请求头&返回包-方法&头修改&状态码等
你有没有寄过快递?你填写的快递单就像请求头,上面有收件人地址(Host)、寄件人信息(User-Agent)、包裹内容类型(Content-Type)等;快递公司给你的运单状态(“已揽收”“运输中”“派送中”)就是状态码;而最终收到的包裹连同里面的物品就是返回包(响应体)。在 Web 开发中,客户端(浏览器、APP)与服务器的每次交互,本质上就是一次 HTTP 请求与响应。理解并能熟练操作“请求头&返回包-方法&头修改&状态码等”,是构建可靠、安全应用的基础。下面我们像一位资深工程师一样,一步步拆解这些概念,并落地到可操作的工具和代码上。
请求方法与状态码:HTTP 的动作与反馈
我们先从最基础的 HTTP 方法和状态码入手。HTTP 方法(如 GET、POST)告诉服务器你想做什么动作,状态码则是服务器告诉你动作的结果如何。这就好比你去餐厅:你说“我要点餐”(POST 方法),服务员回复“好的,这是菜单”(200 OK);或者说“我要取消订单”(DELETE 方法),服务员说“订单已取消”(200 OK)或“订单不存在”(404 Not Found)。这样设计的好处是,客户端和服务端通过一套标准化的“动词”和“状态编号”沟通,无论后端用什么语言,前端都能准确理解意图和结果。
在系统结构中,方法和状态码位于 HTTP 协议的最顶层——请求行和状态行中。请求行由“方法 + 路径 + HTTP版本”组成,状态行由“版本 + 状态码 + 状态短语”组成。浏览器或 HTTP 客户端构建请求时,必须指定方法;服务端处理完请求后,必须返回状态码。它们与请求头、响应头、请求体、响应体并列,但却是最先被解析的部分。
为什么这么设计?因为方法让 HTTP 具备了对资源的操作语义(安全、幂等、可缓存),状态码让客户端能程序化地处理不同结果(比如 2xx 表示成功,自动解析响应体;4xx 表示客户端错误,展示错误提示)。具体工作时,你打开浏览器开发者工具的“网络”面板,刷新页面,可以看到每个请求的方法和状态码。用命令行工具 curl 也能直观查看:
curl -I https://api.github.com/users/octocat返回的第一行就是 HTTP/2 200,状态码 200 表示成功。常用的方法有 GET(获取)、POST(创建)、PUT(全量更新)、PATCH(部分更新)、DELETE(删除);状态码分类为 1xx(信息)、2xx(成功)、3xx(重定向)、4xx(客户端错误)、5xx(服务器错误)。
实际场景中,开发调试 API 时,看到 404 会去检查路径或资源是否存在;看到 500 则要排查服务器代码。最容易踩的坑是滥用方法,比如用 GET 执行删除操作,这违反了 HTTP 语义,也容易被爬虫或搜索引擎误触发;或者返回状态码时只关注 200,即使业务逻辑失败也用 200 包裹,导致客户端无法统一处理错误。正确做法是严格遵循 HTTP 语义:非简单查询用 POST/PUT/DELETE,错误时返回对应 4xx/5xx 状态码。验证方法很简单,用 curl 加上 -X 指定方法,观察返回码。下一步,我们就要学习如何在请求中加入更多控制信息——请求头。
Mermaid 图表:HTTP请求与响应结构图

这张图展示了完整的 HTTP 请求与响应结构。左侧客户端构造请求:请求行包含方法、路径和版本;请求头是一系列键值对;空行分隔头与体;请求体存放要发送的数据。右侧服务器返回响应:状态行包含版本、状态码和短语;响应头控制客户端行为;空行后是响应体数据。箭头表示数据从客户端流向服务器,再返回客户端的顺序。
修改请求头:定制客户端身份与意图
请求头就像快递单上的备注栏,你可以添加额外信息,例如认证令牌(Authorization)、期望的响应格式(Accept)、来源页面(Referer)等。为什么要修改请求头?因为服务端常常依赖这些字段做身份验证、内容协商、流量控制。例如,调用需要登录的 API,你必须在请求头中携带 session ID 或 JWT;想让服务器返回 JSON 而非 XML,就要设置 Accept: application/json。
在系统结构中,请求头处于请求行之后、请求体之前。客户端(浏览器或后端服务)在发送请求前可以自由添加、修改头字段;服务器收到后根据头字段决定如何处理请求。浏览器中可以用 fetch 或 XMLHttpRequest 修改请求头,Node.js 中可以用 axios 或 http 模块,后端服务则可能通过网关或中间件修改请求头(例如添加追踪 ID)。
实际中最常用的工具当然是编程语言自带的 HTTP 客户端或第三方库。2025 年,浏览器环境 fetch 已成标准,Node.js 也内置了 fetch(需要 Node.js 18+),但为了更灵活地控制,很多人仍用 axios。下面是一个前端用 fetch 发送 POST 请求并添加自定义头的例子:
// 浏览器环境
const response = await fetch('https://api.example.com/users', {
method: 'POST', // 指定方法
headers: {
'Content-Type': 'application/json', // 告知服务器请求体是 JSON
'Authorization': 'Bearer eyJhbGci...', // 携带 JWT 令牌
'X-Request-ID': 'abc-123' // 自定义追踪 ID
},
body: JSON.stringify({ name: 'Alice' }) // 请求体
});逐行解释:fetch 的第一个参数是 URL,第二个参数是配置对象。method 明确请求方法;headers 对象里设置需要发送的头,Content-Type 告诉服务器我们发送的是 JSON,Authorization 是常见的认证头,X-Request-ID 是自定义头,常用于链路追踪;body 存放要发送的数据,需序列化为字符串。
服务端如何读取这些头?以 Node.js + Express 为例:
const express = require('express');
const app = express();
app.use(express.json()); // 解析 JSON 请求体
app.post('/users', (req, res) => {
const authHeader = req.headers['authorization']; // 读取 Authorization 头
const requestId = req.headers['x-request-id']; // 读取自定义头
console.log('Auth:', authHeader, 'RequestID:', requestId);
// 这里可做验证:如果 authHeader 无效则返回 401
if (!authHeader || !authHeader.startsWith('Bearer ')) {
return res.status(401).json({ error: 'Unauthorized' });
}
// 处理业务...
res.status(201).json({ id: 123, name: req.body.name });
});
app.listen(3000);req.headers 是一个对象,包含了所有请求头,键名自动转成了小写。我们可以通过它读取并验证头信息。
最容易踩的坑有三个:一是跨域请求时,如果添加了非简单头(比如自定义 X-Request-ID 或 Authorization 其实也算简单头?实际上,Authorization 属于简单头?简单头包括 Accept、Accept-Language、Content-Language、Content-Type(仅限某些值),而 Authorization 不属于简单头,因此会触发 CORS 预检请求。这意味着浏览器会先用 OPTIONS 方法询问服务器是否允许该头,若服务器不允许,真正的请求就不会发出。二是头名称大小写,HTTP 规范规定头名称不区分大小写,但某些服务器实现可能依赖特定大小写(一般不会)。三是不要在请求头中暴露敏感信息(如内部 IP、数据库密码),因为请求头在客户端可见(浏览器中)。
验证请求头是否正确发送,可以使用浏览器开发者工具的“网络”面板,点击请求查看“请求头”部分;或者用 curl 的 -v 参数查看详细交互。下一步,我们自然要看看服务端如何返回自己的头和状态码。
Mermaid 图表:请求头修改流程(以Node.js中间件为例)
这张图展示了请求头在服务端被中间件修改或验证的流程。客户端请求进入后,第一个中间件可能添加或修改头(比如插入追踪 ID);第二个中间件读取并验证 Authorization 头,若有效则交给路由处理器,无效则跳转到错误中间件;最终所有路径都会汇聚到响应返回客户端。蓝色和黄色分别表示不同的中间件职能,箭头方向是请求的传递路径。
修改响应头与状态码:控制客户端行为
响应头和状态码是服务端控制客户端行为的主要手段。状态码告诉客户端请求结果的大类,响应头则提供细化指令,比如 Content-Type 告诉浏览器如何解析响应体,Cache-Control 控制缓存策略,Set-Cookie 让浏览器保存身份信息,Location 配合 3xx 状态码实现重定向。你就像快递公司,不仅告诉客户“包裹已发出”(状态码 200),还在面单上注明“需本人签收”(Cache-Control: no-cache)。
在系统结构中,服务端程序通过框架提供的 API 设置状态码和响应头。以 Express 为例,res.status(code) 设置状态码,res.set(field, value) 或 res.set(object) 设置响应头,最后用 res.send() 或 res.json() 发送响应体。
举个例子,我们创建一个登录接口,成功时返回 200 和 JWT 令牌,同时设置安全响应头防止浏览器错误解析;失败时返回 401 并要求认证:
app.post('/login', async (req, res) => {
const { username, password } = req.body;
// 假设验证逻辑(实际应查询数据库)
if (username === 'admin' && password === 'secret') {
// 设置响应头:指明内容类型为 JSON,并添加安全头
res.set({
'Content-Type': 'application/json',
'Cache-Control': 'no-store', // 禁止缓存登录结果
'X-Content-Type-Options': 'nosniff' // 防止浏览器 MIME 嗅探
});
// 生成 JWT(简化示例,实际应使用库)
const token = 'jwt.' + Buffer.from(username).toString('base64');
// 设置状态码 200,并返回 JSON 体
res.status(200).json({ token });
} else {
// 认证失败:返回 401 并告诉客户端需要 Basic 认证
res.set('WWW-Authenticate', 'Basic realm="User Login"');
res.status(401).json({ error: 'Invalid credentials' });
}
});逐行解释:首先通过 req.body 获取用户名密码;验证成功后,用 res.set 批量设置响应头:Content-Type 明确是 JSON,Cache-Control: no-store 避免登录状态被缓存,X-Content-Type-Options 是安全头,防止浏览器将响应误当作其他格式执行;最后 res.status(200).json(...) 设置状态码并发送 JSON。失败时,设置 WWW-Authenticate 头(用于 HTTP 基础认证),并返回 401 状态码和错误信息。
容易踩的坑有:在调用 res.send() 或 res.json() 之后又尝试设置头或状态码,这会导致“Can’t set headers after they are sent”错误;状态码设置后忘记 return,导致后续代码继续执行,可能再次发送响应;响应头重复,除了 Set-Cookie 允许重复,其他头一般应避免重复。验证时用 curl -I 只看响应头,或用 curl -v 看完整交互:
curl -X POST http://localhost:3000/login -H "Content-Type: application/json" -d '{"username":"admin","password":"secret"}' -v输出会显示响应状态码和所有头字段。接下来,我们结合请求头修改和响应头设置,做一个综合示例,并引入安全相关的中间件。
Mermaid 图表:响应头与状态码设置流程
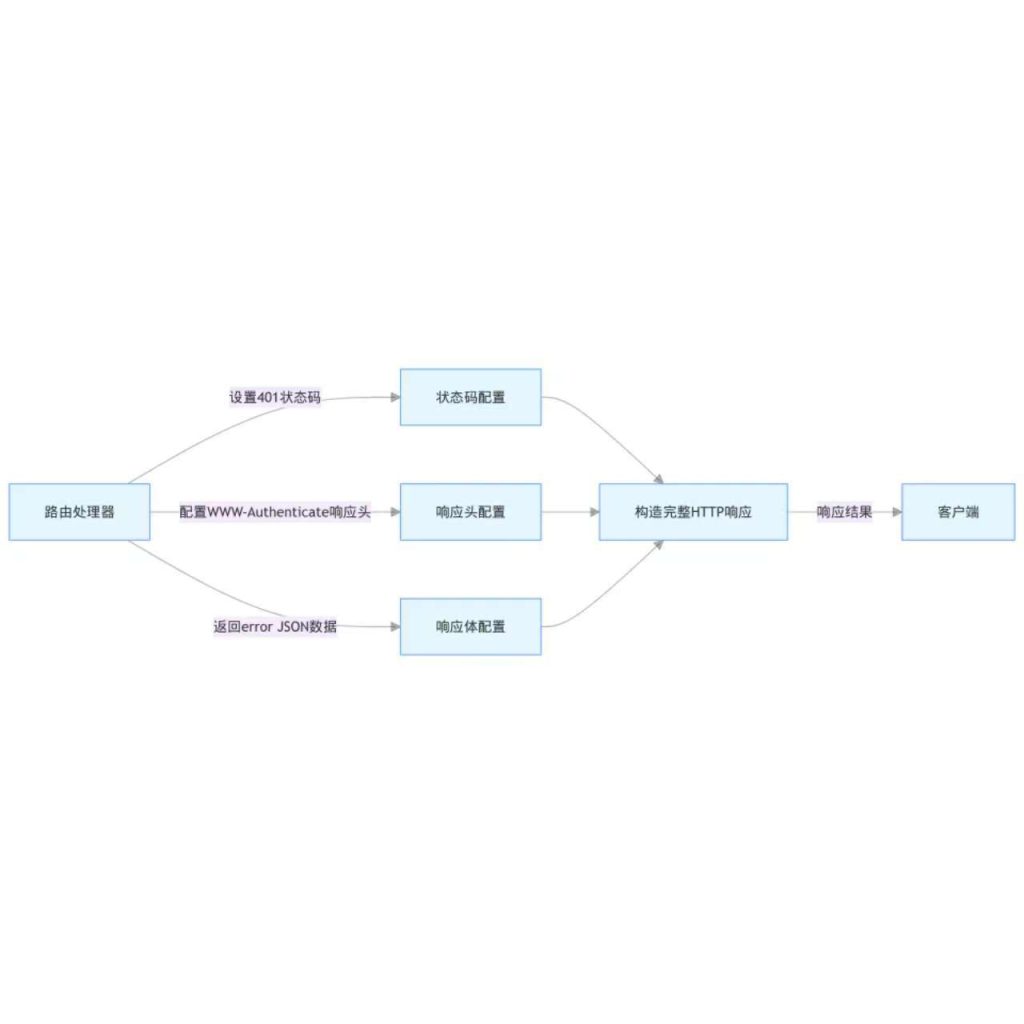
这张图描述了服务器内部如何构建响应。路由处理器分别通过框架方法设置状态码、响应头和响应体,这些组件最终被组合成一个完整的 HTTP 响应报文,发送回客户端。箭头表示数据流从处理器到响应对象,再到客户端。
综合示例与安全考虑
现在我们把请求头修改、响应头设置、状态码结合起来,实现一个具有基本安全防护的 API。假设我们提供一个获取用户资料的接口,需要验证 Authorization 头中的 JWT,同时返回安全响应头防止常见漏洞。我们将使用 Express 和 helmet 中间件(一个集成了多种安全响应头的库)。
const express = require('express');
const helmet = require('helmet'); // 2025年主流版本
const app = express();
app.use(helmet()); // 自动设置多个安全头:CSP、X-Frame-Options、X-XSS-Protection 等
app.use(express.json());
// 模拟用户数据库
const users = { 1: { name: 'Alice' }, 2: { name: 'Bob' } };
// 认证中间件:验证 Authorization 头
function authenticate(req, res, next) {
const authHeader = req.headers['authorization'];
if (!authHeader || !authHeader.startsWith('Bearer ')) {
// 设置响应头 WWW-Authenticate,提示客户端需要 Bearer 令牌
res.set('WWW-Authenticate', 'Bearer realm="User Profile"');
return res.status(401).json({ error: 'Missing or invalid token' });
}
const token = authHeader.substring(7); // 去掉 "Bearer "
// 实际应用应验证 JWT 签名,这里仅做演示
if (token !== 'valid-jwt') {
return res.status(403).json({ error: 'Forbidden' }); // 令牌无效
}
req.user = { id: 1 }; // 模拟解析出的用户信息
next();
}
app.get('/profile/:id', authenticate, (req, res) => {
const userId = parseInt(req.params.id);
if (userId !== req.user.id) {
// 尝试访问其他用户的资料,返回 403
return res.status(403).json({ error: 'Access denied' });
}
const user = users[userId];
if (!user) {
return res.status(404).json({ error: 'User not found' });
}
// 设置额外响应头:禁止缓存,明确内容类型
res.set({
'Cache-Control': 'private, no-cache',
'Content-Type': 'application/json'
});
res.status(200).json(user);
});
app.listen(3000, () => console.log('Server running on port 3000'));逐行解释:helmet() 引入后会自动设置安全响应头,比如 Content-Security-Policy 防止 XSS,X-Frame-Options 防止点击劫持。authenticate 中间件读取 Authorization 头,若不存在或格式不对则返回 401 并附带 WWW-Authenticate 头(符合 HTTP 规范);若令牌内容不是 valid-jwt(演示用)则返回 403。通过验证后,将解析出的用户信息挂载到 req.user 上。路由处理中,检查请求的 id 是否与令牌中的用户一致,防止越权;若不一致返回 403。找到用户后设置缓存控制和内容类型,返回 200 和用户数据。
最容易踩的坑是“头注入”(Header Injection)漏洞。如果服务端用用户输入拼接响应头(比如 res.set('X-Custom-Header', userInput)),攻击者可能通过输入包含换行符的字符串,注入虚假头或分割响应体。正确做法是永远不要直接使用未过滤的用户输入设置头,或者至少移除换行符。验证安全头配置可以用 curl -I 查看,或使用在线工具如 securityheaders.com 扫描。下一步操作建议:深入学习 HTTPS 确保传输层加密,以及 OAuth2、JWT 等认证授权机制,它们都依赖于请求头(Authorization)和响应头(Set-Cookie)。
Mermaid 图表:包含安全头与认证的请求处理流程
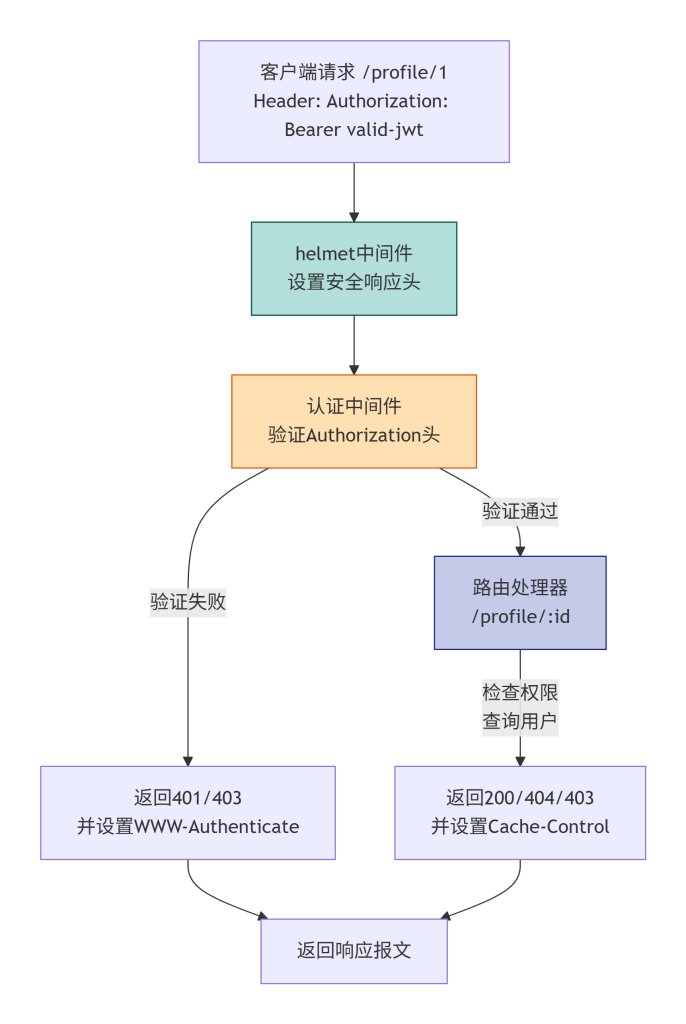
这张图完整呈现了请求经过多个中间件最终生成响应的路径。首先 helmet 中间件在响应上预设安全头(即使后续出错,这些头也会被发送)。然后认证中间件验证请求头,通过后进入路由处理器,处理器根据业务逻辑返回不同状态码和头。所有路径最后汇聚成最终响应返回客户端。不同颜色区分了通用安全中间件、认证中间件和业务处理器。
决策指南:何时必须修改请求头与返回包?
你需要修改请求头的情况很明确:当你要传递身份凭证(Authorization)、告知服务器你期望的内容格式(Accept)、追踪请求链路(X-Request-ID)、或者需要模拟特定客户端(User-Agent)时,就必须在请求中设置相应的头。替代方案是用 Cookie 传递身份(本质也是请求头),或者将信息放在 URL 查询参数中,但查询参数会暴露在浏览器历史、服务器日志中,不适合敏感数据,且长度受限。
修改响应头和状态码则是服务端的必备技能。必须修改的场景包括:
- 根据业务结果返回正确的状态码(2xx/4xx/5xx),这是 API 设计的基本要求。
- 控制客户端缓存,使用
Cache-Control、ETag等头。 - 设置安全策略,如
Content-Security-Policy、X-Frame-Options、Strict-Transport-Security(HSTS),这些在现代 Web 应用中是不可或缺的。 - 引导客户端重定向(3xx + Location 头)。
- 通过
Set-Cookie在客户端存储状态。
替代方案是依赖服务器的默认头,但默认头往往缺乏安全考虑(如可能泄露服务器版本),且无法实现精细化控制。因此,对于生产环境,强烈建议至少使用 helmet 这样的中间件统一设置安全头,并根据业务需求定制状态码和缓存头。
总而言之,请求头和返回包是 HTTP 对话的“元数据”,它们和方法、状态码共同构成了 Web 通信的骨架。掌握它们的修改方法,不仅能让你构建出功能完备的接口,更是迈向安全开发的第一步。现在,你可以打开终端,动手试试用 curl 或写一小段代码,观察头的变化,逐步加深理解。
数据包分析-红队攻击工具&蓝队流量研判
想象一下,你是一名快递公司的安全主管,每天有成千上万的包裹(数据包)在分拨中心流转。红队就是那些试图混入假包裹或违禁品的“渗透测试员”,他们会用特殊的包装手法(攻击工具)、伪造的面单信息(流量特征)来测试你的安检能力。而蓝队,就是你在监控室里盯着屏幕的安检专家,你的任务是从海量流转的包裹中,通过扫描仪图像(流量数据)快速识别出那些异常包裹,判断它来自哪个团伙、用了什么手法、企图运到哪里,这就是“数据包分析-红队攻击工具&蓝队流量研判”。上一讲我们聚焦于单个 HTTP 请求和响应的“书信格式”,这一讲我们将视角拉高,观察一整段网络会话的“攻防录像”,学习如何从流量中还原攻击者的每一个动作。
数据包分析:网络世界的“黑匣子”与“X光机”
数据包分析解决的核心问题,是在网络攻击发生后,回答“三个W”:谁(Who)攻击了我们?用了什么工具(What tool)?做了哪些操作(What action)?这就像飞机失事后寻找黑匣子,通过分析飞行数据记录来还原事故经过。在日常运维中,我们只能看到服务器日志里的 IP 和状态码(就像上一讲学的响应头和状态码),但日志不会记录攻击者传输的恶意文件内容,也不会记录加密隧道里具体的命令交互。数据包分析,就是让我们有机会看到“快递包裹”里到底装的是什么——是明文传输的“whoami”命令,还是加密后的 C2 心跳包。
在系统结构中,数据包分析工具(如 Wireshark)位于网络协议栈的“最底层”,它能捕获网卡上流经的原始电信号,并将其解析为从物理层到应用层的完整数据。它与我们上一讲的“请求头&返回包”是什么关系?上一讲我们关注的是构造请求和解析响应,是“写信”的规范;而数据包分析是“读信”的逆向过程,并且能读取到 TCP 三次握手、IP 分片、TLS 握手等传输层和网络层的细节,这些在浏览器的开发者工具里是看不到的。举个例子,当你用 Burp Suite(一个 Web 代理工具)抓包时,它只能看到 HTTP/HTTPS 层,而 Wireshark 能看到底层的 TCP 序列号、窗口大小,甚至能检测到 TCP 会话劫持。
为什么必须学会数据包分析?因为红队工具越来越狡猾。比如 Cobalt Strike(简称 CS)的流量可以伪装成正常的 HTTPS,如果你只依赖 Web 日志,看到的只是一堆 200 OK 的加密流量,根本无法判断是用户正常浏览还是攻击者在远程执行命令。只有通过流量分析,结合 JA3 指纹、心跳包间隔、证书特征等,才能从加密流量中揪出“披着羊皮的狼”。
Mermaid 图表:数据包分析在网络安全体系中的位置
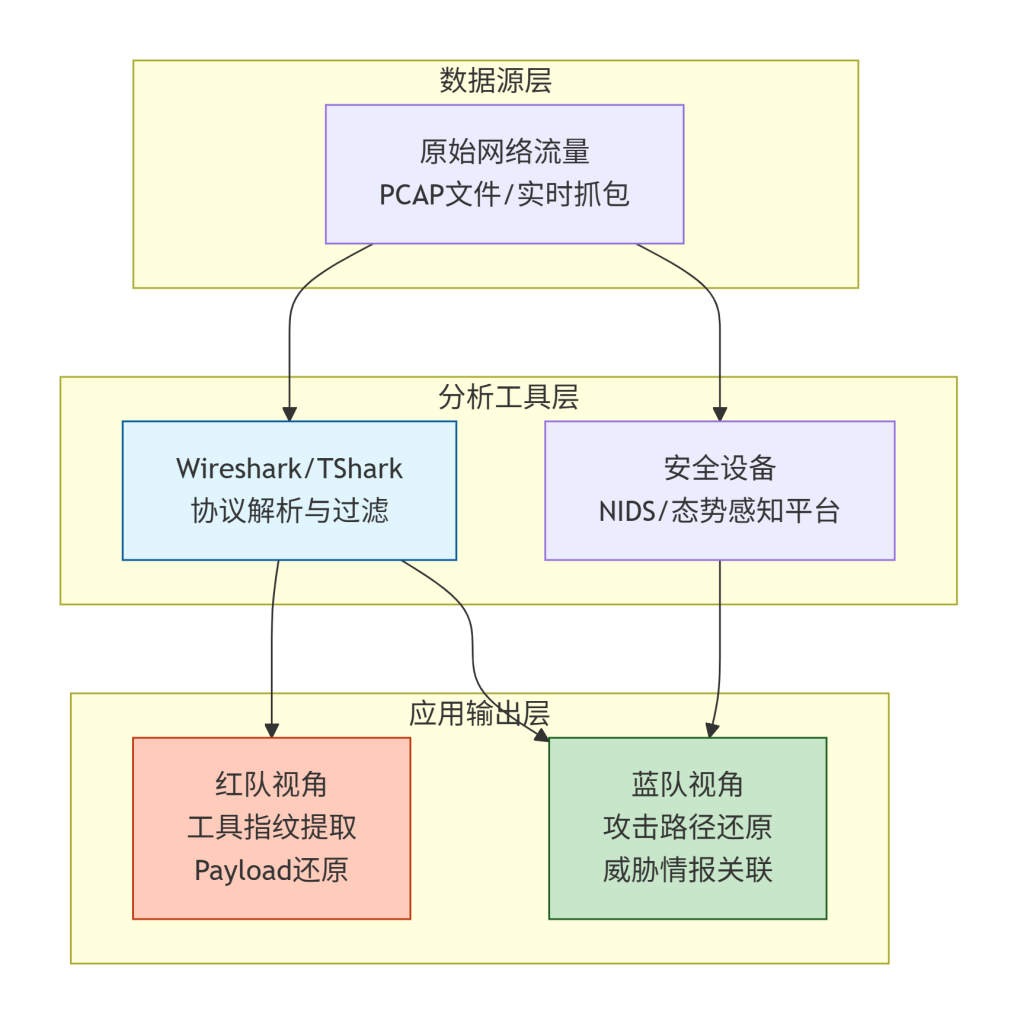
这张图展示了数据包分析的层级结构。最底层是原始流量,可以是实时抓取或保存的 PCAP 文件。中间层是分析工具,Wireshark 负责深度协议解析,而 NIDS(如 Snort)负责自动告警。最上层是应用输出:红队用分析结果优化工具特征(如修改 CS 的默认证书),蓝队则用其还原攻击链、关联威胁情报。蓝色代表通用工具,橙色代表红队用途,绿色代表蓝队用途。
红队攻击工具流量特征:识别攻击者的“签名”
红队工具五花八门,但无论怎么隐藏,只要产生网络流量,就一定会留下“签名”。这些签名可能藏在 TLS 证书的颁发者字段里,可能藏在 HTTP 头的顺序里,甚至藏在加密流量的包长度规律里。识别这些签名,就是蓝队研判的核心。
常见红队工具及其流量指纹
先从最基础的工具说起。Nmap 是一个端口扫描器,它的 SYN 半开扫描会在短时间内产生大量源 IP 相同、目标端口递增的 TCP SYN 包,没有完整的三次握手,这种流量模式很容易被 IDS 检测到。SQLMap 是一个自动化 SQL 注入工具,它的流量特征通常包括大量的布尔查询、时间延迟注入的明显响应时间差,以及 User-Agent 默认值(如 “sqlmap/1.6”),不过红队通常会修改 UA,所以更隐蔽的特征是请求参数中大量的数学运算(如 2*3、4-2)用于判断注入点。
真正让蓝队头疼的是 Cobalt Strike (CS) 和 Metasploit (MSF) 这类远控工具。CS 的默认 HTTPS 监听器有非常明显的特征:证书的颁发者(Issuer)字段通常包含 “cobaltstrike” 字样,或者使用默认的 Java Keystore 生成的证书,其指纹(如 38:8C:9E:D1:0A:8D:73:2C:…)是公开的。此外,CS 的 Beacon 默认心跳间隔是 60 秒,且心跳包通常是固定的长度和结构,比如一个 GET 请求,URI 是 /pixel.gif 这类看似正常的路径,但如果你在 Wireshark 里设置 http.time_delta > 50 过滤出响应间隔超过 50 秒的包,就能把这些“慢心跳”揪出来。更高级的是,红队会使用 Malleable C2 Profiles 彻底改造流量特征,比如把 Beacon 通信伪装成 Microsoft Update 的流量,包括修改 UA 为 “Windows-Update-Agent”,修改 POST 的数据格式为 XML 等等。
对于 MSF,其默认生成的 Meterpreter Payload 在 reverse_http 模式下,流量中有固定的 “Firefox” UA 头(即使是在 Windows 上),而且初始的几轮 GET/POST 请求的 URI 是随机字符串,但长度和结构有规律。MSF 自带的 SSL 证书也是公开特征,如果你看到某个 HTTPS 流量的证书序列号是特定的值,或者证书详情里出现 “Metasploit”,基本可以断定是 MSF 在通信。
红队如何修改特征:对抗蓝队研判
为了躲避检测,红队会花大量精力做“反溯源”和“流量加密”。以 CS 为例,他们会用 keytool 命令重新生成证书,将证书的 CN(Common Name)改为 www.baidu.com 这种正常域名,有效期改为 1 年,消除原有的特征。还会通过编写 Profile 文件修改心跳包的 URI、Cookie 的字段名,甚至把 C2 流量藏到 CDN 后面,让蓝队追踪到的 IP 是 Cloudflare 的节点,而非真正的服务器。
MSF 则可以通过 auxiliary/gather/impersonate_ssl 模块,直接从百度等正规网站克隆一个证书,加载到监听器中,这样流量加密层的证书就和正常网站一模一样,证书指纹告警就会失效。此外,红队还会用 DNS Tunnel 技术,把数据切分成小块,塞进 DNS 的 TXT 记录查询里,因为防火墙通常会放行 DNS,这种流量如果不做深度内容检查,很难发现有人在用 DNS 传输数据。
Mermaid 图表:红队工具流量特征的对抗演化
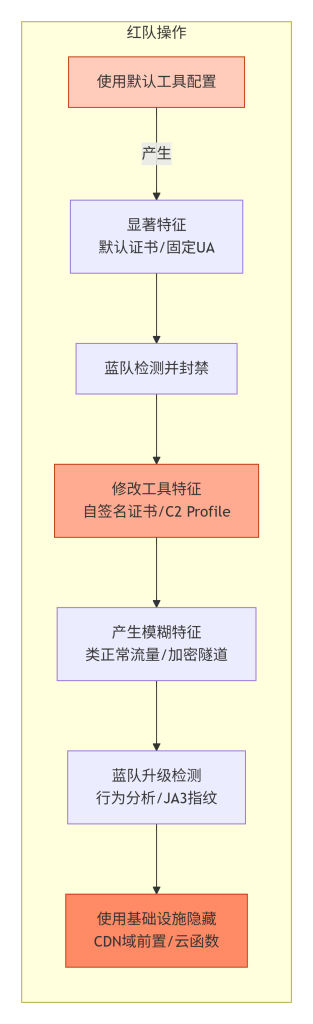
这张图展示了红队与蓝队在流量特征上的“军备竞赛”。从左到右:红队从使用默认工具(产生明显特征),到蓝队检测并拦截,倒逼红队修改特征(如替换证书),使流量趋近正常。蓝队随之升级检测手段到行为分析,红队则进一步利用 CDN 等基础设施隐藏真实 IP。颜色深浅代表对抗的升级层次。
蓝队流量研判:Wireshark实战与攻击还原
作为蓝队,我们拿到一个 PCAP 文件后,怎么从海量数据包中找到那根“针”?核心方法论是:先宏观,后微观。先用统计工具看整体轮廓,再过滤出可疑会话逐包分析。
第一步:宏观分析——协议分级与会话统计
用 Wireshark 打开捕获文件后,先不要急着翻包。点击 统计 -> 协议分级,这里会显示各种协议的比例。如果一个 PCAP 里 ARP 协议占比异常高,可能是内网扫描;如果 HTTP 占比极少,而 HTTPS 流量占 90% 以上,那就要重点看看这些 TLS 流的证书和 SNI(服务器名称指示)。接着点击 统计 -> 会话,可以按 IPv4 地址对排序,查看哪个 IP 对之间通信量最大、连接数最多。如果内网一台服务器对公网某个 IP 产生了大量长连接,且上下行字节数不对称(比如上行很小,下行很大,可能是下载数据;或者上行很大,下行很小,可能是数据泄露),这就是高危线索。
第二步:过滤可疑流量——精准定位攻击
根据上一讲的请求头知识,我们可以构建强大的过滤表达式。假设怀疑有 SQL 注入,可以用 http.request.uri matches ".*(select|union|insert).*" 过滤出 URI 里包含 SQL 关键字的请求。如果怀疑是 WebShell 通信,比如蚁剑的流量,其 POST 数据通常经过 base64 编码,并且有固定的参数名(如 cmd),可以用 http.request.method == "POST" && http contains "cmd" 来过滤。对于反弹 shell,比如用 NC(Netcat)反弹的明文 shell,流量特征非常明显:在一段 TCP 流中,能看到客户端发送的命令(如 whoami),紧接着服务器返回命令结果,完全明文。过滤时可以尝试 tcp contains "whoami" 或 tcp contains "/bin/sh" 这类关键词。
举一个具体场景:分析一个 NC 反弹 shell 的数据包。受害者 IP 192.168.1.100 主动连接攻击者 IP 192.168.1.200 的 8888 端口。在 Wireshark 中过滤 ip.addr == 192.168.1.200 and tcp.port == 8888。跟踪 TCP 流(右键 -> 追踪流 -> TCP Stream),你会看到类似下面的交互:
whoami
desktop-abc\user
ipconfig
Windows IP Configuration
...(网络配置信息)这就是典型的明文反弹 shell 特征。而如果是加密的 C2 流量,比如 CS 的 Beacon,你追踪 TCP 流看到的会是乱码,但可以通过 TLS 握手细节 来判断:查看服务器的证书,如果证书的 CN 是随机字符串,或者颁发者是 unknown,并且 JA3 指纹(一种 TLS 客户端指纹)匹配已知恶意指纹库,就高度可疑。
第三步:提取与验证——还原攻击载荷
当发现可疑的 HTTP 流量下载了一个 .exe 或 .zip 文件,我们可以用 Wireshark 的 导出对象 功能。点击 文件 -> 导出对象 -> HTTP,会列出所有 HTTP 传输的文件,可以直接保存下来。保存后用杀毒软件扫描,或者上传到微步在线、VirusTotal 等威胁情报平台进行分析。对于 SMB 协议传输的恶意文件,也可以导出对象。
最容易踩的坑:第一个是流量太大时忘了用显示过滤器,直接在数千个包里翻找,结果眼花了也没找到;第二个是遇到加密流量直接放弃,其实加密流量也可以分析——看证书、看握手时的 SNI 域名、看流量的包长度序列(心跳包通常大小固定)、看时间间隔;第三个是忽略时间戳,攻击者往往在凌晨行动,通过 视图 -> 时间显示格式 调整到合适格式,按时间排序,找到异常流量爆发的时刻,再倒推回去分析。
验证方法:当你怀疑某条流是恶意软件回连时,可以在威胁情报平台查询目的 IP,看是否被标记为“C2 Server”或“恶意主机”。也可以提取流量中的域名,查询其历史 DNS 解析记录和 Whois 信息,如果域名刚注册一个月,且注册信息隐藏,嫌疑就很大。
下一步操作建议:完成流量研判后,如果是应急响应,应立即在防火墙上封锁 C2 的 IP,并在终端上隔离受害主机。同时,将 IOC(威胁指标,如 IP、域名、JA3 指纹)输入到全流量设备或 EDR 中,进行全网历史数据回扫,看是否有其他主机已经被感染。
Mermaid 图表:蓝队流量研判的标准流程
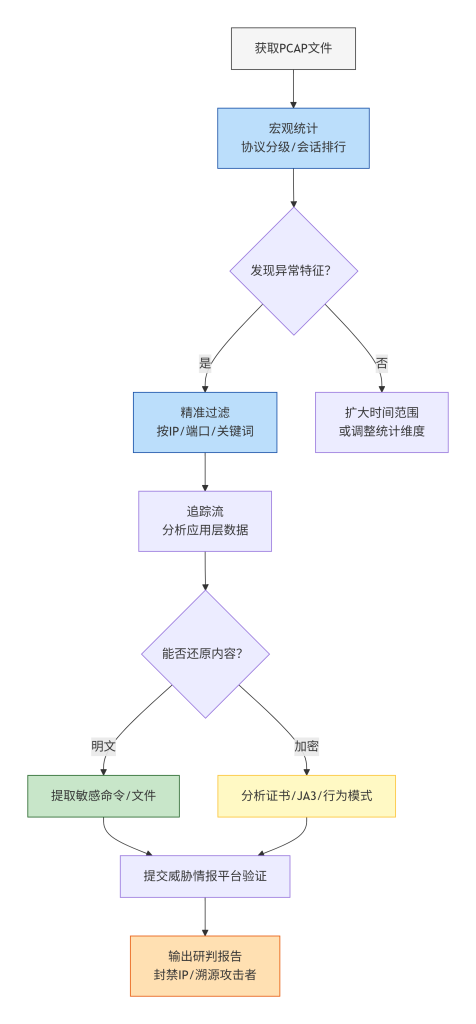
这张图是蓝队流量研判的标准操作流程。从拿到 PCAP 文件开始,先做宏观统计定位可疑 IP 或协议,再通过精准过滤缩小范围,然后追踪流查看应用层数据。根据是否加密分两条路径处理,最后都将可疑信息提交威胁情报平台验证,形成最终的封禁或溯源决策。蓝色代表分析步骤,绿色代表明文处理,黄色代表加密处理,橙色代表输出动作。
决策指南:何时必须做数据包分析?
作为开发者或运维,你必须进行数据包分析的情况主要有三种:
第一,告警确认。当 EDR、态势感知平台或 WAF 发出高危告警(如“WebShell 通信”、“Cobalt Strike 回连”),你需要下载原始 PCAP 包进行人工复现,确认是否误报,并还原攻击路径。这是蓝队的日常核心工作。
第二,日志不足时溯源。如果服务器被入侵,但系统日志被清除,只剩下网络设备里的 NetFlow 或抓包文件,那么数据包分析就成了唯一能还原攻击者手法的途径。你可以通过分析找到攻击者上传的 WebShell 文件名、下载的木马,甚至通过 HTTP 头里的 X-Forwarded-For 找到攻击者的真实 IP。
第三,0day 漏洞捕获。当怀疑遭受未知漏洞攻击,但安全设备没有规则时,通过抓取进出服务器的全流量,在事后用 Wireshark 逐包分析异常的 payload 结构,可以逆向出攻击代码。
什么情况下替代方案够用?如果只是排查应用层的访问异常,查看 Web 服务器日志(access log)和错误日志通常是更快的选择,因为它们已经提供了请求方法、状态码、响应时间等结构化信息。另外,如果公司部署了 NTA(网络流量分析)设备,它们会自动提取流量元数据并做威胁检测,日常监测可以依赖这些平台的告警,只有深入调查时才需要手动数据包分析。
总之,数据包分析是网络安全领域的“底层能力”,它让你从依赖告警的“被动防御者”,成长为能看见攻击者每一个动作的“主动溯源者”。结合上一讲的请求头知识,你现在已经能读懂 HTTP 的“书信内容”,又能从数据包层面看见“邮差送信的全过程”——这两者结合起来,你就能在构建安全应用时,既考虑正确的语义,又能预判攻击流量可能出现的痕迹。
数据包构造-Reqable自定义添加修改请求
如果说上一讲的“数据包分析”是让你成为能看懂监控录像的安保专家,那么这一讲的“数据包构造”就是让你成为能自己编写剧本的导演。你不再是被动地观察流量,而是主动地构造请求,去测试服务器的反应、复现漏洞、或者调试接口的边界情况。这就像厨师做菜时不仅要会品尝(分析),更要会根据口味调整佐料(构造)。Reqable(江湖人称“小黄鸟”)就是这样一把让你随心所欲“调制”HTTP数据包的瑞士军刀——它既能抓包分析,更强大的功能是让你自定义构造请求、修改请求头和请求体,甚至编写脚本自动化处理流量。
Reqable:HTTP数据包的“调试工作台”
Reqable解决的核心问题,是让开发者能够像程序员调试代码一样,单步调试HTTP请求。在实际开发中,你可能会遇到这样的场景:后端接口文档说“传这个参数会返回特定数据”,但你用浏览器访问时却总是报错;或者你怀疑某个请求头(比如Authorization)写错了,但不想重新编译整个前端应用去测试。这时候,你就需要一个工具能让你自由地组合请求方法、URL、请求头、请求体,像搭积木一样拼出一个数据包,然后立刻发送出去看服务器反应。Reqable就是这样一个工具,它把“构造-发送-分析-修改-重发”的闭环集成在一个界面里,让你能像调试代码一样调试HTTP协议。
在系统结构中,Reqable扮演了两个角色:正向代理和HTTP客户端。作为代理,它处于客户端(浏览器/APP)和服务器之间,可以拦截并修改流量(这是上一讲“数据包分析”的场景);作为HTTP客户端,它直接替代浏览器向服务器发送请求,你可以完全控制请求的每一个字节。这与我们第一讲学的内容一脉相承:第一讲我们是用代码(fetch、axios)构造请求,那是“编程式”的;而用Reqable构造请求,是“可视化”的——你不再需要写代码,只需点点鼠标就能生成一个完整的HTTP数据包。
为什么需要这样一个工具?因为在实际的安全测试和接口调试中,手动修改代码再运行的过程太慢了。比如你想测试一个API在缺少某个请求头时的行为,如果用代码改,得修改源码、重启服务、重新发送,而用Reqable,你只需要在界面上删除那个请求头,点击“发送”,一秒后就能看到服务器的返回。这种即时反馈的“试错”体验,能极大提升开发和测试效率。
Mermaid 图表:Reqable在HTTP交互中的角色定位
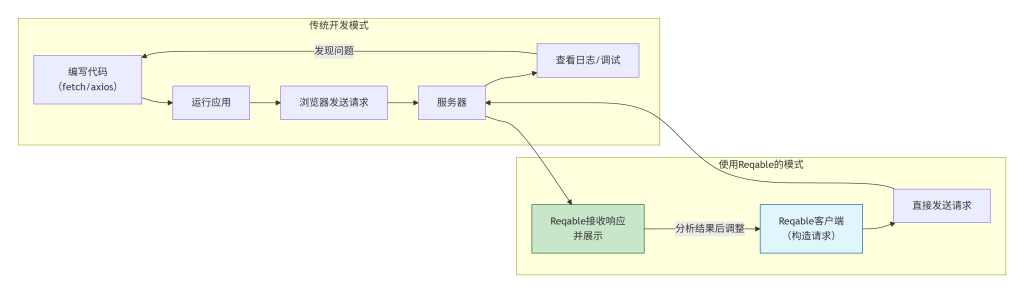
这张图对比了传统开发调试模式和用Reqable构造请求的模式。上方传统模式需要在“编写代码-运行-查看日志”之间多次循环;下方Reqable模式则直接构造并发送请求,根据响应即时调整,闭环更短、反馈更快。蓝色代表构造环节,绿色代表分析环节。
Reqable构造请求:像填表一样组装HTTP数据包
Reqable的请求构造界面,本质上是一个可视化的HTTP数据包编辑器。它把请求行、请求头、请求体拆分成清晰的选项卡,让你逐项填写。我们来看看怎么用它自定义添加和修改请求。
第一步:选择请求方法与输入URL
打开Reqable,你会看到一个简洁的界面。顶部是请求地址栏,你可以在这里输入完整的URL,比如 https://api.example.com/users。左侧下拉菜单可以选择请求方法——GET、POST、PUT、DELETE等,Reqable支持标准的9种HTTP方法,甚至支持自定义方法名,比如你可以输入 HELLO 这种非标准方法,这在测试某些奇葩服务器实现时很有用 。
第二步:修改请求头——表格模式与文本模式
点击“Headers”选项卡,你就进入了请求头编辑区。这里有两种模式:表格模式和文本模式。
表格模式是最直观的,它像Excel表格一样,每一行是一个请求头字段,左边写Key(如 Content-Type),右边写Value(如 application/json)。你可以随意添加、删除、修改行。Reqable还很贴心地提供了内置请求头功能,默认情况下它会自动填充必要的请求头如 Host、User-Agent、Connection 等,这些内置头以灰色显示,你可以点击小眼睛图标显示或隐藏它们 。如果想修改内置头(比如把默认的 User-Agent: Reqable/版本号 改成浏览器的UA),直接点击带锁图标的字段旁边的值,解锁后即可修改 。如果需要批量添加或修改,可以切换到文本模式,这里所有请求头以纯文本形式展示,你可以一次复制粘贴多行 。特别的是,你可以在某一行前面加 // 来注释掉这个请求头,相当于临时禁用但不删除,方便来回对比测试 。
假设我们要模拟一个移动端APP的登录请求,需要添加 Authorization 头和自定义的 X-APP-Version 头。在表格模式下,我们直接新增两行,效果如下 :
// 示例请求头
{
"Content-Type": "application/json",
"Authorization": "Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9...",
"X-APP-Version": "3.2.1"
}第三步:构造请求体——支持多种数据格式
点击“Body”选项卡,这里才是Reqable的精华所在。它支持JSON、文本、XML、表单(Form)、Multipart、文件六种请求体类型 。选择不同的类型,Reqable会自动帮你设置对应的 Content-Type 请求头,比如选JSON就会自动加上 Content-Type: application/json 。
- JSON类型:编辑器自带语法高亮和格式化,你直接写JSON对象,比如
{"username":"admin","password":"123456"}。如果不想用自动添加的Content-Type,可以取消勾选内置的Content-Type,然后手动添加一个新的覆盖它 。 - 表单类型:用于
application/x-www-form-urlencoded格式的数据,界面变成键值对输入,适合模拟网页表单提交。 - Multipart类型:这是最强大的,支持在一个请求体里混合文本和文件。你可以添加一个“文本分部”写普通字段,再添加一个“文件分部”上传本地图片,Reqable会自动生成正确的boundary分隔符 。这在测试文件上传接口时极其方便。
- 文件类型:直接把文件拖拽进去,Reqable会根据文件类型自动推导
Content-Type,比如传.png文件就设为image/png。
第四步:发送请求并查看响应
填好所有信息后,点击右上角的大“发送”按钮。Reqable会立刻将你构造的数据包发出去,并在下方区域展示完整的响应:状态码、响应头、响应体。响应体会根据格式自动格式化(JSON会缩进高亮),你可以一目了然地看到服务器返回了什么 。如果结果不对,你可以直接在上面的请求区域修改参数,再次发送,整个过程没有编译、没有重启,纯粹是“所见即所得”的调试体验。
Mermaid 图表:Reqable构造请求的核心功能模块
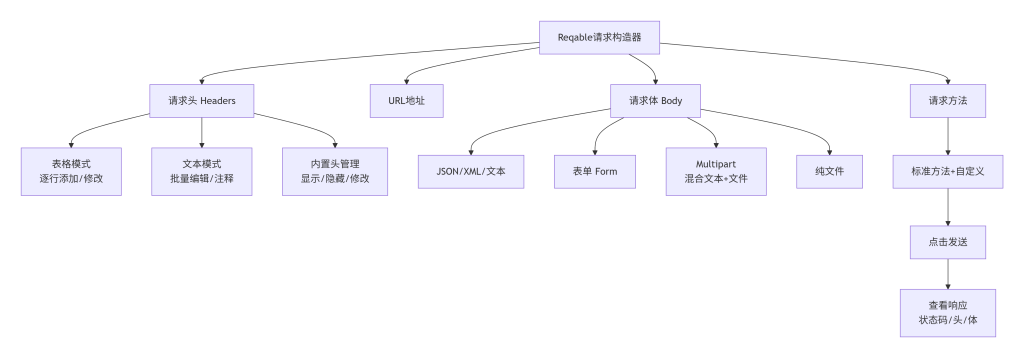
这张图是Reqable请求构造功能的思维导图。从请求构造器出发,分支出请求方法、URL、请求头、请求体四大模块。请求头下有表格/文本/内置头管理三种操作方式;请求体下有六种数据格式;最终汇聚到点击发送并查看响应。这完整展示了Reqable作为可视化HTTP客户端的能力边界。
实战场景:用Reqable复现接口漏洞测试
理论说完了,我们来一个真实的场景:假设我们要测试一个存在越权漏洞的API。正常用户A只能查看自己的资料,但通过修改请求参数,有可能查看到用户B的资料。用Reqable我们可以这样操作。
- 构造正常请求:先正常登录APP,用浏览器开发者工具复制出一个完整的请求。但我们现在用Reqable从头构造。方法选
GET,URL填https://api.example.com/user/profile。在Headers里添加Authorization: Bearer 用户A的token。点击发送,响应里返回了用户A的资料,状态码200。 - 修改参数测试越权:根据经验,很多越权漏洞发生在参数上,比如 URL 改成
https://api.example.com/user/profile?user_id=1002。我们直接在URL后面加上查询参数,再次发送。如果服务器返回了用户B的资料,说明存在越权——它只校验了token有效性,但没有校验token对应的用户ID和请求的user_id是否一致。 - 修改请求方法测试:有些接口对GET做了权限校验,但对POST却疏忽了。我们把方法从GET改成POST,URL不变,在Body里选择JSON,输入
{"user_id":1002}。发送后看状态码,如果是200且返回了用户B资料,恭喜你发现了一个高危漏洞。 - 修改请求头绕过限制:有的API会检查
Referer或Origin头,只允许来自特定域名的请求。我们可以在Headers里添加Referer: https://admin.example.com试试,或者修改User-Agent为Googlebot模拟搜索引擎爬虫,看服务器是否区别对待。
这个过程中,Reqable的价值在于:你可以在几秒钟内尝试各种组合——改参数、改方法、改头、改体,然后立刻看到服务器的状态码和返回内容。相比写代码循环测试,这种手动探索的效率要高得多。
进阶玩法:Reqable脚本实现自动化修改
如果你觉得每次手动点太麻烦,Reqable还提供了脚本功能,让你用Python编写脚本自动修改请求和响应 。这和我们第二讲“蓝队流量研判”正好相反——蓝队是用脚本自动化分析流量,红队是用脚本自动化构造或篡改流量。
脚本功能位于Reqable的“脚本”面板,你可以创建规则,匹配特定的URL,然后编写 onRequest 和 onResponse 函数。例如,你想自动给所有发往 api.example.com 的请求加上一个调试头 X-Debug: true,可以这样写 :
from reqable import *
def onRequest(context, request):
# 给请求头添加自定义字段
request.headers['X-Debug'] = 'true'
# 打印日志,在Reqable控制台可以看到
print(f"正在请求: {request.url}")
return request
def onResponse(context, response):
# 可以在这里修改响应内容
return response启用脚本后,所有匹配的请求都会自动加上这个头。更高级的玩法包括:用脚本实现自动登录并替换token、根据响应内容决定是否阻断请求(返回 None 即可中断)、甚至统计特定域名的请求次数并写入文件 。这就相当于给Reqable装上了自动化引擎,让你能编写复杂的测试逻辑。
最容易踩的坑:脚本依赖本地Python环境,Reqable要求Python版本大于3.6 。如果你电脑装了多个Python,需要在Reqable的设置里手动指定Python解释器路径,否则脚本不会生效且没有任何提示,这是新手最容易困惑的地方。另外,onRequest 和 onResponse 运行在不同的进程中,不能直接共享全局变量,但可以通过 context.shared 来传递数据 。
验证方法:写好脚本后,在Reqable的脚本编辑器里打开调试控制台,发送请求后看控制台是否有 print 输出的日志,如果有说明脚本执行成功。同时可以在抓包列表里点击请求,查看详情里的请求头是否被正确修改。
下一步建议:学会构造请求后,可以结合第一讲的状态码知识,用Reqable批量测试API的容错性——比如故意发送格式错误的JSON、超长的参数、SQL注入payload,观察服务器返回的状态码是400还是500,是200还是403,这些状态码能告诉你服务器的健壮性和安全防护水平。
决策指南:什么时候必须用Reqable构造请求?
你需要用Reqable这类可视化请求构造工具的场景主要有三个:
第一,接口调试阶段。当后端写好接口,前端还未开发时,你需要验证接口是否工作。用Reqable可以快速发送各种参数组合,而不必等待前端页面完成。
第二,漏洞挖掘与安全测试。无论是白盒测试还是渗透测试,你都需要尝试各种边界情况和畸形输入。Reqable能让你灵活修改请求的任何部分,而且能看到服务器原始的返回(不受浏览器或APP逻辑干扰)。
第三,复现线上问题。当用户报障说某个功能不能用,但日志里看不出问题时,你可以用Reqable精确构造出用户可能触发的请求,复现bug,从而定位是前端参数错误还是后端逻辑缺陷。
什么情况下替代方案够用?如果你只需要发送简单的GET请求查看返回,浏览器地址栏就够了。如果你需要编写自动化测试脚本,Postman或写代码(Python requests)可能更适合批量运行。但当你需要“探索式测试”——一边观察响应一边调整参数——Reqable这种可视化即时反馈的工具,是最高效的。
从第一讲学习HTTP数据包结构,到第二讲学会分析流量,再到这一讲能够自己构造数据包,你已经完成了从“理解者”到“使用者”再到“操控者”的三级跳。接下来,你可以把这三讲的知识融会贯通:用Reqable构造攻击请求,用Wireshark抓包分析流量特征,再看服务器返回的状态码和响应头——这正是一个安全测试工程师的日常。