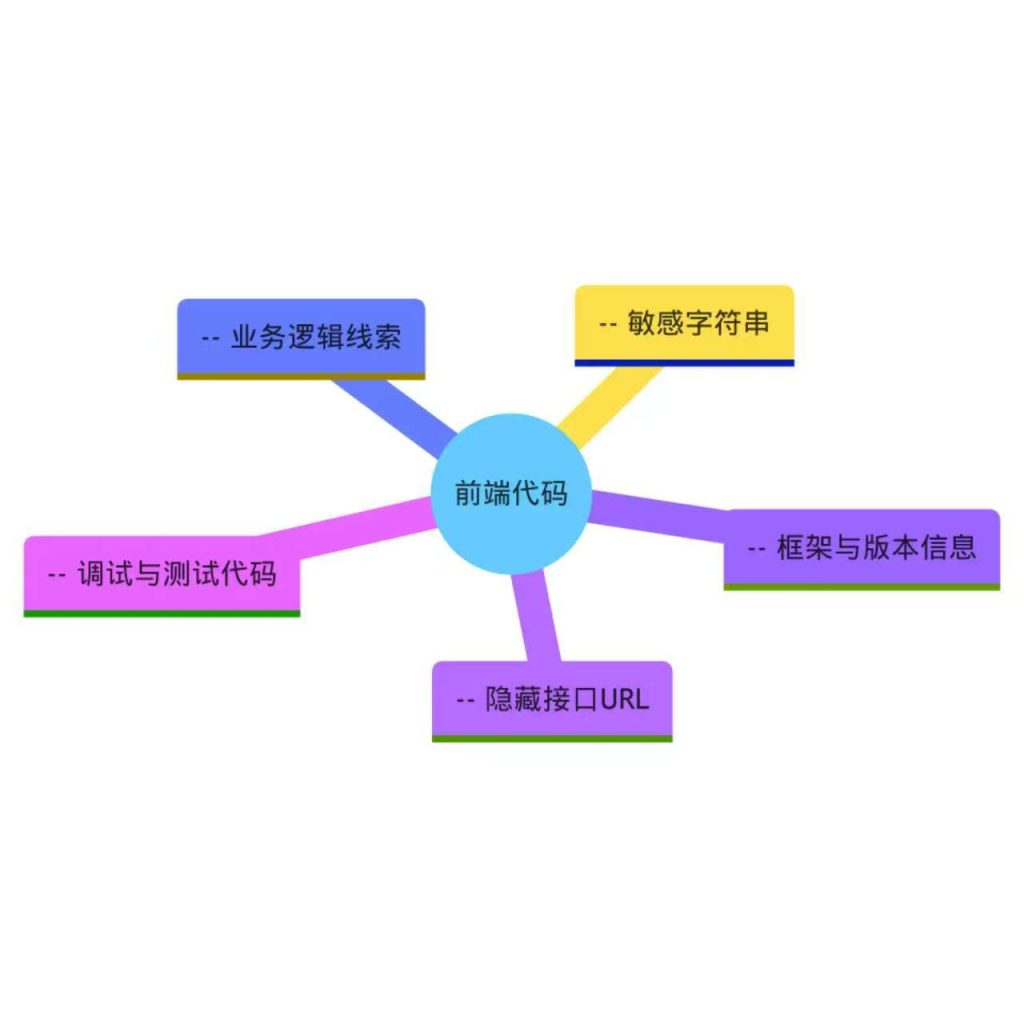
- 隐藏的接口URL:JavaScript中可能包含对后端API的调用路径,甚至未公开的端点。
- 敏感字符串:如API密钥、加密盐、数据库连接字符串(尽管极少,但仍有发生)、测试账号等。
- 业务逻辑线索:前端代码中可能包含注释或未使用的函数,揭示功能实现方式或限制条件。
- 框架与版本信息:通过特定文件(如
.map文件)或特征字符串,可推断技术栈及版本,关联已知漏洞。 - 调试与测试代码:开发人员可能遗留
console.log、debugger语句或测试路由,成为信息泄露点。
3. 在系统中的位置
本模块作为开篇,是后续所有分析的基础。建立“代码即情报”的认知,有助于你主动挖掘前端代码中的价值。后续模块将分别讲解明确分析目标、拆解信息载体、协同使用工具、形成操作流程等。本模块为课程奠定思维基础,不涉及具体工具和步骤,重在改变视角。
4. 可执行命令或查询方式
通过以下简单操作体验代码可见性:
- 使用浏览器开发者工具(F12)→“源代码”(Sources)面板,浏览当前页面加载的所有JavaScript、CSS、HTML文件。
- 使用
curl获取页面源码并搜索关键字:
curl -s http://testphp.vulnweb.com/ | grep -i "api\|key\|token\|secret\|admin"- 查看页面源代码(右键→查看页面源代码),观察注释块。
5. 工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| 浏览器开发者工具 | 实时交互分析前端代码 | 集成环境,支持断点调试、网络请求查看、元素检查 | 手动操作,批量处理能力弱 |
curl + 命令行文本工具 | 快速抓取页面源码并搜索关键词 | 轻量、可脚本化,适合批量初筛 | 仅能获取静态HTML,无法执行JavaScript或提取动态加载的代码 |
| Burp Suite(Target/Map) | 被动扫描记录所有请求与响应 | 可捕获所有通过代理的流量,包括JS文件内容 | 需要配置代理,对HTTPS需安装证书 |
| 爬虫工具(如gospider) | 自动收集页面链接及JS文件 | 可递归爬取,提取所有子资源和链接 | 可能产生大量噪声,需要后续过滤 |
6. 标准操作步骤
- 打开目标站点:在浏览器中访问授权测试目标,例如
http://testphp.vulnweb.com/。 - 查看页面源代码:右键→“查看页面源代码”,浏览HTML,关注
<script>标签的src属性引用的外部JS文件。 - 审查网络流量:按F12打开开发者工具,切换到“网络”(Network)标签,刷新页面,过滤JS类型,观察加载的所有JavaScript文件。
- 初步关键词搜索:在源代码或JS文件中使用Ctrl+F搜索常见敏感词,如
api、key、token、password、admin、debug、test。 - 记录疑似信息:将发现内容记录在笔记中,作为后续分析线索。
7. 如何验证结果真实性
- 接口URL验证:发现疑似API路径(如
/api/users),可直接在浏览器中访问(若支持GET)或通过Burp Repeater发送请求,观察响应是否返回数据。 - 敏感字符串验证:若找到类似API密钥的字符串,可尝试在请求头中加入该值访问相关接口,验证是否认证通过;需在授权范围内,避免越权操作。
- 框架版本验证:根据发现的特征(如特定JS变量名、文件哈希),通过在线漏洞库或本地知识库确认版本是否存在已知漏洞。
8. 常见错误与排查方式
- 误判敏感信息:将普通变量名误认为密钥。应结合上下文判断,例如
apiKey可能只是占位符。可尝试在后续请求中实际使用验证。 - 忽略动态加载的代码:单页面应用(SPA)通过AJAX动态加载JS文件,仅查看初始页面源码会遗漏。应使用网络面板监控所有请求。
- 过度依赖自动化:自动化工具可能产生大量结果,需人工筛选。建议结合手动浏览关键页面。
9. 合规边界说明
- 使用场景:仅限在获得授权的渗透测试、安全评估或漏洞挖掘项目中,针对测试环境或合法授权的目标进行。
- 风险:前端代码分析属于信息收集,不涉及攻击行为,但若发现敏感信息(如真实API密钥),切勿擅自使用,应报告给资产所有者。
- 缓解措施:测试前签订书面授权,明确测试范围;发现敏感信息后及时按照漏洞披露流程处理。
- 决策指南:测试初期应执行此步骤,无论是否发现敏感信息,都作为基础工作。黑盒测试中,前端代码分析是获取初步情报的最直接方式;白盒测试中,可结合源代码审计。
10. 本模块阶段性小结
通过本模块,你重构了对前端代码的认知,理解静态代码中可能隐藏大量对安全测试有价值的线索。这种认知转变是后续深入分析的前提。下一模块将明确分析目标,系统化定义从代码中提取的具体信息,使分析有的放矢。
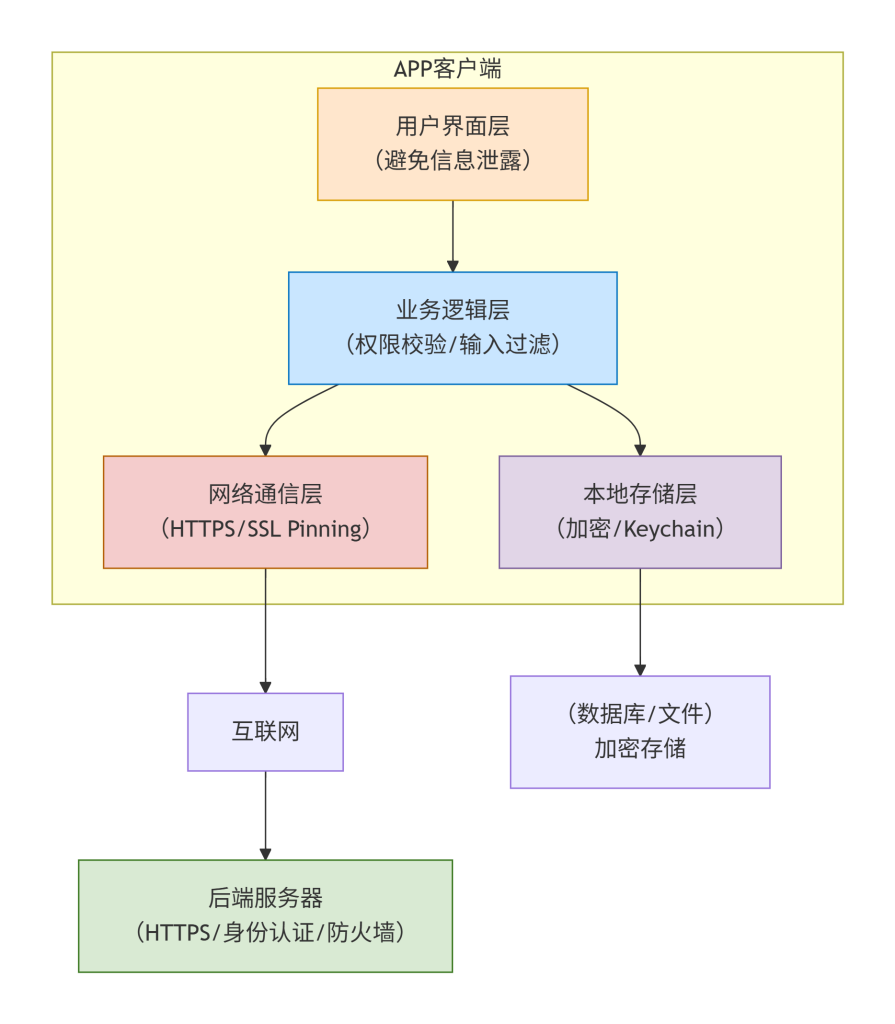
前端代码信息泄露面示意图
二、明确分析目标
1. 模块概念解释
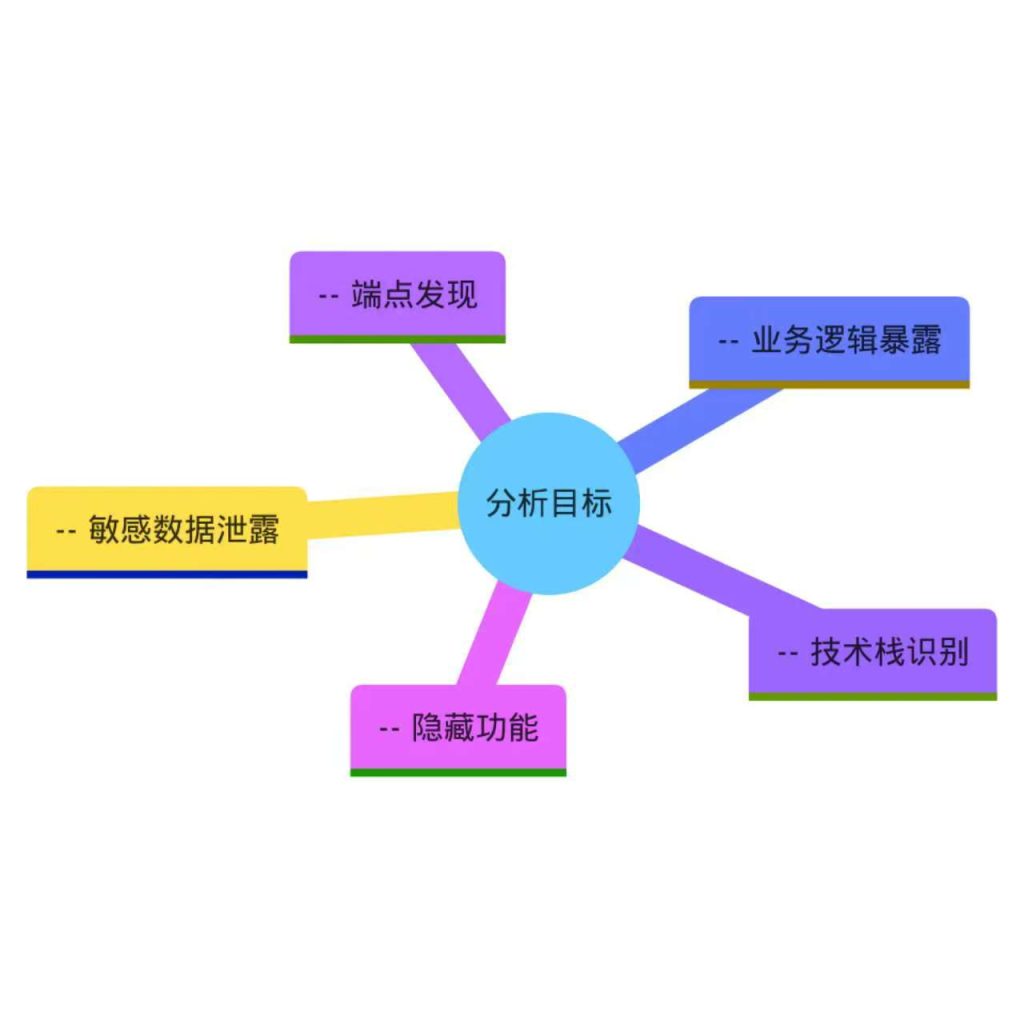
在重构代码价值认知之后,需将宽泛的“寻找线索”转化为具体、可操作的目标。本模块帮助确立从代码中提取攻击情报的目标,即明确要在前端代码中寻找什么,以及这些信息对后续测试有何帮助。目标可分为几类:端点发现、敏感数据泄露、业务逻辑暴露、技术栈识别、隐藏功能等。设定清晰目标能提高分析效率,避免在海量代码中迷失方向。
2. 技术原理说明
基于前端代码可见性的基本特性,我们可以从架构角度定义具体分析目标:
- 前后端分离:前端通过API与后端交互,这些API端点通常硬编码在前端代码中,或通过动态配置加载。发现这些端点意味着扩大攻击面。
- 敏感信息硬编码:开发人员可能为了方便,将测试密钥、调试开关、注释中的密码等留在代码中。这些信息一旦泄露,可能直接导致权限绕过。
- 前端校验与逻辑:某些业务逻辑(如权限判断、输入校验)可能在前端实现,后端未做同样校验。分析前端逻辑可发现绕过点。
- 框架指纹:通过特定文件(如
angular.js、react.js)或构建产物特征(如webpack的chunk文件)可识别技术栈,进而关联已知漏洞。 - 隐藏功能:前端可能包含未链接的管理入口、调试页面、测试接口等,通过分析路由配置可发现这些隐藏功能。
3. 在系统中的位置
本模块承接认知重构,将感性认知转化为具体目标列表。后续模块“拆解信息载体结构”将基于这些目标,深入分析代码中哪些部分可能承载这些信息。本模块也为后续的工具选择和操作步骤提供依据,确保分析有重点、不盲目。
4. 可执行命令或查询方式
以Juice Shop为例,使用命令行工具初步提取目标信息:
# 下载所有JS文件并保存
curl -s https://juice-shop.herokuapp.com | grep -oP 'src="\K[^"]+\.js' | xargs -I {} curl -s https://juice-shop.herokuapp.com{} > all.js
# 搜索API端点模式(如/api/开头)
grep -oP '"/api/[^"]+"' all.js | sort -u
# 搜索可能的关键词
grep -iE 'key|token|pass|admin|debug|test' all.js5. 工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
grep/ripgrep | 在本地代码文件中搜索关键词 | 快速、支持正则,适合批处理 | 需要先获取代码文件,无法处理动态加载 |
| LinkFinder | 从JS文件中提取URL和路径 | 专门用于提取端点,支持输入文件或URL | 可能产生误报,需人工验证 |
| Burp Suite(Engagement Tools) | 在代理历史中搜索 | 可直接在已捕获的流量中查找敏感字符串 | 依赖代理配置,无法覆盖未经过代理的请求 |
| Chrome插件(如Wappalyzer) | 实时识别技术栈 | 快速识别框架、服务器、库版本 | 仅基于特征库,可能误判或漏判 |
6. 标准操作步骤
- 定义信息类别:根据项目背景,列出要提取的信息类型,例如:API端点、硬编码凭证、调试接口、版本信息、注释内容。
- 获取前端代码集合:通过爬虫或手动下载,收集目标站点的所有HTML、JS、CSS文件(可借助工具如
gospider或httrack)。 - 执行初步关键词搜索:使用
grep或专用工具,按预先定义的类别进行搜索,生成初步结果。 - 对结果进行归类:将搜索结果分类存放,如端点列表、疑似密钥、框架标识等。
- 优先级排序:根据信息敏感程度和后续利用价值,对结果进行优先级排序,例如硬编码凭证优先于普通注释。
- 记录目标清单:形成待深入分析的目标清单,供后续模块使用。
7. 如何验证结果真实性
- 端点验证:对提取的每个API端点,使用Burp Repeater发送请求,观察响应状态码和内容。若返回200且有数据,说明该端点有效;若返回404或403,仍需注意可能权限受限。
- 硬编码凭证验证:若找到类似用户名密码的字符串,可尝试在登录接口使用,但必须在授权范围内。
- 框架版本验证:对比已知漏洞库,若版本存在已知漏洞,则记录为高风险点。
8. 常见错误与排查方式
- 目标定义过宽:搜索所有关键词导致结果过多,难以处理。应聚焦最敏感的关键词,或使用更精准的正则。
- 遗漏动态内容:有些端点可能在用户交互后才动态生成(如点击按钮后加载的JS)。应结合动态爬虫或手动触发关键操作。
- 混淆前端路由与后端接口:前端路由(如React Router的路径)可能只是前端显示,并不直接对应后端API。验证时需通过实际请求确认。
9. 合规边界说明
- 使用场景:本模块的分析仍属于信息收集阶段,不涉及攻击。但必须确保对目标拥有合法授权。
- 风险:若在分析过程中发现敏感信息(如明文密码),切勿公开或滥用,应立即通知相关方。
- 缓解措施:建议在隔离环境中进行分析,避免无意中访问生产系统。所有发现应保密。
- 决策指南:在信息收集阶段,必须明确分析目标,避免无目的漫游。目标清单应基于测试范围(如仅关注特定功能模块)而定。
10. 本模块阶段性小结
本模块将前端代码分析的泛化认知转化为具体的目标列表,使后续分析有章可循。你能够根据项目需求定制自己的信息提取重点。下一模块将拆解信息载体结构,深入探讨代码中的哪些结构单元可能承载这些目标信息,以及如何解析它们。
前端代码分析目标分类图
三、拆解信息载体结构
1. 模块概念解释
明确了分析目标后,需要理解这些信息具体存在于代码的哪些部分。本模块解析前端代码中承载敏感信息的逻辑单元,如JavaScript对象、数组、函数参数、HTML注释、CSS中的背景图路径、Source Map文件、配置文件等。通过对这些载体的深入拆解,可以更精准地定位信息,并理解其上下文,避免孤立地看待字符串。
2. 技术原理说明
前端代码由多种语言和资源组成,每种语言都有其特定的语法和结构,信息可能嵌入在不同的结构中:
- HTML:注释块(
<!-- ... -->)、<meta>标签、data-*属性、隐藏输入域(<input type="hidden">)、<a>标签的href、<form>的action等都可能包含路径或参数。 - JavaScript:变量声明、对象属性、数组元素、函数参数、字符串字面量、正则表达式、模板字符串等都可能存储敏感数据。特别是配置对象(如
apiBaseUrl)、路由表(如$routeProvider)、常量定义等。 - CSS:
background: url(...)、@import、content属性可能包含路径或Base64编码的图片数据。 - Source Map:
.map文件可还原原始源代码,暴露变量名、注释、目录结构等。 - JSON/JS配置文件:如
package.json、config.js、.env(有时被错误打包)等直接包含配置信息。 - WebAssembly:二进制格式,但可能通过调试符号泄露信息。
- 动态加载的模板:某些框架(如Vue的单文件组件)将模板编译为JS,可能包含HTML片段。
3. 在系统中的位置
本模块是具体技术实现的核心,它将前一模块的目标映射到代码的具体结构上,使你知道在哪里找什么。同时,它为下一模块“建立协同分析方法”提供了分析单元,即我们需要针对不同载体选择合适的手动或自动化方法。
4. 可执行命令或查询方式
针对DVWA(本地)进行示例:
# 获取登录页面并提取隐藏字段
curl -s http://localhost:8080/DVWA/login.php | grep -oP 'type="hidden".*?value="\K[^"]+'
# 下载所有JS文件并解析对象
curl -s http://localhost:8080/DVWA | grep -oP 'src="\K[^"]+\.js' | xargs -I {} curl -s http://localhost:8080/DVWA{} > dvwa.js
# 使用Node.js脚本分析JS中的对象
node -e "const fs=require('fs'); const code=fs.readFileSync('dvwa.js','utf8'); const matches=code.match(/(\{[^{}]+\})/g); console.log(matches);"5. 工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| Chrome DevTools(Sources) | 手动查看和调试JS对象 | 可实时查看变量值、断点调试,上下文清晰 | 手动操作,不适合大批量文件 |
js-beautify | 格式化压缩的JS代码 | 使代码可读,便于手动分析 | 仅格式化,不提取信息 |
esprima / acorn | JavaScript解析器,生成AST | 可编程提取特定结构(如对象属性) | 需要编写脚本,有一定学习曲线 |
grep/ripgrep | 快速搜索特定模式 | 简单快速,适合已知关键词 | 无法理解结构,易漏掉动态生成的内容 |
Source Map解析工具(如source-map库) | 还原原始源代码 | 可看到未压缩的变量名和注释 | 需要.map文件存在 |
6. 标准操作步骤
- 收集代码文件:使用爬虫或手动下载所有前端资源(HTML、JS、CSS、MAP等)。
- 格式化与美化:对压缩的JS/CSS使用工具(如
js-beautify)格式化,提高可读性。 - 识别载体类型:根据文件扩展名和内容,判断可能的信息载体(如
.js文件重点关注对象和函数;.html关注注释和隐藏域)。 - 手动审查关键区域:
- 对于HTML,滚动查找注释、隐藏输入、data属性。
- 对于JS,搜索常见配置对象名(如
config、settings、env),以及所有字符串字面量。 - 对于CSS,搜索
url(。
- 使用AST解析提取结构(可选):编写简单脚本,使用
esprima解析JS,提取所有对象属性名和字符串,生成结构化数据。 - 记录信息及其上下文:将发现的信息与所在文件、行号、前后代码一同记录,便于后续理解。
7. 如何验证结果真实性
- 上下文验证:查看信息出现的上下文,例如一个字符串是否被赋值给名为
password的变量,或出现在Authorization头的设置中。 - 动态验证:在浏览器中设置断点,执行到对应代码时查看变量值,确认是否实际被使用。
- 请求验证:如果找到的是API路径,尝试构造请求,看是否有效。
8. 常见错误与排查方式
- 混淆压缩变量名:压缩后的变量名无意义,但对象属性名可能仍保留原样。重点分析属性名而非变量名。
- 忽略Source Map:如果网站启用了Source Map,应尝试访问
.map文件(通常通过JS文件路径加.map),可能获得原始代码。 - 误判注释:注释中的信息可能已过时或不准确,需结合代码逻辑判断。
9. 合规边界说明
- 使用场景:在授权测试中,对目标代码进行结构化分析是合法的信息收集行为。
- 风险:Source Map可能泄露完整的项目结构和未压缩的代码,包括目录结构,这可能包含未公开的接口。不应滥用这些信息进行越权访问。
- 缓解措施:对发现的敏感信息(如数据库配置)不应公开,应按照漏洞报告流程处理。
- 决策指南:当目标使用大量前端框架时,必须拆解其特有的信息载体(如Vue的
data对象、React的state初始化),否则可能遗漏关键信息。
10. 本模块阶段性小结
本模块深入探讨了前端代码中的信息载体,使你能够从语法和结构层面精准定位目标信息。通过理解这些载体的特性,可以更有效地进行后续的人工与自动化协同分析。下一模块将建立协同分析方法,探讨如何结合手动和自动化方法,实现高效的信息提取。
前端信息载体与内容结构图

四、建立协同分析方法
1. 模块概念解释
单纯依靠手动分析或自动化工具都有其局限性。手动分析细致但效率低,自动化工具速度快但可能遗漏上下文或产生误报。本模块旨在构建人工与自动化互补的分析模型,即通过自动化工具快速筛选出可疑点,再由人工进行深度确认和上下文分析;同时,人工的洞察可以指导自动化工具的规则优化,形成迭代提升。这种协同方法能够最大化信息提取的覆盖率和准确性。
2. 技术原理说明
- 自动化工具的优势:可批量处理大量文件,执行模式匹配、正则搜索、AST分析,快速生成潜在点列表。例如,使用
LinkFinder提取所有URL,使用SecretFinder搜索密钥模式。 - 人工分析的优势:理解业务逻辑、代码意图、上下文关系,判断自动化结果的真伪,发现非结构化信息(如注释中的提示)或复杂逻辑漏洞。
- 协同工作流:
- 自动化工具对收集的代码进行初步扫描,输出候选结果。
- 人工审查候选结果,剔除误报,并记录有价值的发现。
- 人工分析过程中可能发现新的模式,可反过来优化自动化工具的规则(如添加自定义关键词)。
- 对于关键功能,人工进行深度调试(如设置断点、跟踪调用栈)以验证和深入挖掘。
3. 在系统中的位置
本模块位于拆解载体结构之后,操作执行路径之前。它提供了方法论,指导如何将载体分析落地为实际操作。后续的“形成操作执行路径”将基于此方法设计标准流程。
4. 可执行命令或查询方式
以Juice Shop为例,使用多个自动化工具协同:
# 使用LinkFinder提取JS中的URL
python linkfinder.py -i https://juice-shop.herokuapp.com -o cli
# 使用SecretFinder搜索密钥
python secretfinder.py -i https://juice-shop.herokuapp.com -o cli
# 使用grep搜索自定义关键词
curl -s https://juice-shop.herokuapp.com/main.js | grep -iE 'admin|backdoor|debug'
# 手动在浏览器中打开开发者工具,切换到Sources,搜索(Ctrl+Shift+F)整个项目【补充说明:LinkFinder 脚本的具体使用方式和参数说明,可参考其官方项目文档。依据:GerbenJavado/LinkFinder 】
5. 工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| LinkFinder | 提取JS中的URL/端点 | 专注于端点发现,支持多种输入 | 依赖Python,需本地运行 |
| SecretFinder | 检测硬编码密钥、令牌 | 内置常见密钥正则,可扩展 | 可能误报,需人工验证 |
| Burp Suite(Scanner) | 被动扫描发现信息泄露 | 集成在代理中,自动标记响应中的敏感内容 | 可能漏掉未经过代理的静态文件 |
| Chrome DevTools(全局搜索) | 在加载的资源中搜索关键词 | 实时、直观,支持正则 | 仅限当前页面加载的资源 |
| 自定义脚本(Node/Python) | 根据特定需求编写解析逻辑 | 高度灵活,可处理复杂结构 | 需要编程能力,前期投入较大 |
6. 标准操作步骤
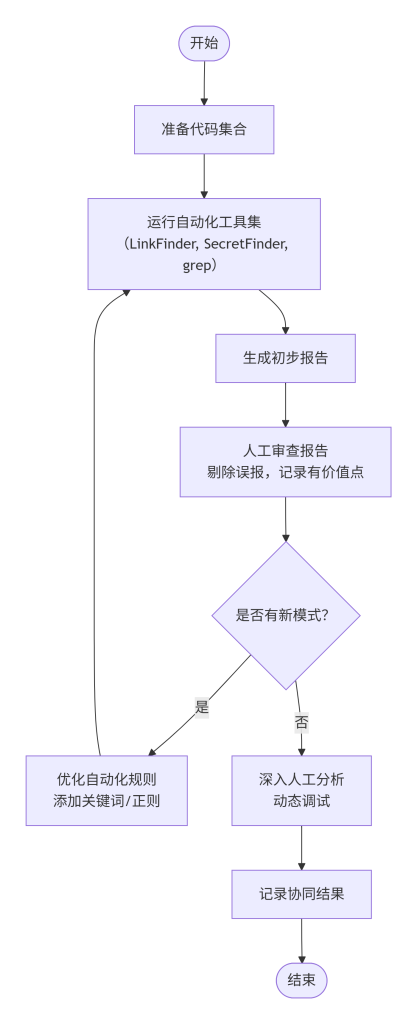
协同分析遵循如图所示的流程。首先,准备代码集合,将所有相关的前端代码文件下载到本地,或通过代理记录所有响应。接着,运行自动化工具集,例如使用LinkFinder提取所有可能的端点,使用SecretFinder搜索硬编码密钥,使用自定义grep脚本搜索常见关键词,将所有输出合并去重,生成初步报告。然后,人工审查初步报告,查看每个候选结果所在文件及上下文,标记明显误报(如example.com、占位符),记录有进一步分析价值的点。深入分析时,在浏览器中设置断点动态调试,使用开发者工具的调用堆栈追踪数据流向,尝试修改代码或使用控制台执行函数。根据人工发现,添加新的关键词或正则到自动化工具配置中,重新运行以发现更多类似信息。最后,记录协同结果,将最终确认的信息整理成结构化数据,供下一模块使用。
7. 如何验证结果真实性
- 自动化结果的验证:对自动化提取的每个条目,至少通过查看上下文或动态请求确认一次。
- 动态验证:在浏览器中执行相关代码片段,观察实际输出的值,确保不是静态死代码。
- 交叉验证:同一信息可能被多个工具或方法发现,增强可信度。
8. 常见错误与排查方式
- 过度依赖自动化:自动化工具可能产生大量结果,但真正的敏感信息可能不在其规则中。必须结合人工分析。
- 忽略工具的输出格式:不同工具输出格式各异,需统一整理,避免遗漏。
- 未处理动态加载:自动化工具运行时可能未触发动态加载的代码。可在爬虫阶段使用无头浏览器(如Puppeteer)模拟点击,捕获所有JS。
9. 合规边界说明
- 使用场景:协同分析方法应在授权测试中使用,确保所有自动化工具的行为不构成攻击(如发送过多请求导致服务压力)。
- 风险:自动化工具可能误报并诱导测试人员关注错误方向,浪费精力;也可能因规则不当而漏报。
- 缓解措施:对工具进行审查,避免使用未经授权的插件;控制扫描频率,避免影响目标业务。
- 决策指南:在测试初期,自动化工具可快速扩大覆盖面;但在关键功能模块,必须辅以人工分析。当目标为老旧系统或定制框架时,人工分析应占主导。
10. 本模块阶段性小结
本模块建立了人工与自动化协同的分析模型,使信息提取既有广度又有深度。你掌握了如何利用工具快速筛选,再通过人工分析精准确认的方法。下一模块将形成操作执行路径,将这一模型固化为标准化的操作流程,确保每次分析都能有条不紊地进行。
人工与自动化协同分析流程图
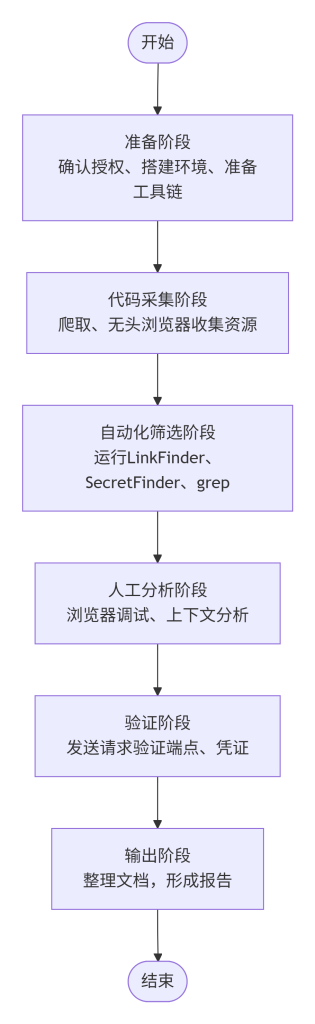
五、形成操作执行路径
1. 模块概念解释
有了协同分析的方法,还需要一套标准化的操作流程来指导实践,避免遗漏步骤或重复工作。本模块设计从代码采集到信息筛选的完整操作执行路径,包括准备阶段、采集阶段、分析阶段、验证阶段和输出阶段。该路径可重复执行,适用于不同目标,并能与团队协作相结合。
2. 技术原理说明
操作执行路径基于PDCA(计划-执行-检查-处理)循环,确保分析过程的系统性和可改进性:
- 计划:确定目标范围、授权边界、选择工具集合。
- 执行:按照步骤采集代码、运行自动化工具、进行人工分析。
- 检查:验证发现的真实性,排除误报。
- 处理:记录结果,优化规则,为下一轮迭代做准备。
流程的标准化能够减少人为错误,提高效率,并便于知识传递和团队协作。
3. 在系统中的位置
本模块将前四个模块的理论和方法转化为可操作的步骤,是课程从理论到实践的桥梁。后续模块“界定活动边界”将强调合规与风险,而“整合实战输出能力”则说明如何利用分析成果。
4. 可执行命令或查询方式
以DVWA(本地)为例,展示一个完整的操作流程脚本片段:
#!/bin/bash
# 阶段1:采集
mkdir dvwa_analysis
cd dvwa_analysis
wget -r -l 2 -np http://localhost:8080/DVWA/ 2>/dev/null
# 阶段2:自动化扫描
find . -name "*.js" -exec cat {} \; > all.js
python /tools/linkfinder.py -i all.js -o cli > endpoints.txt
grep -iE 'pass|key|token|admin' all.js > keywords.txt
# 阶段3:人工分析提示
echo "请手动审查 endpoints.txt 和 keywords.txt,并在浏览器中打开 http://localhost:8080/DVWA/ 进行动态调试"【补充说明:wget 的 -r(递归下载)、-l(最大深度)、-np(不追溯父目录)等参数行为,参见 GNU Wget 官方手册。依据:Debian Manpages – wget(1) 】
5. 工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
wget/httrack | 静态站点镜像 | 简单可靠,递归下载 | 无法处理动态内容(如AJAX加载) |
gospider | 爬取现代Web应用 | 支持JavaScript渲染、表单提交 | 配置较复杂,可能产生大量请求 |
LinkFinder/SecretFinder | 自动化信息提取 | 专注于特定类型信息 | 需要单独安装,依赖Python环境 |
Burp Suite(主动爬取) | 集成爬虫与扫描 | 可抓取动态内容,与代理结合 | 需要许可证(专业版)才能充分发挥 |
| 自定义Shell脚本 | 串联多个工具 | 灵活定制,适合重复使用 | 需要维护脚本,依赖工具链 |
6. 标准操作步骤
操作执行路径如图所示,分为六个主要阶段。首先,准备阶段需确认测试授权书和范围,搭建本地测试环境(如需)或配置代理,确保所有工具可用。代码采集阶段使用爬虫工具(如gospider)或手动浏览,收集目标站点的所有HTML、JS、CSS、MAP文件;若目标为SPA,使用无头浏览器(Puppeteer)渲染并捕获所有动态加载的资源。自动化筛选阶段运行端点提取工具(LinkFinder)生成候选端点列表,运行密钥检测工具(SecretFinder)生成候选密钥列表,运行自定义关键词搜索(grep)生成候选敏感词列表,去重合并后形成初步发现报告。人工分析阶段使用浏览器开发者工具加载目标页面,全局搜索(Ctrl+Shift+F)初步报告中的关键词,查看上下文;对可疑点设置断点,动态跟踪变量值;记录确认的有效信息,并补充上下文说明。验证阶段对发现的端点发送测试请求,验证可访问性;对发现的密钥尝试在授权范围内使用(如API请求)。输出阶段将验证后的信息整理成结构化的文档,包括信息类型、位置、上下文、验证方法,为下一模块准备输入。
7. 如何验证结果真实性
- 步骤验证:每个阶段完成后,检查是否生成了预期输出(如文件是否下载完整)。
- 抽样验证:对自动化结果随机抽取10%进行人工验证,评估工具准确性。
- 最终验证:所有最终结果必须经过至少一次人工确认。
8. 常见错误与排查方式
- 采集不全:未考虑动态加载内容。应使用无头浏览器或触发所有可见功能。
- 工具链断裂:工具之间输出格式不兼容。应编写脚本统一格式。
- 人工分析遗漏:未能深入理解业务逻辑。建议多人交叉审查关键部分。
9. 合规边界说明
- 使用场景:该操作路径仅适用于授权测试,不得用于未经授权的系统。
- 风险:采集阶段可能对目标服务器造成额外负载,需控制并发和速率。
- 缓解措施:在采集时设置延迟(如
wget --wait),并尽量在非业务高峰进行。 - 决策指南:对于生产系统,采集前必须评估影响,必要时申请只读账号或使用镜像环境。
10. 本模块阶段性小结
本模块将前序理论固化为可重复执行的操作路径,使前端代码分析成为一个工程化过程。你现在能够独立完成从采集到输出的完整工作。然而,操作过程中必须时刻注意合规性,下一模块将界定活动边界,深入探讨信息提取过程中的法律与道德边界。
前端代码分析操作执行路径图
六、界定活动边界
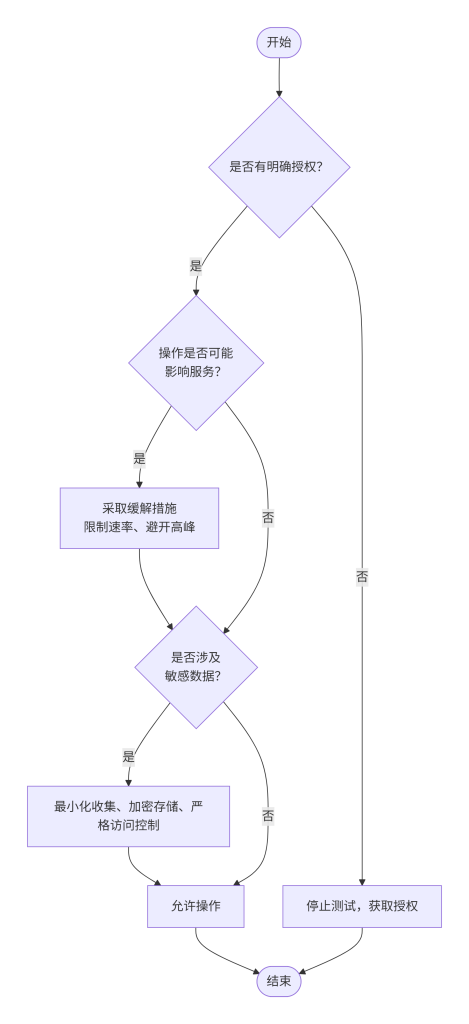
1. 模块概念解释
在信息提取过程中,测试人员容易忽略行为的合法性,可能无意中触犯法律或违反测试协议。本模块旨在划定信息提取过程中的合规与风险边界,明确哪些行为是允许的,哪些可能越界。通过建立边界意识,确保测试活动始终在授权范围内,保护测试者自身和被测方。
2. 技术原理说明
法律和行业规范对安全测试有明确规定,主要基于以下几点:
- 授权原则:任何对系统的非授权访问或数据提取都可能构成违法行为(如《计算机信息系统安全保护条例》、《网络安全法》)。
- 最小必要原则:只提取测试所需的信息,不额外收集无关数据。
- 数据保护原则:发现的敏感信息(如个人数据、商业机密)不得泄露,应按漏洞披露流程处理。
- 避免破坏原则:测试行为不得导致服务中断或数据损坏。
技术上的“能否做到”不等于“应该做”。测试人员必须时刻反思当前操作是否在授权范围内。
3. 在系统中的位置
本模块是承上启下的关键:它提醒你在执行前五模块的操作时,必须遵守边界;同时,它也指导后续模块“整合实战输出能力”中如何使用分析成果,避免滥用。
4. 可执行命令或查询方式
虽然本模块不涉及具体命令,但可以展示如何在操作中体现合规性,例如在爬虫命令中加入延时和限制:
# 合规的爬取示例:限制深度、请求间隔,并遵守robots.txt
wget --wait=2 --limit-rate=100k --execute robots=off -r -l 2 http://testphp.vulnweb.com/(注意:robots=off应仅在授权情况下使用,通常应遵守robots.txt)
【补充说明:–wait 参数用于设置请求间隔,–limit-rate 用于限制带宽,这些是控制爬虫对服务器影响的有效手段。依据:Debian Manpages – wget(1) 】
5. 工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
wget with --wait | 需要控制请求频率 | 简单易用,支持延时 | 无法处理复杂JavaScript |
| Burp Suite(Throttle) | 设置代理请求延迟 | 可精细控制每个请求间隔 | 需手动配置 |
| 自定义爬虫(如Python+Requests) | 完全控制请求行为 | 可编写符合合规要求的请求策略 | 需要编程,前期投入大 |
6. 标准操作步骤
- 确认授权范围:书面明确允许测试的IP、域名、时间窗口,以及允许的测试类型(如仅信息收集,不包括漏洞利用)。
- 评估操作影响:对将要使用的工具和命令进行影响评估,是否会发送大量请求、是否会触发敏感操作(如修改数据)。
- 设置操作边界:
- 限制爬取深度和广度。
- 设置请求延时,避免对服务器造成压力。
- 排除登录、修改、删除等操作。
- 数据最小化:只保存与分析相关的代码片段,不存储无关的个人信息。
- 安全存储发现:将发现的信息加密存储,严格控制访问权限。
- 定期审查:在测试过程中定期检查操作是否符合授权,如有越界立即停止并报告。
7. 如何验证结果真实性
- 授权验证:与授权书比对,确认测试目标、时间、范围一致。
- 日志审计:保留所有操作日志,包括请求的URL、时间戳,以备审计。
- 数据脱敏验证:检查保存的数据中是否包含非必要个人信息,如有则删除。
8. 常见错误与排查方式
- 忽视robots.txt:虽然robots.txt不是法律强制,但应尊重网站管理者的意愿,除非授权书明确允许。
- 过度爬取:爬取整个站点可能导致性能问题。应限制深度和并发。
- 误将测试数据用于其他目的:发现的信息仅用于本次测试报告,不得用于其他项目或公开。
9. 合规边界说明
- 使用场景:任何安全测试都必须有明确的授权,包括内部测试、众测、红队演练等。
- 风险:未授权测试可能导致法律诉讼、合同违约、声誉损失。
- 缓解措施:与法务团队确认授权书,必要时购买专业责任险;测试前签署保密协议。
- 决策指南:当遇到模糊地带(如第三方组件、云服务),必须咨询授权方;如无明确授权,不进行任何测试。
10. 本模块阶段性小结
本模块强调了合规与边界的重要性,使你在执行操作时始终绷紧法律和道德之弦。只有确保合规,测试成果才能被安全地用于后续阶段。下一模块将整合实战输出能力,学习如何将分析成果转化为后续测试的有效输入。
合规边界决策模型图
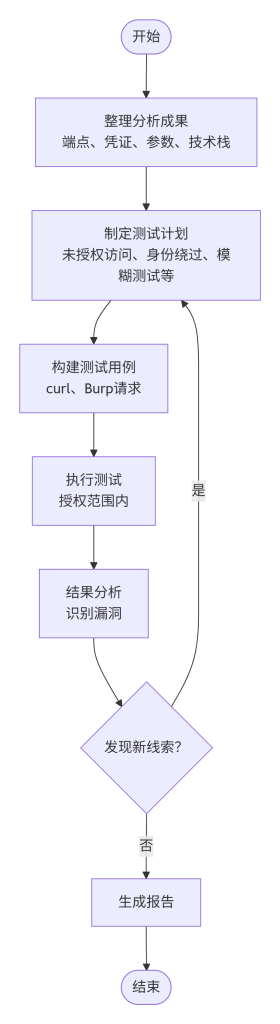
七、整合实战输出能力
1. 模块概念解释
经过前六个模块的学习和实践,我们已经从前端代码中提取了大量有价值的信息,包括API端点、硬编码凭证、业务逻辑线索等。本模块的目标是教会你如何将这些分析成果融合起来,作为后续安全测试(如漏洞挖掘、渗透测试)的输入,实现从信息收集到实战利用的转化。输出能力包括生成测试用例、构造请求、绘制攻击面地图等。
2. 技术原理说明
前端代码分析得到的成果可以服务于多种后续测试:
- API端点:可直接用于模糊测试、权限绕过测试、未授权访问测试。
- 硬编码凭证:可用于尝试登录或API认证,检测是否存在权限提升风险。
- 业务逻辑线索:如参数名、数据类型、校验规则,可用于构造更精准的测试Payload。
- 技术栈信息:可关联已知漏洞库,针对特定版本进行漏洞验证。
- 隐藏功能:如调试接口,可能直接暴露管理功能,测试其是否存在弱认证。
整合输出是将碎片信息转化为系统性的测试计划,提高测试的针对性和效率。
3. 在系统中的位置
本模块是整个课程的收尾,也是实际测试工作的起点。它将前期的信息收集成果转化为可执行的测试任务,使你能够完成从信息收集到漏洞发现的完整链条。
4. 可执行命令或查询方式
以Juice Shop为例,假设我们从代码中提取了以下信息:
- API端点:
/api/Users、/api/Products - 参数名:
email、password - 认证方式:Bearer Token
可以构造如下测试命令(仅展示概念,非攻击):
# 使用curl获取用户列表,测试未授权访问(期望返回401或403)
curl -i https://juice-shop.herokuapp.com/api/Users
# 如果找到硬编码Token,尝试携带
curl -i -H "Authorization: Bearer eyJhbGciOiJSUzI1NiIsInR5cCI6IkpXU1..." https://juice-shop.herokuapp.com/api/Users
# 模糊测试参数
ffuf -u https://juice-shop.herokuapp.com/api/Users?FUZZ=test -w /usr/share/wordlists/parameters.txt -H "Authorization: Bearer ..."5. 工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
curl | 手动验证单个请求 | 简单直接,适合快速测试 | 不适合批量或复杂流程 |
| Burp Suite(Repeater/Intruder) | 构造和重放请求,进行模糊测试 | 图形化,支持多种攻击类型 | 需要配置代理,专业版收费 |
ffuf/wfuzz | 高速模糊测试 | 性能好,支持多线程 | 需要编写参数列表,结果需人工分析 |
Postman | 集合测试和自动化脚本 | 便于组织测试用例,支持环境变量 | 主要用于API测试,不直接支持漏洞利用 |
| 自定义Python脚本 | 复杂场景的自动化测试 | 灵活,可处理会话、验证逻辑 | 开发成本高,需维护 |
6. 标准操作步骤
从信息收集到实战输出的流程如图所示。首先,整理分析成果,将前序模块发现的各类信息分类整理,包括端点列表(URL、方法、参数)、凭证列表(用户名、密码、令牌)、参数名列表、技术栈信息、业务逻辑线索等。接着,制定测试计划,根据成果确定要执行的测试类型,如未授权访问测试、身份认证绕过、参数模糊测试、版本漏洞验证等。然后,构建测试用例,针对每个测试点编写具体的请求示例(使用curl或Burp)。执行测试时,在授权范围内运行测试用例,记录响应。结果分析阶段,将测试结果与预期对比,识别漏洞或异常行为;若发现新线索,可返回优化测试计划。最后,生成报告,整合测试过程与发现,形成最终的安全测试报告。
7. 如何验证结果真实性
- 漏洞验证:对于疑似漏洞,需通过多次请求确认,排除误报(如权限不足返回403是正常行为,但返回200且包含数据则可能是漏洞)。
- 重复性验证:在其他环境或相同条件下重试,确保漏洞可复现。
- 危害评估:结合业务逻辑判断漏洞的实际危害,如泄露用户数据可能为高危。
8. 常见错误与排查方式
- 未考虑认证状态:测试未授权访问时,可能因未携带认证头而得到401,但携带后却得到200,需区分。
- 过度依赖单一工具:某些工具可能对特殊字符处理不当,导致测试失败。应交叉使用curl和Burp验证。
- 忽略请求顺序:某些功能需要先登录或获取CSRF令牌,应在测试用例中包含前置步骤。
9. 合规边界说明
- 使用场景:本模块的测试活动必须在授权范围内进行,不得对生产系统造成破坏。
- 风险:模糊测试可能产生大量请求,导致服务负载过高;使用硬编码凭证登录可能触发账户锁定策略。
- 缓解措施:测试前通知系统管理员;使用低频率模糊测试;对可能触发锁定的操作提前沟通。
- 决策指南:当发现高危漏洞时,应立即停止自动化测试,转为手动确认,并按照漏洞报告流程处理,避免进一步影响。
10. 本模块阶段性小结
本模块完成了从信息收集到实战输出的闭环,使你能够将前端代码分析的成果有效应用于后续安全测试。至此,整个“Web前端代码信息深度挖掘”课程构建了一个完整的工程化流程:从认知重构、目标明确、载体拆解、协同分析、操作路径、合规边界到实战输出。你已具备系统化挖掘前端代码价值并用于安全测试的能力。
从信息收集到实战输出流程图
参考与进一步阅读
- GNU Wget 1.21.4 Manual:本文中
wget命令(包括-r,-l,-np,--wait,--limit-rate等参数)的权威参考。GNU 官方文档 - LinkFinder GitHub Repository:本文介绍的用于从 JavaScript 文件中提取端点的工具
LinkFinder的官方项目页面,包含安装、使用方法和示例。GerbenJavado/LinkFinder - SecretFinder Source Documentation (via DeepWiki):本文中提到的秘密检测工具
SecretFinder的正则表达式模式和输入处理机制的详细说明。m4ll0k/SecretFinder / Regular Expression Patterns m4ll0k/SecretFinder / Input Processing Pipeline - GoSpider GitHub Repository & Go Package Documentation:本文中提及的快速 Web 爬虫
gospider的官方文档,介绍了其功能、安装和参数。jaeles-project/gospider gospider – Go Packages - Burp Suite 官方文档:PortSwigger 公司提供的 Burp Suite 工具套件的完整文档,涵盖代理、爬虫、Repeater、Intruder 等功能的使用方法。PortSwigger Documentation
信息收集-Web应用-JS提取分析-URL&配置&逻辑
一、重构前端交互认知框架
一、模块概念解释
本模块建立对Web应用中客户端JavaScript(JS)代码的宏观定位理解。现代Web应用多采用前后端分离架构,前端承担交互逻辑、路由管理、状态维护及与后端API的通信职责。JS代码已从页面点缀转变为应用功能实现的核心部分。理解前端代码在整体架构中的角色,有助于安全测试人员明确信息收集的切入点和分析价值。JS文件中隐藏着大量关于后端接口、业务逻辑约束、配置参数等关键信息,这些信息是后续深入测试的基础。
二、技术原理说明
从架构层面,Web应用由前端(客户端)和后端(服务器)组成。前端代码(HTML/CSS/JS)被发送到浏览器执行,负责呈现用户界面和收集用户输入,并通过HTTP请求与后端交互。后端提供应用程序编程接口(API)服务,处理业务逻辑和数据存储。这种分离设计要求前端必须知晓与后端交互的细节:API的URL、请求方法、参数格式、认证方式等。这些信息通常以字符串形式硬编码或动态拼接在前端JS中。此外,前端可能包含业务规则的客户端实现(如表单验证、权限判断),虽然这些规则最终需由后端强制执行,但其代码片段可能泄露业务逻辑细节。因此,前端JS代码揭示了客户端与后端的协作方式,以及可访问的入口点。
三、在系统中的位置
本模块为JS提取分析流程的认知起点。在信息收集阶段,测试人员通常先通过爬虫或手动浏览获得应用的大致功能点,然后进入JS分析环节。本模块建立分析视角:将代码视为前端与后端交互的规范来解读,而非孤立阅读。后续模块将在此视角下深入具体提取方法、载体单元分析和操作流程。
四、可执行命令或查询方式
在分析前,可通过浏览器开发者工具查看当前页面加载的JS文件。以OWASP Juice Shop为例:
- 访问
http://localhost:3000。 - 按F12打开开发者工具,切换到“Network”标签,刷新页面。
- 在筛选栏输入“JS”,查看加载的JS文件列表。
- 点击任意文件,在“Response”或“Preview”选项卡中查看源代码。
也可用curl获取JS文件:
curl -s http://localhost:3000/main.js -o main.js五、工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| 浏览器开发者工具(Network面板) | 实时查看页面加载的JS文件及请求详情 | 无需安装,实时可视,可结合其他面板分析 | 无法批量处理,需手动保存 |
| curl / wget | 获取静态JS文件到本地 | 简单高效,可集成脚本自动化 | 无法处理动态加载或需特定上下文的JS |
| 浏览器扩展(如JavaScript Detector) | 快速发现页面中所有内联和外部JS | 快速提取所有JS链接 | 扩展可能收集数据,需注意隐私 |
| 爬虫工具(如ZAP、Burp Suite Spider) | 自动发现应用中的JS资源 | 集成在综合工具中,可联动后续扫描 | 配置较复杂,可能遗漏动态加载资源 |
六、标准操作步骤
- 打开目标应用首页(如
http://localhost:3000),打开浏览器开发者工具。 - 切换到Network面板,勾选“Preserve log”防止页面跳转丢失记录。
- 刷新页面,在筛选框输入“JS”过滤出JS文件。
- 依次点击每个JS文件,在“Preview”或“Response”中查看源代码,初步了解代码结构和信息类型。
- 记录外部JS文件的完整URL,后续可用其他工具下载。
- 关闭开发者工具。
七、如何验证结果真实性
验证方法:
- 对比开发者工具中JS文件列表与页面源码中
<script src="...">标签的引用是否一致。 - 用curl或浏览器访问JS文件的URL,确认返回内容为JS(HTTP 200),且与开发者工具显示一致。
- 对于动态生成的文件(如含时间戳),多次刷新确认其存在且内容合理。
八、常见错误与排查方式
- 错误1:只关注外部JS,忽略内联脚本
排查:在开发者工具“Elements”面板中搜索<script>标签,查看内联JS。 - 错误2:未开启“Preserve log”导致跳转后记录丢失
排查:始终勾选Preserve log,或使用浏览器的录制功能。 - 错误3:混淆第三方JS与应用自身JS
排查:通过URL域名区分,应用自身JS通常位于同域名下(如localhost:3000)。
九、合规边界说明
网络安全视角:本模块仅涉及对公开可访问的客户端代码进行观察和下载,属合法信息收集范畴,不构成攻击。但未经授权对网站进行大规模爬取可能违反服务条款,应在授权测试范围内进行。
风险与局限:静态JS文件列表无法全面反映动态加载的代码(如通过 import() 引入的模块),需结合动态分析补充。
缓解措施:测试前确认目标授权范围;对敏感JS文件内容妥善保管。
决策指南:在安全测试早期信息收集阶段,建议执行本模块操作以获取应用前端全貌。若应用高度依赖服务端渲染(SSR),则JS文件可能较少,应结合其他方法收集信息。
十、本模块阶段性小结
本模块建立了前端交互的宏观认知,明确了JS代码在Web应用中的定位及信息价值,并掌握了初步的JS资源发现方法。后续模块将深入探讨从JS代码中提取的具体信息及其对测试的指导作用。
二、明确信息提取的核心目标
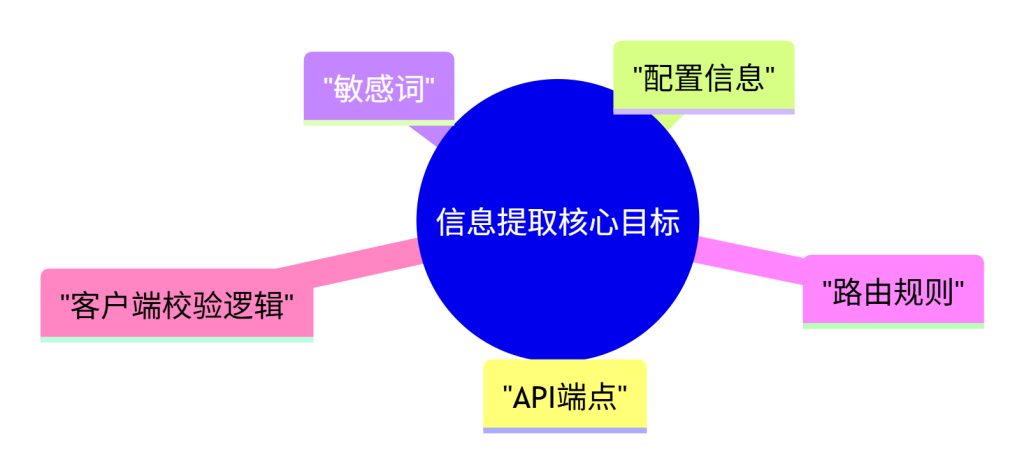
一、模块概念解释
获取前端JS文件后,需明确从中提取的信息以支持后续安全测试。本模块界定信息提取的核心目标:从脚本代码中挖掘对后端接口探测、配置发现、业务逻辑理解有直接帮助的数据元素,例如隐藏的API端点、请求参数格式、硬编码凭证或密钥、路由规则、客户端校验逻辑等。明确目标可提高信息收集的效率和准确性。
二、技术原理说明
这些信息出现在前端代码的原因包括:前端需与后端通信,因此API路径、请求方法、参数名等必须在前端指定;开发者可能为调试或快速迭代,临时将敏感信息(如测试环境密钥、内部接口)留在代码中;现代前端框架(如React、Vue)的路由定义可能暴露未在菜单中显示的功能页面;部分业务逻辑(如折扣计算、权限判断)可能在客户端实现,虽最终需后端校验,但前端实现可能泄露逻辑漏洞点。信息提取的核心目标是找出这些本不应暴露但实际存在的敏感数据。
三、在系统中的位置
本模块承接上一模块的认知框架,将宏观认知转化为具体信息查找清单,指导后续的解构载体单元和分析方法。在此阶段,需带着明确目标审视JS代码。
四、可执行命令或查询方式
可使用命令行工具 grep 快速搜索JS文件中的常见模式。以Juice Shop为例:
# 搜索可能的API路径(以/api/开头)
grep -E '"/api/[^"]+"' main.js
# 搜索可能的URL(包含http或https)
grep -E 'https?://[^"]+' main.js
# 搜索敏感词(key, secret, token, password)
grep -i -E 'key|secret|token|password' main.js
# 搜索路由定义(如Vue Router中的path)
grep -E 'path:\s*"[^"]+"' main.js也可使用浏览器开发者工具的全局搜索(Ctrl+Shift+F)在所有加载资源中搜索关键词。
五、工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| grep (命令行) | 快速在本地JS文件中搜索关键词 | 速度快,可批量处理,支持正则 | 需先下载文件,无法处理动态内容 |
| 浏览器开发者工具(全局搜索) | 在浏览器中实时搜索所有已加载资源 | 无需下载,支持上下文查看 | 搜索结果可能受限于动态加载内容 |
| 在线正则测试工具(如regex101) | 验证正则表达式有效性 | 可视化调试,便于学习正则 | 不直接分析JS文件 |
| IDE(如VS Code) | 对整个项目JS文件进行高级搜索 | 支持代码高亮、多文件重构分析 | 需导入文件,适合深度分析 |
六、标准操作步骤
- 收集所有待分析的JS文件(可从上一模块获取)。
- 确定搜索关键词列表:API端点(/api/, /v1/, /rest/)、HTTP方法(GET, POST, PUT, DELETE)、参数名(id, user, token)、敏感词(key, secret, internal, admin)。
- 使用grep或IDE对所有JS文件执行关键词搜索。
- 记录匹配的行及其上下文,评估潜在价值(如
/api/admin可能表示管理员接口)。 - 将疑似API路径整理为待验证列表。
七、如何验证结果真实性
搜索结果可能包含误报,需进一步验证:
- 对发现的API路径,在授权环境下用curl测试:
bash curl -I http://localhost:3000/api/admin
观察HTTP状态码,若返回200、401、403等非404码,说明接口存在。 - 对发现的敏感词,检查上下文,确认是变量名或注释,而非真实凭证。
- 动态执行代码(下一模块)可验证部分信息是否实际使用。
八、常见错误与排查方式
- 错误1:搜索词过于宽泛导致大量无意义结果
排查:使用更精确的正则,结合上下文过滤,例如搜索完整路径模式而非单个词。 - 错误2:忽略代码压缩混淆导致关键词变形
排查:关注可能被编码或拼接的字符串,如'/api/' + 'user'。 - 错误3:误将第三方库中的关键词当作应用自身信息
排查:通过目录或注释区分第三方库代码。
九、合规边界说明
网络安全视角:搜索JS文件中的关键词是标准信息收集技术,但不得利用发现的信息进行未授权访问或攻击。发现的敏感信息(如硬编码密钥)应立即报告,避免滥用。
风险与局限:静态搜索可能遗漏动态拼接的信息,且压缩混淆会降低搜索效果。
缓解措施:结合动态分析(模块四)补充;对搜索结果进行人工研判。
决策指南:本模块为信息提取的核心规划阶段,建议在静态分析前明确目标。若应用代码极度混淆,应考虑以动态分析为主。
图:信息提取核心目标思维导图
十、本模块阶段性小结
本模块明确了从JS代码中提取信息的核心目标,包括API端点、配置、敏感词等,并介绍了通过关键词搜索快速定位潜在信息点的方法。这些目标将成为后续解构信息载体单元的具体指向。后续模块将解析承载这些信息的代码结构。
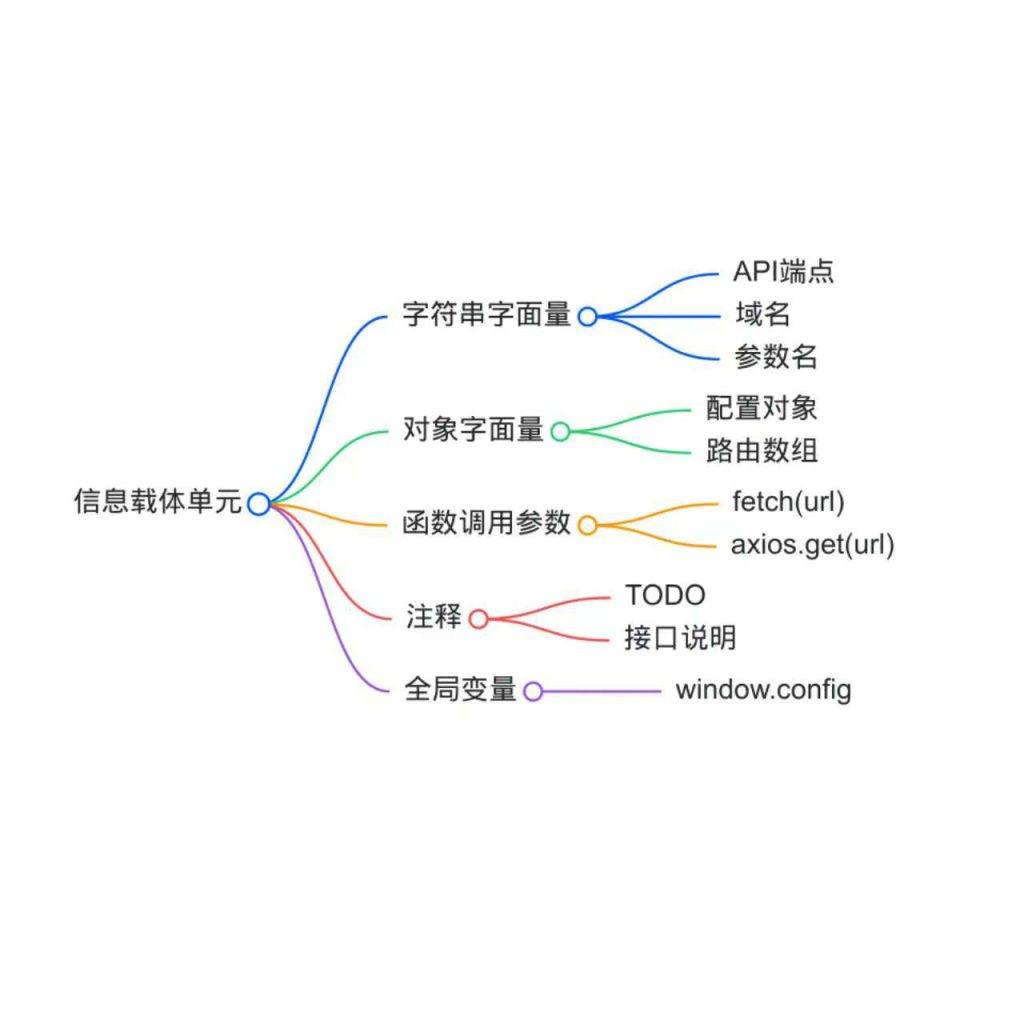
三、解构代码中的信息载体单元
一、模块概念解释
JavaScript代码由各种语法单元组成,其中某些单元类型特别容易承载有价值的信息。本模块划分这些关键构成要素,帮助你识别代码中哪些部分可能包含接口定义、配置对象、路由规则、硬编码数据等。通过掌握信息载体单元的特征,可以更系统地提取信息,而非零散地寻找关键词。
二、技术原理说明
从代码结构层面,以下单元是信息载体的常见形式:
- 字符串字面量:API端点、域名、参数名等通常以字符串形式出现,可能直接写死或通过模板字符串拼接。
- 对象字面量:配置信息(如
{ apiUrl: '...', timeout: 5000 })常以对象形式集中定义;路由框架(如Vue Router、React Router)使用对象数组描述路径和组件映射。 - 函数调用参数:
fetch(url, options)、axios.get(url)等网络请求函数,其第一个参数往往是API路径。 - 注释:开发者可能留下TODO、FIXME、说明性注释,其中可能包含接口说明或测试账号。
- 全局变量:某些框架会将配置挂载到全局对象(如
window.config)。
理解这些载体单元,有助于在阅读代码时快速定位潜在信息点。
三、在系统中的位置
本模块是静态分析的核心技术环节,它建立在明确提取目标的基础上,将关键词搜索细化为结构识别。通过学习本模块,你将能从代码中“看到”信息,而不仅仅是“找到”关键词。后续的动态分析将在此基础上验证这些信息是否真实有效。
四、可执行命令或查询方式
可以使用更精细的正则表达式或抽象语法树(AST)工具提取特定结构。例如:
# 提取所有对象字面量中的apiUrl属性
grep -E 'apiUrl\s*:\s*"[^"]+"' main.js
# 提取fetch调用中的第一个字符串参数
grep -E 'fetch\s*\(\s*["`][^"`]+["`]' main.js
# 提取Vue Router的path定义
grep -E 'path\s*:\s*["`][^"`]+["`]' main.js若需更精确的提取,可使用JavaScript解析工具如 jq 结合AST(如 acorn),但普通测试中grep足够。
五、工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| grep / ripgrep | 快速搜索特定模式 | 速度快,支持正则,适合一次性查找 | 无法理解代码结构,易漏掉动态拼接 |
| IDE智能感知(如VS Code) | 查看变量引用、跳转到定义 | 可结合代码结构分析,方便人工审查 | 需人工操作,不适合批量自动化 |
| 浏览器开发者工具(Sources面板) | 断点调试,查看运行时对象 | 可观察变量实际值,验证静态推测 | 动态调试耗时,不适合大规模提取 |
| AST工具(如ast-grep) | 基于语法树精确匹配代码结构 | 精确度高,支持复杂查询 | 学习曲线陡峭,需配置规则 |
六、标准操作步骤
- 将JS文件加载到支持语法高亮的编辑器(如VS Code)中。
- 浏览代码,识别常见的载体单元:
- 查找包含
api、url、endpoint等关键字的变量赋值。 - 查找形如
{ path: '/admin', component: AdminPanel }的对象数组,这可能是路由定义。 - 查找
fetch、axios、XMLHttpRequest调用。 - 查找
window.xxx赋值,可能为全局配置。
- 查找包含
- 使用编辑器的搜索功能,结合正则或普通文本查找上述模式。
- 对每个发现,记录其出现的文件和行号,以及上下文代码片段。
- 初步判断每个发现是否可能对应实际可访问的接口或配置。
七、如何验证结果真实性
- 对于路由定义,尝试在浏览器中直接访问该路径(如
http://localhost:3000/admin),观察是否有页面加载。 - 对于fetch调用中的URL,用curl测试该端点。
- 对于配置对象中的属性,可在浏览器控制台输出对应对象查看实际值(例如若代码中有
console.log(config),可打开控制台查看输出)。 - 若代码被压缩,可使用浏览器开发者工具的“Pretty print”功能格式化代码后重新分析。
八、常见错误与排查方式
- 错误1:将模板字符串中的变量部分误认为固定路径
排查:注意${}插值,需要进一步追踪变量来源。 - 错误2:忽略动态导入的模块
排查:查找import()调用,其参数可能包含动态加载的JS路径,需额外分析。 - 错误3:误将注释中的示例URL当作真实接口
排查:注释中的URL往往是示例或文档,应优先关注代码实际使用的字符串。
九、合规边界说明
网络安全视角:解构代码中的信息载体是深度分析的必要步骤,但需注意不要尝试利用发现的未公开接口进行权限提升或越权操作。所有发现的潜在入口点应仅在授权测试范围内验证。
风险与局限:静态解构无法识别运行时动态生成的字符串(如通过 /api/ + userId 拼接),也无法处理经过复杂混淆的代码。
缓解措施:结合动态执行(如模块四)补充,对混淆代码可使用动态调试逐步还原。
决策指南:当应用代码较简单或未混淆时,本模块方法高效;若代码高度混淆,应优先采用动态分析。
图:信息载体单元分类思维导图
十、本模块阶段性小结
本模块深入剖析了JS代码中承载信息的语法单元,使你能够从结构层面识别API、路由、配置等关键元素。现在你已经能够静态定位到潜在的信息点,但静态信息是否真实有效,还需通过动态执行来验证。后续模块将介绍如何结合静态与动态分析,形成完整的分析框架。
四、构建静态动态结合的分析框架
一、模块概念解释
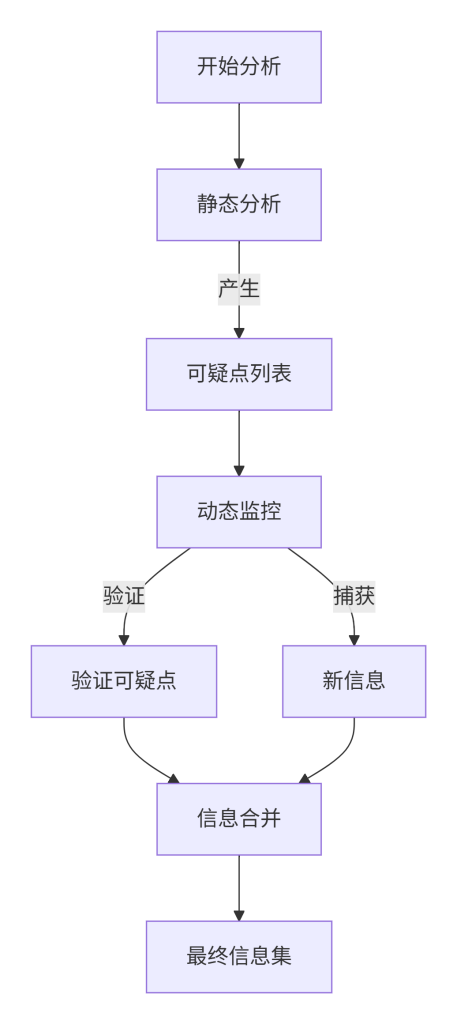
单纯的静态代码分析可能遗漏动态生成的信息,而纯粹的动态分析又可能缺乏全局视角。本模块确立一种通用模式:将静态代码阅读与动态执行监控相结合,以全面提取信息。静态分析负责快速定位可能的代码位置和结构,动态分析则负责验证这些信息在运行时是否真实出现,并捕捉动态拼接的字符串、异步加载的代码等静态无法覆盖的内容。通过两者结合,可以最大化信息提取的完整性和准确性。
二、技术原理说明
静态分析基于源代码文本,可以快速发现硬编码的字符串和结构模式,但无法处理依赖运行时环境(如用户状态、浏览器API)才确定的值。动态分析通过实际执行代码,观察其行为(如网络请求、控制台输出、DOM变化),能够捕获代码在真实运行时的表现。两者结合的逻辑是:先通过静态分析列出所有可疑点,然后在动态执行时重点关注这些点是否触发,同时利用动态工具(如网络监听)捕获所有实际发出的请求,与静态列表对比,发现遗漏。此外,动态分析还能通过断点调试,在代码执行到特定位置时查看变量值,从而解析出动态拼接的完整字符串。
三、在系统中的位置
本模块是信息提取的方法论核心,它整合了前三个模块的成果(认知、目标、载体),并引入动态维度,使分析从“纸面”走向“真实运行”。完成本模块后,你将掌握一套通用的信息提取流程,能够应对大多数Web应用。后续模块将把这个流程固化为标准操作序列。
四、可执行命令或查询方式
使用浏览器开发者工具进行动态监控:
- 打开开发者工具,切换到“Network”面板,确保已勾选“Preserve log”。
- 在应用中进行常规操作(点击按钮、提交表单、导航等),观察网络请求中是否出现了静态分析中未发现的API。
- 切换到“Sources”面板,找到感兴趣的JS文件,设置断点(点击行号)。
- 触发断点,在“Scope”或“Watch”中查看变量值,特别是那些静态分析中为变量名的部分。
- 使用“Console”面板,输入代码中出现的对象名(如
config),查看其属性值。
也可以在命令行中使用无头浏览器(Headless Browser,如Puppeteer)自动抓取网络请求:
// 简单的Puppeteer脚本示例
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.setRequestInterception(true);
page.on('request', request => {
if (request.url().includes('/api/')) {
console.log('API请求:', request.url());
}
request.continue();
});
await page.goto('http://localhost:3000');
// 等待页面可能触发的异步请求
await page.waitForTimeout(5000);
await browser.close();
})();五、工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| 浏览器开发者工具 | 手动交互式动态分析 | 直观,可结合多种面板实时调试 | 手动操作,不适合大规模重复 |
| Puppeteer / Playwright | 自动化模拟用户行为,捕获网络请求 | 可编程,可重复,可集成到流程 | 需编写脚本,处理动态内容较复杂 |
| Burp Suite(Proxy+Repeater) | 拦截并修改请求,观察响应 | 专业Web测试工具,可深度分析 | 需配置代理,对前端JS动态分析较弱 |
| 浏览器扩展(如Requestly) | 修改请求/响应,模拟不同场景 | 方便快速测试特定场景 | 功能有限,不如完整工具强大 |
六、标准操作步骤
- 完成静态分析,整理出可疑API列表和配置点。
- 打开浏览器开发者工具,准备动态监控:
- Network面板:开启Preserve log,清空现有日志。
- Console面板:准备查看输出。
- Sources面板:在静态分析中发现的感兴趣位置设置断点。
- 在应用中手动执行所有可能触发网络请求的操作,或编写自动化脚本模拟用户行为。
- 观察Network面板中新增的请求,对比静态列表,记录新发现的端点。
- 当断点触发时,在Scope面板中查看相关变量的值,记录动态拼接出的完整字符串。
- 将动态发现的信息补充到信息汇总表中。
七、如何验证结果真实性
动态分析的结果本身就是真实运行时发生的,因此其真实性相对可靠。但仍需验证:
- 观察网络请求是否成功发送并收到响应(状态码非0)。
- 断点处查看的变量值应与后续网络请求中的参数一致。
- 若使用自动化脚本,可增加断言判断是否捕获到预期请求。
八、常见错误与排查方式
- 错误1:未触发所有功能点,导致动态信息遗漏
排查:遍历应用所有功能,或使用爬虫工具触发尽可能多的路径。 - 错误2:断点设置过多导致调试混乱
排查:仅对关键位置设断点,或使用条件断点。 - 错误3:未考虑异步加载的代码
排查:在Network面板中留意新加载的JS文件,对其也进行静态分析。
九、合规边界说明
网络安全视角:动态分析涉及实际执行代码并发送请求,必须在授权目标上进行。断点调试仅影响本地浏览器环境,不构成攻击。但自动化脚本可能产生大量请求,需注意不要对目标造成拒绝服务。
风险与局限:动态分析依赖于用户行为的覆盖度,可能遗漏深层功能;且某些请求可能需特定权限(如登录),需提前准备测试账号。
缓解措施:结合多种用户角色进行测试;对敏感操作(如删除)谨慎触发。
决策指南:当静态分析发现大量动态拼接或异步加载时,必须采用动态分析;若应用非常简单且无动态交互,静态分析可能已足够。
图:静态动态结合分析框架流程图
十、本模块阶段性小结
本模块构建了静态动态结合的分析框架,使你能够从静态结构入手,通过动态执行验证并补充信息。现在你已经具备了全面提取JS信息的方法论。接下来,我们将把这些方法固化为系统性的操作序列,形成标准作业流程。
五、形成系统性信息提取操作序列
一、模块概念解释
本模块将前序的理论和方法整合为一套标准化的操作序列,从获取JS代码到最终整理出可用的信息清单,每一步都有明确的目标和产出。通过遵循这套流程,测试人员可以系统性地完成JS信息提取,避免遗漏和混乱,提高工作效率和结果的可复现性。
二、技术原理说明
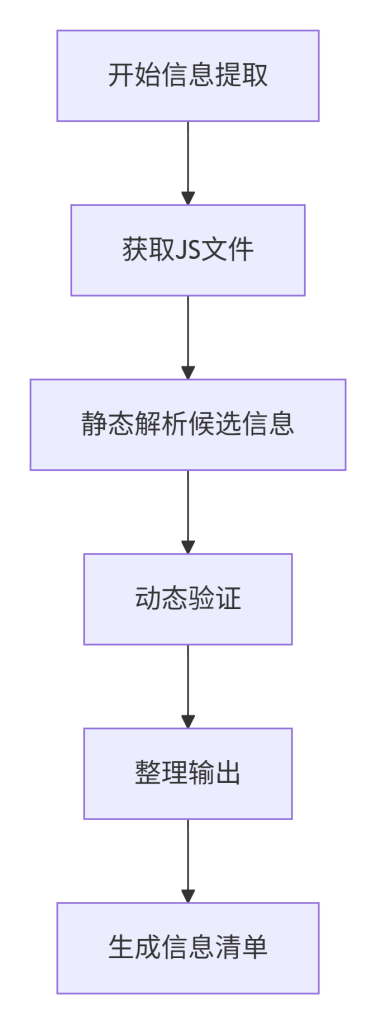
系统性操作序列基于信息处理的生命周期设计:获取(Acquisition)→ 静态解析(Static Analysis)→ 动态验证(Dynamic Verification)→ 整理输出(Consolidation)。每个阶段都有特定的任务和工具。获取阶段确保得到完整的JS资源;静态解析阶段通过关键词和结构提取候选信息;动态验证阶段通过执行和监控确认候选信息的真实性并发现新信息;整理输出阶段将信息分类、去重、格式化,形成报告。这个序列体现了从广泛收集到精炼验证的漏斗式思维,确保最终信息的质量。
三、在系统中的位置
本模块是操作层面的最终落实,它将前四个模块的知识转化为可执行的步骤。完成本模块后,你将能够独立完成一次完整的JS信息提取任务,并为后续安全测试(如接口fuzz、权限测试)准备好输入数据。
四、可执行命令或查询方式
以下是一个完整的操作序列脚本示例(Linux/bash环境):
# 阶段1:获取
mkdir js_analysis && cd js_analysis
curl -s http://localhost:3000/main.js -o main.js
curl -s http://localhost:3000/vendor.js -o vendor.js
# 如果有多个JS文件,可以编写循环从页面源码中提取
# 阶段2:静态解析
grep -E '"/api/[^"]+"' *.js > api_candidates.txt
grep -E 'https?://[^"]+' *.js > url_candidates.txt
grep -i -E 'key|secret|token' *.js > sensitive_candidates.txt
# 阶段3:动态验证(使用Puppeteer脚本捕获网络请求,需Node.js环境)
node capture_requests.js > dynamic_apis.txt
# 阶段4:整理输出
cat api_candidates.txt dynamic_apis.txt | sort -u > final_apis.txt五、工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| Shell脚本组合 | 自动化批量处理本地文件 | 灵活,可定制,适合Linux环境 | 需手动编写脚本,处理动态需结合其他工具 |
| Burp Suite + 扩展 | 集成化Web测试,可记录所有请求 | 图形化,可深度分析请求/响应 | 动态分析依赖手动触发,自动化有限 |
| 专用JS分析工具(如LinkFinder) | 自动化从JS中提取端点 | 专门针对此任务,功能集中 | 可能误报,需人工验证 |
| Postman + Newman | 测试API并管理集合 | 适合后续API测试阶段 | 不直接用于JS提取,需先获取端点 |
六、标准操作步骤
- 获取JS文件:
- 使用爬虫或手动方式收集目标应用的所有JS文件URL。
- 下载所有JS文件到本地目录,记录来源URL。
- 静态解析候选信息:
- 对每个JS文件运行正则搜索,提取API路径、URL、敏感词等。
- 使用AST工具(可选)提取更精确的结构化信息。
- 合并所有候选结果,去重,形成待验证列表。
- 动态验证:
- 在浏览器中打开应用,启用开发者工具Network录制。
- 遍历应用主要功能,确保触发尽可能多的请求。
- 记录所有发往本域的请求URL,与静态列表对比,补充新发现。
- 对静态列表中的可疑端点,手动在浏览器中访问或使用curl测试,确认是否存在。
- 整理输出:
- 将验证为存在的API端点整理成清单,标注请求方法(若能从JS中推测)。
- 将发现的配置信息(如密钥占位符)归类记录。
- 输出报告,包含端点、参数示例、上下文说明。
七、如何验证结果真实性
最终的信息清单必须经过验证:
- 对每个API端点,使用
curl -I或浏览器访问,确认返回状态码(即使401/403也说明端点存在)。 - 对配置信息,检查其是否在运行时被使用(如通过控制台输出)。
- 对于敏感词,确认其不是随机字符串或误报。
八、常见错误与排查方式
- 错误1:静态解析时未考虑多个JS文件之间的相互引用
排查:合并所有JS文件后再搜索,或使用支持跨文件搜索的IDE。 - 错误2:动态验证时遗漏了需要特定用户状态才能触发的请求
排查:使用不同权限账号登录测试,或模拟认证状态。 - 错误3:信息整理混乱,未标注来源和可信度
排查:建立结构化记录格式,例如CSV包含字段:端点、发现方式(静态/动态)、状态码、上下文。
九、合规边界说明
网络安全视角:系统性操作流程应只在授权测试环境中执行。提取的API清单不得用于非法攻击。若发现硬编码敏感信息,应立即报告并建议开发移除。
风险与局限:流程依赖测试者的操作覆盖度,可能遗漏深层功能;自动化工具可能产生误报。
缓解措施:采用多轮测试,结合自动化脚本和手动探索;对关键结果进行人工复核。
决策指南:在每次安全测试的信息收集阶段,都应执行此操作序列;对于大型应用,可编写自动化脚本定期执行。
图:系统性信息提取操作序列流程图
十、本模块阶段性小结
本模块将信息提取过程标准化为四个阶段:获取、静态解析、动态验证、整理输出,并提供了可执行的命令示例。至此,你已经掌握了从JS中提取信息的完整操作流程。接下来,我们需要讨论这些分析行为的有效范围与约束,以避免误判和过度解读。
六、界定分析行为的有效范围与约束
一、模块概念解释
任何分析方法都有其适用条件和潜在风险。本模块旨在明确JS信息提取的有效范围(即哪些情况下该方法可靠)以及可能出现的误判风险,并提供风险控制措施。理解这些边界条件,可以帮助你更准确地解读分析结果,避免将不存在的接口误认为真实,或将误报引入后续测试。
二、技术原理说明
JS信息提取的有效性与应用的架构、代码质量、混淆程度等因素相关。
- 适用条件:在前后端分离的单页应用(SPA)中,前端包含大量API定义,提取效果最好。传统多页应用(MPA)中,JS代码较少,信息可能主要存在于服务端渲染的页面中,JS提取的价值相对较低。
- 误判风险:
- 代码中可能包含注释掉的旧接口或示例URL,这些并不实际存在。
- 动态拼接的URL可能在运行时才确定,静态分析无法准确还原。
- 混淆工具(如UglifyJS、Webpack打包)会使变量名无意义,但字符串通常保留,仍可提取。
- 提取的API端点可能仅在前端用于展示,而后端并未实现(如mock数据)。
- 部分API需要特定HTTP方法或请求头才能访问,仅凭URL无法确认其可用性。
- 风险控制:通过动态验证、上下文分析、状态码判断等手段降低误报。
三、在系统中的位置
本模块位于操作流程之后,但属于元认知层面,指导如何解读和应用前面得到的信息。它提醒我们在使用提取结果进行后续测试前,必须评估其可信度和局限性,避免盲目行动。
四、可执行命令或查询方式
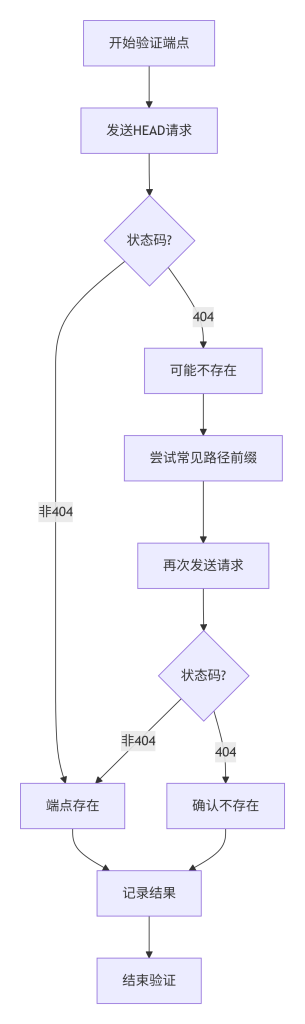
验证提取的API端点是否真实存在:
# 测试端点是否存在(不发送敏感数据)
curl -I http://localhost:3000/api/candidate观察HTTP状态码:
- 200/401/403/500 等非404状态码 → 端点很可能存在。
- 404 → 端点可能不存在,或需要特定路径前缀。
若怀疑是动态拼接,可尝试常见变体:
curl -I http://localhost:3000/api/v1/candidate
curl -I http://localhost:3000/rest/candidate五、工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| curl | 快速测试单个端点 | 简单,支持自定义方法/头 | 需手动测试每个端点,效率低 |
| HTTPie | 类似curl,但输出更友好 | 语法简洁,彩色输出 | 同上 |
| Burp Suite Intruder | 批量测试多个端点 | 可自动化,支持变量 | 配置较复杂 |
| 自定义脚本(Python requests) | 批量测试并记录结果 | 灵活可控,可集成到流程 | 需编程能力 |
六、标准操作步骤
- 将待验证的API端点列表导入一个文本文件。
- 编写简单脚本(如Python)批量发送HEAD请求,记录状态码。
- 对返回非404的端点,进一步用GET请求测试,观察响应内容。
- 分析响应内容,确认是否与应用功能相关(例如返回JSON数据或错误信息)。
- 标记每个端点的验证结果:存在、可能不存在、需进一步确认。
七、如何验证结果真实性
验证的逻辑是:如果端点返回HTTP 200/4xx/5xx(非404),说明服务器处理了该请求,即该路径是有效的路由。但需注意:
- 某些框架可能对任意路径都返回200(如前端路由的history模式),此时需结合Content-Type判断。
- 若返回200但内容是HTML页面,可能是前端路由的页面,而非API端点。
- 对于API端点,期望的响应通常是JSON/XML,可通过
curl -H "Accept: application/json"测试。
八、常见错误与排查方式
- 错误1:将404直接判定为不存在,但可能缺少路径前缀
排查:尝试添加常见前缀(/api、/v1、/rest)重新测试。 - 错误2:忽略HTTP方法要求
排查:如果GET返回404,尝试POST或OPTIONS方法。 - 错误3:被WAF或认证机制干扰
排查:观察响应头或响应体是否提示缺少认证,若返回401/403,说明端点存在且需要认证。
九、合规边界说明
网络安全视角:验证API存在时,应仅使用轻量级请求(如HEAD),避免对目标造成压力。不得尝试利用验证出的端点进行越权操作或数据篡改。
风险与局限:验证只能确认端点存在,但不能确认其安全状况。端点可能包含漏洞,需后续专项测试。
缓解措施:在验证阶段严格限制请求频率和大小;对敏感端点(如/admin)测试前确认授权。
决策指南:在将信息用于后续测试前,必须经过验证。若验证结果模糊(如所有路径都返回200),需结合其他手段(如JS上下文分析、应用功能映射)辅助判断。
图:API端点验证决策流程图
十、本模块阶段性小结
本模块明确了JS信息提取的有效范围,强调了误判风险,并提供了验证方法和风险控制措施。现在你能够更客观地评估所提取信息的可信度,避免将虚假信息带入后续测试阶段。接下来,我们将讨论如何将已验证的信息整合输出,形成支持安全测试决策的成果。
七、整合输出可执行的应用分析成果
一、模块概念解释
信息收集的最终目的是为后续安全测试提供输入。本模块讲解如何将提取并验证的信息进行结构化整理,转化为可执行的测试依据。输出成果应包括:API端点清单(含方法、参数示例)、敏感配置项、业务逻辑片段等。这些成果将指导后续的漏洞挖掘(如权限测试、注入测试、配置审查)。
二、技术原理说明
安全测试通常遵循“信息→攻击面→漏洞”的路径。JS提取的成果直接构成了攻击面的一部分:API端点是直接可交互的入口;配置项可能暴露敏感数据或调试功能;业务逻辑片段可辅助理解功能流程,发现逻辑漏洞。因此,输出成果必须清晰、准确、可操作。例如,API清单应包含端点URL、推测的HTTP方法、需要的认证类型(若能从JS中推断)、请求参数示例等。此外,还需标注信息来源(静态/动态)和可信度,以便测试时合理分配精力。
三、在系统中的位置
本模块是整个JS信息收集流程的收尾阶段,产出物将直接输入到下一阶段的测试(如模糊测试、权限测试)。它是信息收集与漏洞挖掘之间的桥梁。
四、可执行命令或查询方式
生成一份Markdown格式的成果报告示例:
# 生成API清单表格
echo "| 端点 | 方法 | 参数 | 来源 | 状态码 |" > api_report.md
echo "|------|------|------|------|--------|" >> api_report.md
while read line; do
# 假设line格式为:/api/user GET static 200
echo "| $line |" >> api_report.md
done < validated_apis.txt也可以输出为JSON格式,便于后续工具处理:
{
"endpoints": [
{"url": "/api/user", "method": "GET", "source": "static", "status": 200}
],
"configs": [
{"key": "recaptcha_site_key", "value": "6Lc...", "context": "main.js:120"}
]
}五、工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| Markdown表格 | 人工阅读的报告 | 简洁清晰,适合文档 | 不适合程序解析 |
| JSON/YAML | 程序化输入 | 易于被测试工具读取 | 需额外处理生成 |
| CSV | 数据交换 | 通用性强,可导入Excel | 缺乏层次结构 |
| Burp Suite 站点地图 | 直接导入Burp进行测试 | 无缝集成测试工具 | 仅限于Burp生态 |
六、标准操作步骤
- 汇总已验证的API端点,包括URL、推测的HTTP方法(若JS中有显示)、请求参数示例(从JS中提取或合理猜测)。
- 整理发现的敏感配置项,记录其键名、值(若存在)、所在文件和上下文。
- 标注每个信息点的来源(静态提取/动态捕获)和可信度(高/中/低)。
- 选择合适的输出格式(如Markdown报告、JSON文件)。
- 将成果提交给后续测试环节,或在报告中作为攻击面部分展示。
七、如何验证结果真实性
成果的真实性已在上一模块的验证步骤中确认。但最终输出时仍需确保:
- 所有端点均经过实际请求验证(状态码非404)。
- 配置项的值已脱敏(若为真实密钥,需替换为[REDACTED]),但注明其存在。
- 上下文描述准确,无歧义。
八、常见错误与排查方式
- 错误1:输出混乱,未区分API和静态资源
排查:明确标注类型,如API端点应区别于JS/CSS文件URL。 - 错误2:未包含方法信息,导致后续测试盲目使用GET
排查:尽量从JS中推断方法(如axios.post对应POST),无法推断则标注“未知”,并建议后续测试时尝试常见方法。 - 错误3:敏感信息未脱敏就输出到共享报告
排查:在生成报告前自动替换或手动审核敏感内容。
九、合规边界说明
网络安全视角:输出成果仅供授权测试使用,不得公开或泄露。若包含真实敏感信息(如密钥),应立即通知开发人员修复,而非在报告中明文保留。
风险与局限:成果可能不完整(如遗漏需深度交互的接口),测试人员应结合其他信息源(如爬虫结果)补充。
缓解措施:定期更新成果,随着测试深入可能发现新信息;对关键系统可采用多轮信息收集。
决策指南:在任何安全测试开始之前,必须完成此整合输出,形成攻击面清单。若应用规模庞大,可先输出高价值端点(如涉及认证、敏感数据的接口)优先测试。
十、本模块阶段性小结
本模块完成了从信息提取到成果输出的全流程,使零散的代码片段转化为结构化的可执行测试依据。至此,我们已经走完了“信息收集-Web应用-JS提取分析-URL&配置&逻辑”的完整工程化链条。通过这一系列模块的学习,你能够系统地从前端JavaScript中挖掘出对安全测试至关重要的信息,并为其后续利用奠定坚实基础。
参考与进一步阅读
本文操作与验证基于以下权威文档,建议读者访问官方最新页面以确认环境兼容性。
- MDN Web Docs: 向网页添加 JavaScript
本文中关于通过<script>标签识别和定位JavaScript资源的方法依据。 - MDN Web Docs: 理解 JavaScript 前端框架
本文中关于现代前端框架(SPA)路由定义、组件结构与信息泄露风险的技术原理依据。 - Puppeteer 官方文档: What is Puppeteer?
模块四中 Puppeteer 自动化脚本示例及其功能说明的主要依据。 - Puppeteer 官方文档: FAQ
模块四中关于page.waitForTimeout替代方案及Puppeteer核心概念的补充依据。 - PortSwigger: Launching Burp Suite from the command line
工具对比表和合规边界说明中,关于 Burp Suite 专业Web测试工具功能描述的依据。