

本题答案为:
f_Z(z) = 2(1 - z), 0 < z < 1
f_Z(z) = 0, 其他
这里的关键不是把 X 和 Y 当成独立变量,而是直接使用二维连续型随机变量的变量变换公式。
一、题目条件与变量范围
题目给出 (X,Y) 的联合密度:
f(x,y) = x + y, 0 < x < 1, 0 < y < 1
= 0, 其他
要求:
Z = XY
因为 0 < X < 1,0 < Y < 1,所以:
0 < Z = XY < 1
因此最后的密度只可能在 0 < z < 1 上非零。
二、使用乘积型随机变量公式
图 2 中的公式本质上是:
若 Z = XY,且 (X,Y) 的联合密度为 φ(x,y),则
f_Z(z) = ∫ 1/|x| · φ(x, z/x) dx
这里不是要求 X,Y 独立。只要知道联合密度 φ(x,y),就可以用这个公式。
本题中:
φ(x,y) = x + y
所以:
φ(x, z/x) = x + z/x
于是:
f_Z(z) = ∫ 1/|x| · (x + z/x) dx
但积分范围不能直接写成 -∞ 到 +∞ 后就不管了。必须结合原来的区域:
0 < x < 1
0 < y < 1
y = z/x
因为 0 < z < 1,且 x > 0,所以:
0 < z/x < 1
这等价于:
x > z
同时又有:
x < 1
因此积分范围是:
z < x < 1
所以:
f_Z(z) = ∫[z 到 1] 1/x · (x + z/x) dx
化简:
1/x · (x + z/x)
= 1 + z/x²
于是:
f_Z(z)
= ∫[z 到 1] (1 + z/x²) dx
= ∫[z 到 1] 1 dx + ∫[z 到 1] z/x² dx
分别计算:
∫[z 到 1] 1 dx = 1 - z
以及:
∫[z 到 1] z/x² dx
= z∫[z 到 1] x⁻² dx
= z[-1/x][z 到 1]
= z(-1 + 1/z)
= 1 - z
所以:
f_Z(z) = (1 - z) + (1 - z) = 2(1 - z)
最终:
f_Z(z) = 2(1 - z), 0 < z < 1
f_Z(z) = 0, 其他
三、图 2 公式的转化原理
图 2 的公式来自二维变量变换。
要求 Z = XY 的密度,通常补充一个辅助变量,例如令:
U = X
Z = XY
那么:
x = u
z = xy
由 z = xy 得:
y = z/u
所以反变换为:
x = u
y = z/u
接下来要算雅可比因子:
∂(x,y)/∂(u,z)
也就是:
x = u
y = z/u
对 u,z 求偏导:
∂x/∂u = 1
∂x/∂z = 0
∂y/∂u = -z/u²
∂y/∂z = 1/u
所以行列式为:
| 1 0 |
| -z/u² 1/u |
= 1/u
取绝对值:
|∂(x,y)/∂(u,z)| = 1/|u|
因为这里 u=x,所以就是:
1/|x|
于是联合密度变为:
f_{U,Z}(u,z)
= φ(u, z/u) · 1/|u|
再把辅助变量 U 积掉,就得到 Z 的边缘密度:
f_Z(z) = ∫ φ(u, z/u) · 1/|u| du
把 u 改写成 x,就是图 2 的公式:
f_Z(z) = ∫ 1/|x| · φ(x, z/x) dx
所以这个公式的本质是:
先做二维变量变换,再对辅助变量积分消去。
四、这个公式有哪些常见变式?
这类题的核心套路是:要求一个新变量 Z = h(X,Y) 的密度,就补一个变量,把二维变换凑成一一对应,然后用雅可比因子。
1. 和:Z = X + Y
令:
U = X
Z = X + Y
则:
Y = Z - X
所以:
f_Z(z) = ∫ φ(x, z - x) dx
这里雅可比因子是 1。
2. 差:Z = X – Y
令:
U = X
Z = X - Y
则:
Y = X - Z
所以:
f_Z(z) = ∫ φ(x, x - z) dx
也可以令 U = Y,则:
X = Z + Y
于是:
f_Z(z) = ∫ φ(z + y, y) dy
这两个写法本质一样,只是选的辅助变量不同。
3. 积:Z = XY
这就是图 2 的公式:
f_Z(z) = ∫ 1/|x| · φ(x, z/x) dx
如果 X,Y 独立,联合密度可以写成:
φ(x,y) = f_X(x)f_Y(y)
于是才有:
f_Z(z) = ∫ 1/|x| · f_X(x) · f_Y(z/x) dx
但注意,本题没有用独立性,因为题目已经给了联合密度 φ(x,y)=x+y。
4. 商:Z = Y/X
令:
U = X
Z = Y/X
则:
Y = XZ
所以:
f_Z(z) = ∫ |x| · φ(x, xz) dx
这里的雅可比因子变成了 |x|,不是 1/|x|。
原因是:
积:y = z/x,所以 dy/dz = 1/x
商:y = xz,所以 dy/dz = x
所以积和商的系数正好不同。
五、为什么本题不能直接套独立变量乘积公式?
本题的联合密度是:
f(x,y) = x + y
如果 X,Y 独立,应当有:
f(x,y) = f_X(x)f_Y(y)
但本题中:
f_X(x) = ∫[0 到 1] (x+y) dy = x + 1/2
f_Y(y) = ∫[0 到 1] (x+y) dx = y + 1/2
如果独立,则应有:
f_X(x)f_Y(y) = (x + 1/2)(y + 1/2)
这显然不等于:
x + y
所以 X,Y 不独立。
但是不独立完全不影响本题计算,因为图 2 公式本来就是用联合密度 φ(x,y) 来算的,不是独立公式。
六、这类题的快速识别方法
看到题目给出 (X,Y) 的联合密度,又要求 Z = XY、Z = X/Y、Z = X+Y、Z = X-Y 这类变量函数的密度时,优先想到:
二维变量变换 + 雅可比因子 + 积掉辅助变量
具体到乘积型:
Z = XY
直接记:
f_Z(z) = ∫ 1/|x| · f(x, z/x) dx
然后最重要的一步是找积分范围:
原区域条件 + y = z/x
本题就是:
0 < x < 1
0 < z/x < 1
推出:
z < x < 1
这一步是这类题最容易错的地方。公式本身不难,难点通常在于把原来的二维区域正确投影到辅助变量的积分区间上。
这个雅克比因子,这一串是指按照这种式子∂(x,y)/∂(u,z)来推导的话,是不是只要行替换之后,他这个求因子的结果就会作为替换过后公式的系数对吧?
对,可以这样理解:按 ∂(x,y)/∂(u,z) 这种反变换雅可比来推导时,算出来的雅可比行列式绝对值,就会作为变量替换后密度函数前面的“系数因子”。
但要注意三个限制:
1. 必须取绝对值;
2. 必须用“旧变量对新变量”的雅可比:∂(x,y)/∂(u,z);
3. 还要重新确定新变量的取值范围,不能只换公式不换范围。
更准确地说,原来有联合密度:
f_{X,Y}(x,y)
现在做变量变换:
u = u(x,y)
z = z(x,y)
如果能反解出:
x = x(u,z)
y = y(u,z)
那么新变量 (U,Z) 的联合密度是:
f_{U,Z}(u,z)
= f_{X,Y}(x(u,z), y(u,z)) · |∂(x,y)/∂(u,z)|
所以你说的“替换过后公式的系数”基本就是这个意思。
以第 59 题为例,要算:
Z = XY
补一个辅助变量:
U = X
Z = XY
于是反解:
X = U
Y = Z/U
也就是:
x = u
y = z/u
接下来算雅可比因子:
∂(x,y)/∂(u,z)
对应矩阵是:
| ∂x/∂u ∂x/∂z |
| ∂y/∂u ∂y/∂z |
因为:
x = u
y = z/u
所以:
∂x/∂u = 1
∂x/∂z = 0
∂y/∂u = -z/u²
∂y/∂z = 1/u
因此:
∂(x,y)/∂(u,z)
=
| 1 0 |
| -z/u² 1/u |
= 1/u
取绝对值:
|∂(x,y)/∂(u,z)| = 1/|u|
因为这里 u = x,所以也可以写成:
1/|x|
于是:
f_{U,Z}(u,z)
= f_{X,Y}(u, z/u) · 1/|u|
然后再把辅助变量 u 积掉:
f_Z(z) = ∫ f_{X,Y}(u, z/u) · 1/|u| du
把 u 换名叫 x,就得到图 2 的形式:
f_Z(z) = ∫ f_{X,Y}(x, z/x) · 1/|x| dx
这里的本质可以用一句话概括:
概率不变,但坐标面积被拉伸或压缩了,所以密度要乘上面积缩放因子。
原来的概率小块大约是:
P ≈ f_{X,Y}(x,y) dxdy
变量换成 (u,z) 后,同一个小块面积满足:
dxdy = |∂(x,y)/∂(u,z)| dudz
所以:
P ≈ f_{X,Y}(x(u,z), y(u,z)) · |∂(x,y)/∂(u,z)| dudz
因此新密度就是:
原密度代入反变换 × 雅可比因子绝对值
这就是它为什么会变成“系数”的原因。
但是要特别注意:不能随便算 ∂(u,z)/∂(x,y) 然后直接乘。
如果算的是:
∂(u,z)/∂(x,y)
那这是“新变量对旧变量”的雅可比。密度变换中通常要用的是它的倒数:
|∂(x,y)/∂(u,z)| = 1 / |∂(u,z)/∂(x,y)|
当然前提是变换局部一一对应。
比如本题:
u = x
z = xy
算:
∂(u,z)/∂(x,y)
矩阵为:
| ∂u/∂x ∂u/∂y |
| ∂z/∂x ∂z/∂y |
=
| 1 0 |
| y x |
行列式是:
x
所以反过来:
|∂(x,y)/∂(u,z)| = 1/|x|
这和前面算出的 1/|u| 是一致的,因为 u=x。
所以考研里可以这样记:
如果用反解后的旧变量 x=x(u,z), y=y(u,z) 来算雅可比,
那么算出来的 |∂(x,y)/∂(u,z)| 直接乘到原联合密度后面。
如果用原变换 u=u(x,y), z=z(x,y) 来算雅可比,
那么要取倒数再乘。
第 59 题中就是:
旧密度:f(x,y) = x + y
反变换:
x = u
y = z/u
代入旧密度:
f(u, z/u) = u + z/u
乘雅可比因子:
f_{U,Z}(u,z) = (u + z/u) · 1/|u|
然后再根据原区域确定 u 的积分范围。因为原来:
0 < x < 1
0 < y < 1
代入:
x = u
y = z/u
得到:
0 < u < 1
0 < z/u < 1
当 0 < z < 1 时,有:
z < u < 1
所以:
f_Z(z)
= ∫[z 到 1] (u + z/u) · 1/u du
= ∫[z 到 1] (1 + z/u²) du
= 2(1 - z)
最后再强调一句:雅可比因子确实会作为替换后的系数,但它不是“凭空多出来的系数”,而是二维面积元从 dxdy 变成 dudz 时的面积缩放比例。
这类题最常见的错误不是雅可比算错,而是只记得乘 1/|x|,却忘了重新根据原区域确定积分上下限。第 59 题真正的关键就是从:
0 < x < 1, 0 < y < 1, y = z/x
推出:
z < x < 1
这个范围一旦确定,后面就是机械积分。
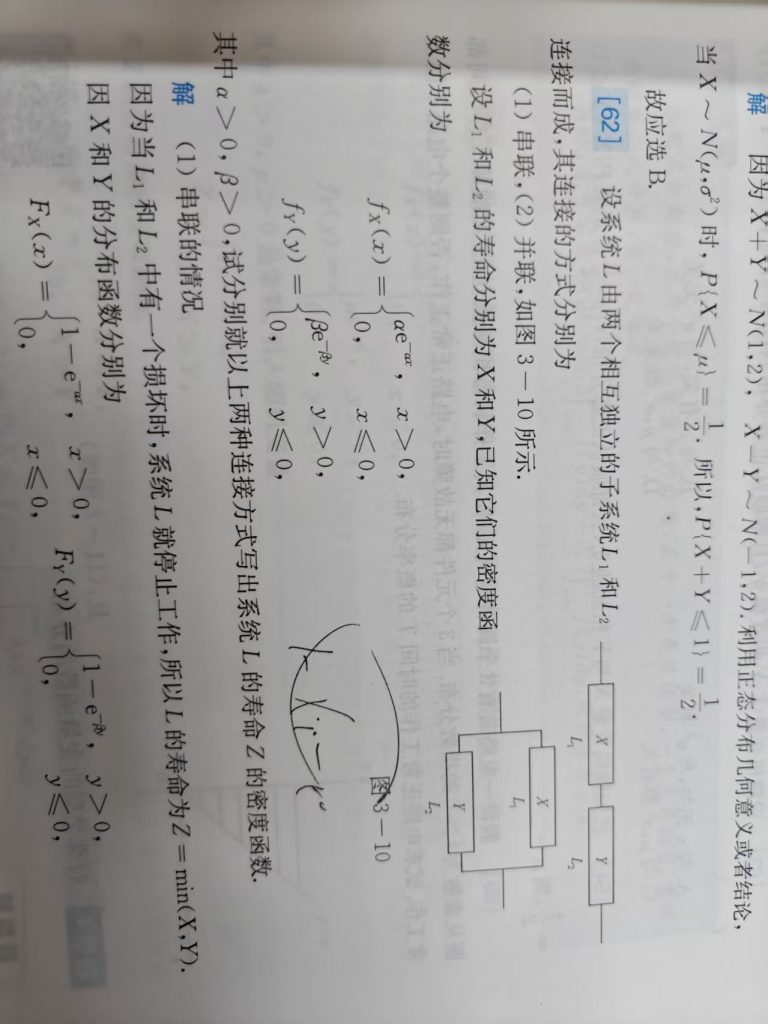
对,这道题的核心理解基本正确,但要稍微修正一下说法:
这里不是“求 f(x,y) 不能直接用密度函数”,而是说:要求系统寿命 Z = min(X,Y) 或 Z = max(X,Y) 的密度时,不能把 X、Y 的密度函数简单代入 min 或 max 得到 Z 的密度。
因为 Z = min(X,Y) 不是一一变换。很多不同的 (x,y) 都可能对应同一个 z,比如:
min(2,5)=2
min(2,100)=2
min(2,2.3)=2
所以不能像二维变量变换那样,直接用雅可比行列式写出密度。考研数学里遇到这种“由随机变量构造新随机变量”的题,尤其是 min(X,Y)、max(X,Y),最稳的方法就是先求分布函数,再求导得到密度函数。
本题中,X 和 Y 分别表示两个独立子系统 L₁、L₂ 的寿命,且
f_X(x) = αe^(-αx), x > 0
f_Y(y) = βe^(-βy), y > 0
它们都是指数分布。先由密度函数得到分布函数:
F_X(x) = P(X ≤ x) = 1 - e^(-αx), x > 0
F_Y(y) = P(Y ≤ y) = 1 - e^(-βy), y > 0
同时还要记住生存函数:
P(X > x) = e^(-αx)
P(Y > y) = e^(-βy)
对于串联系统,只要其中一个坏了,整个系统就停止工作,所以系统寿命为
Z = min(X,Y)
要求 Z 的分布函数:
F_Z(z) = P(Z ≤ z)
也就是:
F_Z(z) = P(min(X,Y) ≤ z)
这个事件不太好直接算,因为它表示“X ≤ z 或 Y ≤ z”,涉及并事件。考研中通常转化为对立事件:
min(X,Y) > z
等价于:
X > z 且 Y > z
所以:
P(min(X,Y) > z) = P(X > z, Y > z)
由于 X 和 Y 独立:
P(X > z, Y > z) = P(X > z)P(Y > z)
于是:
P(Z > z) = e^(-αz)e^(-βz) = e^(-(α+β)z)
所以:
F_Z(z) = 1 - P(Z > z)
即:
F_Z(z) = 1 - e^(-(α+β)z), z > 0
再对 z 求导,得到密度函数:
f_Z(z) = (α + β)e^(-(α+β)z), z > 0
这说明串联系统的寿命仍然服从指数分布,参数为 α + β。
这里容易误解的是“独立之后是不是可以直接乘密度”。
独立只能说明联合密度可以写成:
f_XY(x,y) = f_X(x)f_Y(y) = αβe^(-αx-βy)
但这只是 (X,Y) 这个二维随机变量的联合密度,不是 Z = min(X,Y) 的密度。
如果要通过联合密度求 Z 的分布,也可以,但仍然要对区域积分:
F_Z(z) = P(min(X,Y) ≤ z)
这个区域是:
{(x,y): x > 0, y > 0, min(x,y) ≤ z}
它不是简单的一条线,而是二维平面中的一大片区域。所以最后还是要转成概率区域积分,通常比分布函数法麻烦。
并联系统则相反,两个部件都坏了系统才停止,所以寿命为
T = max(X,Y)
这时求分布函数特别方便:
F_T(t) = P(T ≤ t)
即:
F_T(t) = P(max(X,Y) ≤ t)
这等价于:
X ≤ t 且 Y ≤ t
所以:
F_T(t) = P(X ≤ t, Y ≤ t)
因为 X 和 Y 独立:
F_T(t) = P(X ≤ t)P(Y ≤ t)
代入:
F_T(t) = (1 - e^(-αt))(1 - e^(-βt)), t > 0
再求导:
f_T(t) = αe^(-αt)(1 - e^(-βt)) + βe^(-βt)(1 - e^(-αt)), t > 0
所以这类题可以总结成两条非常常考的规则:
串联系统:
Z = min(X,Y)
优先用生存函数:
P(Z > z) = P(X > z, Y > z)
若独立:
P(Z > z) = P(X > z)P(Y > z)
并联系统:
T = max(X,Y)
优先用分布函数:
P(T ≤ t) = P(X ≤ t, Y ≤ t)
若独立:
P(T ≤ t) = P(X ≤ t)P(Y ≤ t)
因此你的理解可以整理成一句更准确的话:
对于由 X、Y 构成的新随机变量,特别是 min(X,Y)、max(X,Y) 这种非一一变换,不能把原来的密度函数直接“代进去”得到新变量密度。通常应先根据事件关系求新变量的分布函数,最后对分布函数求导得到密度函数。
这个题就是典型的“系统寿命 + 指数分布 + 串并联 + 最小值最大值分布”的考法。串联看 min,并联看 max;min 常用生存函数,max 常用分布函数。
这种类型的题目与可以直接通过概率密度,然后去求f(x,y)的概率密度的区别在哪?
可以这样区分:
能“直接用概率密度变换公式”的题,本质上是变量变换题;而 min(X,Y)、max(X,Y) 这种题,本质上是事件关系题。
这两类题最大的区别在于:原来的随机变量和新随机变量之间,是否存在一一对应关系。
假设原来有二维随机变量 (X,Y),现在定义新的二维随机变量:
U = X + Y
V = Y
这时从 (X,Y) 到 (U,V) 是可以反解的:
Y = V
X = U - V
也就是说,给定 (U,V),可以唯一确定原来的 (X,Y)。这种情况就是“二维到二维、一一对应”的变量变换题。
于是可以用概率密度变换公式:
f_UV(u,v) = f_XY(u-v, v) × |∂(x,y)/∂(u,v)|
这里的核心是:新变量 (U,V) 和旧变量 (X,Y) 维数相同,并且可以互相唯一确定。所以密度可以通过“代入 + 雅可比因子”来转化。
这类题考研中常见形式是:
U = X + Y, V = X - Y
U = X/Y, V = Y
U = X, V = XY
U = X + Y, V = X
只要能反解出:
x = x(u,v)
y = y(u,v)
并且雅可比不为 0,就可以按变量替换公式做。
但系统寿命这道题不是这种类型。它定义的是:
Z = min(X,Y)
这是从二维随机变量 (X,Y) 变成一维随机变量 Z。
问题在于,给定 Z = z,无法唯一反推出 (X,Y)。
例如:
min(2,3) = 2
min(2,10) = 2
min(2,100) = 2
min(2,2.5) = 2
所以 Z = 2 对应的不是原平面中的一个点,而是一大批可能的 (X,Y)。这就是“多对一”的变换,不是一一变换。
因此不能写成:
f_Z(z) = f_XY(?, ?) × 雅可比因子
因为根本没有唯一的 x(z), y(z) 可以代进去。
这里可以用一句话抓住区别:
变量变换公式解决的是“点到点”的密度转移;而 min(X,Y)、max(X,Y) 解决的是“区域事件”的概率累积。
对于 Z = min(X,Y),要求:
F_Z(z) = P(Z ≤ z)
也就是:
P(min(X,Y) ≤ z)
这个事件对应的是二维平面中的一个区域,而不是某一个点。所以应该先算区域概率,再求导得到密度。
更方便的是算对立事件:
P(Z > z) = P(min(X,Y) > z)
而:
min(X,Y) > z
等价于:
X > z 且 Y > z
所以:
P(Z > z) = P(X > z, Y > z)
若 X、Y 独立,则:
P(Z > z) = P(X > z)P(Y > z)
这就是为什么这道题要先转成分布函数或生存函数。
不过要注意一点:这类题也不是完全不能“用密度”。它只是不能用那种简单的“代入密度 + 雅可比”的方法。
比如 Z = min(X,Y),也可以直接从密度角度理解:
Z 在 z 附近取值,意味着两种情况之一:
第一种:X 在 z 附近坏掉,同时 Y > z;
第二种:Y 在 z 附近坏掉,同时 X > z。
所以密度可以写成:
f_Z(z) = f_X(z)P(Y > z) + f_Y(z)P(X > z)
代入指数分布:
f_X(z) = αe^(-αz)
f_Y(z) = βe^(-βz)
P(X > z) = e^(-αz)
P(Y > z) = e^(-βz)
于是:
f_Z(z) = αe^(-αz)e^(-βz) + βe^(-βz)e^(-αz)
整理得:
f_Z(z) = (α + β)e^(-(α+β)z)
这和先求分布函数再求导的结果一样。
但是这个“密度法”本质上仍然是在分析事件,而不是做普通变量替换。
所以两类题的判断标准可以整理成这样:
| 类型 | 典型形式 | 能不能直接用密度变换公式 | 原因 |
|---|---|---|---|
| 一一变量变换 | U=X+Y, V=Y | 可以 | 新旧变量维数相同,能唯一反解 |
| 多对一变量变换 | Z=X+Y | 不能直接代入,但可用卷积 | 二维变一维,给定 Z 不能唯一确定 X,Y |
| 最值变量 | Z=min(X,Y)、T=max(X,Y) | 不能直接代入 | 一个 z 对应一大片区域 |
| 事件型构造 | Z=min(X,Y)、T=max(X,Y) | 优先用分布函数 | 事件关系最清楚 |
考研里可以按这个规则快速判断:
如果题目让求 (U,V) 的联合密度,并且 U,V 都由 X,Y 变来,优先考虑“变量变换 + 雅可比”。
如果题目只定义一个新变量,比如:
Z = X + Y
Z = XY
Z = X/Y
Z = min(X,Y)
Z = max(X,Y)
这时通常不能直接代入密度。要么补一个辅助变量转成二维变换,要么用分布函数法。
其中:
Z = X + Y 常用卷积;
Z = XY、Z = X/Y 常用辅助变量加雅可比;
Z = min(X,Y)、Z = max(X,Y) 常用分布函数。
因此这道系统寿命题和普通密度变换题的本质区别就是:
普通密度变换题是在做“坐标变换”;系统寿命题是在做“事件转化”。
串联系统寿命 min(X,Y),关注的是“至少一个坏了”或“两个都还没坏”。
并联系统寿命 max(X,Y),关注的是“两个都坏了”或“至少一个还没坏”。
所以这类题最稳的入口不是密度公式,而是事件等价关系。
相互独立正态随机变量的线性组合仍服从正态分布

63 题选 A:与 μ 无关,与 σ² 有关。
64 题答案是:
μ = 1/2
这两题本质上都在考同一个知识点:相互独立正态随机变量的线性组合仍服从正态分布,并且均值、方差按线性组合规则计算。
63 题解析
题目条件是:
X, Y 相互独立
X ~ N(μ, σ²)
Y ~ N(μ, σ²)
要求判断:
P{|X - Y| < 1}
是否与 μ、σ² 有关。
因为 X 和 Y 独立,且都是正态分布,所以它们的差仍然服从正态分布。
设:
Z = X - Y
则:
E(Z) = E(X - Y) = E(X) - E(Y) = μ - μ = 0
方差为:
D(Z) = D(X - Y)
= D(X) + D(Y)
= σ² + σ²
= 2σ²
这里之所以是加号,是因为 X 和 Y 相互独立。减法不会让方差相减,方差衡量的是波动程度,线性组合里系数要平方:
D(aX + bY) = a²D(X) + b²D(Y)
所以:
X - Y ~ N(0, 2σ²)
因此:
P{|X - Y| < 1}
= P{|Z| < 1}
这个概率只由 Z 的分布决定,而 Z 的分布是:
N(0, 2σ²)
其中均值已经变成 0,不含 μ;但方差是 2σ²,仍然含 σ²。
所以它 与 μ 无关,与 σ² 有关。
答案:
A
这道题容易错在把 X - Y 的均值和方差混在一起。均值确实相减,导致 μ 抵消;但方差不是相减,而是因为独立而相加。
64 题解析
题目条件是:
X 与 Y 相互独立
X ~ N(μ, 1/2)
Y ~ N(μ, 1/2)
P{X + Y < 1} = 1/2
求 μ。
设:
S = X + Y
因为 X、Y 独立且服从正态分布,所以 S 仍然服从正态分布。
先求均值:
E(S) = E(X + Y) = E(X) + E(Y) = μ + μ = 2μ
再求方差:
D(S) = D(X + Y)
= D(X) + D(Y)
= 1/2 + 1/2
= 1
所以:
X + Y ~ N(2μ, 1)
题目给出:
P{X + Y < 1} = 1/2
正态分布有一个非常重要的性质:正态分布关于它的均值对称。
如果:
S ~ N(a, σ²)
那么:
P{S < a} = 1/2
也就是说,正态分布中,小于均值的概率正好是 1/2。
现在题目说:
P{S < 1} = 1/2
而 S 的均值是:
2μ
所以必须有:
1 = 2μ
因此:
μ = 1/2
答案:
1/2
这道题的关键不是查表,而是抓住正态分布的对称性。看到 P{某个正态变量 < 某个数} = 1/2,第一反应应该是:这个“某个数”就是该正态变量的均值。
相关知识点总结
这两题都属于考研数学概率论里非常常见的题型:正态随机变量线性组合的分布。
如果:
X ~ N(μ₁, σ₁²)
Y ~ N(μ₂, σ₂²)
并且 X、Y 相互独立,那么:
aX + bY ~ N(aμ₁ + bμ₂, a²σ₁² + b²σ₂²)
特别常用的几个形式是:
X + Y ~ N(μ₁ + μ₂, σ₁² + σ₂²)
X - Y ~ N(μ₁ - μ₂, σ₁² + σ₂²)
注意,X - Y 的方差仍然是:
σ₁² + σ₂²
不是:
σ₁² - σ₂²
因为:
D(X - Y) = D(X) + D(-Y)
= D(X) + (-1)²D(Y)
= D(X) + D(Y)
这是这类题最容易出错的地方。
如果 X、Y 不独立,则要多出协方差项:
D(aX + bY)
= a²D(X) + b²D(Y) + 2abCov(X,Y)
例如:
D(X - Y)
= D(X) + D(Y) - 2Cov(X,Y)
所以题目中特意强调“相互独立”,就是为了让协方差为 0,从而直接用方差相加。
正态分布对称性的常见用法
如果:
X ~ N(μ, σ²)
那么正态分布关于 μ 对称,因此:
P{X < μ} = 1/2
P{X > μ} = 1/2
所以如果题目给出:
P{X < a} = 1/2
并且 X 是正态分布,那么通常可以直接得到:
a = μ
64 题正是这个考法。
它不是让我们去查标准正态分布表,而是让我们识别:
X + Y ~ N(2μ, 1)
又因为:
P{X + Y < 1} = 1/2
所以 1 是 X + Y 的均值。
这类题的快速识别方法
遇到下面这些表达,要立刻想到“线性组合正态分布”:
X + Y
X - Y
aX + bY
P{X + Y < c}
P{|X - Y| < c}
解题步骤固定为三步。
第一步,设新变量:
Z = aX + bY
第二步,求新变量的分布:
E(Z) = aE(X) + bE(Y)
D(Z) = a²D(X) + b²D(Y)
如果 X、Y 独立,直接相加;如果不独立,要补协方差项。
第三步,根据题目要求求概率或反求参数。
63 题是判断概率与参数的关系,所以只需要看 X - Y 的分布里还剩哪些参数。
64 题是利用 P{正态变量 < 均值} = 1/2 反求 μ。
相关系数 ρ = 0
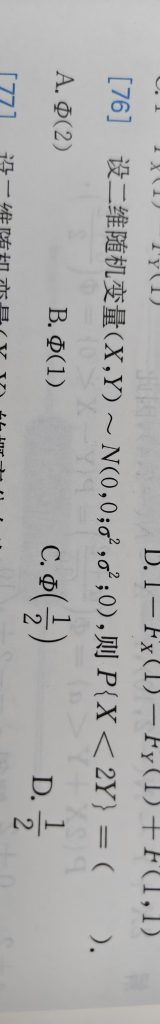
这题选 D:1/2。
题目是:
(X, Y) ~ N(0, 0; σ², σ²; 0)
求 P{X < 2Y}
这里的关键有两个:
第一,(X, Y) 是 二维正态分布,不是一维正态分布。
第二,最后那个 0 表示 相关系数 ρ = 0,不是新的随机变量,也不是第五个“分布参数”之外的东西。
一维正态分布确实通常写成:
X ~ N(μ, σ²)
它只有两个参数:
μ:均值
σ²:方差
但二维正态分布描述的是两个随机变量 X、Y 的联合分布,因此除了分别给出 X 和 Y 的均值、方差之外,还要说明它们之间的相关关系。
二维正态分布常写成:
(X, Y) ~ N(μ₁, μ₂; σ₁², σ₂²; ρ)
其中:
μ₁ = E(X)
μ₂ = E(Y)
σ₁² = D(X)
σ₂² = D(Y)
ρ = X 与 Y 的相关系数
所以题目中的:
(X, Y) ~ N(0, 0; σ², σ²; 0)
意思是:
E(X) = 0
E(Y) = 0
D(X) = σ²
D(Y) = σ²
ρXY = 0
最后一个 0 就是相关系数:
ρXY = 0
它表示 X 和 Y 不相关。而在二维正态分布中,若相关系数为 0,则 X 和 Y 还可以进一步推出 相互独立。
这是二维正态分布里非常重要的结论:
二维正态 + ρ = 0 ⇒ X 与 Y 相互独立
但这道题其实即使不强调独立,也可以直接用协方差为 0 来算。
要求:
P{X < 2Y}
先把不等式移到一边:
X < 2Y
X - 2Y < 0
令:
Z = X - 2Y
因为 X、Y 服从二维正态分布,所以它们的线性组合仍然服从正态分布。也就是说:
Z = X - 2Y
一定还是正态随机变量。
下面求 Z 的均值和方差。
均值:
E(Z) = E(X - 2Y)
= E(X) - 2E(Y)
= 0 - 2 × 0
= 0
方差:
D(Z) = D(X - 2Y)
= D(X) + 4D(Y) - 4Cov(X, Y)
又因为相关系数:
ρXY = 0
而:
Cov(X, Y) = ρXY · σX · σY
所以:
Cov(X, Y) = 0
因此:
D(Z) = σ² + 4σ²
= 5σ²
所以:
Z = X - 2Y ~ N(0, 5σ²)
于是原概率变成:
P{X < 2Y}
= P{X - 2Y < 0}
= P{Z < 0}
而 Z 是均值为 0 的正态分布。正态分布关于均值对称,所以:
P{Z < 0} = 1/2
因此:
P{X < 2Y} = 1/2
选:
D
这道题最容易错的地方在于看到 X < 2Y 后,想把它变成:
P{X < 2Y} = F_X(2Y)
这是不对的。因为 2Y 不是一个常数,而是随机变量。不能直接把随机变量代入 X 的分布函数。
这类题的标准做法是:看到正态变量之间的不等式,优先把它整理成一个线性组合。
例如:
P{X < 2Y}
要转化为:
P{X - 2Y < 0}
然后研究:
Z = X - 2Y
的分布。
只要 (X, Y) 是二维正态,那么 aX + bY 一定是一维正态。接下来只需要求均值和方差,再用正态分布性质即可。
关于二维正态的五个参数,可以这样记:
两个均值 + 两个方差 + 一个相关系数
即:
N(μ₁, μ₂; σ₁², σ₂²; ρ)
其中 ρ 的作用是刻画 X 和 Y 之间的线性相关程度。
如果:
ρ > 0
说明 X 和 Y 正相关。
如果:
ρ < 0
说明 X 和 Y 负相关。
如果:
ρ = 0
说明 X 和 Y 不相关。
对于一般随机变量,“不相关”不一定等于“独立”;但对于二维正态分布来说:
ρ = 0 ⇔ X 与 Y 相互独立
这是考研概率论里很常考的结论。
第79题不选 A,核心原因是:Y = 1/3 对连续型随机变量来说是一个概率为 0 的事件,不能直接套用普通条件概率公式。
普通条件概率公式是:
P(A | B) = P(AB) / P(B)
但这个公式要求:
P(B) > 0
本题中 Y 是连续型随机变量,所以取某一个具体值的概率为 0:
P(Y = 1/3) = 0
同时:
P(X < 1/2, Y = 1/3) = 0
所以 A 选项实际上变成:
0 / 0
这是没有意义的,不能作为条件概率的定义。
这类题考的是“连续型随机变量在给定 Y = y 条件下的条件分布”。虽然 P(Y = 1/3) = 0,但可以通过条件密度来定义:
f<sub>X|Y</sub>(x | y) = f(x,y) / f<sub>Y</sub>(y)
其中:
f<sub>Y</sub>(y) = ∫<sub>-∞</sub><sup>+∞</sup> f(x,y) dx
因此:
P(X < 1/2 | Y = 1/3)
应该写成:
∫<sub>-∞</sub><sup>1/2</sup> f<sub>X|Y</sub>(x | 1/3) dx
所以选 B。
A 选项的错误本质是:把离散型随机变量的思路直接套到了连续型随机变量上。
如果 Y 是离散型随机变量,并且 P(Y = 1/3) > 0,那么 A 是可以用的:
P(X < 1/2 | Y = 1/3) = P(X < 1/2, Y = 1/3) / P(Y = 1/3)
但本题明确说 (X,Y) 是二维连续型随机变量,所以 Y = 1/3 这种“精确取值事件”概率为 0,A 不成立。
顺带看一下 C 为什么也不对。
C 是:
∫<sub>-∞</sub><sup>1/2</sup> f(x,y) dx
如果这里把 y 理解成 1/3,那就是:
∫<sub>-∞</sub><sup>1/2</sup> f(x,1/3) dx
它积分的是联合密度在直线 y = 1/3 上的截面,不是概率。因为二维连续型随机变量求概率必须对一个“面积区域”积分,而不是只沿着一条线积分。
它和正确答案的关系是:
∫<sub>-∞</sub><sup>1/2</sup> f(x,1/3) dx = f<sub>Y</sub>(1/3) · P(X < 1/2 | Y = 1/3)
所以它少除以了一个 f<sub>Y</sub>(1/3)。
这类题的快速判断方法是:
看到连续型随机变量里出现:
P(X < a | Y = b)
不要用:
P(X < a, Y = b) / P(Y = b)
而要立刻想到条件密度:
P(X < a | Y = b) = ∫<sub>-∞</sub><sup>a</sup> f<sub>X|Y</sub>(x | b) dx
其中:
f<sub>X|Y</sub>(x | b) = f(x,b) / f<sub>Y</sub>(b)
这就是本题不选 A,而选 B 的根本原因。



