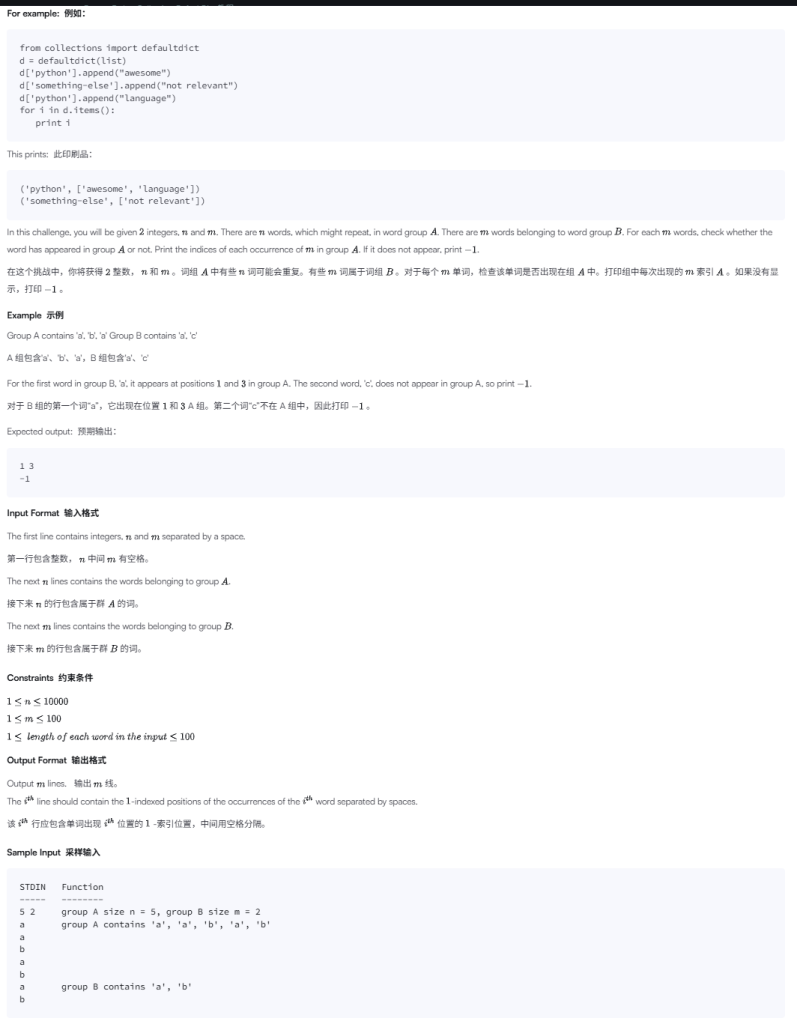
这道题本质上在考什么
这道题考的是:如何记录一个单词在 A 组中出现过哪些位置,然后快速查询 B 组中的每个单词。
题目不是让你判断单词有没有出现一次,而是要输出它在 A 组中出现的所有位置。
例如 A 组是:
a
a
b
a
b
位置从 1 开始编号:
第1个:a
第2个:a
第3个:b
第4个:a
第5个:b
所以:
a 出现在 1 2 4
b 出现在 3 5
如果 B 组查询的是:
a
b
输出就是:
1 2 4
3 5
一、先把题目翻译成人话
输入分成三部分:
第一行:
n m
表示:
A 组有 n 个单词
B 组有 m 个单词
接下来 n 行,是 A 组单词。
再接下来 m 行,是 B 组单词,也就是要查询的单词。
要求你对 B 组里的每个单词做查询:
如果这个单词在 A 组出现过,就输出它出现的所有位置。
如果没有出现过,就输出:
-1
二、这道题应该怎么思考
关键问题是:
对于 A 组中的每个单词,我们要记住它出现过哪些位置。
所以我们可以建立一个“单词 -> 位置列表”的关系。
比如 A 组是:
a
a
b
a
b
我们希望最后得到:
{
"a": [1, 2, 4],
"b": [3, 5]
}
这样后面查询的时候就很简单了。
如果查询 "a",直接找到:
[1, 2, 4]
如果查询 "b",直接找到:
[3, 5]
如果查询 "c",发现没有这个 key,就输出 -1。
三、为什么适合用 defaultdict(list)
普通字典 dict 如果你想这样写:
d["a"].append(1)
前提是 d["a"] 已经存在,而且它必须是一个列表。
否则会报错,因为一开始字典里没有 "a" 这个 key。
所以普通写法通常要这样:
d = {}
if "a" not in d:
d["a"] = []
d["a"].append(1)
但是 defaultdict(list) 可以帮我们自动创建空列表。
from collections import defaultdict
d = defaultdict(list)
d["a"].append(1)
d["a"].append(2)
这时字典会变成:
{
"a": [1, 2]
}
也就是说:
defaultdict(list)
可以理解成:
如果某个 key 第一次出现,就自动给它配一个空列表
[]。
所以这道题非常适合用:
defaultdict(list)
因为我们正好要记录:
单词 -> 多个位置
四、基本代码结构
这道题的整体步骤是:
- 读入
n和m - 创建一个字典,用来保存 A 组单词的位置
- 读取 A 组的 n 个单词,记录每个单词出现的位置
- 读取 B 组的 m 个单词
- 对每个 B 组单词查询:
- 如果出现过,输出所有位置
- 如果没出现过,输出
-1
代码如下:
from collections import defaultdict
n, m = map(int, input().split())
positions = defaultdict(list)
for i in range(1, n + 1):
word = input().strip()
positions[word].append(i)
for _ in range(m):
word = input().strip()
if word in positions:
print(*positions[word])
else:
print(-1)
五、逐行解释代码
先看第一行:
from collections import defaultdict
这表示从 collections 模块里导入 defaultdict。
defaultdict 是一种特殊字典,适合用来处理“一个 key 对应多个值”的情况。
然后读入第一行:
n, m = map(int, input().split())
比如输入是:
5 2
input() 读到的是字符串:
"5 2"
split() 把它拆成:
["5", "2"]
map(int, ...) 把字符串转成整数:
5, 2
最后赋值给:
n = 5
m = 2
创建字典:
positions = defaultdict(list)
这个字典用来保存每个单词出现的位置。
比如最后可能长这样:
{
"a": [1, 2, 4],
"b": [3, 5]
}
读取 A 组单词:
for i in range(1, n + 1):
word = input().strip()
positions[word].append(i)
这里非常关键。
为什么是:
range(1, n + 1)
因为题目要求输出的位置是从 1 开始,不是从 0 开始。
如果 n = 5,那么:
range(1, n + 1)
实际就是:
1, 2, 3, 4, 5
假设输入的 A 组是:
a
a
b
a
b
执行过程是:
| i | word | 执行后 positions |
|---|---|---|
| 1 | a | {"a": [1]} |
| 2 | a | {"a": [1, 2]} |
| 3 | b | {"a": [1, 2], "b": [3]} |
| 4 | a | {"a": [1, 2, 4], "b": [3]} |
| 5 | b | {"a": [1, 2, 4], "b": [3, 5]} |
所以这一句:
positions[word].append(i)
意思是:
把当前单词出现的位置 i 追加到它对应的列表中。
然后读取 B 组单词并查询:
for _ in range(m):
word = input().strip()
if word in positions:
print(*positions[word])
else:
print(-1)
这里的 _ 表示:
循环 m 次,但我不关心当前是第几次。
如果查询的单词在 positions 里面,就输出它的位置列表。
比如:
positions["a"]
得到:
[1, 2, 4]
这句:
print(*positions[word])
会把列表展开输出。
也就是说:
print(*[1, 2, 4])
效果相当于:
print(1, 2, 4)
输出:
1 2 4
如果不用 *,直接写:
print(positions[word])
输出会变成:
[1, 2, 4]
这不符合题目要求。
六、用样例完整走一遍
输入:
5 2
a
a
b
a
b
a
b
第一行:
n = 5
m = 2
接下来 5 个单词属于 A 组:
a
a
b
a
b
记录之后得到:
positions = {
"a": [1, 2, 4],
"b": [3, 5]
}
接下来 2 个单词属于 B 组:
a
b
查询 "a":
positions["a"] = [1, 2, 4]
输出:
1 2 4
查询 "b":
positions["b"] = [3, 5]
输出:
3 5
最终输出:
1 2 4
3 5
七、完整答案代码
from collections import defaultdict
n, m = map(int, input().split())
positions = defaultdict(list)
for i in range(1, n + 1):
word = input().strip()
positions[word].append(i)
for _ in range(m):
word = input().strip()
if word in positions:
print(*positions[word])
else:
print(-1)
八、常见错误与易混点
1. 位置编号写成从 0 开始
错误写法:
for i in range(n):
word = input().strip()
positions[word].append(i)
这样记录的位置会是:
0 1 2 3 4
但题目要求的是:
1 2 3 4 5
所以应该写:
for i in range(1, n + 1):
2. 忘记用 list 保存多个位置
错误思路:
positions[word] = i
这样只能保存最后一次出现的位置。
比如 a 出现了 3 次:
第1次:1
第2次:2
第3次:4
如果你写:
positions["a"] = i
最后只会留下:
"a": 4
前面的 1 和 2 会被覆盖掉。
所以必须用列表:
positions[word].append(i)
3. 直接打印列表格式不对
错误写法:
print(positions[word])
输出是:
[1, 2, 4]
题目要求是:
1 2 4
所以可以写:
print(*positions[word])
4. 没有处理不存在的单词
如果查询的单词没有在 A 组出现过,不能空着不输出,而是要输出:
-1
所以必须写判断:
if word in positions:
print(*positions[word])
else:
print(-1)
九、这类题的通用思路
以后你遇到这种题,可以先问自己三个问题:
第一,题目要不要记录“某个东西出现过哪些位置”?
如果要,那就很适合用:
字典 + 列表
第二,是否会重复出现?
如果会重复出现,就不能只存一个值,要存列表。
例如:
"a": [1, 2, 4]
第三,后面是不是要快速查询?
如果要快速查询,就不要每次都从头遍历 A 组,而是先建立字典。
这道题的核心思想就是:
先预处理 A 组,把每个单词的位置保存好;再查询 B 组,直接查字典。
十、练习
给你一组数字:
6 3
10
20
10
30
20
10
10
20
40
前 6 个数字属于 A 组,后 3 个数字属于 B 组查询。
请你输出每个 B 组数字在 A 组中出现的位置。如果没有出现,输出 -1。
提示:
- 仍然可以使用
defaultdict(list) - 位置仍然从 1 开始
- 输入读到的是字符串,如果你只比较内容,其实可以不转成整数
- 查询
10时应该能找到多个位置
本质上就是字典里面嵌套列表,但是用了特殊的函数来处理,对吧?
对,本质理解是正确的。
这道题的核心数据结构就是:
{
"a": [1, 2, 4],
"b": [3, 5]
}
也就是:
字典里面的 key 是单词
字典里面的 value 是列表
列表里面存这个单词出现过的位置
所以可以把它理解成:
字典嵌套列表
更准确一点说,是:
一个字典,每个 key 对应一个列表
defaultdict(list) 只是帮你省掉了“第一次遇到某个单词时,先手动创建空列表”的步骤。
普通字典写法是:
positions = {}
word = "a"
if word not in positions:
positions[word] = []
positions[word].append(1)
用了 defaultdict(list) 之后,可以直接写:
from collections import defaultdict
positions = defaultdict(list)
word = "a"
positions[word].append(1)
因为当 positions["a"] 还不存在时,defaultdict(list) 会自动创建:
positions["a"] = []
然后再执行:
positions["a"].append(1)
所以它不是一种新的复杂结构,它本质上还是字典,只不过这个字典有一个“默认值机制”。
可以这样记:
dict:没有 key,直接访问会报错
defaultdict(list):没有 key,会自动给你一个空列表 []
所以这道题的核心就是:
positions[word].append(i)
这句话可以翻译成:
把当前单词 word 出现的位置 i,放进这个单词对应的位置列表里。
比如连续执行:
positions["a"].append(1)
positions["a"].append(2)
positions["a"].append(4)
最后就是:
{
"a": [1, 2, 4]
}
你现在的理解可以总结成一句话:
这道题就是用一个“单词 -> 位置列表”的字典来保存 A 组信息,defaultdict(list) 只是让创建列表这一步自动完成。



