算法类型-单向散列&对称性&非对称性
我们先从生活里最常见的需求聊起。你给朋友发一封邮件,希望邮件内容不被别人偷看,这需要保密性;你下载一个软件安装包,担心它被黑客篡改植入病毒,这需要完整性;你收到自称是银行发来的通知,如何确认它真的是银行发的而不是钓鱼,这需要身份验证。在计算机系统里,这三种需求分别由三类基础算法解决:单向散列保证完整性,对称加密保证保密性,非对称加密既保证保密性又能完成身份验证。它们各司其职,又常常组合使用,构成了现代网络安全的基石。
单向散列:数据的指纹
它解决什么问题? 生活里,快递包裹贴了封条,签收前你可以检查封条是否完好,以此确认包裹在运输途中没有被打开过。单向散列(也叫哈希函数)就是数据的封条。它把任意长度的数据(比如文件、密码)压缩成一段固定长度的短字符串,称为散列值或摘要。只要原始数据有任何一点点改动,重新计算出的散列值就会面目全非(雪崩效应)。所以,通过对比事先保存的散列值,就能判断数据是否被篡改。
它在系统中处于什么位置? 哈希函数通常部署在数据存储层或网络传输层的一侧。比如在文件下载服务器上,管理员预先计算好文件的SHA256值并公布在官网;用户下载完文件后,在本地重新计算哈希,并与官网公布的值对比。在密码存储场景里,系统不保存用户的明文密码,只保存密码的哈希值,登录时把用户输入的密码再次哈希后比对。
它具体怎么工作,为什么这样设计? 哈希函数内部通过复杂的位运算、压缩函数、迭代结构(如Merkle-Damgård或海绵结构)将输入数据打乱、混合,最终产生固定长度的输出。这种设计保证了三个核心特性:单向性(无法从哈希值倒推出原始数据)、抗碰撞性(极难找到两个不同数据拥有相同哈希值)、敏感性(输入变一位,输出变一半)。单向性是密码存储的基础,抗碰撞性保证了没人能伪造一个“替身文件”蒙混过关。
实际常用的实现工具? 早期流行的MD5、SHA-1如今已被证明不安全,容易发生碰撞攻击,坚决不能再用。现在主流是SHA-2家族(如SHA-256、SHA-512)和SHA-3。SHA-256输出256位,是目前最通用的选择。在密码存储场景,我们通常不直接对密码用简单哈希,而是使用加盐的慢哈希算法如bcrypt、PBKDF2、Argon2,它们能抵抗暴力破解和彩虹表攻击。
典型真实场景 + 可复制的配置示例
你从网上下载一个Linux发行版的ISO镜像,官网通常会提供CHECKSUM文件,里面记录了镜像的SHA256值。假设你下载了ubuntu.iso,在Linux终端可以用如下命令验证:
# 计算本地文件的SHA256哈希值
sha256sum ubuntu.iso
# 输出类似:a1b2c3... ubuntu.iso
# 人工比对官网给出的值,或者用 -c 选项自动比对
echo "a1b2c3... ubuntu.iso" > checksum.txt # 假设官网的值写入文件
sha256sum -c checksum.txt # 自动比对,输出"ubuntu.iso: OK"第一行命令计算哈希,输出十六进制串和文件名;第二、三行把期望值存到文本文件,用-c让命令自动检查,匹配则显示OK。这个过程确保了下载的镜像是未经篡改的原始版本。
最容易踩的坑、验证方法、下一步联动
最常踩的坑是直接对用户密码使用简单哈希,比如只存MD5(password)。这极易被彩虹表破解。正确做法是使用加盐的慢哈希,比如PHP的password_hash()默认自动生成盐并用bcrypt。验证方法永远是用同样的算法对同样的输入计算,然后比对输出。下一步,哈希常与加密算法联动:比如在数字签名里,先对消息哈希生成摘要,再用私钥对摘要签名,这样能极大提升效率。
本模块决策指南
当你需要检查数据完整性(如文件校验、软件更新)或安全存储密码时,必须使用单向散列。对于密码存储,请直接使用专业的慢哈希函数(bcrypt/Argon2),而不是自己拼凑加盐SHA。如果只是防意外损坏而非恶意篡改,简单的CRC校验可能就够用,但安全性场景必须用密码学哈希。
Mermaid 图表:单向散列计算流程

这张图里,左侧的“输入数据”代表任意长度的原始信息,中间的“单向散列函数”是一个数学黑盒(比如SHA-256),它执行压缩和混淆,右侧输出固定长度的十六进制串作为数据的“指纹”。箭头表示数据流动方向,强调输入到输出的单向性,无法反向。
对称加密:同一把钥匙开同一把锁
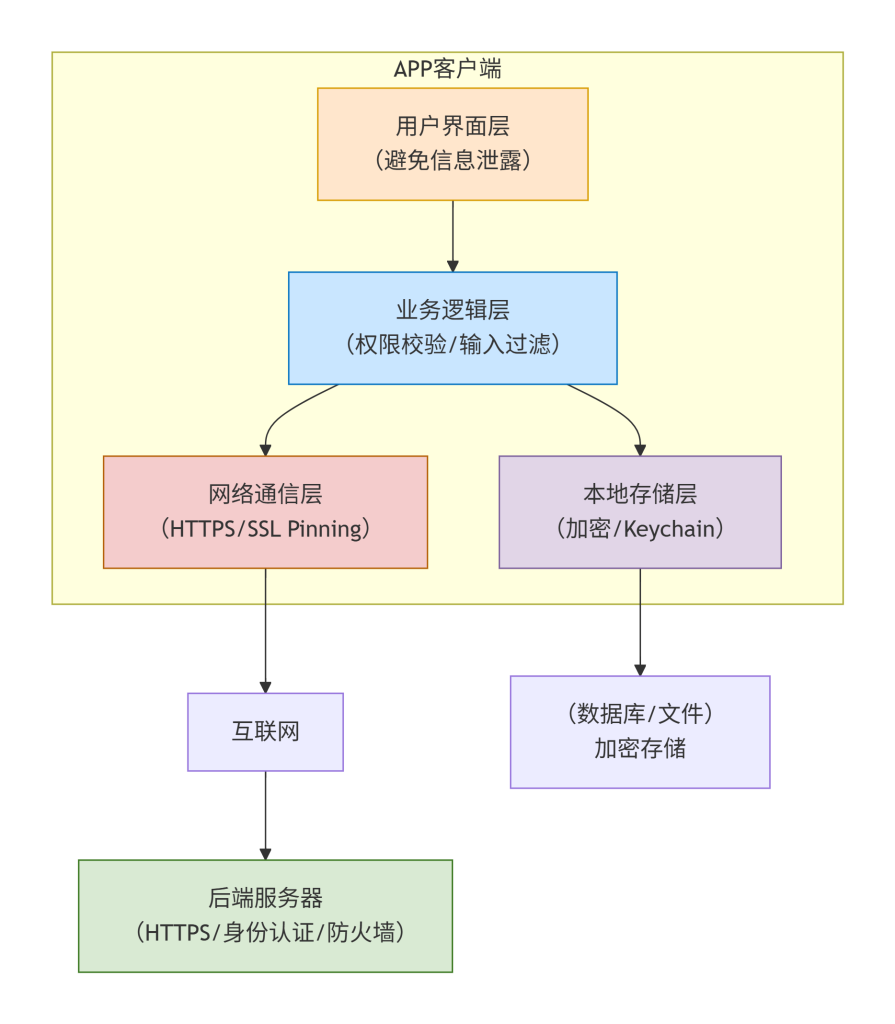
它解决什么问题? 你和朋友想互相写密信,又不希望邮差偷看。最简单的办法是两人共有一把相同的钥匙,你用钥匙把信锁进箱子寄出,朋友收到后用同样的钥匙打开箱子。对称加密就是这种模式:加密和解密使用完全相同的密钥。它解决了数据的机密性问题,保证只有拥有密钥的人才能读懂内容。
它在系统中处于什么位置? 对称加密通常用于传输层(如TLS记录协议)或存储层(如全盘加密、数据库加密)。在HTTPS连接中,浏览器和服务器通过握手协商出一个临时的对称密钥(会话密钥),之后所有网页数据都用该密钥加密传输。因为对称加密速度快,适合大量数据。
它具体怎么工作,为什么这样设计? 对称加密算法分为分组密码(如AES)和流密码(如ChaCha20)。AES把数据分成固定大小的块(比如128位),用密钥对每个块进行多轮替换和置换操作(SubBytes、ShiftRows、MixColumns、AddRoundKey),最后输出密文。为了加密超过一块的数据,还需要引入工作模式,如CBC(密码分组链接)让每个块与前一个块关联,或GCM(伽罗瓦计数器模式)同时提供加密和完整性校验。设计成块操作和复杂轮函数是为了混淆和扩散,使密文与密钥、明文的关系极其复杂,抵御统计分析攻击。使用相同密钥是因为对称算法数学上高效,加解密速度快。
实际常用的实现工具? 目前最通用的对称加密标准是AES(高级加密标准),支持128/192/256位密钥。很多CPU内置AES指令集,硬件加速极快。ChaCha20是流密码,在移动设备上软件效率高,常与Poly1305搭配(如Google的TLS实现)。工具层面,OpenSSL库、Libsodium、各种编程语言的crypto库都提供现成的实现。
典型真实场景 + 可复制的配置示例
你想加密一个敏感文件file.txt,用AES-256-CBC加密,并设置密码。使用OpenSSL命令行:
# 加密:输入密码,生成密文file.enc
openssl enc -aes-256-cbc -salt -in file.txt -out file.enc -pass pass:YourPassword
# 解密:用相同密码还原file_dec.txt
openssl enc -aes-256-cbc -d -in file.enc -out file_dec.txt -pass pass:YourPassword第一行enc表示加密命令,-aes-256-cbc指定算法模式,-salt增加随机盐防止字典攻击,-in指定输入文件,-out输出密文,-pass提供密码(实际使用中应通过环境变量或文件避免命令行泄露)。第二行-d表示解密模式。加盐保证了同样的明文和密码每次加密结果不同,提高安全性。
最容易踩的坑、验证方法、下一步联动
最大的坑是密钥管理:如果密钥存在本地硬盘且被窃取,加密形同虚设;如果通过网络传输密钥,又面临被截获风险。正确做法是密钥仅保存在内存,或使用硬件安全模块(HSM)。验证方法就是解密后看内容是否一致。下一步,对称加密通常与非对称加密结合:用非对称加密安全地交换对称密钥,这就是混合加密(如HTTPS握手过程)。
本模块决策指南
当需要加密大量数据(文件、数据库、网络流)时,必须使用对称加密,因为它性能最优。如果只是临时、少量数据且密钥能通过其他安全方式传递(如面对面交换),对称加密也足够。但如果无法预先共享密钥,就必须引入非对称加密来协商密钥。
Mermaid 图表:对称加密流程
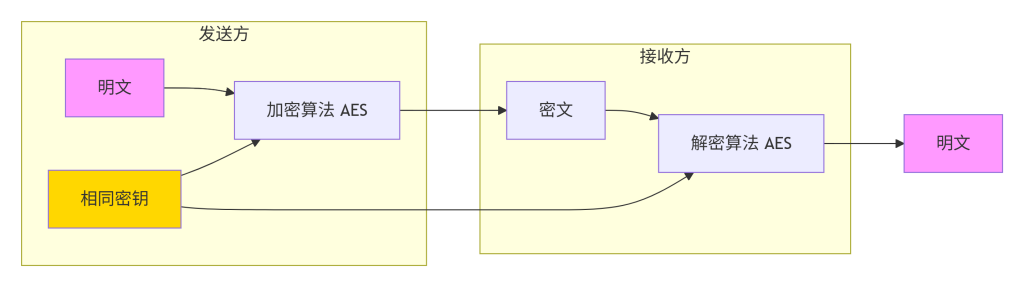
这张图展示了对称加密的全过程。发送方使用密钥K对明文进行AES加密生成密文,密文通过不安全的信道传输给接收方;接收方使用相同的密钥K对密文解密恢复出明文。黄色填充的“相同密钥”表示两处密钥必须完全相同,这是对称加密的核心特点。
非对称加密:公钥开锁,私钥上锁
它解决什么问题? 生活里你想给远方的朋友寄个保险箱,但你们之前没有共享过钥匙。朋友可以先寄给你一个打开的挂锁(公钥),你锁上箱子后寄给他,他用自己保留的钥匙(私钥)打开。非对称加密就是这种模式:公钥公开,任何人都能用公钥加密数据;私钥私有,只有拥有者能用私钥解密。它解决了在不安全信道上安全交换信息的问题,同时也能实现数字签名——用私钥签名消息,公钥验证签名,从而证明身份。
它在系统中处于什么位置? 非对称加密通常用于协议握手阶段(如TLS、SSH)、数字签名、证书体系(X.509)。它不用于加密大量数据(因为慢),而是加密少量关键信息,比如对称密钥或散列值。在HTTPS中,服务器证书携带公钥,浏览器用公钥加密一个随机数(预主密钥),服务器用私钥解密,双方再基于这个随机数生成对称会话密钥。
它具体怎么工作,为什么这样设计? 非对称加密基于数学难题,例如RSA基于大整数因数分解的困难性。RSA生成两个大素数,计算乘积n,再根据欧拉函数生成公钥(e, n)和私钥(d, n)。加密时,消息m表示为整数,计算c = m^e mod n;解密时,m = c^d mod n。这种设计保证了从公钥无法推导出私钥(因为不知道因数p、q)。ECC(椭圆曲线密码)基于椭圆曲线离散对数问题,密钥更短但安全性相当。之所以这样设计,是因为可以公开加密密钥而不泄露解密密钥,解决了密钥分发的千古难题。
实际常用的实现工具? 最广泛使用的是RSA(2048位及以上)和ECC(如NIST P-256、Curve25519)。在SSH、TLS、PGP中都能见到它们。具体实现常用OpenSSL、LibreSSL、Java的KeyPairGenerator、Python的cryptography库。数字签名常用RSA-PSS、ECDSA、Ed25519(后者更现代、更安全)。
典型真实场景 + 可复制的配置示例
你希望通过SSH登录服务器,不想每次输密码,而是用公私钥认证。首先生成密钥对:
# 生成RSA密钥对(默认2048位)
ssh-keygen -t rsa -b 4096 -f ~/.ssh/mykey
# 一路回车,会生成私钥 mykey 和公钥 mykey.pub
# 将公钥内容追加到服务器的 ~/.ssh/authorized_keys 文件中
ssh-copy-id -i ~/.ssh/mykey.pub user@server
# 登录时指定私钥
ssh -i ~/.ssh/mykey user@serverssh-keygen生成一对文件:mykey是私钥(必须严格保管),mykey.pub是公钥(可公开)。ssh-copy-id把公钥安全复制到服务器,之后登录时SSH客户端会用私钥签名一个挑战,服务器用公钥验证你的身份。这利用了非对称加密的数字签名功能。
最容易踩的坑、验证方法、下一步联动
常见坑包括:密钥长度过短(如1024位RSA已可破解)、随机数生成弱(导致私钥可预测)、中间人攻击(公钥被替换)。验证方法:用私钥解密一段用公钥加密的数据,或者用公钥验证签名。下一步,非对称加密需要与对称加密联动形成混合加密,以兼顾安全性和性能;同时需要公钥基础设施(PKI)来证明公钥确实属于声称的实体,防止中间人。
本模块决策指南
必须使用非对称加密的场景:密钥交换(双方无共享密钥)、数字签名(身份认证、不可否认性)、证书体系。如果双方已经通过其他安全方式共享了密钥,那么对称加密就能胜任,不需要引入非对称加密。非对称加密是混合加密的基石,单独使用时只能加密小块数据,不能替代对称加密进行大量数据加密。
Mermaid 图表:非对称加密(加密与签名)
-1024x140.png)
上图分两部分。上半部分是加密:发送方使用接收方的公钥对明文加密,接收方用自己的私钥解密,确保只有接收方读懂。下半部分是数字签名:发送方对消息哈希后用自己私钥签名,接收方用发送方公钥验证签名,确保消息确实来自发送方且未被篡改。蓝色填充代表公钥操作,粉色填充代表私钥操作,体现了非对称性。
通过这三类算法的组合,现代系统得以在开放网络上安全运行。单向散列为数据打上防伪指纹,对称加密筑起快速保密通道,非对称加密则解决了密钥分发和身份认证的难题。理解它们各自的角色和协作方式,是设计安全系统的第一步。
算法识别加解密-MD5&AES&DES&RSA
上一篇文章我们拆解了三大类算法的原理与协作方式,今天我们把焦点放到四个具体的经典算法上:MD5、AES、DES、RSA。它们分别属于不同的算法类型,有的曾经辉煌但现已退居二线甚至禁用,有的至今仍是行业基石。学习它们,不仅是为了知道“怎么用”,更是为了在维护老系统、阅读历史代码时能一眼识别出它们的特点、漏洞以及替代方案,就像老工程师一看代码中的“MD5”就会警觉一样。下面我们逐个解剖。
MD5:曾经的数据指纹,如今的过气明星
它解决什么问题? 在互联网早期,MD5(Message-Digest Algorithm 5)被广泛用于检查文件完整性、存储口令摘要。它的设计目标就是把任意长度的数据压缩成一个128位(16字节)的指纹,只要原始数据一丁点变化,指纹就会完全改变。
它在系统中处于什么位置? 在十几年前的软件下载站、早期Linux发行版、旧版SVN版本库中,你常能看到MD5值。系统会预先计算文件的MD5并公布,用户下载后用md5sum命令核对。在早期Web系统中,开发者会把用户密码的MD5直接存进数据库。
它具体是怎么工作的,为什么这样设计? MD5将输入消息分成512位一块,通过压缩函数迭代处理,最后输出128位摘要。它的核心是四个非线性函数(F、G、H、I)和左循环移位操作,经过64轮运算充分混合输入位。设计上追求速度和雪崩效应,但当时没有预见到抗碰撞攻击的重要性。2004年起,中国密码学家王小云团队发现了MD5的快速碰撞方法,现在用普通电脑几分钟就能生成两个不同文件但MD5相同,因此它已完全丧失抗碰撞性。
实际中最常用的实现工具/方式? 尽管不安全,但很多操作系统和编程语言仍默认安装了md5sum或hashlib.md5。例如查看文件MD5:
md5sum ubuntu-20.04.iso
# 输出示例:f6e77a5a8c543f8b3d4b6d7e8f9a0b1c ubuntu-20.04.iso许多旧脚本、安装程序还在使用MD5做完整性校验,但从安全角度看,应该立即替换。
典型真实场景 + 简单可复制配置示例
假设你接手一个老旧项目,它的发布脚本里写着:
# 老脚本:计算软件包的MD5并输出到文件
md5sum myapp.tar.gz > myapp.tar.gz.md5
# 后续用户验证
md5sum -c myapp.tar.gz.md5这个校验流程在今天看来是不安全的,因为攻击者可以同时篡改文件和md5文件。正确做法是换成SHA-256。
最容易踩的坑、验证方法、下一步联动
最大的坑就是仍在使用MD5做安全相关的校验(如代码签名、密码存储)。验证MD5碰撞的方法:用工具如fastcoll生成两个不同文件但MD5相同,看看它们能否通过你的校验逻辑。下一步,对于完整性校验,应迁移到SHA-256或SHA-3;对于密码存储,应迁移到bcrypt/Argon2。
本模块决策指南
除非你是在考古或对非安全场景(如防止意外传输损坏,非恶意篡改)做校验,否则绝对不能再使用MD5。安全敏感场景必须用SHA-2家族。
Mermaid 图表:MD5计算流程
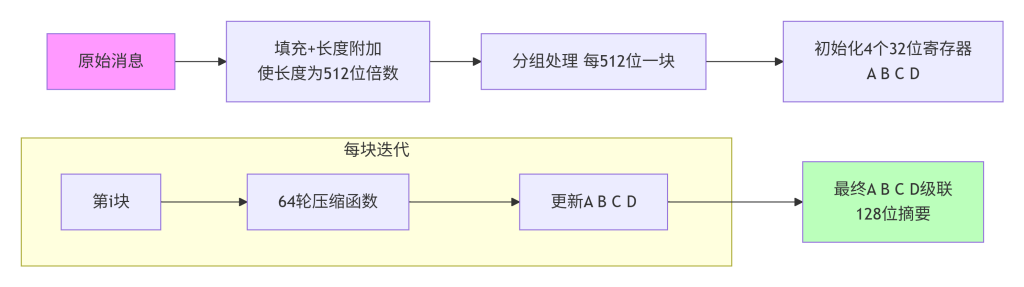
这张图描述了MD5的总体结构。原始消息先填充至512位的整数倍,并在末尾附上原始长度。然后每512位一块进入循环,每块通过64轮压缩函数更新四个32位寄存器的值。最后四个寄存器串联起来就是128位摘要。箭头表示数据流向,红色强调MD5的迭代结构,但并未体现其被攻破的现状。
DES:对称加密的鼻祖,如今一踢就倒
它解决什么问题? DES(Data Encryption Standard)诞生于1970年代,目的是为美国政府和非机密机构提供一种标准化的数据加密方法。它属于对称加密,加密和解密使用相同的56位密钥。
它在系统中处于什么位置? DES曾在ATM交易、早期SSL协议、金融系统中占据统治地位。但由于密钥长度太短,1999年EFF的专用计算机在22小时15分钟内破解了DES密钥,现在用普通硬件(如FPGA、GPU)几秒钟就能穷举。所以今天所有标准都已废弃DES,转而使用AES或至少3DES(三重DES)。
它具体是怎么工作的,为什么这样设计? DES基于Feistel网络结构,将64位数据块分成左右两半,经过16轮迭代,每轮使用一个48位的子密钥(由56位主密钥派生)。它的核心是S盒(替换盒),将6位输入变成4位输出,提供非线性变换。设计上考虑了硬件实现效率,但密钥长度受限于当时的技术条件。之所以设计成Feistel结构,是因为加解密过程高度相似(只需子密钥逆序),节省硬件资源。
实际中最常用的实现工具/方式? 现在几乎没有新系统直接使用DES,但在OpenSSL等密码库中仍能找到DES的接口(如openssl enc -des-ecb)。例如用DES加密一个文件:
# 加密(极度不安全,仅作演示)
openssl enc -des-ecb -in file.txt -out file.des -K 0123456789ABCDEF
# 解密
openssl enc -des-ecb -d -in file.des -out file_dec.txt -K 0123456789ABCDEF-K后面跟16进制密钥,DES实际只用了56位(每字节第8位是奇偶校验),所以密钥16个字符表示64位,有效56位。
典型真实场景 + 简单可复制配置示例
你可能在旧版金融接口配置文件中看到类似配置:
<encryption algorithm="DES" mode="ECB" key="0123456789ABCDEF"/>这种配置现在必须升级。ECB模式本身有缺陷(相同明文块产生相同密文块,容易泄露模式),加上短密钥,可被瞬间攻破。
最容易踩的坑、验证方法、下一步联动
坑就是在不该用DES的地方用了DES,比如遗留系统互连时还配置DES。验证方法很简单:用穷举工具(如Hashcat)尝试破解密钥,如果能在可接受时间内完成,说明算法太弱。下一步,所有DES必须替换为AES,且确保使用CBC、GCM等安全模式,并妥善管理密钥。
本模块决策指南
在任何新系统中,绝对不能选择DES。老系统升级时,应尽快替换。如果必须与不支持AES的老设备通信,可以考虑用3DES(尽管也不推荐,但比DES强),但最佳实践是淘汰旧设备。
Mermaid 图表:DES Feistel结构(一轮)
-1024x942.png)
这张图展示了DES的一轮迭代。右侧32位Ri-1和子密钥Ki进入轮函数F,输出32位结果,然后与左侧32位Li-1异或,得到新的右侧Ri。原来的右侧Ri-1直接成为新的左侧Li。箭头表示数据流动,颜色区分左右半区。这种结构保证了加解密的一致性。
AES:现代加密的黄金标准
它解决什么问题? 1997年,NIST公开征集新的加密标准以取代DES,最终Rijndael算法胜出,成为AES(Advanced Encryption Standard)。它用128位分组,支持128/192/256位密钥,能抵抗所有已知攻击,是目前对称加密的事实标准。
它在系统中处于什么位置? 无处不在。你的HTTPS连接、Wi-Fi密码(WPA2/AES)、全盘加密(BitLocker、FileVault)、数据库透明加密,底层几乎都是AES。它通常运行在CPU的专用指令集上(AES-NI),速度极快。
它具体是怎么工作的,为什么这样设计? AES不是Feistel网络,而是代换-置换网络(SPN)。它将128位数据组织成4×4字节矩阵,经过10/12/14轮(取决于密钥长度)变换。每轮包含:字节代换(SubBytes,通过S盒非线性替换)、行移位(ShiftRows,行间移动字节)、列混淆(MixColumns,矩阵乘混合每列)、轮密钥加(AddRoundKey,与子密钥异或)。最后一轮不执行列混淆。这种设计同时实现了混淆(S盒)和扩散(行移位+列混淆),在硬件和软件上都能高效实现,且安全余量大。
实际中最常用的实现工具/方式? OpenSSL、Libsodium、各语言内置库(如Python的Crypto.Cipher.AES)。命令行常用:
# 用AES-256-CBC加密,密码派生命令
openssl enc -aes-256-cbc -salt -in secret.txt -out secret.enc -pbkdf2 -iter 100000
# 解密
openssl enc -aes-256-cbc -d -in secret.enc -out secret_dec.txt -pbkdf2 -iter 100000-pbkdf2使用基于密码的密钥派生函数,增加迭代次数抗暴力破解;-iter指定迭代次数。
典型真实场景 + 简单可复制配置示例
假设你写一个脚本备份数据库,需要加密备份文件:
from cryptography.hazmat.primitives.ciphers import Cipher, algorithms, modes
from cryptography.hazmat.backends import default_backend
import os
key = os.urandom(32) # 256位密钥
iv = os.urandom(16) # 128位初始化向量
cipher = Cipher(algorithms.AES(key), modes.CBC(iv), backend=default_backend())
encryptor = cipher.encryptor()
# 假设数据已填充到16字节倍数
ciphertext = encryptor.update(b"your database dump...") + encryptor.finalize()这里os.urandom生成安全随机数作为密钥和IV,CBC模式需要IV,每次加密应重新生成。
最容易踩的坑、验证方法、下一步联动
常见坑:使用ECB模式(不隐藏数据模式)、IV重用(同一密钥下IV重复会泄露信息)、未进行身份验证(只加密不校验完整性,可能被篡改)。正确做法是选用GCM或CCM等认证加密模式,或加密后附加HMAC。验证方法:解密后对比原文,同时检查认证标签。下一步,AES常与RSA结合:用RSA加密AES密钥,实现安全传输。
本模块决策指南
所有需要对称加密的场景,必须首选AES-256-GCM(兼顾速度和认证)。如果平台不支持GCM,可选AES-256-CBC配合HMAC-SHA256。绝对不要自己实现AES,用经过审计的库。
Mermaid 图表:AES加密一轮(除最后一轮)
-442x1024.png)
这张图描述了AES一轮的四个操作。字节代换是非线性替换,行移位实现行间扩散,列混淆混合每列数据,轮密钥加引入密钥。箭头表示执行顺序,每个方框代表一个可逆变换,最终实现了高度的混淆和扩散。
RSA:非对称加密的基石
它解决什么问题? 在互联网上通信的双方如何安全地交换密钥,而不怕被监听?RSA(Rivest-Shamir-Adleman)解决了密钥分发问题,并支持数字签名,是公钥密码学的里程碑。
它在系统中处于什么位置? RSA常用于SSL/TLS握手阶段(服务器证书携带RSA公钥)、SSH密钥认证、电子邮件加密(PGP)、数字签名(软件更新)。它不直接加密大数据,而是加密对称密钥或散列值。
它具体是怎么工作的,为什么这样设计? RSA基于大整数因数分解难题。随机选择两个大素数p和q,计算n = pq。欧拉函数φ(n) = (p-1)(q-1)。选择公钥指数e(通常65537),计算私钥d,使得e*d ≡ 1 mod φ(n)。公钥为(n, e),私钥为(n, d)。加密时,c = m^e mod n;解密时,m = c^d mod n。安全性依赖于分解n的困难性。设计成模幂运算是因为这一运算可公开计算,但逆向分解极难。
实际中最常用的实现工具/方式? OpenSSL、GnuPG、Java KeyPairGenerator。生成2048位RSA密钥对:
# 生成私钥
openssl genrsa -out private.pem 2048
# 提取公钥
openssl rsa -in private.pem -pubout -out public.pem
# 用公钥加密小文件(数据长度必须小于密钥长度-11字节,因为填充)
echo "secret data" | openssl rsautl -encrypt -pubin -inkey public.pem > secret.enc
# 用私钥解密
openssl rsautl -decrypt -inkey private.pem -in secret.enc注意rsautl只能加密短数据,实际中我们通常用它加密AES密钥。
典型真实场景 + 简单可复制配置示例
在HTTPS配置中,Nginx需要服务器私钥和证书,证书包含RSA公钥:
server {
listen 443 ssl;
ssl_certificate /etc/nginx/ssl/server.crt; # 包含公钥的证书
ssl_certificate_key /etc/nginx/ssl/server.key; # 私钥
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers HIGH:!aNULL:!MD5;
}握手时,浏览器用证书中的公钥加密一个随机数,服务器用私钥解密,后续生成对称密钥。
最容易踩的坑、验证方法、下一步联动
坑:密钥长度过短(1024位已可破解)、使用不安全的填充方案(如无填充的“教科书RSA”易受攻击)、随机数生成弱(导致私钥可预测)。正确做法:RSA加密必须使用OAEP填充,签名使用PSS填充。验证方法:用公钥验证签名,或用私钥解密用公钥加密的数据。下一步,RSA必须与对称加密结合形成混合加密,因为RSA本身不能加密大数据。
本模块决策指南
必须使用RSA的场景:需要公钥加密或数字签名,且与广泛兼容的旧系统交互(如许多PKI体系基于RSA)。但新系统可考虑使用ECC(如ECDSA、Ed25519),密钥更短、性能更好。如果仅用于密钥交换,可考虑使用DH或ECDH。总之,RSA仍是主流,但ECC正逐渐取代它。
Mermaid 图表:RSA混合加密流程
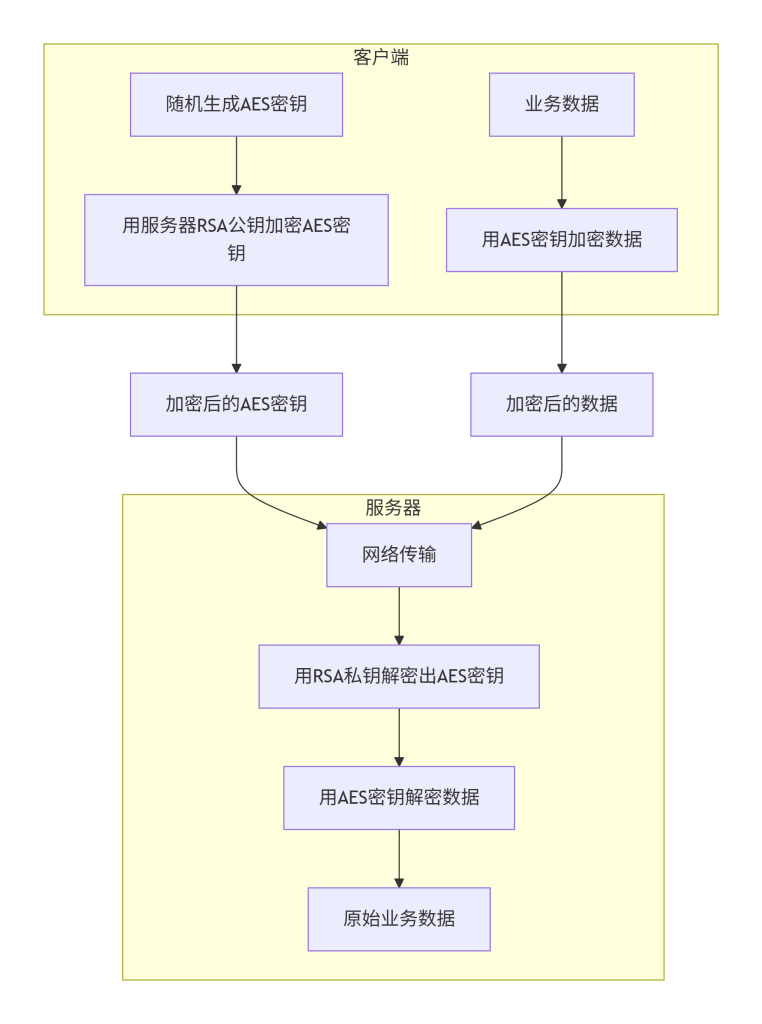
这张图展示了典型的混合加密。客户端随机生成临时AES密钥,用服务器的RSA公钥加密后随加密数据一起发送。服务器用RSA私钥解密得到AES密钥,再用AES密钥解密密文。这样结合了RSA的安全密钥分发和AES的高效加密。
如何一眼识别这些算法
- MD5:哈希值长度16字节(32个十六进制字符),常出现在旧版文件校验、密码字段(长度为32的字符串)。
- DES:密钥长度64位(有效56位),密文块64位,特征为ECB模式下的相同明文产生相同密文,现在很少见到。
- AES:密钥支持128/192/256位,块大小128位,加密后数据通常带IV,现代代码中随处可见。
- RSA:密钥以PEM格式存储(
-----BEGIN RSA PRIVATE KEY-----),公钥可公开,用于加密小数据或签名。
在实际系统中,这些算法往往组合出现:RSA加密AES密钥,AES加密大量数据,而MD5已经退役,由SHA-256或SHA-3接替。当你维护老代码看到MD5或DES时,就应该拉响警报,准备升级。
算法识别加解密-MD5&AES&DES&RSA那章,我们聊的是如何一眼认出这些算法本身。今天我们要往前走一步:假设你面对的是一个黑盒系统,你抓到了加密的数据包,或者在代码里看到一段疑似解密的逻辑,你怎么找到解开这些数据的钥匙?这就是“解密条件寻找”——通过分析逻辑特征、阅读源码片段、动态调试JavaScript,定位加密函数、密钥、IV向量的过程。它和上一篇文章的区别在于:之前是“静态识别”,现在是“动态追踪”;之前是“这是什么算法”,现在是“密钥藏在哪里,怎么调用”。
逻辑特征:从密文反推算法的侦探游戏
它解决什么问题? 当你只有一段密文,比如从HTTP响应里看到一堆乱码,你首先要判断这是什么算法加密的,才有下一步的搜索方向。生活里就像你捡到一个锁着的盒子,先看锁眼形状,才能推断用哪种钥匙。
它在系统结构中处于什么位置? 密文通常出现在API响应体、Cookie值、LocalStorage或配置文件中。分析逻辑特征是在不接触源码的情况下,通过密文的长度、字符集、固定格式来缩小算法范围。
它具体怎么工作,为什么这样设计? 不同算法的输出有各自的特征。比如Base64编码通常以等号结尾,字符集是A-Za-z0-9+/;十六进制串由0-9a-f组成,长度总是偶数;MD5输出32个十六进制字符;AES加密经过Base64编码后,长度通常是16字节的倍数(加上填充)。为什么可以这样判断?因为算法规范决定了输出格式——AES块大小128位,CBC模式需要IV,这些都会在密文中留下痕迹。通过频率分析和块长度分析,就能猜个八九不离十。
实际中最常用的判断方式? 肉眼观察 + 工具辅助。看到一段密文,先看长度:32位可能是MD5,40位可能是SHA1,64位可能是SHA256。看结尾:等号很可能有Base64。看开头:U2FsdGVkX1是OpenSSL加密的典型头(”Salted__”的Base64)。也可以丢进在线工具如CyberChef,尝试自动检测。
典型真实场景 + 简单可复制示例
假设你抓包看到一段响应数据:
{"data": "U2FsdGVkX1+6x3Fp7Q8yL9zW2q4rB5nC8vA="}看到开头”U2FsdGVkX1″,立刻能猜到这是OpenSSL用密码加密的AES(默认 salted)。长度48字节,Base64解码后36字节,去掉8字节salt,剩下28字节,符合AES-256-CBC填充后的块大小。
最容易踩的坑、验证方法、下一步联动
坑是误判算法,比如把Base64当加密算法,或者把自定义编码当成标准加密。验证方法:用猜测的算法写一小段测试代码,看能否解出有意义的内容。下一步,有了算法判断,就可以去源码里搜索对应的关键词(如AES.decrypt)。
本模块决策指南
必须用逻辑特征分析的时候:你没有源码,只有抓包数据,需要快速锁定逆向方向。如果密文格式明显(如JWT),一眼就能认出;如果完全看不出特征,可能涉及自定义混淆,需要结合动态调试。
Mermaid 图表:密文特征推断流程
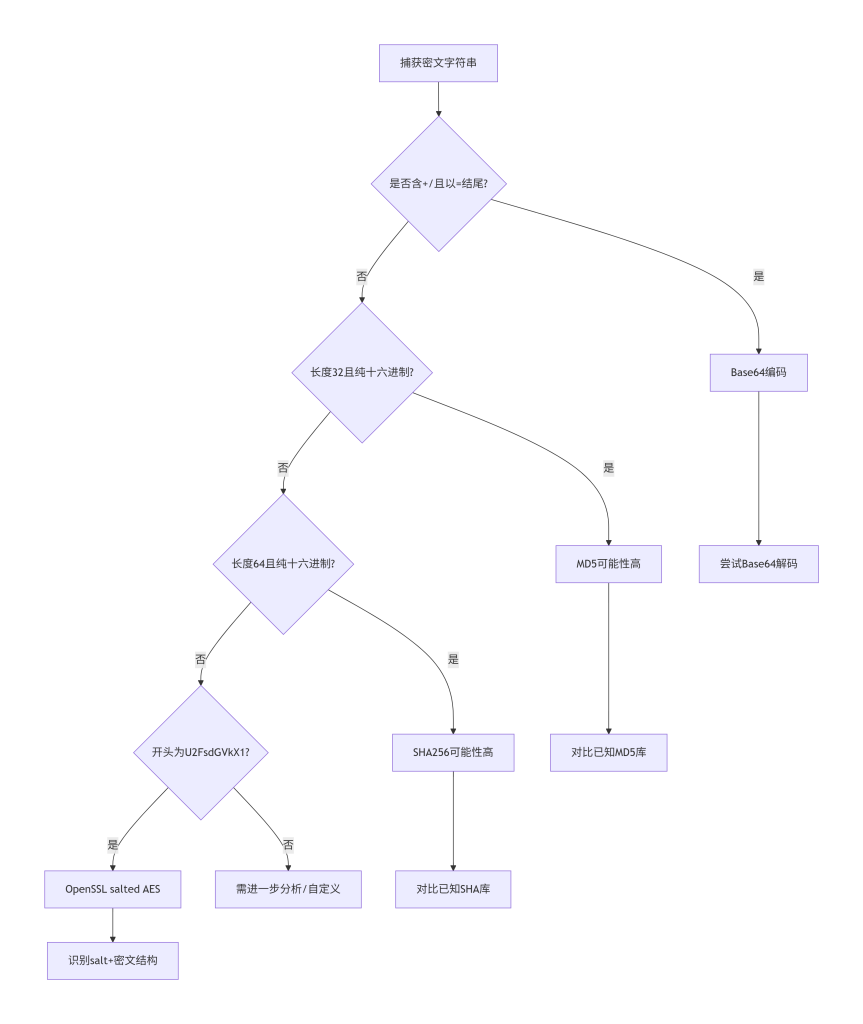
这张图展示了从密文字符串出发的推理分支。每个菱形框是判断条件,根据长度、字符集、固定前缀走向不同的算法路径。箭头表示逻辑流向,帮助新手建立“先看特征再动手”的习惯。
源码中定位:从混淆森林里找到解密函数
它解决什么问题? 你拿到了前端或客户端代码,但代码可能经过混淆(Obfuscated),变量名都是a,b,c,甚至用JSFuck、AAencode写成颜文字。你需要在这团乱麻里找到真正的解密逻辑。
它在系统结构中处于什么位置? 解密函数通常位于发送请求前的数据处理模块,或收到响应后的渲染模块。在Web前端,一般在某个.js文件里;在Android/iOS,可能在so库或Java/Kotlin代码中。
它具体怎么工作,为什么这样设计? 开发者为了保护代码,会用工具如javascript-obfuscator把代码变得难以阅读。但不管怎么混淆,最终执行时还是要调用真实的解密API,比如CryptoJS.AES.decrypt、window.atob、node内置的crypto模块。所以搜索关键词是突破口。为什么这样设计?因为混淆只能增加阅读难度,不能改变程序必须调用的底层函数。
实际中最常用的定位方式? 在代码里全局搜索关键词:decrypt、AES、CBC、mode、iv、key、padding、parse、toString。如果代码经过OB混淆,搜索字符串字面量可能无效,要搜索混淆后的数组下标或动态字符串。另一个技巧:搜索Base64特征字符串,反向定位解密调用。
典型真实场景 + 简单可复制示例
你找到一个JS文件,里面都是_0x2345['0x12']这种混淆,但仔细看末尾有:
var _0x12ab = function(_0x34cd) {
var _0x56ef = CryptoJS['AES']['decrypt'](_0x34cd, _0x78ab, {
iv: CryptoJS['enc']['Utf8']['parse'](_0x90ij),
mode: CryptoJS['mode']['CBC'],
padding: CryptoJS['pad']['Pkcs7']
});
return _0x56ef['toString'](CryptoJS['enc']['Utf8']);
}尽管变量名被混淆,但CryptoJS['AES']['decrypt']这个调用链没变,一眼就能认出这是AES解密。
最容易踩的坑、验证方法、下一步联动
坑是只搜decrypt不搜其他变体,比如开发者可能用decode、unpad、_d等别名。验证方法:在找到的函数处设断点,运行并查看参数值。下一步,从函数往上看,找到key和iv的来源——可能来自固定字符串、接口返回、或动态拼接。
本模块决策指南
当你有源码(即使混淆)时,必须用关键词搜索定位。如果代码极小且无混淆,直接阅读逻辑;如果重度混淆,可能需要借助AST(抽象语法树)工具还原,或者直接动态调试,因为运行时的值才是真实的。
Mermaid 图表:混淆代码中的解密函数定位

这张图描述了从混淆代码到解密函数的定位路径。红色框代表原始混乱代码,经过关键词过滤后找到可疑函数,再检查内部是否调用了标准密码库,最终确认。箭头表示操作步骤,强调”先搜索再验证”。
JS分析:动态调试抠出解密逻辑
它解决什么问题? 静态代码里你找到了函数,但不知道它实际运行时key是什么、iv怎么生成。你需要让代码真正跑起来,观察变量值,甚至把解密函数单独抠出来在本地运行。
它在系统结构中处于什么位置? JS分析发生在浏览器开发者工具里,在Sources面板下断点、监视变量,或者在Node.js环境复现。
它具体怎么工作,为什么这样设计? 动态调试利用JavaScript解释器的执行环境。你在可能调用解密函数的地方设断点(比如XHR断点或关键字断点),刷新页面,代码执行到断点时会暂停,此时可以查看作用域里的所有变量,逐步跟踪。为什么这样设计?因为运行时所有混淆都被还原成真实值,能直接看到密钥是什么。抠代码是因为原网页可能有反爬虫环境检测,需要补环境(如navigator、document)才能跑通。
实际中最常用的工具? Chrome DevTools是最强工具。步骤:F12打开,Sources面板,Ctrl+Shift+F全局搜索解密关键词,找到后行号单击设断点。触发操作(如翻页),断住后鼠标悬停变量看值,或进入Call Stack回溯调用链。
典型真实场景 + 简单可复制示例
接上面的例子,你在CryptoJS.AES.decrypt处设断点,刷新页面后断住。右侧Scope面板里看到arguments[0]是密文,arguments[1]是key变量,发现它来自一个全局变量_globalKey。往上翻Call Stack,找到调用这个解密函数的上一层,发现_globalKey是由一个/api/key接口返回的。于是你补全整个流程:先请求key,再用key解密数据。
最容易踩的坑、验证方法、下一步联动
坑是环境检测:有些JS会检测是否在浏览器(navigator、window、document)下运行,在Node.js里会报错。需要补环境,比如手动定义global.navigator = {userAgent: '...'}。验证方法:把抠出的代码和必要的环境变量复制到本地JS文件,用Node运行,看能否输出正确明文。下一步,如果解密成功,就可以用Python/Java等语言模拟这个过程,实现自动化。
本模块决策指南
必须动态分析的情况:静态代码混淆严重,或密钥动态生成。如果代码清晰且密钥硬编码,静态分析就够了。动态调试是最后的王牌,但耗时也长,适合无法直接阅读的场景。
Mermaid 图表:动态调试解密流程
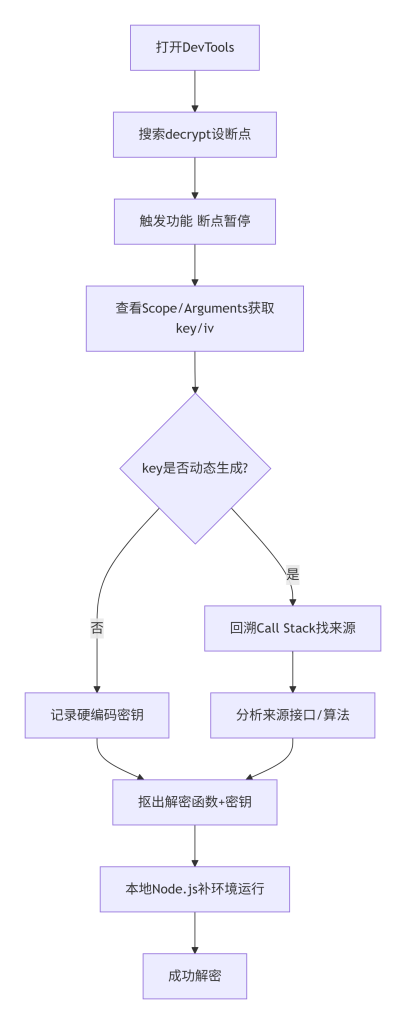
这张图呈现了完整的JS动态调试步骤。从打开开发者工具开始,经过设断点、暂停、查看变量、回溯调用栈,到抠出代码本地运行,每一步都是实践中的必经环节。菱形判断引导分析人员区分密钥来源类型,箭头展示成功路径。
通过逻辑特征推断算法、源码中定位函数、动态调试获取密钥,这三步构成了寻找解密条件的完整方法论。它和我们之前学的算法知识紧密结合:你知道AES-CBC需要IV,就会在调试时特别关注iv变量;你知道RSA加密数据不能太长,就会理解为什么只加密对称密钥。当你真正上手分析一个加密接口时,这三板斧能帮你一步步逼近真相。