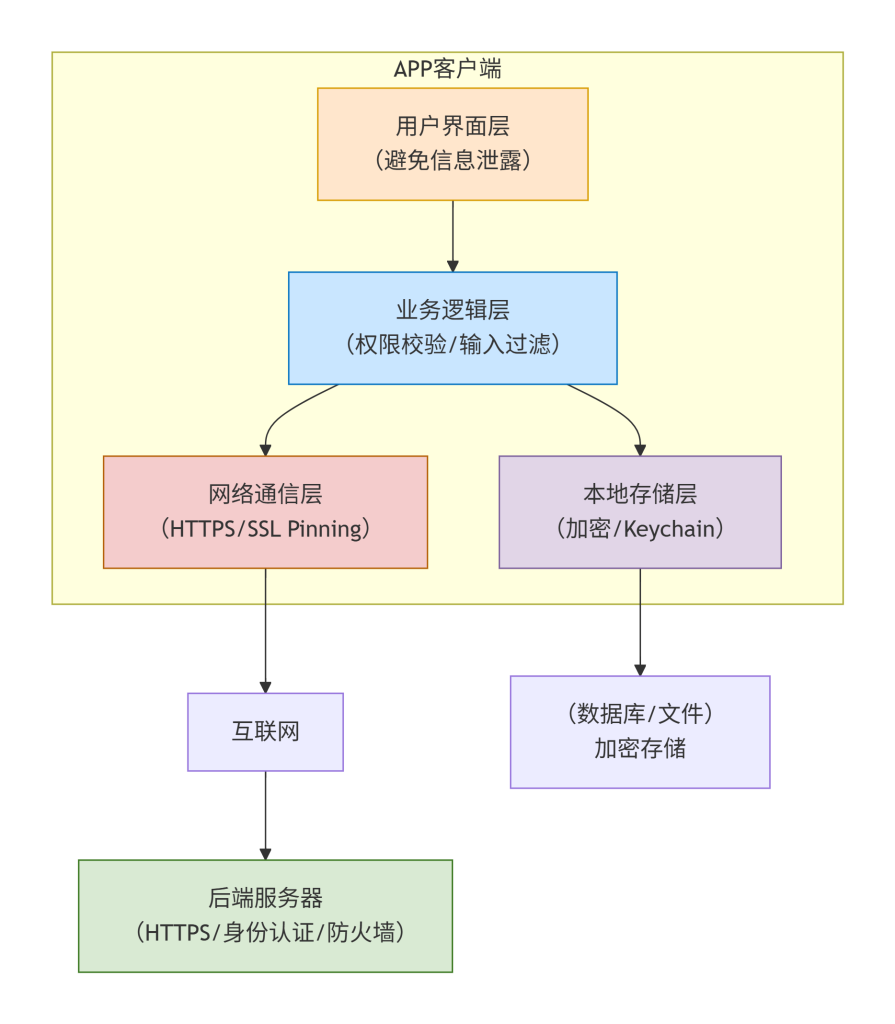
下面这一节我们讲的是:基础入门 · Web 应用 · 蜜罐系统(Honeypot)。
你可以把“蜜罐系统”理解成:专门用来“引诱攻击者”的假系统,用来提前发现威胁、分析攻击行为、保护真实系统的一种安全组件。它不是直接挡攻击的盾牌,而是一个“诱饵 + 监控器 + 取证工具”的组合系统。
首先说清楚一个最核心的问题:蜜罐系统到底解决什么具体问题?
现实生活里有一个很好理解的例子:商场里会放“假包包”“假手机”当诱饵,上面装定位和监控,一旦小偷去偷这个假目标,就会立刻暴露位置和行为路径,从而保护真正值钱的商品。蜜罐系统在网络里的作用就是这个逻辑。在真实业务系统旁边,部署一个“看起来很真实”的假网站、假服务器、假登录页面、假数据库接口,让攻击者误以为这是目标系统。一旦攻击者开始扫描、入侵、爆破、上传木马、注入代码,所有行为都会被完整记录下来。
它解决的不是“挡住攻击”,而是三个现实问题:
第一,提前发现攻击行为,而不是等系统被打挂才知道。
第二,分析攻击手法,知道别人是怎么打你的。
第三,把攻击流量引走,降低真实系统被直接攻击的概率。
接下来讲它在整个系统结构中的位置,以及它和其他模块的协作关系。
蜜罐不是放在用户访问路径上的,而是放在系统外围安全层。典型结构是:
用户正常访问 → CDN → WAF → 真实 Web 服务
攻击流量或扫描行为 → 被引流到蜜罐系统 → 记录 + 分析 + 告警
也就是说,它不是防火墙,也不是 WAF,也不是服务器,而是一个旁路监控系统。
它通常会和这些模块协作:
- CDN:把异常请求转发到蜜罐
- WAF:把疑似攻击请求镜像到蜜罐
- 防火墙:将扫描端口的IP引导到蜜罐地址
- 日志系统:蜜罐数据送入日志平台分析
- 安全运营中心:基于蜜罐告警做响应
蜜罐的定位很清晰:它不是防御主力,而是情报来源和诱捕系统。


这张结构图里可以看到几个关键模块:真实业务服务器在核心区域,外围是 CDN、WAF、防火墙;蜜罐系统通常放在侧边区域,通过流量镜像、策略转发、端口引流接收攻击流量。箭头表示正常用户流量走主链路,而扫描、异常访问、恶意请求被分流到蜜罐,形成独立的攻击分析通道,不影响真实系统运行。
然后说它具体是怎么工作的,用一个简化流程一步一步讲清楚。
流程非常固定:
第一步:部署一个“看起来像真的系统”
比如:
- 一个有登录页面的假后台
- 一个带 API 接口的假服务
- 一个开放 22、80、443 端口的假服务器
- 一个可访问但无真实数据的假数据库接口
第二步:对外暴露访问入口
比如:
- 开放公网 IP
- 绑定域名
- 暴露端口
- 在扫描路径上出现
- 在子域名中出现(如 admin.xxx.com、test.xxx.com)
第三步:攻击者开始探测
- 扫描端口
- 扫描路径
- 测试弱口令
- 尝试注入
- 尝试上传脚本
第四步:蜜罐记录行为
- 记录 IP
- 记录请求路径
- 记录请求参数
- 记录 payload
- 记录攻击工具特征
- 记录会话行为轨迹
第五步:数据送入分析系统
- 进入日志平台
- 进入安全平台
- 生成告警
- 分析攻击模式
- 更新防御策略
整个过程中,攻击者以为自己在攻击真实系统,实际上是在“攻击一个实验室环境”。


这类流程图中,左侧是攻击源,中间是蜜罐服务(Web 蜜罐、SSH 蜜罐、数据库蜜罐等),右侧是日志系统与分析平台。
箭头表示攻击请求进入蜜罐,蜜罐不做真实业务处理,而是专门做行为记录、特征提取和数据转发,最终流入安全分析系统形成告警和策略规则。
接下来讲现实中最常用的实现工具/系统,以及它们的特点。
在真实环境中,蜜罐主要分三类:
第一类:低交互蜜罐(模拟型)
只模拟协议和接口,不提供真实系统功能。
特点:安全、稳定、风险低,但攻击分析深度有限。
代表工具:
Cowrie(SSH/Telnet 蜜罐)
Honeyd(多服务模拟蜜罐)
第二类:高交互蜜罐(真实型)
是真实系统环境,只是业务是假的。
特点:数据价值高,但安全隔离要求极高。
通常用虚拟机 + 容器隔离部署。
第三类:一体化平台型蜜罐系统
集成部署、日志、可视化、告警、分析。
代表系统:
T-Pot(多蜜罐组合平台,基于 Docker)
Modern Honey Network(集中管理平台)
现实中企业最常用的是:低交互蜜罐 + 平台型系统组合,因为风险低、部署简单、数据够用。
给你一个最典型的真实应用场景:
场景:一个电商网站部署管理后台
结构是:
www.xxx.com(真实网站)
admin.xxx.com(真实后台)
安全团队会额外部署:
test-admin.xxx.com(蜜罐后台)
api-test.xxx.com(蜜罐接口)
这些蜜罐地址不对外宣传,只会被扫描工具、攻击脚本发现。
一旦有人访问这些地址,就基本可以判定为异常行为,直接记录分析。
下面给你一个最简可落地的蜜罐配置示例(以 Cowrie SSH 蜜罐为例,新手能直接理解原理):
[ssh]
enabled = true
listen_endpoints = tcp:2222:interface=0.0.0.0
[honeypot]
hostname = server01
fake_addr = 192.168.1.100
[output_jsonlog]
enabled = true
logfile = cowrie.json逐行解释:
[ssh]
表示启用 SSH 蜜罐服务模块。
enabled = true
开启 SSH 蜜罐监听。
listen_endpoints = tcp:2222:interface=0.0.0.0
在 2222 端口监听所有网卡请求(模拟 22 端口服务)。
[honeypot]
蜜罐基础配置区域。
hostname = server01
对外显示的主机名,模拟真实服务器名称。
fake_addr = 192.168.1.100
对外伪装的服务器地址。
[output_jsonlog]
日志输出模块。
enabled = true
开启日志记录。
logfile = cowrie.json
所有攻击行为记录成 JSON 文件,方便分析。
实际部署时,外部扫描者访问你的 22 端口,会被转发到 2222,进入这个蜜罐环境。
再举一个真实可落地的 Web 蜜罐场景:
部署一个假登录系统:
server {
listen 80;
server_name admin-test.xxx.com;
location / {
root /var/www/honeypot;
index login.html;
access_log /var/log/nginx/honeypot.log;
}
}
逐行解释:
listen 80;
监听 80 端口。
server_name admin-test.xxx.com;
绑定一个“看起来很真实”的后台域名。
root /var/www/honeypot;
假网站目录。
index login.html;
显示假登录页面。
access_log /var/log/nginx/honeypot.log;
记录所有访问日志,作为攻击数据来源。
这个“后台”没有任何真实功能,只负责记录所有输入行为。
最后说最容易踩的坑和正确做法:
第一个坑:蜜罐和真实系统在同一网络环境
这是非常危险的,一旦蜜罐被攻破,可能横向攻击真实系统。
正确做法:
物理隔离 / VLAN 隔离 / 容器网络隔离 / 虚拟机隔离。
第二个坑:蜜罐对外暴露真实数据
比如连真实数据库、真实接口。
正确做法:
蜜罐系统永远只允许假数据、假接口、假服务。
第三个坑:部署后不分析数据
只记录日志不处理,等于白搭。
正确做法:
接入日志系统、告警系统、规则引擎,形成安全闭环。
第四个坑:把蜜罐当防火墙用
蜜罐不是防御工具,是情报工具。
正确认知是:
WAF 防护 + 防火墙阻断 + 蜜罐诱捕 + 日志分析 = 完整安全体系。
自然过渡到系统协作关系上来说:
蜜罐系统真正的价值,不在“单独存在”,而在于它和WAF、防火墙、日志系统、态势感知平台形成联动。
攻击行为 → 蜜罐捕获 → 行为分析 → 生成规则 → 更新 WAF 策略 → 阻断真实攻击
这就形成了一个完整闭环:
发现威胁 → 理解威胁 → 反制威胁 → 优化防护体系
这也是为什么在真实企业架构中,蜜罐永远属于“安全感知层”,而不是业务层组件。
基础入门-Web应用-堡垒机运维
一、它在整个系统中解决什么问题?(用生活化例子理解)
在真实工作环境里,服务器从来不是“一个人用”的,而是很多人一起用:运维人员、开发人员、安全人员、外包工程师、临时支持人员都会登录服务器操作。如果所有人都直接用账号密码连服务器,就会出现三个致命问题:第一是账号乱,密码到处传,谁登过根本查不清;第二是权限乱,新人和管理员权限一样,一旦误操作直接删库;第三是责任不清,出问题了不知道是谁干的。
堡垒机做的事情,本质上就是在“人”和“服务器”之间加一个统一入口。所有人只能先登录堡垒机,再由堡垒机代替你去连接服务器。就像小区门禁系统一样:不是每家每户都直接给你钥匙,而是先刷门禁,系统记录你是谁、几点进来、去了哪栋楼、干了什么。
所以堡垒机运维解决的是三个现实问题:统一入口、权限控制、操作审计。
二、它在系统结构中的位置?与其他模块如何协作?
在 Web 系统架构中,用户访问 Web 应用是通过浏览器访问网站;运维人员访问服务器,是通过终端工具访问系统。堡垒机的位置就在运维人员终端和服务器集群之间,它不处理业务流量,只处理“运维连接流量”。
数据结构上是这样的逻辑链路:运维人员电脑 → 堡垒机 → Web服务器 / 数据库服务器 / 中间件服务器,也就是说,堡垒机不替代服务器、不替代网络、不替代防火墙,它只是一个“运维入口控制层”。
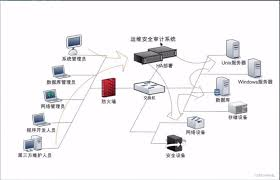
这类图中通常可以看到:左边是运维人员电脑,中间是一台或一组堡垒机节点,右边是多台业务服务器。所有箭头都必须先进入堡垒机,再由堡垒机转发到目标服务器。颜色区分一般是:灰色表示外部终端流量,蓝色表示堡垒机内部控制流量,绿色表示到业务服务器的访问流量,清晰表达“统一入口”的结构关系。
三、它具体是怎么工作的?以及为什么要这样设计?
工作流程其实很固定:
- 第一步,人登录堡垒机。不是登录服务器,而是先登录堡垒机系统本身(Web界面或终端界面)。
- 第二步,堡垒机做身份认证。校验你是谁,是运维A、开发B、实习生C,属于哪个组。
- 第三步,堡垒机做权限匹配。比如运维A可以进生产服务器,开发B只能进测试服务器,实习生只能看日志不能执行命令。
- 第四步,堡垒机代替你连接服务器。你不是直接连服务器,而是堡垒机用“内部凭证”连接服务器。
- 第五步,堡垒机实时记录全过程。包括:登录时间、操作命令、执行路径、文件传输内容、会话录像。
这样设计有几个非常现实的工程原因:
第一,隔离真实服务器账号密码。
服务器真实账号只存在堡垒机中,人永远接触不到,避免泄露扩散。
第二,集中控制权限模型。
权限只在堡垒机配置,不在每台服务器分散配置,减少管理复杂度。
第三,强制审计能力。
所有操作流量经过堡垒机,天然可记录,不靠人工。
第四,安全边界清晰。
服务器只允许堡垒机IP访问,其他IP一律拒绝,物理隔离运维入口。
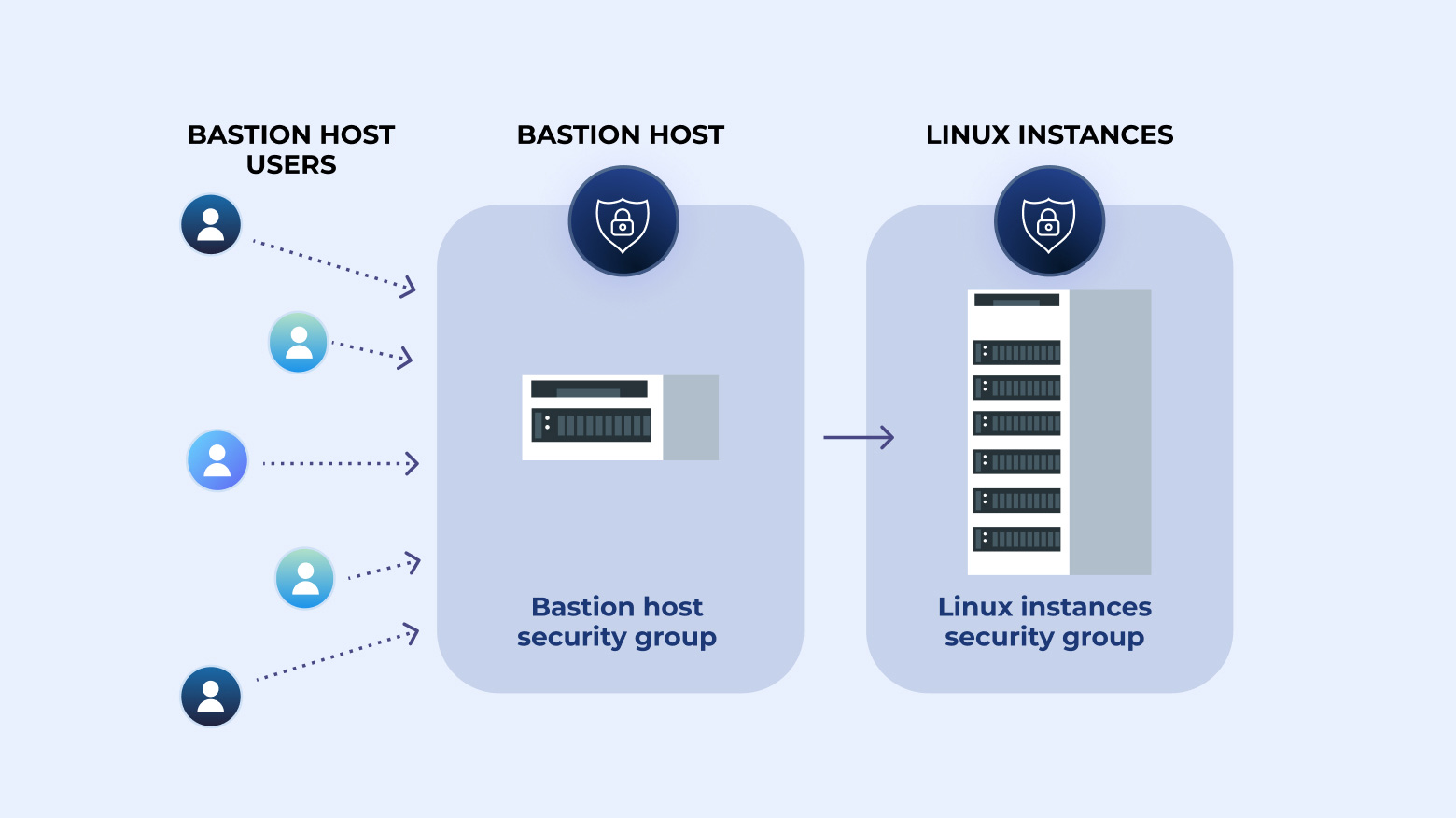
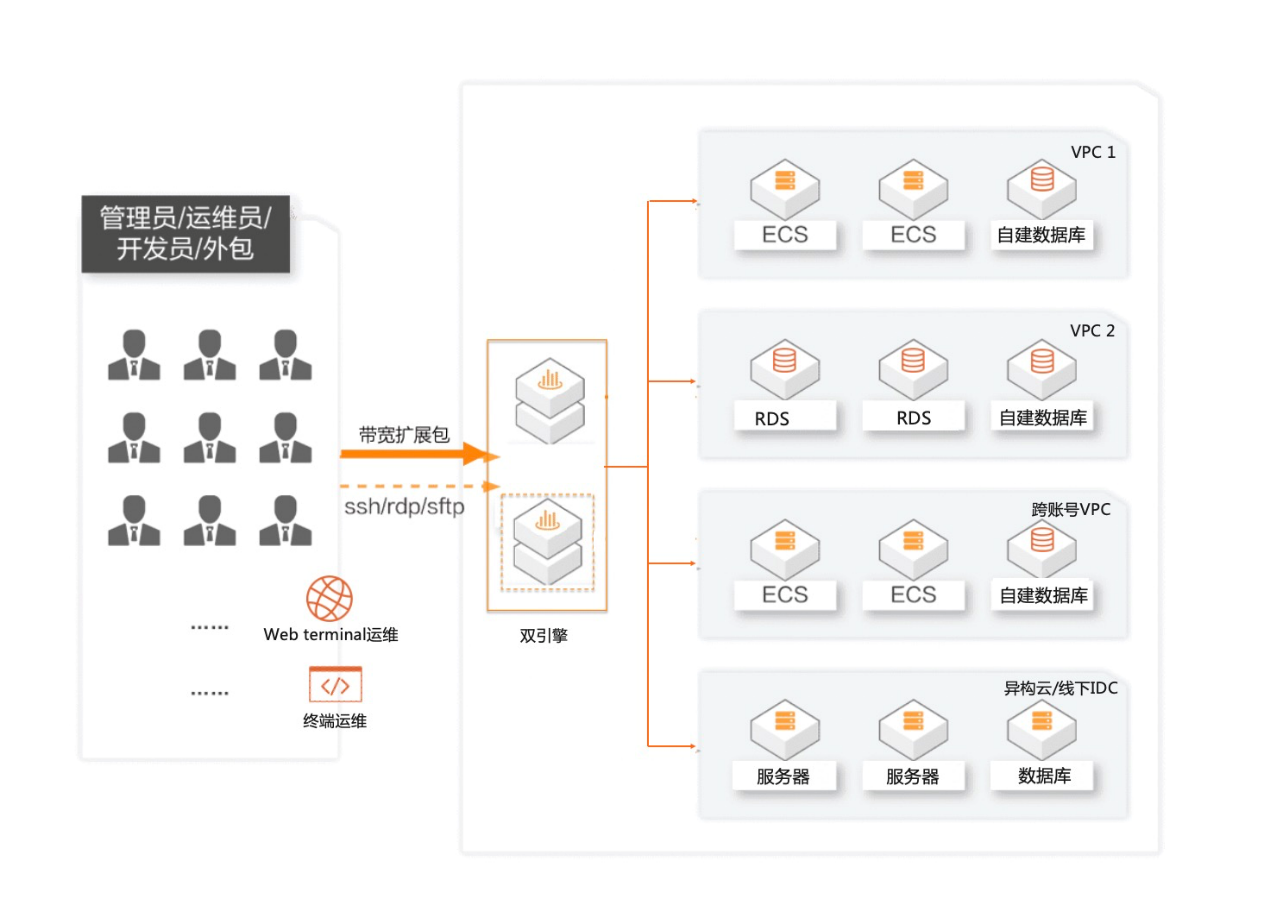
这类流程图中通常会画出:用户终端 → 登录认证模块 → 权限控制模块 → 会话代理模块 → 目标服务器。箭头是单向顺序流动,每一层代表一个控制点,体现“层层校验 + 代理访问 + 审计记录”的设计逻辑。
四、实际中常用的实现工具/软件有哪些?各有什么特点?
在真实工程中,堡垒机分为三类:第一类是商用堡垒机:如云厂商堡垒机、安全厂商堡垒机。
特点是界面完整、审计强、合规能力强,但成本高、依赖厂商。第二类是开源堡垒机系统:如 JumpServer、Teleport、OpenSSH + 审计系统组合。特点是免费、可控性强、适合学习与中小系统,但需要自己运维。第三类是轻量级替代方案:SSH跳板机 + 日志审计。特点是简单、成本低,但审计能力弱,不适合生产级合规要求。对于新手学习和搭建实训环境,最典型的是:JumpServer + Linux服务器 这一组合,结构清晰、概念完整、真实可用。
五、典型真实场景 + 可直接复制的配置示例(逐行解释)
场景:
一个小型 Web 系统,有 3 台服务器:Web服务器、数据库服务器、日志服务器。
要求:所有运维人员必须通过堡垒机访问,不允许直连。
简化版 SSH 跳板堡垒机示例配置(教学级理解模型):
服务器防火墙配置(只允许堡垒机访问):
# 只允许堡垒机IP访问22端口
iptables -A INPUT -p tcp -s 10.0.0.10 --dport 22 -j ACCEPT
iptables -A INPUT -p tcp --dport 22 -j DROP
逐行解释:
第一行表示:允许来源IP为堡垒机IP的SSH连接。
第二行表示:拒绝所有其他IP的SSH连接。
效果是:服务器只能被堡垒机访问。
堡垒机 SSH 转发配置示例:
# 堡垒机本地连接服务器
ssh user@10.0.0.21 # Web服务器
ssh user@10.0.0.22 # 数据库服务器
ssh user@10.0.0.23 # 日志服务器
逻辑解释:
运维人员只登录堡垒机,真正的服务器连接行为由堡垒机完成。
JumpServer结构逻辑配置(概念层级):
用户 → 用户组 → 权限策略 → 资产(服务器) → 账号 → 协议(SSH/RDP)
含义是:
人不直接绑定服务器,而是通过权限策略间接控制访问能力。

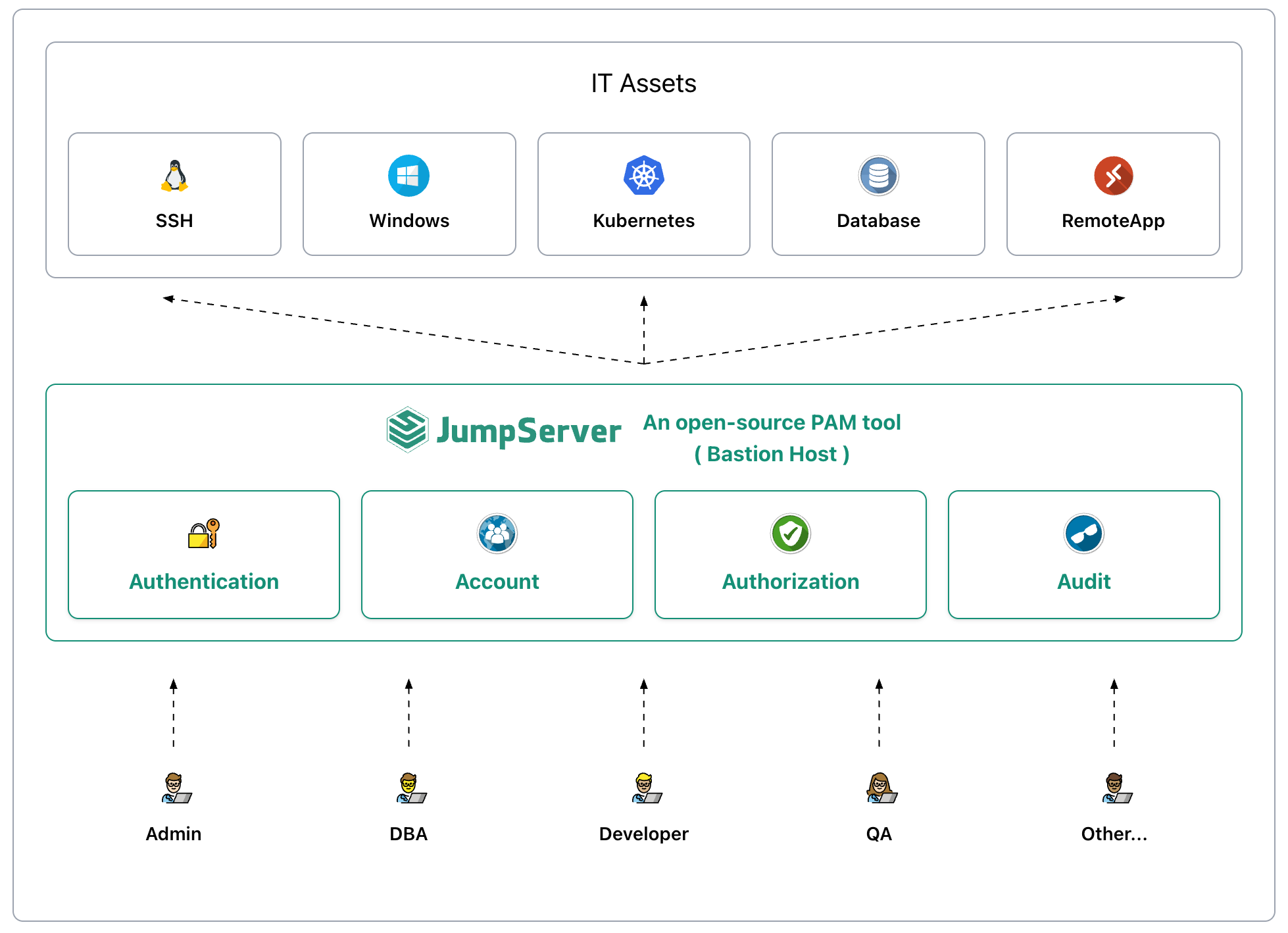
这类图中会表现:堡垒机IP是唯一入口,服务器防火墙只开放堡垒机来源;堡垒机内部有用户模块、权限模块、资产模块,箭头表示访问授权路径而不是物理连接路径。
六、常见坑、正确做法、验证方法、下一步操作
最常见的坑:第一,服务器仍然对公网开放22端口。结果是堡垒机形同虚设,绕过入口直接连服务器。第二,共用账号登录堡垒机。导致审计失效,不知道是谁操作。第三,只做登录审计,不做命令审计。无法回溯具体操作行为。
正确做法:服务器层面只信任堡垒机IP。堡垒机层面用户实名绑定。权限必须分级(只读 / 运维 / 管理)。操作日志与会话录像必须开启。
验证方法:在非堡垒机电脑直接SSH服务器,应该连接失败。在堡垒机登录后访问服务器,连接成功。查看堡垒机日志,能看到用户、时间、命令记录。
下一步操作建议:在堡垒机中接入更多服务器资产。开始做权限分级模型设计。将数据库服务器、核心节点单独设高权限组。形成“最小权限访问”结构。
七、本模块决策指南(什么时候必须用?什么时候可以不用?)
必须使用堡垒机的情况:多人运维环境,生产系统环境,有安全审计要求,有合规要求(金融、政企、数据系统),存在外包或临时运维人员。
可以不用堡垒机的情况:个人学习环境,单人服务器,临时测试机,纯本地实验环境。
简要对比替代方案:
- 直接SSH登录:简单,但无审计、无控制、风险高
- SSH跳板机:有隔离,但审计弱
- 堡垒机系统:入口统一、权限控制、全量审计、合规支持完整
决策核心一句话:只要不是“一个人用一台服务器”的环境,就必须上堡垒机。
总结一句工程化理解
堡垒机不是安全工具,而是运维入口控制系统。它的核心价值不是“防攻击”,而是:控制谁能进、进哪里、干了什么、能不能追责。
基础入门-Web应用-内外API接口
一、它在整个系统中解决什么问题?(用生活化例子理解)
在一个真实的 Web 系统中,不只是“人”会访问系统,还有大量“程序”在访问系统。比如这些场景:前端页面要获取用户数据,需要访问后端接口;手机 App 要登录系统,需要访问接口;支付系统要通知订单系统付款成功,需要访问接口日志系统要拉取数据分析,需要访问接口。如果没有 API 接口,系统只能靠“页面访问”,程序之间根本无法协作。
API接口,本质就是“程序和程序之间说话的标准通道”。
那“内外API接口”解决的核心问题是:不是所有接口都能给外部用,也不是所有接口都应该暴露出去。所以系统必须区分两类接口:内网API:只给系统内部模块用外网API:给外部系统、App、第三方平台用,生活化理解就是:公司内部办公系统接口 ≠ 对外开放服务接口,内部走内线电话,外部走客服电话
解决的是三个现实问题:安全隔离、权限控制、系统稳定性保护
二、它在系统结构中的位置?与其他模块如何协作?
在 Web 应用架构中,API接口层处于业务系统对外通信的边界层,是系统的数据出入口。
结构关系是:
- 内部模块 → 内部API → 内部模块
- 外部系统 → 外部API → 内部业务系统
也就是说:内API服务于系统内部模块之间调用,外API服务于系统对外提供能力
逻辑位置上,API接口层处在:
前端 / 外部系统
↓
API接口层(内外接口边界)
↓
业务服务层
↓
数据层

图中看到:左侧是外部系统(App、第三方平台、浏览器),右侧是内部服务模块(订单、用户、支付等),中间是 API 接口层。通常用颜色区分:红色表示外部API区域,蓝色表示内部API区域,箭头方向清晰显示“外部请求只能进外API,内部调用走内API通道”。
三、它具体是怎么工作的?以及为什么要这样设计?
工作流程(外部API为例)
- 外部系统发起请求
- 请求进入外部API入口
- 进行身份认证(token / key / 签名校验)
- 权限判断(能不能访问这个接口)
- 流量控制(限流、防刷)
- 请求转发给内部业务服务
- 返回结果给外部系统
内部API流程
- 内部服务发起请求
- 通过内网API接口
- 内部鉴权(服务身份校验)
- 服务调用业务模块
- 返回内部结果
为什么要区分内外API?
原因非常工程化:
第一,安全等级不同
外部API面对公网,必须防攻击、防刷、防扫描
内部API在内网环境,重点是稳定与效率
第二,接口复杂度不同
外部API需要稳定版本控制、兼容性设计
内部API可以快速迭代,不追求长期兼容
第三,性能模型不同
外部API必须限流
内部API追求高并发、高吞吐
第四,权限模型不同
外部API是“用户级权限”
内部API是“服务级权限”
这类流程图通常会画出两条路径:一条从公网进入外部API入口,经过认证、限流、网关,再进入业务服务;另一条是内网服务之间的直连调用路径。颜色区分内外网络区域,箭头显示数据流动方向。
四、实际中常用的实现方式有哪些?各有什么特点?
常见实现方式分三层理解:
第一层:接口形式层
REST API(HTTP接口)
特点:简单通用,浏览器、App、程序都能用
第二层:接口隔离方式
路径隔离:/api/internal/*/api/external/*
域名隔离:internal.api.xxx.comapi.xxx.com
网络隔离:
内API只在内网IP可访问
外API暴露公网
第三层:控制机制
鉴权机制(token/key)
限流机制
日志审计
版本控制
五、典型真实场景 + 可直接复制的配置示例(逐行解释)
场景:一个 Web 系统有用户系统和订单系统,同时对外提供 App 接口。设计目标:外部API给App用,内部API给系统模块调用
路径隔离示例
外部API:
POST /api/external/login
GET /api/external/user/info
POST /api/external/order/create
内部API:
POST /api/internal/user/check
GET /api/internal/order/status
POST /api/internal/log/write
含义解释:external路径 = 对外接口,internal路径 = 内部接口
简化Nginx隔离配置示例
location /api/internal/ {
allow 10.0.0.0/8;
deny all;
proxy_pass http://internal_service;
}
逐行解释:
- 允许内网IP访问内API
- 拒绝所有公网访问
- 请求转发到内部服务集群
location /api/external/ {
proxy_pass http://external_service;
}
解释:
外部API对公网开放,由外部访问

图中显示两条API通道:外部API通道连公网,内部API通道只连内网服务,箭头方向清晰区分访问边界。
六、常见坑、正确做法、验证方法、下一步操作
常见坑
内外API混用一个接口路径
内API暴露公网
无权限控制
无流量控制
接口无版本管理
正确做法
路径隔离或域名隔离
网络层隔离
权限模型区分
限流机制
接口分级管理
验证方法
公网访问 internal 接口 → 必须失败
内网访问 internal 接口 → 成功
外部接口访问正常
日志可区分内外调用来源
下一步操作建议
开始设计接口权限模型
引入接口认证机制
建立接口文档规范
为外部API设计版本控制规则
七、本模块决策指南(什么时候必须用?什么时候可以简化?)
必须区分内外API的场景:
- 系统对外提供服务
- 多模块系统架构
- 微服务结构
- 多端接入(App + Web + 第三方)
- 安全要求较高系统
可以简化的场景:
- 单体系统
- 单人项目
- 学习实验项目
- 无外部系统接入
简要对比:
- 不区分内外API:简单但混乱,风险高
- 逻辑区分(路径):低成本隔离
- 网络区分(内外网):工程级安全
- 网关隔离:生产级标准方案
决策核心一句话:只要系统要对外提供接口能力,就必须区分内外API。
总结一句工程化理解
内外API接口不是“接口分类问题”,而是系统边界设计问题。
它解决的不是“怎么写接口”,
而是:
谁能访问
从哪里访问
访问到哪里
能访问什么
访问是否可控
访问是否可追溯
这是 Web 应用从“能跑”走向“可控、可扩展、可运维”的关键一步。
基础入门-Web应用-第三方拓展架构
现在开始讲解主题:基础入门 → Web应用 → 第三方拓展架构。
这一部分只聚焦“第三方拓展架构”在 Web 应用体系中的作用与实现,不引入任何其他未指定模块或概念。
在一个最基础的 Web 应用里,最早期往往只有“前端页面 + 后端服务 + 数据库”这三样东西。用户访问网页,数据从前端到后端,再进数据库,再返回给用户。这种结构在小项目阶段完全够用,但一旦系统开始变复杂,就会遇到非常现实的问题:你会发现很多能力不是“业务核心”,但又是“必须要有”的,比如短信验证码、邮件通知、支付能力、地图定位、对象存储、实名认证、语音识别、风控校验、图像识别、推送通知等。如果这些功能全部自己开发,一方面成本极高,另一方面专业性也很难追上成熟厂商,于是就产生了一个非常自然的系统设计结果:把这些“通用能力”交给专业第三方服务来提供,这就是第三方拓展架构存在的根本原因。
用生活化一点的比喻来讲,一个 Web 系统就像一家正在扩张的公司,总部负责核心业务,比如产品、运营、用户逻辑,但保洁、电力、物流、金融服务、安全认证这些,如果全部自己养团队做,成本极高且不专业,于是外包给专业公司。第三方拓展架构,本质上就是 Web 系统里的“能力外包体系”,让系统只专注于自己的核心业务,把通用能力通过接口方式接入外部服务。
在系统结构中,第三方拓展架构通常位于Web 后端服务层的外侧。也就是说,浏览器请求不会直接访问第三方服务,而是先进入你自己的后端服务,再由后端服务作为“中间控制者”去调用第三方平台接口,然后把结果再统一返回给前端。这种设计不是偶然的,而是出于三个非常重要的原因:第一是安全性,第三方接口密钥不能暴露给前端;第二是控制权,所有业务逻辑必须由你自己的系统掌控;第三是解耦合,前端不依赖具体第三方厂商,后端可以随时更换服务提供商。
[插入图片:Web应用第三方拓展整体结构图]
这张图从左到右依次是:用户浏览器、Web前端、Web后端服务、第三方服务平台集群。浏览器通过 HTTP 请求访问前端页面,前端通过 API 调用后端服务。后端服务右侧连接多个第三方平台模块,比如“短信服务”“支付平台”“对象存储”“身份认证”“地图服务”。箭头全部是单向请求-响应流:前端 → 后端 → 第三方平台 → 后端 → 前端。图中后端位于中心位置,所有外部能力都必须通过后端中转接入,体现“统一控制入口”的结构设计。
从工作机制上看,第三方拓展架构的核心逻辑非常清晰:业务系统不直接实现能力,而是通过标准接口调用外部能力服务。流程一般是:用户操作 → 前端发请求 → 后端接收请求 → 后端判断业务逻辑 → 后端调用第三方接口 → 接收第三方返回结果 → 后端处理结果 → 返回给前端。
之所以这样设计,是因为接口化调用可以做到模块隔离、责任分离和风险控制。比如支付系统出问题,不影响你自己的业务逻辑系统本身;短信平台更换厂商,只需改接口适配层,不影响前端和数据库结构;对象存储服务更换区域节点,不影响业务系统代码结构。
[插入图片:第三方服务调用流程图]
图中左侧是“用户操作”,进入“前端页面”,然后进入“后端业务服务层”。后端内部包含“业务逻辑模块”和“第三方接口适配模块”。从接口适配模块发出箭头连接到“第三方服务平台”。返回路径是:第三方平台 → 接口适配模块 → 业务逻辑模块 → 前端 → 用户。图中清晰标注“统一出口、统一入口”,表示所有第三方调用都集中管理,而不是散落在系统各处。
在实际系统中,最常见的第三方拓展服务包括但不限于:短信服务平台(验证码、通知)、邮件服务平台、支付平台(支付宝、微信支付类能力)、对象存储服务(文件存储)、地图与定位服务、实名认证服务、语音识别与图像识别服务、推送通知平台。这些服务的共同特征是:通过 HTTP API 提供能力、通过密钥鉴权、按调用量或资源量计费、对外提供标准接口文档。
从技术实现上,第三方拓展架构通常会在后端系统中形成一个独立的“第三方服务适配层”或“外部服务模块层”,专门负责:接口封装、参数转换、鉴权签名、错误处理、重试机制、日志记录。这一层的存在,是为了避免第三方逻辑污染业务核心代码,让系统保持结构清晰。
下面给一个非常典型、真实可用的示例场景:接入短信验证码服务。
场景:用户注册账号 → 需要发送手机验证码 → 系统调用第三方短信平台接口发送验证码。
假设后端是一个简单的 Web 服务,使用 HTTP 调用第三方短信平台 API,示例配置如下(示意为通用接口形式):
SMS_API_URL=https://api.sms-provider.com/send
SMS_APP_KEY=your_app_key_here
SMS_APP_SECRET=your_app_secret_here
这三行配置含义非常明确:
第一行是短信平台提供的接口地址,也就是请求要发送到哪里。
第二行是平台分配给你的应用身份标识,用于识别是谁在调用接口。
第三行是密钥,用于接口鉴权,证明你有权限使用该服务。
后端请求示意流程逻辑(文字描述):后端接收到“发送验证码”请求 → 生成随机验证码 → 组装请求参数(手机号、验证码、签名) → 向 SMS_API_URL 发送 HTTP 请求 → 接收返回结果 → 判断是否成功 → 写入日志 → 返回前端结果。
[插入图片:短信第三方服务接入结构图]
图中左侧是“注册页面”,连接到“后端注册服务模块”。后端右侧是“短信接口适配模块”,再连接“第三方短信平台服务器集群”。箭头方向为:注册请求 → 后端 → 短信接口模块 → 短信平台 → 返回状态 → 后端 → 前端提示用户“发送成功/失败”。图中短信模块与业务模块是分离结构,表示第三方能力是外挂模块而非核心模块。
使用第三方拓展架构时,最容易踩的坑主要集中在四个方面:
第一是密钥泄露,把第三方接口密钥写在前端代码里,这是严重安全错误;正确做法是只放在后端配置文件或环境变量中。
第二是强耦合,把业务逻辑写死依赖某一个厂商接口格式,导致无法更换服务商;正确做法是做接口适配层抽象。
第三是无异常处理,不处理超时、失败、重试、限流,导致系统稳定性极差;正确做法是加入失败重试、超时控制和熔断机制。
第四是无监控日志,出了问题无法排查;正确做法是记录第三方调用日志和返回状态。
验证方法也非常简单:可以在后端日志中查看是否成功发起请求、是否收到返回结果;通过第三方平台控制台查看调用记录;通过模拟错误(如断网、错误密钥)测试系统是否能正确处理失败场景。
下一步操作建议是:当一个第三方能力接入完成后,必须进行“接口封装 + 统一调用 + 日志记录 + 错误处理 + 配置隔离”五件事,这样系统结构才是长期可维护的。
最后是本模块决策指南。
什么时候必须使用第三方拓展架构?当能力不是业务核心、但又高度专业化(如支付、存储、认证、通信)时,必须使用第三方服务,这是系统工程上最合理的选择。
什么时候可以不用?在学习阶段、小型实验项目、纯教学项目中,可以用本地模拟服务或简单实现替代,不必接真实第三方平台。
与“自己开发”的对比:自己开发成本高、维护难、风险大;第三方拓展成本可控、稳定性高、专业性强。
与“直接前端调用第三方接口”的对比:前端直连风险极高、无控制能力、不安全;后端中转结构安全可控、可维护性强、可扩展性强。
一句话总结这一模块的定位:第三方拓展架构不是为了复杂化系统,而是为了让系统专注核心业务,把通用能力标准化接入,形成“轻核心 + 强能力扩展”的现代 Web 架构模式。当你理解了这一点,后续无论接入支付、存储、认证、AI 服务,结构逻辑都是同一套体系,只是换了外部能力来源而已。