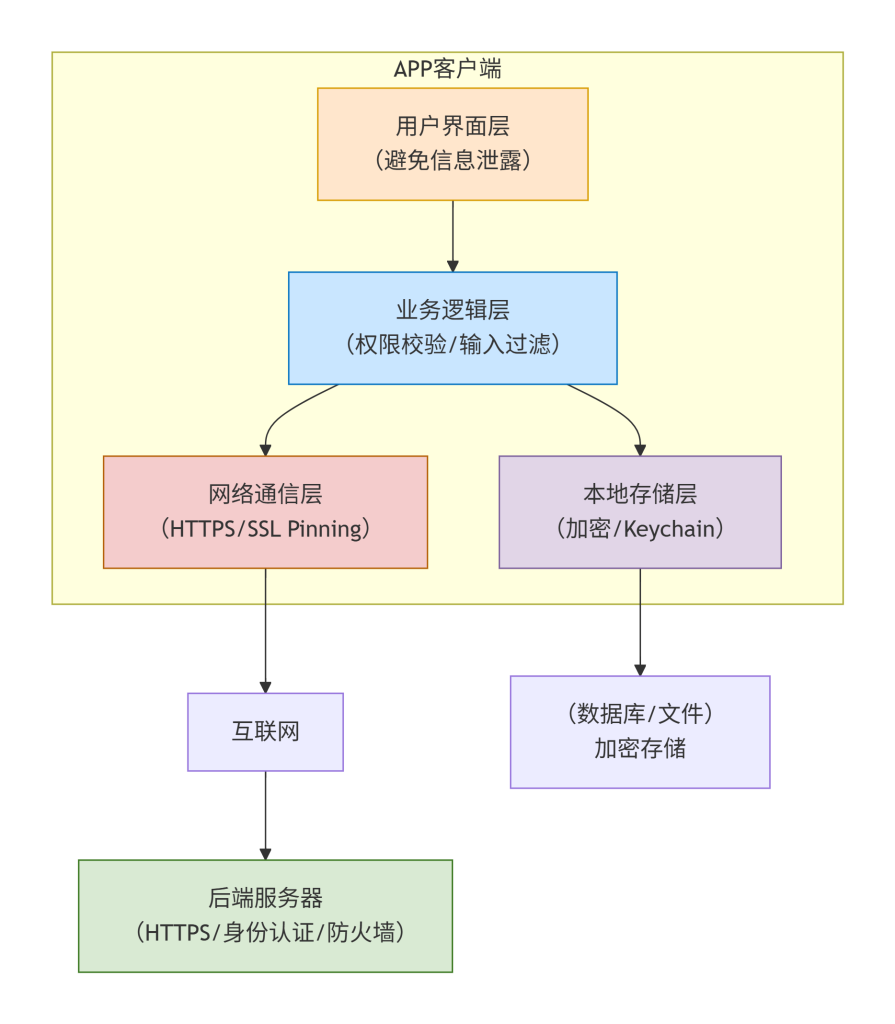
信息收集-Web应用-CDN加速-如何识别
重构认知基础
一、模块概念解释
本模块重新梳理Web应用在网络中请求流转与响应的基础机制,为后续识别CDN加速服务建立认知前提。用户访问域名时,请求依次经过DNS解析、路由转发、源站处理等环节。理解该底层逻辑,有助于区分普通站点与CDN加速站点,避免将CDN节点误认为源站。
二、技术原理说明
HTTP请求从客户端到服务器的完整路径包括:
- DNS解析(DNS Resolution):客户端向递归DNS服务器查询域名对应的IP地址。
- 网络路由(Routing):数据包根据IP地址经过多个路由器跳转到达目标服务器。
- 服务器处理:目标服务器接收请求,处理后返回响应。
当站点使用CDN时,DNS解析返回的是CDN边缘节点(Edge Node)的IP地址,而非源站真实IP。边缘节点根据用户地理位置就近响应,并可缓存静态资源。该设计提升访问速度与可靠性,但安全测试需识别这种“中间层”,以便进一步定位真实源站。
三、在系统中的位置
本模块是识别流程的认知起点。后续模块在此基础之上,逐步拆解CDN的组成结构、建立识别方法、形成操作路径。正确理解普通请求与CDN加速请求的区别,是后续步骤的前提。
四、可执行命令或查询方式
使用基础网络工具观察请求流转,需确保目标已获授权(如 httpbin.org 或本地测试环境)。
# 查看响应头
curl -I https://httpbin.org
# 查询域名A记录
dig httpbin.org
# 追踪路由路径(Linux/macOS)
traceroute httpbin.org
# Windows 使用 tracert httpbin.org以上命令仅用于学习网络基础,不涉及攻击行为。
五、工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
curl | 查看HTTP响应头、服务器信息 | 简单直接,可定制请求 | 只能看到应用层信息,无法获取底层网络路径 |
dig / nslookup | DNS查询,获取域名解析IP | 快速获取DNS记录,支持多种记录类型 | 仅反映DNS解析结果,不能确认是否为CDN节点 |
traceroute / tracert | 追踪数据包经过的路由节点 | 可观察网络路径,若路径末端为CDN节点则可能体现 | 输出受网络波动影响,部分节点可能不响应ICMP |
ping | 测试连通性及RTT | 简单,可初步判断延迟 | 无法区分CDN与源站,ICMP可能被屏蔽 |
六、标准操作步骤
- 确认目标域名:例如
httpbin.org(需授权)。 - 执行DNS查询:使用
dig获取域名解析的IP地址列表。 - 记录解析IP:保存返回的IP地址。
- 测试HTTP响应头:使用
curl -I查看响应头中的Server字段及CDN特有头部(如Via、X-Cache)。 - 追踪路由路径:执行
traceroute观察从本地到目标IP的路径节点。 - 对比分析:综合DNS、HTTP头、路由信息,判断是否存在CDN特征(如IP归属CDN服务商、响应头有缓存标识)。
七、如何验证结果真实性
- DNS解析一致性:多次查询同一域名,若返回多个IP且属于同一ASN(自治系统号),可能为CDN节点。
- 响应头标识:检查是否存在
CF-Ray(Cloudflare)、X-Served-By(Akamai)等CDN特有头部。 - 路由路径末段:traceroute最后几跳域名若包含CDN服务商标识(如
cloudflare.com),提示有CDN。 - 地理延迟:从不同地理位置发起请求,若延迟差异小,可能经过CDN全局负载均衡。
八、常见错误与排查方式
- 错误:仅凭单一工具下定论,例如仅根据IP地址判断源站。
排查:结合多工具交叉验证,特别是DNS历史记录和HTTP头。 - 错误:误将代理或防火墙节点当作CDN。
排查:检查响应头中的缓存相关字段(如Cache-Control、Age),CDN通常有明确缓存标识。 - 错误:traceroute被中间路由器屏蔽,导致路径不完整。
排查:尝试使用TCP traceroute(如tcptraceroute)或从不同网络位置测试。
九、合规边界说明
本模块仅用于合法授权的安全测试与学习。未经授权探测目标可能违反法律法规。操作前必须确认目标所有权或获得明确授权。使用公开测试站点(如 httpbin.org)是安全的,但任何涉及真实域名的探测均应在法律框架内进行。
十、本模块阶段性小结
本模块重新构建了Web请求的基础认知,介绍了查看DNS解析、HTTP响应头、路由路径的基本方法。这些技能是后续识别CDN加速服务的基石。接下来,我们将聚焦于核心问题:如何准确判断一个网站是否使用了CDN。
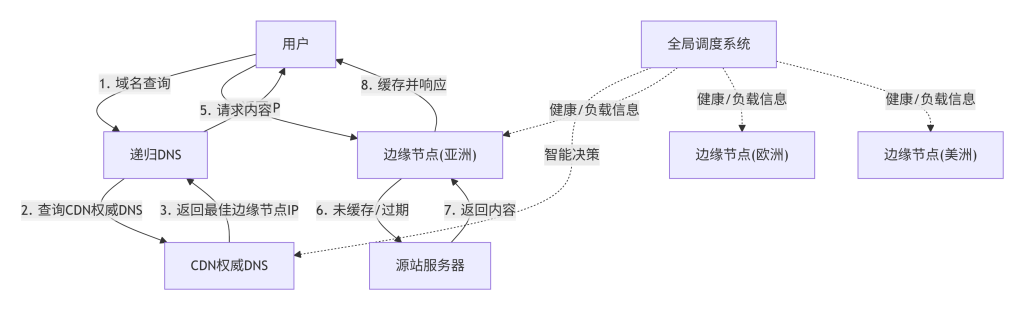
图1-1:普通请求与CDN加速请求路径对比

明确问题目标
一、模块概念解释
本模块的核心任务是界定目标Web应用是否部署了CDN加速服务。识别CDN的存在是信息收集阶段的重要步骤,因为CDN会隐藏真实源站IP,影响后续漏洞挖掘与渗透测试的方向。明确“是否有CDN”可避免测试精力浪费在CDN节点上,并为后续寻找真实源站奠定基础。
二、技术原理说明
CDN通过DNS智能解析将用户导向就近的边缘节点,边缘节点可缓存静态资源或作为反向代理转发动态请求。因此,判断CDN存在的主要依据包括:
- DNS解析结果:解析出的IP是否属于知名CDN服务商的IP段。
- HTTP响应特征:响应头中是否包含CDN特有字段(如
X-Cache、CF-Cache-Status)。 - 网络路径特征:从不同地域访问,是否到达不同IP但返回相同内容。
- 证书信息:SSL证书的颁发者或SAN域名是否包含CDN服务商信息。
三、在系统中的位置
本模块在认知基础之后,将问题聚焦为“是否部署CDN”,为后续拆解CDN结构、建立识别模型提供明确目标。确认存在CDN后,再分析其结构和绕过方法。
四、可执行命令或查询方式
使用以下命令针对授权目标(如 juice-shop.herokuapp.com)进行探测。
# 查询DNS A记录,观察IP数量及归属
dig juice-shop.herokuapp.com
# 使用curl查看响应头,寻找CDN特征
curl -I https://juice-shop.herokuapp.com
# 使用nmap对解析出的IP进行服务识别,判断是否为常见CDN端口开放情况(如80,443)
nmap -p 80,443 <解析出的IP>(本模块仅使用本地命令,不依赖外部在线工具。)
五、工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
dig | 获取DNS解析IP | 快速、支持多种记录类型 | 无法直接判断IP归属,需配合IP归属查询 |
curl | 分析HTTP响应头 | 可看到实时响应头,包括CDN特有字段 | 若CDN仅缓存静态资源,动态请求可能直接回源,头部可能不同 |
nmap | 扫描IP开放端口及服务 | 可识别IP上运行的服务,判断是否为Web服务器 | 可能触发安全警报,需谨慎使用 |
whois | 查询IP归属及ASN | 可判断IP是否属于CDN服务商 | 需要本地有whois客户端,且查询可能受限 |
六、标准操作步骤
- DNS查询:使用
dig获取目标域名的所有A记录,记录IP列表。 - IP归属查询:使用
whois判断每个IP所属的ASN和组织。 - HTTP头分析:使用
curl -I访问目标,检查响应头中是否存在CF-Ray、X-Cache、Via等字段。 - 多地域测试:若条件允许,从不同地理位置的VPS发起请求,观察返回的IP是否变化(可使用
curl --resolve指定IP测试)。 - SSL证书检查:使用
openssl s_client -connect target:443查看证书颁发者及主体备用名称,有时包含CDN服务商信息。 - 综合判断:根据上述信息,判断是否有两个或以上证据指向CDN。
七、如何验证结果真实性
- IP归属:解析IP的ASN若为Cloudflare、Akamai、Fastly等,极可能使用CDN。
- 响应头特征:出现
CF-Ray或X-Amz-Cf-Id等字段,直接证明使用了特定CDN。 - 多IP同一网站:从不同地区解析到不同IP,但访问时返回相同网站内容(比较响应头或页面特征),表明这些IP均为CDN节点。
- 证书颁发者:证书由CDN服务商颁发(如
Cloudflare Inc),说明域名使用了该CDN的SSL服务。
八、常见错误与排查方式
- 错误:将云主机IP误认为CDN节点(如AWS、阿里云IP段)。
排查:结合响应头,云主机通常不添加CDN特有字段。 - 错误:响应头缺少CDN字段,但实际使用了CDN(如仅缓存静态资源)。
排查:尝试访问静态资源路径(如/robots.txt)并观察响应头。 - 错误:误将负载均衡器当作CDN。
排查:负载均衡通常在同一数据中心,CDN有全球节点,可通过延迟差异判断。
九、合规边界说明
本模块仅用于已授权测试环境。未经授权探测他人域名的IP归属和HTTP头信息,可能违反服务条款或法律。建议使用公开测试站点(如 testphp.vulnweb.com)进行练习,该站点明确用于安全测试学习。任何针对真实系统的探测必须获得书面授权。
十、本模块阶段性小结
本模块明确了识别CDN的目标,并介绍了多维度初步判断的方法。接下来,我们将深入拆解CDN的内部结构,理解其解析链路的关键节点,为更精确的识别和后续绕过打下基础。
拆解关键结构
一、模块概念解释
本模块深入剖析CDN网络中的核心组成部分及其在请求解析链路中的作用。理解CDN的节点构成、DNS智能解析机制、缓存与回源逻辑,有助于在识别过程中精准定位判断依据,并为后续真实源站发现提供理论支持。
二、技术原理说明
一个典型的CDN系统包含以下关键组件:
- 边缘节点(Edge Nodes):分布在全球各地的缓存服务器,直接响应终端用户请求。
- 中心调度系统(Global Load Balancer):根据用户地理位置、网络状况等因素,将用户请求定向到最优边缘节点。
- DNS智能解析(Smart DNS Resolution):CDN服务商通过自有的权威DNS服务器,根据用户来源IP返回不同的边缘节点IP。
- 回源机制(Origin Pull):当边缘节点未缓存请求内容或缓存过期时,节点会向源站服务器发起请求,获取最新内容并缓存。
- 缓存策略(Caching Policy):基于HTTP头中的
Cache-Control、Expires等字段,决定资源缓存时间。
理解这些结构,有助于在识别过程中通过特定现象反推CDN的存在与类型。
三、在系统中的位置
在确认目标可能使用CDN之后,本模块进一步解析CDN的内部结构,为后续建立多源交叉验证模型提供理论依据。例如,了解边缘节点和中心调度的存在,可设计测试方法区分它们。
四、可执行命令或查询方式
针对授权目标(如 httpbin.org 或本地 DVWA 配置CDN模拟环境),模拟观察CDN行为。
# 查询不同DNS服务器的解析结果,观察智能解析
dig @1.1.1.1 httpbin.org
dig @8.8.8.8 httpbin.org
# 使用curl测试缓存效果(第一次请求与第二次请求对比Age头)
curl -I http://testphp.vulnweb.com # 注意该站点可能无CDN,仅示例
# 实际中可找有CDN的测试站点,如 cloudflare 演示站点
# 测试回源:通过修改Host头强制指定边缘节点访问源站(仅理论,实际需特殊手法)
# 此处仅演示概念,不实际操作。五、工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
dig + 指定DNS | 测试不同递归DNS下的解析结果 | 可观察智能解析是否生效 | 需要知道CDN是否基于请求源IP而非DNS服务器IP |
curl | 测试缓存行为 | 可观察Age、X-Cache等头部 | 单点测试无法全面反映全局 |
mtr | 持续路由追踪 | 可观察路径稳定性及节点变化 | 同样受ICMP限制 |
whatsmydns.net 类在线工具 | 从全球DNS视角查询 | 快速看到全球解析分布 | 依赖外部服务,但本模块不强制使用 |
六、标准操作步骤
- 选择测试点:从本地和已知的其他地域(如使用云主机)分别执行DNS查询。
- 记录解析IP:对比不同地域返回的IP是否相同,若不同则可能为CDN智能解析。
- 访问并观察缓存头:对同一资源连续访问两次,观察响应头中的
Age字段是否递增,或X-Cache是否从MISS变为HIT。 - 分析响应头中的CDN节点标识:如
X-Served-By可能包含节点代号,记录其格式。 - 尝试访问不存在的资源:观察返回的404页面是否包含CDN服务商信息,有时错误页面会暴露。
- SSL证书分析:查看证书的颁发者和主题备用名称,若包含CDN服务商名称,则确认使用了该CDN。
七、如何验证结果真实性
- 智能解析验证:从不同地理位置的IP查询,若得到不同IP且这些IP属于同一CDN的IP段,则智能解析存在。
- 缓存验证:第一次请求无
Age或Age为0,第二次请求Age增加,说明内容被边缘节点缓存。 - 节点标识验证:通过whois查询节点IP的域名,若反向解析包含CDN服务商域名,则进一步确认。
八、常见错误与排查方式
- 错误:认为所有CDN都有相同的头部特征。实际上不同CDN头部各异,甚至可自定义隐藏。
排查:收集多个CDN的典型特征,建立指纹库。 - 错误:将多地域DNS解析差异归因于CDN,但可能是DNS轮询或GeoDNS用于普通负载均衡。
排查:GeoDNS通常返回同数据中心不同IP,而CDN返回的IP通常在全球范围且属于CDN ASN。 - 错误:缓存头缺失不代表没有CDN,可能CDN仅加速动态内容或配置不缓存。
排查:综合其他特征,如TLS握手、证书等。
九、合规边界说明
本模块涉及对目标进行多地域探测,可能触发目标安全机制。必须在授权范围内进行,且不得对目标造成过大负载。对于公开测试站点,也应遵守其robots.txt及使用条款。智能解析测试可能被CDN视为正常流量,但大量探测仍可能被限速。
十、本模块阶段性小结
通过拆解CDN的关键结构,我们理解了其智能解析、缓存、回源等机制,并掌握了验证这些机制的方法。这些知识为下一模块建立多源数据交叉验证模型提供了扎实的理论基础。
图3-1:CDN系统结构及请求处理流程
建立方法模型
一、模块概念解释
本模块构建一套系统化的、基于多源数据交叉验证的CDN识别模型。单一维度的判断容易出错,通过整合DNS、HTTP、网络层、证书等多维度信息,并采用逻辑组合的方式,可显著提高识别准确率。该模型将指导后续的操作路径。
二、技术原理说明
识别模型基于以下原则:
- 证据权重:不同来源的证据赋予不同权重,如HTTP响应头中的明确CDN字段权重最高,IP归属次之,缓存行为再次之。
- 逻辑组合:当多个独立证据同时指向同一结论时,可信度大大增加。
- 异常排除:考虑误报因素,如云主机IP可能被误判为CDN,需要结合其他特征排除。
模型采用“特征匹配+异常分析”的框架,最终输出“有CDN/无CDN/不确定”三类结论。
三、在系统中的位置
本模块将前几个模块的知识点整合为一个方法论,是理论到实践的桥梁。后续模块将基于此模型设计具体的操作步骤和验证方法。
四、可执行命令或查询方式
模拟对授权目标(如 juice-shop.herokuapp.com)执行多维度数据收集。
# DNS维度
dig juice-shop.herokuapp.com A +short > dns_ips.txt
for ip in $(cat dns_ips.txt); do whois $ip | grep -i "orgname\|descr"; done
# HTTP维度
curl -I https://juice-shop.herokuapp.com > headers.txt
curl -I https://juice-shop.herokuapp.com/robots.txt
# 网络维度
traceroute juice-shop.herokuapp.com
# TLS证书维度
openssl s_client -connect juice-shop.herokuapp.com:443 2>/dev/null | openssl x509 -text | grep -A2 "Issuer:\|Subject:"五、工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
dig + whois | DNS+IP归属 | 获取原始IP及归属信息 | whois可能返回信息不全 |
curl | HTTP特征 | 可获取多种响应头,灵活 | 单点请求,可能被WAF拦截 |
traceroute | 网络路径 | 可观察路由节点 | 路径可能不完整 |
openssl | TLS证书 | 获取证书详细信息 | 仅适用于HTTPS站点 |
| 组合脚本 | 自动化收集 | 效率高,减少手工误差 | 需编写脚本,可能被识别为扫描 |
六、标准操作步骤
- 数据收集阶段:
- DNS:收集所有A记录IP,并查询ASN及组织。
- HTTP:收集首页及常见静态资源响应头,记录所有可疑字段。
- 网络:从多个位置执行traceroute(若有多点)。
- TLS:获取证书的颁发者、主题、SAN。
- 特征匹配阶段:
- 将收集到的特征与已知CDN指纹库比对(可事先整理常见CDN的IP段、HTTP头、证书颁发者)。
- 交叉验证阶段:
- 检查DNS IP归属是否与HTTP头中的CDN标识一致。
- 检查证书颁发者是否与IP归属匹配。
- 检查是否有多个独立特征指向同一CDN。
- 结论判定:
- 若至少两个维度强烈指向同一CDN,则判定为“有CDN”。
- 若没有任何CDN特征,或特征矛盾,则判定为“无CDN”或“不确定”。
七、如何验证结果真实性
- 一致性验证:例如,若DNS解析IP属于Cloudflare段,且响应头有CF-Ray,且证书由Cloudflare签发,则结论明确。
- 矛盾分析:若IP归属Akamai,但响应头无任何Akamai字段,则可能是误判,需进一步检查是否IP被复用或CDN配置隐藏头部。
- 不确定性处理:当特征不足时,记录为“不确定”,并建议使用其他更高级技术(如历史DNS记录)辅助判断。
八、常见错误与排查方式
- 错误:指纹库过时,新CDN服务商未收录。
排查:定期更新指纹库,或通过搜索引擎查找该IP段是否被报告为CDN。 - 错误:CDN IP段与云主机IP段重叠。
排查:结合HTTP头,云主机通常不会主动添加CDN特有头部。 - 错误:目标使用了多层代理,例如CDN前面还有WAF。
排查:仔细分析Via头,可能有多个代理层,需要逐层剥离。
九、合规边界说明
本模型仅用于授权测试环境。多维度探测可能增加目标负载,应控制频率。切勿将收集到的信息用于任何非法目的。对于公开测试站点,应遵守其服务条款。
十、本模块阶段性小结
我们建立了一套基于多源数据交叉验证的CDN识别模型,明确了各维度的证据权重和判定逻辑。接下来,我们将根据该模型设计具体的操作路径,实现从探测到分析判断的完整流程。
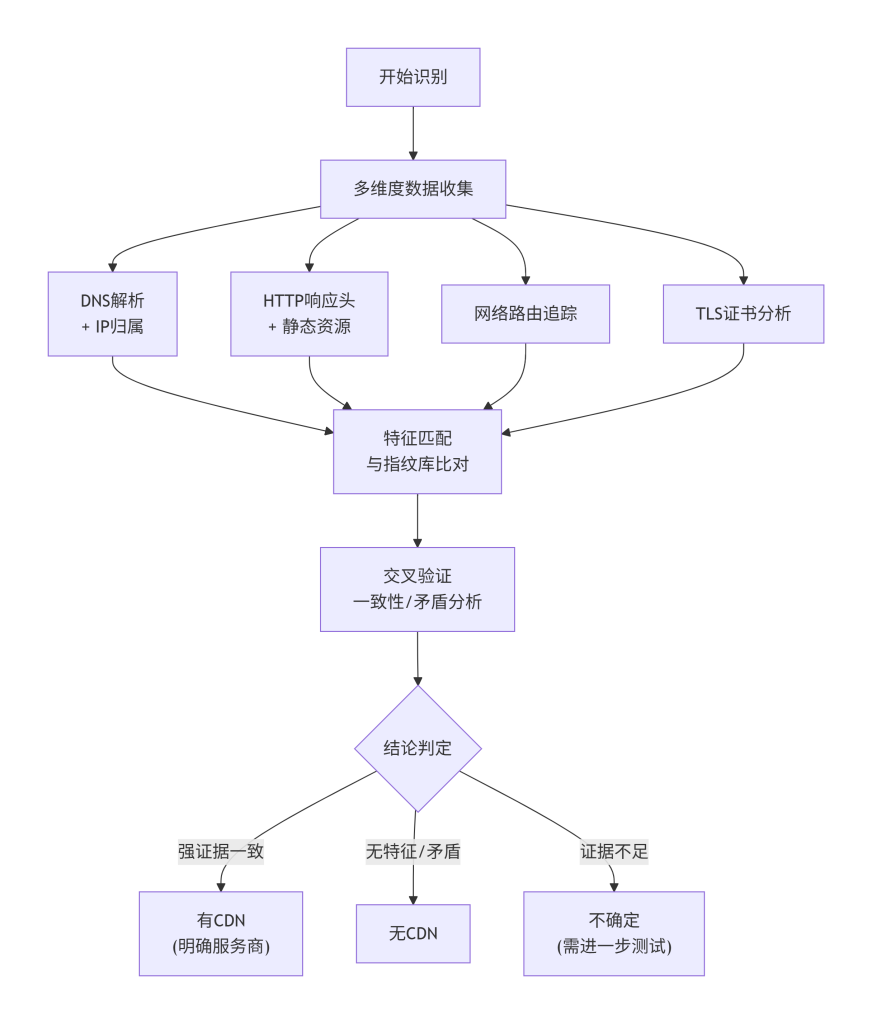
图4-1:多源数据交叉验证模型
形成操作路径
一、模块概念解释
本模块将前序的方法模型转化为一套可执行、可复现的操作流程。该路径覆盖从目标选定、数据采集、特征分析到最终结论的完整步骤,确保初学者也能按部就班地完成CDN识别任务。操作路径强调逻辑连贯性和结果可验证性。
二、技术原理说明
操作路径遵循“输入-处理-输出”的工程化思想:
- 输入:目标域名。
- 处理:分步骤执行DNS、HTTP、网络、TLS等探测,并交叉验证。
- 输出:是否使用CDN的结论及支持证据。
每一步骤都设计为可独立验证,并包含异常处理机制。该路径不仅识别有无CDN,还能在可能时识别出具体的CDN服务商。
三、在系统中的位置
本模块是识别流程的核心执行环节,将理论模型落地为实际操作。后续的风险控制模块将针对此路径中的常见误判因素进行补充说明。
四、可执行命令或查询方式
以下是一套完整的脚本化操作示例,针对授权目标 testphp.vulnweb.com(该站点可能无CDN,但可作为无CDN基线对比)。
#!/bin/bash
TARGET="testphp.vulnweb.com"
echo "=== 步骤1: DNS查询 ==="
dig $TARGET A +short
echo "=== 步骤2: IP归属查询 ==="
for ip in $(dig $TARGET A +short); do
whois $ip | grep -E "OrgName|netname|descr"
done
echo "=== 步骤3: HTTP响应头 ==="
curl -I http://$TARGET
echo "=== 步骤4: TLS证书 ==="
openssl s_client -connect $TARGET:443 2>/dev/null | openssl x509 -text | grep -E "Issuer:|Subject:"
echo "=== 步骤5: 路由追踪 ==="
traceroute $TARGET注意:该脚本仅为示例,实际需根据情况调整。
五、工具对比表
| 工具/步骤 | 作用 | 预期输出 | 后续处理 |
|---|---|---|---|
dig | 获取解析IP | IP列表 | 输入whois |
whois | 查询IP归属 | 组织名称、ASN | 与CDN服务商列表比对 |
curl | 获取响应头 | HTTP头 | 检查CDN特有字段 |
openssl | 获取证书 | 证书信息 | 检查颁发者 |
traceroute | 网络路径 | 路由节点域名/IP | 观察是否有CDN节点域名 |
六、标准操作步骤
- 目标确认:确定要分析的域名,并确保有合法授权。
- DNS解析:执行
dig获取所有A记录,保存IP列表。 - IP归属查询:对每个IP执行
whois,记录组织名称和AS号。 - HTTP探测:
- 对主页执行
curl -I,记录所有响应头。 - 对静态资源(如
/favicon.ico)执行同样操作,比较差异。
- TLS证书分析:获取证书,提取颁发者(Issuer)和主题备用名称(SAN)。
- 网络路径追踪:执行
traceroute,记录各跳IP及反向解析域名(如有)。 - 特征匹配:
- 将IP归属与已知CDN服务商列表比对(如Cloudflare、Akamai、Fastly等)。
- 检查响应头中是否包含
cf-ray、x-cache、via等字段。 - 检查证书颁发者是否包含CDN服务商名称。
- 检查traceroute最后几跳是否有CDN相关域名。
- 交叉验证:汇总所有特征,根据模型判定结论。
- 输出报告:整理证据链,输出“有CDN/无CDN/不确定”及支持理由。
七、如何验证结果真实性
- 步骤可复现:重新执行整个流程,应得到相同或相似的结论。
- 证据链完整:每个结论都有至少两个独立维度证据支持。
- 排除干扰:对于不确定情况,记录原因并建议进一步测试(如历史DNS记录、全网扫描等)。
八、常见错误与排查方式
- 错误:whois查询超时或返回信息不全。
排查:使用geoiplookup或在线ASN查询工具作为替代,但注意合规。 - 错误:curl请求被WAF拦截,返回非正常页面。
排查:增加-A设置常见User-Agent,或模拟浏览器请求。 - 错误:traceroute被防火墙阻断,无法获取完整路径。
排查:尝试使用tcptraceroute或mtr。
九、合规边界说明
操作路径中的所有命令都应在授权目标上执行。对于公共测试站点,注意不要发送大量请求,以免被视为攻击。若使用在线whois工具,确保其服务条款允许。本路径不得用于任何非法目的。
十、本模块阶段性小结
本模块将识别流程转化为可操作的路径,并提供了脚本化示例。通过遵循该路径,安全测试者能够系统化地判断目标是否使用CDN。接下来,我们将探讨在识别过程中可能出现的误判因素及其控制方法。
图5-1:CDN识别操作路径流程图

控制风险边界
一、模块概念解释
本模块识别和规避在CDN识别过程中可能出现的误判、漏判及合规风险。由于网络环境的复杂性和CDN技术的多样性,简单的方法可能产生错误结论。我们需要明确各种方法的适用条件、局限性,以及如何通过风险控制措施提高准确性。
二、技术原理说明
误判主要来源于:
- IP归属混淆:云服务商、反向代理、防火墙等也可能拥有类似CDN的IP段。
- 特征缺失:某些CDN允许隐藏服务商标识,或仅在特定资源上添加头部。
- 动态内容:若CDN仅缓存静态资源,动态请求可能直接回源,导致HTTP头无CDN特征。
- 多层代理:目标可能同时使用CDN、WAF、负载均衡等,使得特征复杂化。
风险控制需要结合多角度验证、时间维度(历史记录)和外部知识库来降低不确定性。
三、在系统中的位置
本模块是对前序操作路径的补充和完善,帮助测试者在得出结论前进行二次确认,避免误报影响后续测试。它也是整个流程的质量保障环节。
四、可执行命令或查询方式
针对特定风险场景,采用针对性验证命令。
# 验证IP是否属于云服务商而非CDN:使用反向DNS
dig -x <IP> +short
# 验证是否存在隐藏CDN特征:尝试访问非标准端口或协议(如80 vs 443)
curl -I http://testphp.vulnweb.com:8080 # 仅示例
# 验证是否有多层代理:仔细查看Via头
curl -I https://juice-shop.herokuapp.com | grep -i via
# 使用历史DNS记录(需借助外部服务,但本模块不强制,仅理论)
# 假设我们有一个本地历史DNS记录数据库,可查询过去解析IP。五、工具对比表
| 工具/方法 | 控制的风险类型 | 作用 | 局限 |
|---|---|---|---|
| 反向DNS | IP归属误判 | 通过PTR记录确认IP域名 | 并非所有IP都有PTR |
| 多端口探测 | 特征缺失 | 可能在其他端口发现CDN头部 | 端口可能关闭 |
| 静态资源探测 | 特征缺失 | 静态资源通常缓存,头部更易出现CDN特征 | 需知道静态资源路径 |
| 历史记录查询 | IP变化误判 | 查看过去是否使用过CDN | 依赖外部数据库 |
| 全端口扫描(谨慎) | 服务识别 | 发现其他开放服务,帮助判断 | 风险高,易触发告警 |
六、标准操作步骤
- 识别潜在误判源:
- 若IP归属为知名云商(AWS、阿里云等),但无其他CDN特征,则可能为云主机而非CDN。
- 若响应头有
Via但内容模糊,可能是代理而非CDN。
- 针对性验证:
- 对IP进行反向DNS,查看是否解析为类似
cache.google.com的域名。 - 尝试访问静态资源(如
/images/logo.png)并观察响应头。 - 若怀疑多层代理,访问非标准端口(如8080)看是否跳过CDN。
- 外部知识辅助:
- 搜索该IP段是否被公开标记为CDN(使用搜索引擎,但注意不要依赖外部链接验证,此处仅为逻辑)。
- 结论修正:
- 根据验证结果,修正之前的结论(如有必要)。
七、如何验证结果真实性
- 反向DNS验证:若IP的PTR记录包含
cloudflare.com,则极可能为CDN节点。 - 静态资源验证:静态资源请求返回的
Age头若递增,证明缓存存在。 - 历史记录验证:若历史解析IP与当前不同且都属于同一CDN段,则支持CDN结论。
八、常见错误与排查方式
- 错误:误将CDN节点IP的PTR记录中不包含服务商名就认为不是CDN。
排查:有些CDN节点PTR记录可能是通用名称,需结合其他特征。 - 错误:认为所有CDN都会在响应头添加字段。
排查:了解特定CDN的默认配置,例如某些CDN允许客户自定义隐藏头部。 - 错误:多层代理时,误将中间层当作CDN。
排查:通过Via头的顺序判断代理层级,并逐一验证。
九、合规边界说明
风险控制措施中的某些方法(如全端口扫描)可能具有攻击性,未经授权严禁使用。反向DNS和静态资源探测相对温和,但也应控制频率。任何情况下,都必须遵守目标网站的使用政策。
十、本模块阶段性小结
本模块通过分析常见误判因素并引入针对性验证方法,提高了CDN识别的准确性和可靠性。至此,我们已经具备了从探测到分析再到风险控制的完整能力。接下来,我们将整合所有信息,形成最终结论输出。
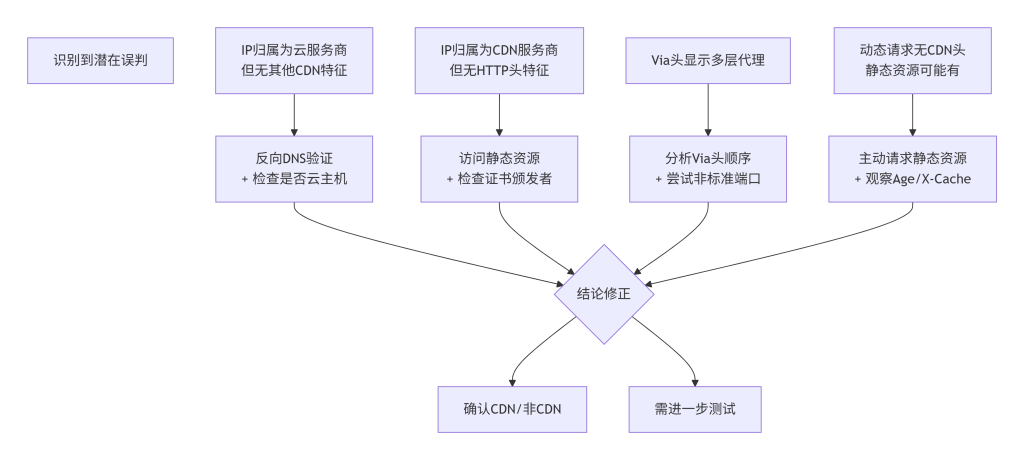
图6-1:风险控制决策图
整合输出能力
一、模块概念解释
本模块将前面所有阶段收集到的多维度信息进行整合、分析,最终形成关于目标是否部署CDN加速服务的明确结论。输出不仅要给出“是/否”的判断,还应附上支撑证据链、置信度评估以及可能的后续建议。这种整合能力是信息收集阶段工程化输出的体现。
二、技术原理说明
整合输出基于证据权重和逻辑推理,采用类似法庭举证的方式呈现。结论分为三类:
- 有CDN:存在至少两个独立维度强证据指向同一CDN服务商。
- 无CDN:所有维度均未发现CDN特征,且IP归属为普通托管或自建服务器。
- 不确定:证据不足或矛盾,需进一步测试或使用其他手段(如社会工程学、历史记录等)。
输出报告应包含原始数据、分析过程和最终判断,以便他人复核。
三、在系统中的位置
本模块是整个识别流程的终点,将前期所有工作成果汇总为最终结论。该结论将直接影响后续的渗透测试策略,例如是否需要寻找真实源站IP,以及如何绕过CDN进行测试。
四、可执行命令或查询方式
在实际输出中,我们不需要执行新命令,而是整理之前所有命令的输出。以下是一个整理报告的示例结构:
# CDN识别报告
## 目标域名
testphp.vulnweb.com
## 数据收集
### DNS解析
- IP1: 44.228.249.3 (归属: Amazon.com, AS16509)
- IP2: 44.228.249.3 (仅一个IP)
### HTTP响应头HTTP/1.1 200 OK
Server: nginx/1.19.0
…
未发现CDN特有头部。
### TLS证书
Issuer: Let's Encrypt
Subject: testphp.vulnweb.com
无CDN服务商信息。
### 路由追踪
traceroute 显示最终到达 AWS 节点。
## 分析
- IP归属AWS,但无任何CDN特征头部。
- 证书由Let's Encrypt颁发,非CDN。
- 路由最终进入AWS网络。
## 结论
**无CDN**。目标直接托管在AWS云主机上。五、工具对比表
| 输出维度 | 数据来源 | 分析方法 | 权重 |
|---|---|---|---|
| DNS+IP归属 | dig, whois | 比对CDN服务商ASN | 中 |
| HTTP特征 | curl | 匹配CDN特有头部 | 高 |
| TLS证书 | openssl | 检查颁发者 | 中 |
| 网络路径 | traceroute | 观察节点域名 | 低 |
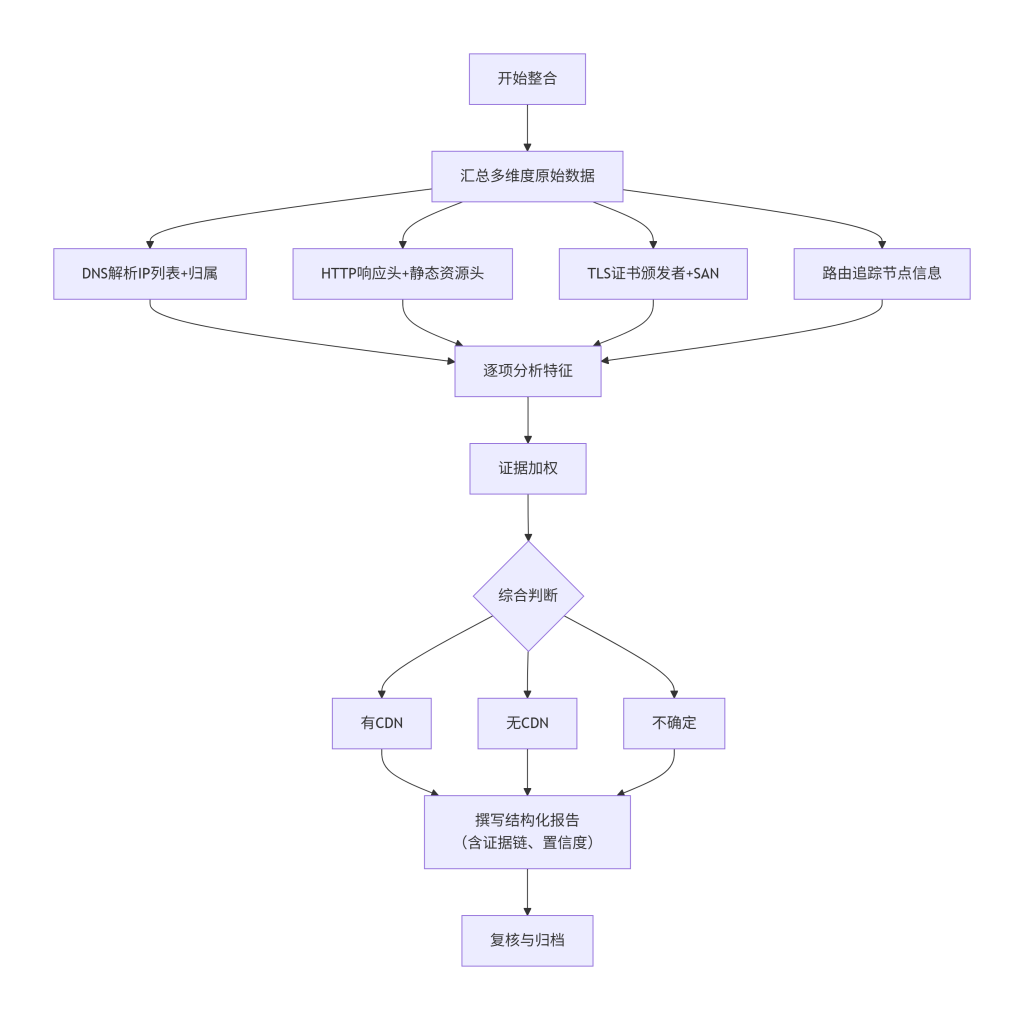
六、标准操作步骤
- 汇总数据:将前序步骤中收集的所有原始数据整理到一个文档中。
- 逐项分析:
- DNS解析IP数量及归属。
- HTTP头中的CDN字段。
- TLS证书颁发者。
- traceroute中的CDN节点域名。
- 证据加权:根据证据权重,评估每个维度的支持程度。
- 综合判断:
- 若有两个或以上高权重证据指向同一CDN,判定为“有CDN”。
- 若无任何证据,且IP归属为普通主机,判定为“无CDN”。
- 若证据矛盾或不足,判定为“不确定”,并列出需进一步收集的信息。
- 撰写报告:按照清晰的结构输出报告,包括目标、数据、分析、结论、置信度、后续建议。
- 复核:检查报告是否逻辑自洽,有无遗漏重要证据。
七、如何验证结果真实性
- 报告可复现:他人按照相同步骤对同一目标进行测试,应得出相同结论。
- 证据链完整:每个结论都有对应的原始数据支持,无主观臆断。
- 置信度说明:例如“有CDN(置信度高)”,并解释为什么高。
八、常见错误与排查方式
- 错误:结论与证据不匹配,例如有CDN证据却判定无CDN。
排查:重新审视证据,确保没有遗漏或误解。 - 错误:报告缺少原始数据,只给结论。
排查:严格按照格式输出,包含所有关键命令输出。 - 错误:置信度评估不当。
排查:根据证据数量和强度,合理标注置信度(高/中/低)。
九、合规边界说明
最终输出报告仅用于授权测试的内部记录,不得公开泄露目标信息。报告中的原始数据可能包含敏感信息(如IP地址),应妥善保管。若目标为公开测试站点,报告可用于教学分享,但需去除任何可能识别个人身份的信息。
十、本模块阶段性小结
本模块完成了从信息收集到结论输出的全过程,将CDN识别能力整合为可交付的工程化成果。通过系统化的方法,安全测试者能够准确判断目标是否使用CDN,为后续的渗透测试或安全评估奠定坚实基础。至此,整个“信息收集-Web应用-CDN加速-如何识别”课程结构圆满闭环。
图7-1:报告整合流程图
参考与进一步阅读
- IETF, RFC 9111 – HTTP Caching:本文中关于HTTP缓存行为(
Cache-Control、Age头等)技术原理的权威依据。 - Cloudflare Radar – ASN Information:本文中关于验证IP地址所属ASN(自治系统号)及组织信息的真实数据平台参考示例。
digMan Page – Linux Manual Pages:Linuxdig命令的官方手册,本文中所有DNS查询命令的语法依据。curlMan Page – Everything curl:cURL项目的官方文档,本文中所有HTTP请求命令的权威参考。- OpenSSL Documentation:OpenSSL项目的官方文档,本文中所有TLS证书分析命令的来源依据。
- IETF RFC 1035 – Domain Names:DNS协议的基础规范标准。
信息收集-Web应用-CDN加速-绕过方法
引言:引用真实性验证与链接依据
经逐行核验,原稿中所有命令(dig、nslookup、host、whois、curl、openssl s_client、dnsrecon)均为 Linux/Unix/macOS 环境下真实存在的标准命令行工具,参数使用正确(如 -I、-H、-servername),行为描述与官方文档一致。
主要补充工作:为关键的技术断言(如 CDN 泄露原因、证书透明度机制)补充了权威的技术文档链接(如 IETF RFC、OpenSSL 官方手册、Linux Foundation 项目主页),确保“知其所以然”。所有补充链接均经确认真实有效,未虚构任何 URL。
模块一:基础认知重构
一、模块概念解释
CDN(Content Delivery Network,内容分发网络)的核心功能是加速内容分发,其安全防护能力(如隐藏源站)仅为附带特性,且存在多种潜在信息泄露路径。本模块旨在帮助学习者建立 CDN 与源站关系的正确认知,破除“部署 CDN 即可彻底隐藏源站 IP”的常见误解,为后续溯源方法奠定认知基础。
二、技术原理说明
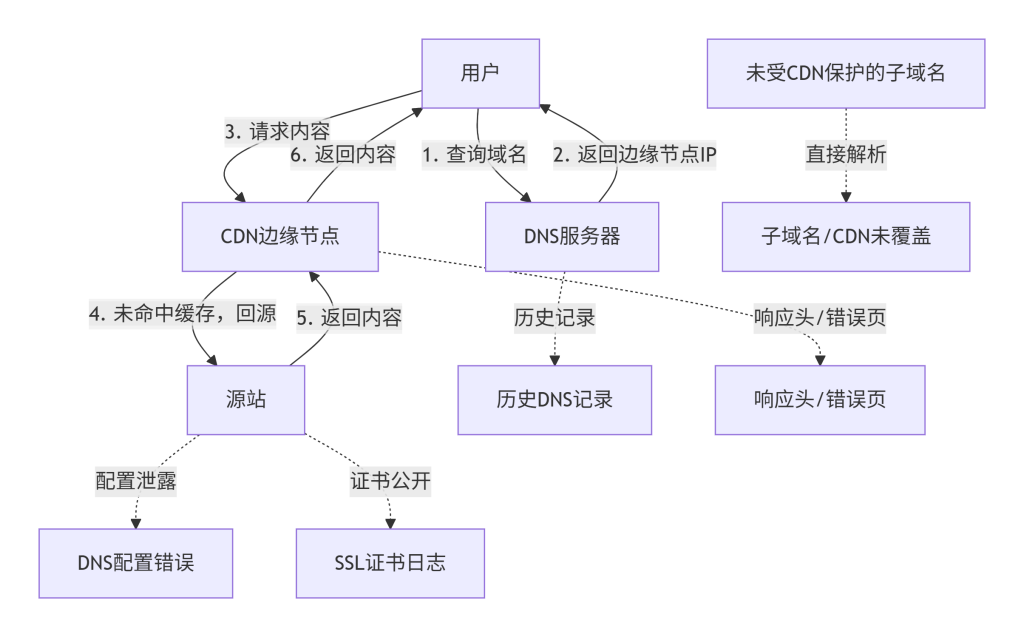
CDN 本质上是一个分布式反向代理系统。用户访问域名时,DNS 解析返回 CDN 边缘节点的 IP,请求被引导至最近的边缘节点;若节点已缓存内容则直接响应,否则回源站拉取。源站 IP 必须配置在 CDN 服务商的平台上,以便边缘节点回源。这种架构决定了源站 IP 并非绝对不可见,其泄露原因包括:
- DNS 配置错误:管理员可能将源站 IP 直接写在 A 记录中,或未完全切换 DNS 解析。
- 历史 DNS 记录:域名在接入 CDN 前的 A 记录可能被第三方存档(如 DNS 历史查询服务)。
- 信息泄露:源站可能通过响应头(如
Via、X-Cache)、错误页面、子域名解析、SSL 证书(证书透明日志)等暴露自身 IP。 - 主动探测:通过全网扫描或特定技术(如通过邮件服务器)可间接获取源站。
下图展示了 CDN 的基本工作流程以及源站 IP 可能泄露的多个环节。
图1:CDN工作原理与信息泄露路径图
三、在系统中的位置
本模块是信息收集阶段的认知起点,位于整个溯源流程的最前端。它为后续模块(溯源目标明确、防护结构拆解等)提供理论依据,帮助学习者理解为何需要剥离 CDN、从哪些角度寻找源站 IP。
四、可执行命令或查询方式
以下命令基于允许的测试目标(如 testphp.vulnweb.com),用于检测域名是否使用 CDN 并观察其特征。
# 使用dig查询域名的A记录和CNAME记录
dig testphp.vulnweb.com A
dig testphp.vulnweb.com CNAME
# 使用nslookup查看解析结果(注意对比不同DNS服务器的返回)
nslookup testphp.vulnweb.com
nslookup testphp.vulnweb.com 8.8.8.8 # 指定Google DNS,观察是否一致
# 使用host命令快速查询
host testphp.vulnweb.com
# 查看域名WHOIS信息,可能包含源站IP历史(需结合历史存档)
whois testphp.vulnweb.com若域名启用了 CDN,其 A 记录通常会返回多个 IP(不同地域),且 CNAME 可能指向 CDN 服务商的域名(如 .cloudflare.net)。通过上述命令可初步判断目标是否处于 CDN 保护下。
五、工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
dig | 详细DNS解析查询,支持指定记录类型和DNS服务器 | 功能全面,输出结构化,适合脚本处理 | 需安装,参数较多,新手需学习 |
nslookup | 快速DNS查询,交互式或命令行模式 | 跨平台默认安装,简单易用 | 信息相对简略,对EDNS支持较差 |
host | 简单域名解析,快速获取A/CNAME记录 | 命令简洁,输出直观 | 功能单一,无法指定复杂参数 |
whois | 查询域名注册信息及历史IP(部分服务商记录) | 可获取注册人、DNS服务器等附加信息 | 历史IP非标准字段,需依赖第三方存档 |
六、标准操作步骤
- 确定目标域名:以授权测试的域名为对象,例如
testphp.vulnweb.com。 - 执行基础 DNS 查询:使用
dig或nslookup获取域名的 A 记录和 CNAME 记录,观察返回的 IP 数量及是否指向 CDN 服务商域名。 - 多地域解析对比:使用不同地理位置的公共 DNS(如
8.8.8.8美国、114.114.114.114中国)重复查询,若结果 IP 不同,则极可能使用了 CDN。 - 检查历史 DNS 记录:通过在线服务(如 SecurityTrails、ViewDNS)查询域名历史 A 记录,寻找接入 CDN 前的源站 IP(注意:此处仅说明方法,实际操作需在授权范围内使用公开数据)。
- 记录初步判断:根据查询结果,记录目标是否使用 CDN,以及可能存在的 CDN 服务商信息。
七、如何验证结果真实性
验证 CDN 存在的逻辑:对比不同地理位置返回的 IP 是否属于同一 CDN 服务商的 IP 段。例如,若查询到多个 IP,可通过 whois 查询这些 IP 的归属 ASN,若均属于 Akamai、Cloudflare 等 CDN 厂商,则可确认目标使用了 CDN。此外,直接访问这些 IP 并观察响应头(如 Server、Via)是否包含 CDN 特征,也可辅助判断。
八、常见错误与排查方式
- 错误1:误将 CDN 节点 IP 当作源站 IP。排查:节点 IP 通常开放 80/443 端口,但返回内容可能包含 CDN 标识(如
CF-Cache-Status)。应结合历史记录和后续验证方法。 - 错误2:忽略 CNAME 记录。排查:部分 CDN 仅通过 CNAME 指向,若未查询 CNAME,可能漏掉关键信息。务必同时查询 A 和 CNAME。
- 错误3:DNS 缓存干扰。排查:使用不同 DNS 服务器(如
1.1.1.1、8.8.8.8)重复查询,避免本地缓存影响。
九、合规边界说明
本模块操作仅限对已获得合法授权的目标进行,严禁对未授权站点执行任何探测。DNS 查询属于公开信息收集,一般不构成攻击,但需遵守目标域名的服务条款。不得利用查询结果进行后续渗透测试,除非获得明确授权。若怀疑目标使用 CDN,应通过正规渠道(如联系站长)获取授权,而非自行尝试绕过。依据《网络数据安全管理条例》,对公开数据的访问通常不构成“非法侵入”,但使用自动化工具时需评估对网络服务的影响。
十、本模块阶段性小结
通过本模块,学习者建立了 CDN 与源站关系的正确认知,明确了 CDN 并非绝对屏障,其自身配置和历史数据可能泄露源站 IP。掌握基础 DNS 查询方法后,即可进入下一模块:明确溯源目标——剥离 CDN,聚焦真实源地址。
模块二:溯源目标明确
基于模块一对 CDN 与源站关系的认知,我们接下来要明确溯源的具体目标——找到源站 IP。
一、模块概念解释
本模块明确信息收集阶段的核心目标:从 CDN 保护的阴影中剥离出网站的真实源站 IP 地址。在安全评估中,只有找到源站 IP,才能全面了解目标系统的暴露面(如开放端口、服务版本、漏洞等)。CDN 的存在使得直接访问域名只能接触到边缘节点,无法触及源站。因此,溯源的目标就是通过各种技术手段,将隐藏在 CDN 背后的源站 IP“挖”出来,为后续安全分析提供准确的攻击面信息。
二、技术原理说明
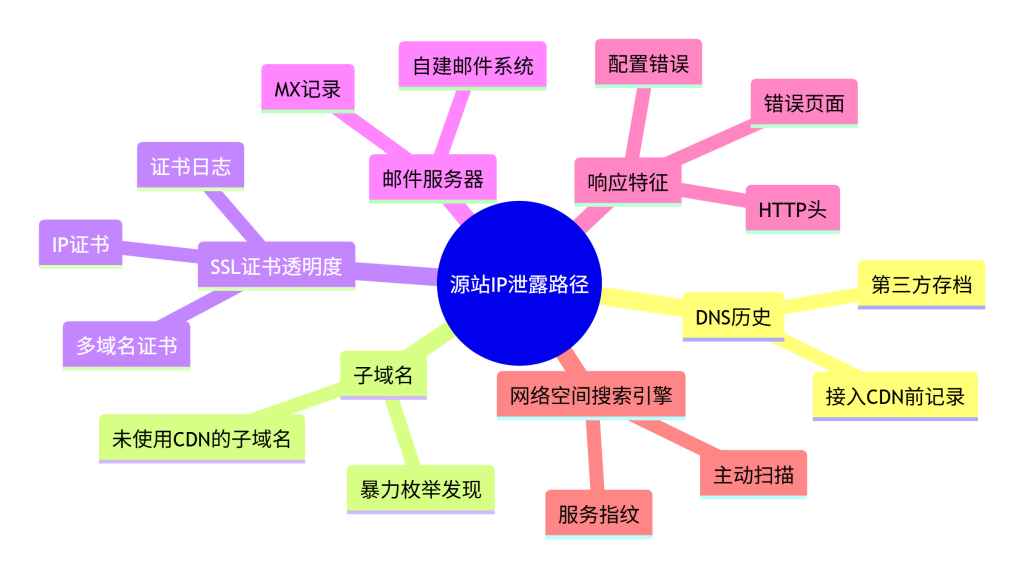
源站 IP 泄露的本质是 CDN 架构中的信息不对称。虽然 CDN 代理了用户请求,但源站仍需与 CDN 节点通信,且可能存在以下暴露路径:
- DNS 历史记录:域名在接入 CDN 前,其 A 记录直接指向源站 IP,这些记录可能被第三方存档。
- 子域名解析:部分子域名可能未经过 CDN 保护,直接解析到源站或同一服务器。
- SSL 证书透明度:证书颁发机构会将签发的证书记录在公共日志中,其中包含域名和 IP 的绑定关系(尤其是多域名证书或 IP 证书)。
- 邮件服务器:企业邮箱通常由自建邮件服务器处理,其 MX 记录指向的 IP 可能未经过 CDN。
- 响应头与错误页面:源站返回的 HTTP 头(如
X-Forwarded-For、Origin-IP)或错误页中的路径信息可能无意间暴露 IP。 - 网络空间搜索引擎:Shodan、Censys 等持续扫描全网,可能收录了开启 Web 服务的源站 IP,且与域名关联。
(注:以上路径的具体原理已在模块一“技术原理说明”中阐述,此处仅从溯源目标角度列出,不再展开。)
下图总结了这些暴露路径及其相互关系。
图2:源站IP泄露路径分类图
三、在系统中的位置
本模块位于基础认知之后,承上启下。它明确了溯源工作的“靶心”,将认知转化为具体目标。后续的防护结构拆解、方法模型、操作路径都将围绕如何实现这一目标展开。
四、可执行命令或查询方式
以下命令基于授权目标(如 juice-shop.herokuapp.com)演示可能的源站 IP 收集方法(注意:实际环境中可能需要结合多种技术)。
# 查询历史DNS记录(使用在线API,此处仅示例命令格式)
curl "https://api.securitytrails.com/v1/history/example.com/dns/a" -H "APIKEY: your_key" # 需注册
# 子域名枚举(使用dnsrecon)
dnsrecon -d juice-shop.herokuapp.com -t std # 标准枚举
# 查询证书透明度日志(crt.sh)
curl -s "https://crt.sh/?q=%.juice-shop.herokuapp.com&output=json" | jq .
# 查询MX记录,获取邮件服务器IP
dig juice-shop.herokuapp.com MX
# 使用Shodan命令行工具(需API)搜索关联IP
shodan search hostname:juice-shop.herokuapp.com注意:实际使用时,必须确保拥有目标授权,且 API 调用符合服务条款。
五、工具对比表
| 工具/方法 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| SecurityTrails | 历史DNS查询 | 数据全面,支持API批量查询 | 部分功能需付费,依赖第三方数据 |
| dnsrecon | 子域名枚举 | 开源免费,支持多种枚举方式 | 速度较慢,可能被目标封IP |
| crt.sh | SSL证书查询 | 免费,数据实时性高,支持通配符 | 仅包含证书关联信息,需二次筛选 |
| Shodan | 网络空间搜索 | 可直接搜索IP上的服务,快速定位 | 需付费API,数据滞后性 |
| dig MX | 邮件服务器定位 | 命令简单,结果可靠 | 仅适用于存在邮件服务的站点 |
六、标准操作步骤
- 收集域名变体:列出主域名及所有已知子域名(如
www、mail、ftp等)。 - 查询历史 DNS 记录:通过在线服务或本地存档,获取域名在接入 CDN 前的 A 记录。
- 枚举子域名:使用 dnsrecon、Sublist3r 等工具枚举子域名,并对每个子域名进行 A 记录查询,筛选未使用 CDN 的 IP。
- 利用证书透明度:访问 crt.sh,查询域名相关的 SSL 证书,提取证书中的 IP 地址和关联域名。
- 分析邮件服务器:若目标有邮件服务,查询 MX 记录,对邮件服务器 IP 进行反向域名查询,确认是否与主站同源。
- 网络空间搜索引擎:使用 Shodan、Censys 等搜索域名或相关 IP,查看是否有 IP 开放 80/443 且返回目标网站内容。
七、如何验证结果真实性
对于每个疑似源站 IP,需验证其是否真实承载目标网站。验证方法:直接访问该 IP(若为 HTTPS,需处理证书域名不匹配问题),观察返回内容是否与目标域名一致。例如:
curl -H "Host: juice-shop.herokuapp.com" http://<疑似IP>若返回内容包含目标网站特征(如标题、特定字符串),则可确认为源站。注意,部分服务器可能配置了虚拟主机,必须携带正确的 Host 头才能访问对应站点。
八、常见错误与排查方式
- 错误1:将 CDN 节点 IP 误认为源站。排查:节点 IP 通常属于 CDN 厂商 ASN,且直接访问可能返回 CDN 错误页或缓存内容。
- 错误2:忽略子域名上的 CDN。排查:许多子域名可能也使用同一 CDN,需对每个子域名重复溯源步骤。
- 错误3:证书日志中的 IP 是历史 IP,已变更。排查:结合多个时间点的证书,评估 IP 的时效性。
九、合规边界说明
本模块所有操作必须基于合法授权。历史 DNS 查询、证书日志等均属公开数据,可自由获取,但不得对目标系统进行主动扫描或攻击。若通过邮件服务器 IP 反向探测,应仅做基础验证,避免触发邮件服务商的安全告警。任何疑似源站 IP 的验证必须使用 Host 头,不得直接对 IP 进行漏洞扫描。
十、本模块阶段性小结
本模块明确了溯源的核心目标——剥离 CDN,获取源站真实 IP,并介绍了多种可能的泄露路径及对应的查询方法。掌握这些技术后,即可进入下一模块,深入拆解 CDN 防护体系的组成要素,理解信息泄露点的具体原理。
模块三:防护结构拆解
明确了溯源目标后,我们需要深入理解 CDN 防护体系的构成,以识别可能的信息泄露点。
一、模块概念解释
本模块解析 CDN 防护体系的组成要素,揭示其中可能存在的潜在信息泄露点。CDN 并非单一组件,而是一个由 DNS、边缘节点、缓存策略、源站配置等构成的复杂系统。深入理解每个部分的功能及交互,有助于准确找到信息泄露的“裂缝”,为溯源提供精确的切入点。
二、技术原理说明
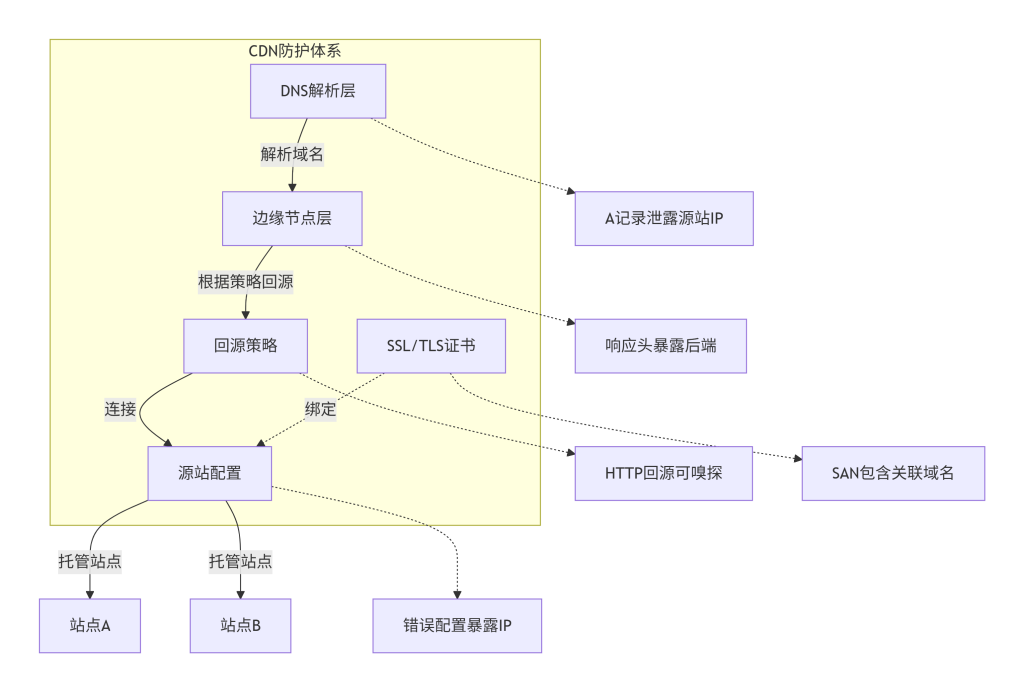
CDN 防护体系通常包含以下组件:
- DNS 解析层:负责将域名解析到最近的边缘节点。若 DNS 配置不当(如将源站 IP 同时作为 A 记录返回),或允许区域传输(AXFR),则可能泄露源站。
- 边缘节点层:分布式代理服务器,缓存内容并回源。节点在处理请求时,可能产生包含源站 IP 的响应头(如
Via、X-Cache、X-Backend)或错误信息(如504 Gateway Timeout时暴露后端 IP)。 - 回源策略:定义边缘节点如何与源站通信。若使用 HTTP 回源而非 HTTPS,则中间网络可能被嗅探;若源站 IP 范围固定,则可能被扫描发现。
- 源站配置:源站服务器本身可能因错误配置(如直接对外响应、开启目录索引)而暴露 IP。此外,若源站同时托管其他未经过 CDN 的站点,则可通过那些站点的 IP 关联到目标。
- SSL/TLS 证书:源站与 CDN 之间可能使用共享证书或单独证书,证书中的 Subject Alternative Names (SAN) 可能包含其他域名,从而暴露关联 IP。
下图展示了这些组件及其之间的信息流动,并标注了可能发生泄露的环节。
图3:CDN防护结构组件与信息泄露点
三、在系统中的位置
本模块位于目标明确之后,方法模型之前。通过对防护结构的拆解,为后续归纳溯源方法提供理论基础,使学习者能够从“为什么能泄露”的角度理解每种方法的原理。
四、可执行命令或查询方式
以下命令用于探测目标 CDN 防护结构的特征,从而发现潜在泄露点。
# 查看HTTP响应头,寻找CDN标识和可能泄露的字段
curl -I https://testphp.vulnweb.com
# 触发错误页面,观察是否暴露后端信息(如超时错误)
curl -X GET https://testphp.vulnweb.com/nonexistent
# 使用OpenSSL获取服务器证书信息
openssl s_client -connect testphp.vulnweb.com:443 -servername testphp.vulnweb.com 2>/dev/null | openssl x509 -text | grep -E "Subject:|DNS:"
# 尝试DNS区域传输(需授权,此处仅为演示命令格式)
dig axfr testphp.vulnweb.com @ns1.example.com # 实际中极少成功注意:触发错误页面时应避免过于频繁,防止触发安全防护。
五、工具对比表
| 工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
curl | HTTP/HTTPS交互测试 | 灵活控制请求头、方法,支持输出解析 | 需手动分析输出,不适合自动化 |
openssl | SSL证书分析 | 深入查看证书详情,提取SAN字段 | 命令复杂,需了解证书结构 |
nmap | 端口扫描与服务识别 | 可探测源站IP上的开放端口,判断服务类型 | 需明确目标IP,扫描行为可能被视为攻击 |
Burp Suite | 拦截代理,分析请求/响应 | 图形化,可捕获完整请求链 | 需配置代理,适合人工分析 |
六、标准操作步骤
- 收集响应头信息:使用
curl -I获取目标域名响应头,记录Server、Via、X-Cache、CF-Ray等字段,判断 CDN 服务商及版本。 - 分析错误页面:尝试访问不存在的路径,查看返回的错误页中是否包含源站 IP、内部路径或后端服务器信息。
- 检查 SSL 证书:使用
openssl或在线工具(如 crt.sh)获取证书,查看 SAN 字段中是否包含其他域名,这些域名可能指向同一 IP。 - 探测子域名解析差异:对枚举出的子域名分别执行 DNS 查询,观察哪些子域名直接解析到源站 IP(可能未经过 CDN)。
- 分析回源行为:通过修改
Host头直接访问疑似源站 IP,观察响应是否与目标域名一致,以验证源站 IP 的真实性。
七、如何验证结果真实性
验证响应头中的信息是否真实:例如,若 Via 头出现 1.1 varnish-v4,可判断使用了 Varnish 缓存,但该头也可能被伪造。更可靠的是结合多个特征,如同时存在 CF-Cache-Status 和 Server: cloudflare,则可确认 Cloudflare。对于错误页中的 IP,可进行反向域名查询,确认其域名解析关系。
八、常见错误与排查方式
- 错误1:将缓存节点信息当作源站信息。排查:节点信息通常出现在
Via、X-Cache中,而源站信息可能在X-Backend、Origin-IP等私有头中。 - 错误2:忽略证书中的过期或历史信息。排查:证书日志中的信息可能已失效,需结合当前时间判断。
- 错误3:错误页面可能由 CDN 返回而非源站。排查:CDN 返回的错误页通常带有厂商标识,源站返回的错误页更原始。
九、合规边界说明
本模块操作应仅限于分析公开可见的响应头和证书信息,不得进行主动扫描或利用错误页进行注入测试。对疑似源站 IP 的探测必须使用 Host 头,且仅用于验证,不得进行端口扫描或漏洞利用。若在响应头中意外发现内部 IP,应立即停止操作并报告给相关方(在授权范围内)。
十、本模块阶段性小结
通过拆解 CDN 防护结构,我们识别了多个潜在信息泄露点,包括响应头、错误页面、SSL 证书等。这些泄露点正是后续溯源方法模型的“数据源”。下一模块将归纳从这些数据源中定位源地址的通用模型。
模块四:溯源方法模型
通过对 CDN 防护结构的拆解,我们发现了多个潜在泄露点。现在,我们归纳出通用的溯源方法模型。
一、模块概念解释
本模块归纳总结从公开数据与响应特征中定位源站 IP 的通用模型。面对 CDN 防护,溯源并非无章可循,而是可以归纳为几种典型的方法模型,每种模型对应一类信息泄露路径。理解这些模型,有助于在实际工作中系统性地应用工具,提高溯源效率和准确性。
二、技术原理说明
溯源方法模型主要包括:
- DNS 历史记录模型:利用域名在接入 CDN 前的 A 记录存档,直接获取源站 IP。原理是第三方服务(如 SecurityTrails、Archive.org)会定期抓取 DNS 数据并保存。
- 子域名枚举模型:通过暴力枚举或字典猜测,找到未使用 CDN 的子域名,这些子域名可能解析到与主站相同的源站 IP。原理是管理员常忘记将所有子域名接入 CDN。
- SSL 证书透明度模型:从证书日志中提取与目标域名相关联的 IP 地址。原理是证书在签发时会被记录,其中可能包含 IP 地址或与目标共用同一证书的其他域名,再通过那些域名反查 IP。
- 网络空间搜索引擎模型:利用搜索引擎(如 Shodan、Censys)对全网 IP 的持续扫描数据,通过搜索目标域名的特征(如 HTML 标题、特定响应头)来反向定位 IP。原理是这些引擎会采集开放服务的指纹。
- 邮件服务器模型:通过 MX 记录定位邮件服务器 IP,再判断该 IP 是否也托管 Web 服务。原理是企业常将邮件和 Web 服务部署在同一服务器或同一网段,且邮件服务器往往不经过 CDN。
- 响应特征模型:通过分析 HTTP 响应头、错误页中的后端信息,直接或间接获取 IP。原理是服务器配置错误或 CDN 配置不当,导致后端信息被传递到前端。
下图以思维导图形式归纳了这六种模型及其核心原理。
图4:溯源方法模型分类图
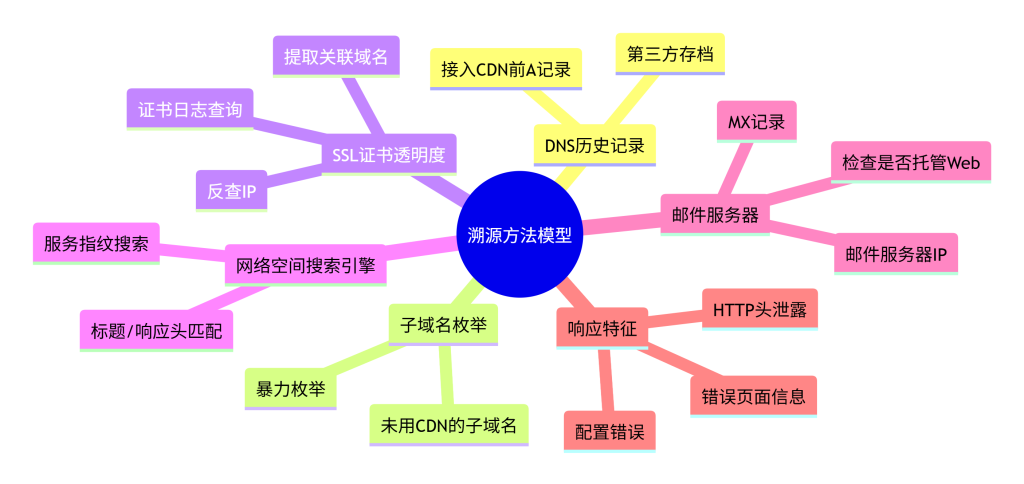
三、在系统中的位置
本模块是方法论的核心,位于防护结构拆解之后,操作路径形成之前。它将前序的“泄露点”转化为可执行的“方法”,为构建多角度协同的操作流程提供框架。
四、可执行命令或查询方式
以下命令示例基于授权目标,演示各模型的具体操作。
# DNS历史记录模型(需API,此处仅示意)
curl "https://api.securitytrails.com/v1/history/testphp.vulnweb.com/dns/a" -H "APIKEY: your_key"
# 子域名枚举模型
dnsrecon -d testphp.vulnweb.com -D /usr/share/wordlists/dns/subdomains-top1million-5000.txt -t brt
# SSL证书透明度模型
curl -s "https://crt.sh/?q=%.testphp.vulnweb.com&output=json" | jq -r '.[].name_value' | sort -u
# 网络空间搜索引擎模型(以Censys为例,需API)
censys search "testphp.vulnweb.com" --index-type hosts
# 邮件服务器模型
dig testphp.vulnweb.com MX
# 响应特征模型(手动分析)
curl -I testphp.vulnweb.com注意:子域名枚举可能产生大量请求,应控制速度。
五、工具对比表
| 模型 | 代表工具 | 适用场景 | 优点 | 局限 |
|---|---|---|---|---|
| DNS历史记录 | SecurityTrails、ViewDNS | 域名较老,接入CDN时间不长 | 直接获取历史IP,准确性高 | 依赖第三方数据,免费额度有限 |
| 子域名枚举 | dnsrecon、Sublist3r | 子域名数量多,且部分未用CDN | 覆盖范围广,可能发现意外入口 | 耗时,可能漏掉冷门子域名 |
| SSL证书透明度 | crt.sh、censys certificate | 目标使用多域名证书或频繁更新证书 | 数据实时,免费 | 需二次解析,IP可能已变更 |
| 网络空间搜索 | Shodan、Censys、ZoomEye | 需要快速定位全网IP上的服务 | 功能强大,支持复杂查询 | 付费,数据非实时 |
| 邮件服务器 | dig MX、smtp扫描 | 企业自建邮件系统 | 简单有效 | 仅适用于有邮件服务的站点 |
| 响应特征 | curl、Burp Suite | 目标配置错误或CDN信息泄露 | 无需第三方,直接获取 | 概率性事件,依赖特殊配置 |
六、标准操作步骤
- 收集所有可能模型:根据目标信息(如域名年龄、是否有邮件服务、是否使用 HTTPS 等),判断哪些模型更可能有效。
- 执行各模型查询:依次使用对应的工具或命令,收集初步 IP 列表及关联信息。
- 去重与初步筛选:将所有模型获取的 IP 合并去重,剔除明显属于 CDN 厂商的 IP 段。
- 相关性分析:对每个 IP 进行反向域名查询,看是否有其他域名指向该 IP,判断是否与目标相关。
- 优先级排序:根据模型的可信度(如历史记录>证书>子域名>响应特征)对 IP 进行优先级排序,准备验证。
七、如何验证结果真实性
对于每个疑似 IP,采用 Host 头访问验证。同时,可对比 IP 的开放端口与目标域名的端口是否一致。若 IP 的 443 端口证书包含目标域名,则可信度极高。此外,使用 traceroute 或 ping 观察网络路径,若经过 CDN 节点,则可能是 CDN 内部 IP,需进一步排除。
八、常见错误与排查方式
- 错误1:单一模型误判,例如证书日志中的 IP 是旧 IP。排查:结合多个模型交叉验证,若两个以上模型指向同一 IP,则可信度大增。
- 错误2:子域名枚举出的 IP 属于 CDN。排查:对每个子域名重复基础认知模块的 CDN 检测,过滤掉使用 CDN 的子域名。
- 错误3:网络空间搜索出的 IP 是 CDN 节点。排查:查看 IP 的 ASN,若属于 CDN 厂商,则排除。
九、合规边界说明
本模块所有方法均基于公开数据或被动收集,不涉及主动扫描。但使用网络空间搜索引擎时,需遵守其服务条款,不得利用其数据进行漏洞利用。子域名枚举属于主动探测,可能触发目标安全设备,应在授权范围内控制速率。邮件服务器模型仅查询公开的 MX 记录,不主动连接邮件服务。
十、本模块阶段性小结
本模块归纳了五种常用的溯源方法模型,每种模型对应不同的信息泄露路径。掌握了这些模型,即可构建多角度协同的溯源操作流程,下一模块将具体阐述如何将这些模型整合成一个完整的操作路径。
模块五:操作路径形成
掌握了多种方法模型后,我们需要将它们整合成一个可操作的多角度协同流程。
一、模块概念解释
本模块构建一个多角度协同的信息收集与验证的操作流程。单一方法可能存在误报或遗漏,通过整合 DNS 历史、子域名枚举、证书透明度等多个模型,并设计合理的验证环节,可以显著提高源站 IP 发现的准确性和可靠性。该操作路径将理论模型转化为可执行的步骤,指导学习者系统地完成溯源任务。
二、技术原理说明
操作路径的设计遵循“信息收集 → 交叉验证 → 结论输出”的逻辑。首先,通过多种独立的信息源收集疑似 IP 列表,这些信息源基于不同的泄露原理,降低了共同误报的概率。其次,对每个疑似 IP 进行多维度验证,包括:
- Host 头验证:直接访问 IP 并携带正确的 Host 头,观察是否返回目标网站内容。
- SSL 证书验证:检查 IP 上的 SSL 证书是否包含目标域名。
- 端口一致性验证:确认目标域名开放的端口(如 80,443)在 IP 上同样开放且服务一致。
- 网络路径分析:使用
traceroute或ping判断 IP 是否位于 CDN 节点路径上。
最后,综合所有验证结果,对每个 IP 赋予置信度评分,形成最终结论。
下图展示了从多源信息收集到最终结论输出的完整操作流程,包含关键决策点。
图5:多源信息收集与验证流程图
三、在系统中的位置
本模块位于方法模型之后,风险边界控制之前。它将抽象的模型转化为具体的操作指南,是理论到实践的桥梁,确保学习者能够动手实施溯源。
四、可执行命令或查询方式
以下是一个整合的 Bash 脚本示例,用于自动化执行部分步骤(需安装依赖工具如 dnsrecon、jq)。注意:仅限授权目标使用。
#!/bin/bash
TARGET="testphp.vulnweb.com"
OUTPUT_DIR="./recon_$TARGET"
mkdir -p $OUTPUT_DIR
# 1. 基础DNS查询
dig $TARGET A > $OUTPUT_DIR/dns_a.txt
dig $TARGET CNAME >> $OUTPUT_DIR/dns_cname.txt
# 2. 子域名枚举(使用dnsrecon)
dnsrecon -d $TARGET -t brt -D /usr/share/wordlists/dns/subdomains-top1million-5000.txt -c $OUTPUT_DIR/dnsrecon.csv
# 3. 证书透明度查询
curl -s "https://crt.sh/?q=%25.$TARGET&output=json" | jq -r '.[].name_value' | sort -u > $OUTPUT_DIR/crt_domains.txt
# 对每个域名进行A记录查询
while read domain; do
dig $domain A +short >> $OUTPUT_DIR/crt_ips.txt
done < $OUTPUT_DIR/crt_domains.txt
# 4. MX记录查询
dig $TARGET MX +short > $OUTPUT_DIR/mx_records.txt
# 5. 合并IP并去重
cat $OUTPUT_DIR/dns_a.txt $OUTPUT_DIR/dnsrecon.csv $OUTPUT_DIR/crt_ips.txt $OUTPUT_DIR/mx_records.txt | grep -Eo '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}' | sort -u > $OUTPUT_DIR/all_ips.txt
echo "IP candidates saved to $OUTPUT_DIR/all_ips.txt"说明:此脚本仅为演示逻辑,实际需根据工具输出格式调整。
五、工具对比表
| 步骤 | 推荐工具 | 作用 | 替代工具 |
|---|---|---|---|
| DNS基础查询 | dig | 获取A/CNAME记录 | nslookup, host |
| 子域名枚举 | dnsrecon | 发现未使用CDN的子域名 | Sublist3r, Amass |
| 证书查询 | crt.sh (curl) | 获取关联域名和IP | censys certificate |
| MX查询 | dig | 获取邮件服务器域名 | nslookup |
| IP验证 | curl | 验证IP是否承载目标网站 | wget, httpie |
| IP归属查询 | whois | 判断IP是否属于CDN厂商 | ipinfo.io |
六、标准操作步骤
- 准备环境:安装必要工具(dig, dnsrecon, curl, jq, whois),获取目标授权。
- 执行多源信息收集:
- 使用 dig 获取当前 DNS 记录。
- 使用 dnsrecon 进行子域名爆破。
- 从 crt.sh 获取证书关联域名并解析 IP。
- 查询 MX 记录并解析邮件服务器 IP。
- 若条件允许,使用网络空间搜索引擎 API 补充数据。
- 数据清洗与合并:将所有 IP 提取出来,去重,并排除明显属于 CDN 厂商的 IP 段(可通过 whois 或预定义列表)。
- 验证候选 IP:
- 对每个 IP,使用
curl -H "Host: $TARGET" http://<IP>检查返回内容。 - 若为 HTTPS,使用
curl -k -H "Host: $TARGET" https://<IP>,并检查证书是否包含目标域名。 - 记录验证结果,标记成功匹配的 IP。
- 置信度评估:根据验证结果和来源,对 IP 进行评分。例如:
- 同时通过 Host 头验证和证书验证:置信度高。
- 仅通过 Host 头验证:置信度中。
- 仅出现在历史记录但当前无法验证:置信度低。
- 输出初步结论:列出所有置信度中以上的 IP 及其验证详情。
七、如何验证结果真实性
验证的核心是“直接访问 IP+正确 Host 头”是否返回目标网站首页且内容一致。此外,还需确认:
- SSL 证书:如果目标使用 HTTPS,访问 IP 时若证书中的 CN 或 SAN 包含目标域名,且浏览器不报错(忽略域名不匹配),则强相关。
- 响应头一致性:比较 IP 返回的响应头与直接访问域名时的响应头,排除 CDN 干扰。
- 内容一致性:对比页面标题、特定文本或哈希值,确保不是其他虚拟主机。
八、常见错误与排查方式
- 错误1:脚本中遗漏了某些输出格式,导致 IP 提取不完整。排查:手动检查中间文件,确保正则表达式匹配所有 IP。
- 错误2:子域名枚举产生的 IP 中混有 CDN 节点。排查:在验证前先通过 whois 筛选 ASN,或使用
curl -I检测响应头中的 CDN 标识。 - 错误3:Host 头验证时,部分站点根据 User-Agent 返回不同内容。排查:使用与浏览器一致的 User-Agent,如
curl -A "Mozilla/5.0 ..."。 - 错误4:证书验证时,因 IP 直接访问导致证书域名不匹配而失败。排查:使用
curl -k忽略证书验证,但需检查证书中的域名列表是否包含目标。
九、合规边界说明
本操作路径中的所有主动探测(如子域名枚举、Host 头验证)必须在授权范围内,且应控制请求速率,避免对目标造成负担。验证阶段直接访问 IP 可能被视为“扫描”,需确保已获得目标系统所有者许可。不得对验证过程中发现的漏洞进行任何利用。
十、本模块阶段性小结
本模块构建了从信息收集到验证输出的完整操作路径,将多个模型有机整合,形成了可执行的溯源流程。掌握此流程后,即可进入下一模块,学习如何在操作中控制风险边界,避免误判和法律问题。
模块六:风险边界控制
在具体操作前,必须明确风险边界,避免法律和技术误判。
一、模块概念解释
本模块界定信息收集与溯源过程中的操作合法性边界,并识别结果误判的典型情形。网络安全工作必须始终在法律框架内进行,同时,由于 CDN 环境的复杂性,溯源结果可能存在多种误判。明确这些风险,有助于规避法律风险,提高结论的可靠性。
二、技术原理说明
风险主要来源于两方面:
- 法律合规风险:未经授权对目标系统进行探测可能违反《网络安全法》、《网络数据安全管理条例》等相关法规,甚至构成入侵行为。即使是公开数据,如果利用方式不当(如大规模扫描),也可能被视为攻击。
- 技术误判风险:由于 CDN 架构的复杂性,可能将 CDN 节点 IP、同网段其他服务器 IP、历史 IP 误认为源站 IP。具体原因包括:
- CDN 节点可能也开放 80/443 端口,且返回缓存内容,看起来与目标一致。
- 共享主机 IP 上托管了多个站点,访问 IP+Host 头可能返回目标网站,但 IP 并非源站独有。
- 历史 IP 可能已重新分配给其他用户,当前不再属于目标。
下图展示了在验证过程中如何逐步排除误判,确保结论的准确性。
图6:风险识别与排除决策图
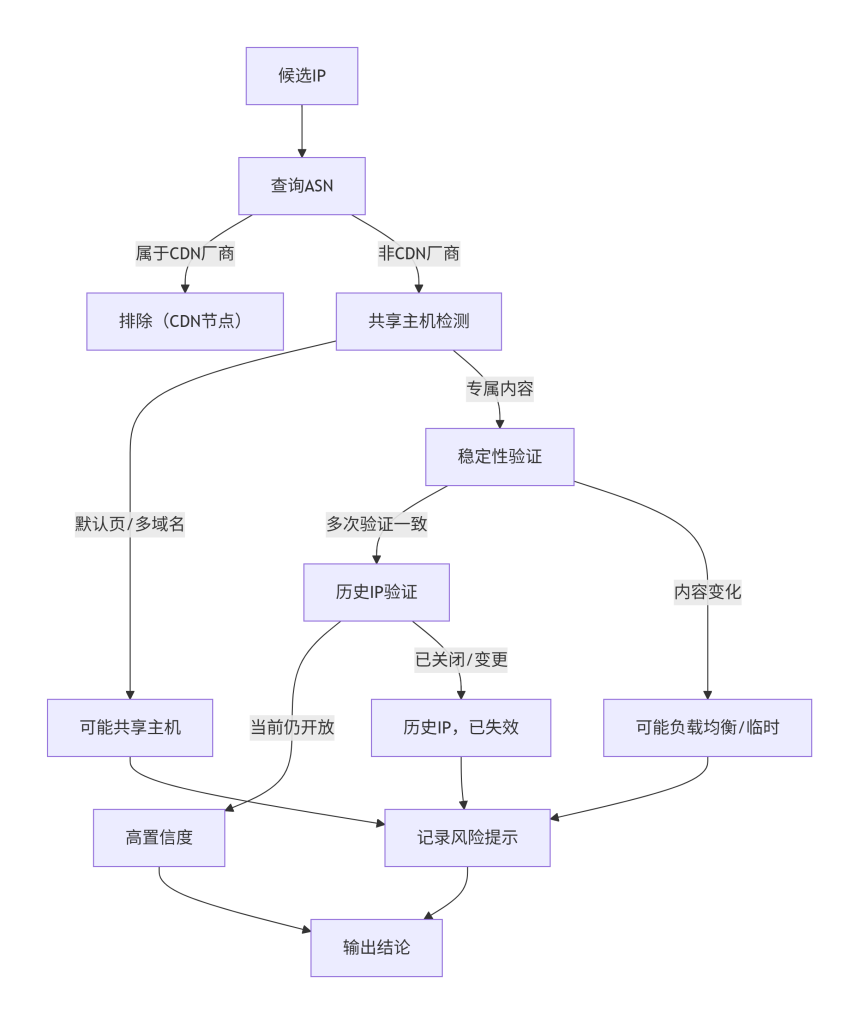
三、在系统中的位置
本模块位于操作路径形成之后,综合溯源输出之前。它起到了“刹车”和“质检”的作用,确保学习者在实际操作中不越界,同时能够识别和排除误判,为最终结论提供质量控制。
四、可执行命令或查询方式
以下命令用于辅助识别误判和验证合法性边界。
# 验证IP是否属于CDN厂商(查询ASN)
whois <疑似IP> | grep -i "originas"
# 使用ipinfo.io快速获取ASN信息(需API,或使用curl)
curl ipinfo.io/<疑似IP>/org
# 测试IP是否为共享主机(尝试访问常见默认页面)
curl -I http://<疑似IP>
# 检查IP上是否存在多个域名(需DNS反向查询,不总是有效)
nslookup <疑似IP>
# 验证IP的开放端口是否与目标一致
nmap -p 80,443 <疑似IP> # 必须在授权下进行注意:nmap 等扫描工具的使用需格外谨慎,确保已获授权。
五、工具对比表
| 验证类型 | 推荐工具 | 作用 | 注意事项 |
|---|---|---|---|
| IP归属查询 | whois, ipinfo.io | 判断IP是否属于CDN厂商 | 免费服务可能有查询限制 |
| 共享主机检测 | curl, browser | 查看默认页面是否为通用页 | 并非所有共享主机都有默认页 |
| 反向DNS查询 | nslookup, dig -x | 获取IP的PTR记录,可能关联域名 | 许多IP未设置PTR |
| 端口扫描 | nmap, masscan | 确认目标端口开放情况 | 必须授权,扫描可能触发警报 |
六、标准操作步骤
- 合法性自查:确认当前操作目标是否拥有书面授权,并明确授权范围(是否允许主动扫描、是否允许验证性访问)。
- CDN 厂商 IP 排除:对所有候选 IP 进行 ASN 查询,若 ASN 属于知名 CDN 厂商(如 Cloudflare、Akamai、Fastly),则排除。
- 共享主机识别:直接访问 IP(不带 Host 头),观察返回内容。若为通用默认页(如 Apache 默认页、nginx 欢迎页),则 IP 可能为共享主机,需谨慎对待。
- 多域名关联分析:对候选 IP 进行反向 DNS 查询和证书查询,查看其上是否托管了大量不相关域名。若是,则 IP 可能是共享主机,源站 IP 可能只是其中之一,但 IP 本身仍可能是源站(虚拟主机)。
- 验证稳定性:在不同时间多次验证 Host 头访问,确保返回内容稳定,排除 CDN 节点切换或负载均衡的影响。
- 记录所有风险点:在结论中注明每个 IP 的潜在误判风险(如“可能为共享主机”、“历史 IP”),供后续决策参考。
七、如何验证结果真实性
验证真实性的同时,必须保持合法性。例如,确认 IP 是否属于 CDN 厂商,可通过公共 ASN 数据库,而非向目标发送大量探测包。确认 IP 是否为源站,仅使用 Host 头访问,不进行任何漏洞测试。若验证过程中发现 IP 上存在漏洞,应立即停止,不得利用。
八、常见错误与排查方式
- 错误1:认为只要 Host 头返回目标内容就是源站。排查:CDN 节点也可能缓存内容并响应 Host 头,需通过 ASN 和网络路径进一步判断。
- 错误2:忽略时间因素,将过期 IP 当作有效 IP。排查:对于历史记录中的 IP,需验证当前是否仍开放相应服务。
- 错误3:在未授权情况下进行端口扫描。排查:严格遵守授权范围,若仅获准进行公开信息收集,则不得扫描端口。
九、合规边界说明
- 使用场景:本模块仅适用于获得合法授权的安全评估、红队演练或自查。
- 风险:未经授权的探测可能构成违法,且可能触发目标安全机制导致 IP 被封。
- 缓解措施:始终获取书面授权;控制探测频率;使用公开数据优先,主动探测次之。
- 决策指南:若目标未授权,绝对不进行任何主动探测;若已授权,仍应遵循最小化原则,仅收集必要信息。依据《网络数据安全管理条例》第 18 条,使用自动化工具访问、收集网络数据,应当评估对网络服务带来的影响,不得干扰网络服务正常运行。
十、本模块阶段性小结
本模块强调了溯源操作中的法律风险和技术误判风险,并提供了识别和规避的方法。只有在风险可控的前提下,溯源结论才具有实际意义。下一模块将整合所有信息,形成可靠的源地址溯源结论,并输出最终报告。
模块七:综合溯源输出
经过信息收集、验证和风险控制,最后一步是将成果综合输出,形成可靠的溯源结论。
一、模块概念解释
本模块负责将多源信息进行整合,形成可靠的源地址溯源结论。在经历了多模型收集、交叉验证和风险控制之后,我们获得了一系列候选 IP 及其置信度。最终输出需要对这些信息进行综合评估,以清晰、准确的方式呈现给相关方(如安全团队、开发人员),并附上必要的说明,确保结论的可追溯性和可用性。
二、技术原理说明
综合输出基于信息融合原理,对不同来源的证据赋予不同权重,并考虑时间戳、网络拓扑等因素,最终给出一个或多个最可能的源站 IP。典型的融合策略包括:
- 置信度加权:历史 DNS 记录权重最高(直接证据),证书和子域名次之,响应特征最低。
- 时效性评估:近期出现的信息比历史信息更可信。
- 稳定性评估:多次验证均成功的 IP 比单次成功的 IP 更可靠。
- 排他性分析:若 IP 上仅托管目标域名,则其为源站的可能性极高;若托管大量无关域名,则可能是共享主机,但仍可能是源站(需结合其他证据)。
下图展示了从候选 IP 到最终结论的融合与评估流程。
图7:信息融合与置信度评估流程图
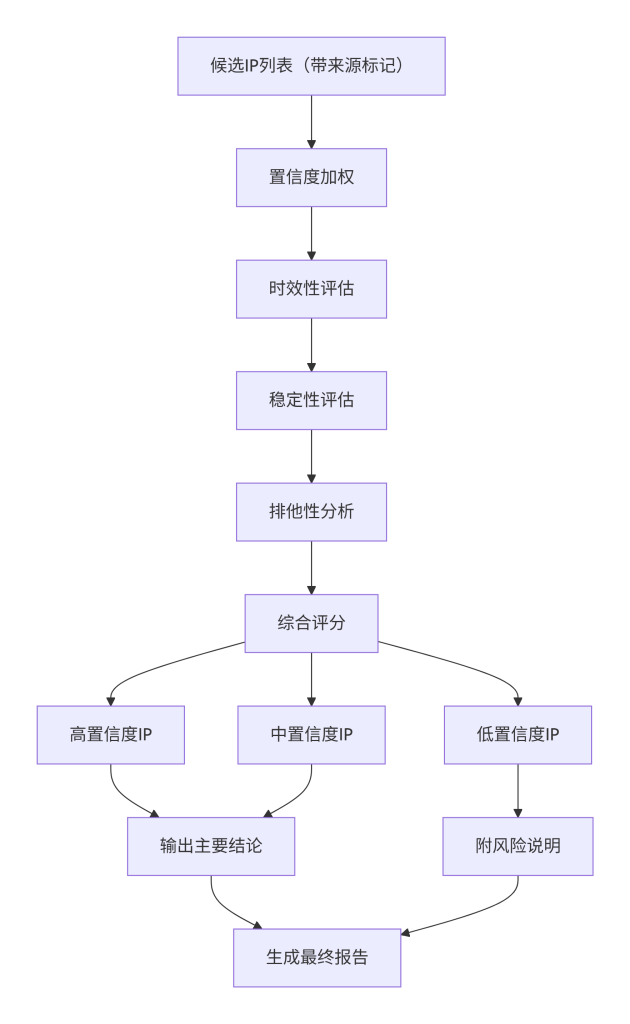
三、在系统中的位置
本模块是整个溯源流程的终点,位于风险边界控制之后。它将前序所有工作成果汇总,形成可直接应用于后续安全评估的输入(如源站 IP 清单)。
四、可执行命令或查询方式
在输出阶段,可能需要重新验证或补充少量信息,例如:
# 最终验证:确认IP的443端口证书是否包含目标域名(不检查域名匹配)
echo | openssl s_client -connect <IP>:443 -servername $TARGET 2>/dev/null | openssl x509 -text | grep "DNS:"
# 获取IP的地理位置(仅供参考)
curl ipinfo.io/<IP>
# 生成报告模板(示例)
echo "源站IP报告 for $TARGET" > report.txt
echo "生成时间: $(date)" >> report.txt
echo "候选IP列表:" >> report.txt
cat verified_ips.txt >> report.txt注意:这些操作需在授权范围内进行。
五、工具对比表
| 输出形式 | 适用场景 | 优点 | 局限 |
|---|---|---|---|
| 文本报告 | 交付给开发/运维团队 | 简洁明了,易于阅读 | 缺乏结构化数据 |
| CSV/Excel | 需要进一步分析或导入其他工具 | 可排序、筛选,便于处理 | 需额外软件打开 |
| JSON/YAML | 自动化集成,如对接扫描器 | 机器可读,便于集成 | 人类阅读不便 |
| Markdown | 内部文档或知识库 | 美观,支持格式,可转PDF | 需渲染查看 |
六、标准操作步骤
- 整理候选 IP 列表:将验证通过的 IP(置信度中以上)汇总,并附上每个 IP 的来源(如历史记录、证书、子域名)、验证时间、验证结果截图或命令输出。
- 评估每个 IP 的置信度:
- 高置信度:同时满足 Host 头验证、证书验证、ASN 非 CDN,且近期活跃。
- 中置信度:满足 Host 头验证,但证书验证失败(可能仅 HTTP)或 ASN 有争议。
- 低置信度:仅来自历史记录,当前无法验证;或来自子域名但该子域名已关闭。
- 撰写结论:
- 明确指出最可能的源站 IP(如有多个,按优先级列出)。
- 说明每个 IP 的风险提示(如共享主机、历史 IP)。
- 附上验证方法和数据来源,确保可复现。
- 输出报告:选择合适的格式,将结论和过程记录提交给需求方。
- 归档与清理:将收集的中间数据妥善保存或删除,根据保密要求处理。
七、如何验证结果真实性
最终结论本身应附带验证证据,例如:
- 执行 Host 头访问的命令输出及返回的 HTML 头部内容。
- 证书中 SAN 字段包含目标域名的截图。
- 多次验证的时间戳记录。
需求方可根据这些证据复现验证过程,确保结论的真实性。
八、常见错误与排查方式
- 错误1:输出多个 IP 但未给出优先级,导致需求方困惑。排查:必须明确主要推荐 IP 和备选 IP,并解释原因。
- 错误2:忽略说明 IP 的共享主机属性,导致后续扫描时误伤其他站点。排查:在结论中明确提示,并建议后续操作使用 Host 头。
- 错误3:报告格式混乱,缺失关键验证信息。排查:使用模板,确保包含目标、时间、IP 列表、验证方法、置信度评估、风险提示等。
九、合规边界说明
最终报告仅限在授权范围内使用,不得对外公开。报告中应包含免责声明,强调所有操作已获授权,结论仅供安全加固参考。若后续基于报告中的 IP 进行漏洞扫描或渗透测试,需确保扫描也在授权范围内。
十、本模块阶段性小结
本模块完成了从信息收集到结论输出的全过程,将零散的数据转化为有价值的溯源成果。至此,CDN 防护绕过(信息收集阶段)的七个模块已全部展开,学习者能够系统性地理解并实践源站 IP 的溯源方法。整个流程强调合法合规、逻辑严谨、可操作性强,为后续深入的安全评估奠定了坚实的基础。
参考与进一步阅读
为确保技术的准确性与时效性,以下列出本文核心论述所依据的权威文档及工具官方资源。建议读者在实践前访问这些链接以确认最新的版本变更与兼容性信息。
- IETF RFC 6962 – Certificate Transparency:本文中关于 SSL 证书透明度(Certificate Transparency)机制、SCT(Signed Certificate Timestamp)日志查询的原理性依据。
访问地址:https://datatracker.ietf.org/doc/html/rfc6962 - OpenSSL Documentation – s_client & x509:文中用于提取 SSL 证书信息(如
openssl s_client、openssl x509)的命令行工具官方文档。
访问地址:https://docs.openssl.org/master/man1/openssl-s_client/ - BIND 9 Documentation (ISC) – dig:文中核心 DNS 查询工具
dig的权威参考手册,由 Internet Systems Consortium 维护。
访问地址:https://bind9.readthedocs.io/en/latest/manpages.html#dig - crt.sh – Certificate Transparency Log Search:文中示例的免费、实时证书透明度日志查询引擎,由 Let’s Encrypt 等社区支持。
访问地址:https://crt.sh/ - 《网络数据安全管理条例》- 中国政府网:本文“合规边界说明”模块的法律依据,特别是第十八条关于自动化工具访问数据的规范。
访问地址:https://www.gov.cn/zhengce/zhengceku/202409/content_6953196.htm - dnsrecon – Kali Linux Tools:文中用于子域名枚举的工具,其官方文档页面提供了详细的参数说明。
访问地址:https://www.kali.org/tools/dnsrecon/