传输格式&数据-类型&编码&算法
数据在网络中传输,就像寄快递——你得把物品包装好(传输格式),贴上正确的标签(数据类型),写上收件人地址(编码),有时候还得加把锁(算法),确保东西安全到达。下面我们按这个链条,一步步拆解这些概念在系统里的实际作用。
传输格式
当两个服务需要交换数据时,首先得约定一种双方都能理解的“语言”——这就是传输格式。它解决的核心问题是:如何将内存中的对象转换成字节流,发送出去,再在另一端还原成对象。生活中就像两个人写信,必须用同一种文字才能沟通。
在系统结构中,传输格式位于应用层协议(如HTTP、gRPC)的载荷部分,紧挨着业务逻辑。它负责把业务数据序列化成网络字节流,接收端再反序列化回来。常见的传输格式有JSON、XML、Protobuf、MessagePack等。JSON人类可读、调试方便,但体积大、解析慢;Protobuf是二进制格式,体积小、解析快,但需要预定义Schema,适合高性能内部通信。
具体工作流程:发送方将数据对象(如Python字典)通过序列化库(如json.dumps)转换成字符串,加上HTTP头后发出去;接收方用反序列化库(如json.loads)还原成对象。为什么这样设计?因为网络只能传输字节流,必须有一个标准格式将数据结构“扁平化”,同时保留类型信息,才能正确还原。
实际中最常用的传输格式是JSON,尤其在Web API中。下面是一个FastAPI(Python 3.12+)的示例,定义了一个接收JSON的接口:
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
price: float
is_offer: bool = False
@app.post("/items/")
async def create_item(item: Item):
# FastAPI自动将请求体JSON反序列化为Item对象
return {"item_name": item.name, "item_price": item.price}这里Item类定义了JSON中期望的字段和类型。FastAPI利用Pydantic自动完成JSON到对象的转换。如果请求体是{"name":"Apple","price":1.5},它会正确解析;如果缺少字段或类型错误,会返回422错误。
最容易踩的坑是JSON注入攻击。攻击者可能构造恶意JSON,利用解析库的漏洞(如原型链污染在JavaScript中)或超大JSON导致拒绝服务。正确做法:使用安全的解析库(如Python的json模块默认不支持任意对象)、限制输入大小、使用Schema校验(如Pydantic)。验证方法:用模糊测试工具发送畸形JSON,观察服务是否异常。下一步操作建议:与下一个模块“数据类型”联动,在反序列化后立即进行类型校验。
决策指南:必须用传输格式的场景——任何跨网络的数据交换;替代方案——如果只有同构系统且性能要求极高,可直接使用语言内置序列化(如Java的RMI),但牺牲了跨语言互操作性。
Mermaid 图表:传输格式在HTTP请求中的位置

这张图展示了从客户端发送JSON请求到服务端处理的流程。方框代表系统组件或数据载体,箭头表示数据流动方向。JSON请求首先被解析器反序列化成内存对象,然后经过类型校验器确保字段类型正确,最后交给业务逻辑处理,处理结果再序列化成JSON返回客户端。整个过程中,传输格式(JSON)起到了桥梁作用,使不同语言编写的客户端和服务端能交换数据。
数据类型
数据在传输格式中被序列化后,接收方拿到的是字节流,需要还原成有明确类型的对象——这就是数据类型要解决的问题。它确保程序能正确解释内存中的二进制数据,避免因类型误解导致逻辑错误或安全漏洞。生活中就像收到一封信,你得知道哪部分是日期、哪部分是金额,才能正确处理。
在系统结构中,数据类型属于编程语言的类型系统,以及数据校验层。它与传输格式紧密协作:传输格式提供了数据的结构,数据类型则规定了每个字段的取值约束。常见的类型系统包括静态类型(如Java、Go)和动态类型(如Python、JavaScript)。在Web API中,我们常用Schema定义语言(如JSON Schema、Pydantic模型)来声明类型。
具体工作流程:数据从传输格式反序列化后,会生成原始类型(如Python的dict),然后通过类型校验器根据预定义Schema转换成强类型对象。为什么这样设计?因为网络传输只能传递基础类型(字符串、数字、布尔等),业务逻辑需要更丰富的类型(如UUID、日期时间、枚举),类型校验层负责转换和验证,保证数据符合预期。
实际中最常用的类型定义工具是Pydantic(Python)、Zod(TypeScript)、Joi(Node.js)。下面是一个使用Pydantic定义带约束类型的示例:
from pydantic import BaseModel, Field, ValidationError
from datetime import date
class User(BaseModel):
id: int
name: str = Field(..., min_length=1, max_length=50)
birth_date: date
email: str = Field(..., regex=r"^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$")
# 假设从JSON解析得到的数据
raw_data = {
"id": 123,
"name": "Alice",
"birth_date": "1990-01-01", # 字符串会自动转换为date
"email": "alice@example.com"
}
try:
user = User(**raw_data)
print(user.birth_date.year) # 可以直接访问date属性
except ValidationError as e:
print(e.json())这里Pydantic不仅校验类型,还自动将符合格式的字符串转换成date对象,并验证邮箱格式。如果传入birth_date格式不对或name为空,会抛出清晰的错误。
最容易踩的坑是类型混淆漏洞。例如攻击者将本该是整数的字段改成字符串,绕过SQL注入过滤(如ORM可能将字符串原样拼接)。或者利用动态语言的隐式类型转换造成逻辑错误。正确做法:严格校验输入类型,拒绝意外类型;使用强类型语言或在边界进行防御性校验。验证方法:编写单元测试,传入边界值和恶意类型,检查是否被拦截。下一步操作建议:与“编码”模块联动,在类型校验之后,对需要编码的字段(如用户输入)进行安全编码。
决策指南:必须使用显式类型定义的场景——任何接收外部输入的系统,尤其是涉及安全敏感操作时;替代方案——如果系统完全内部且信任,可依赖语言动态特性,但风险较高,不推荐。
Mermaid 图表:数据类型校验与转换流程
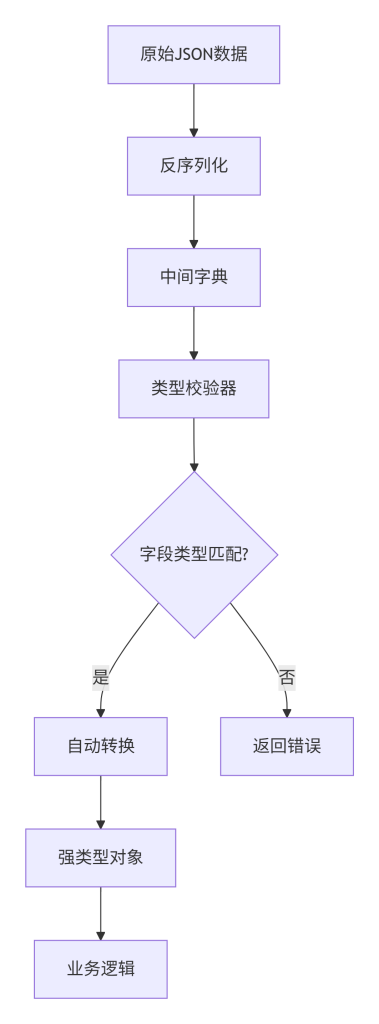
这张图描绘了从反序列化后的原始字典到强类型对象的转换过程。类型校验器检查每个字段是否与预定义类型匹配,如果匹配,则可能进行自动类型转换(如字符串到日期),最终生成一个强类型对象供业务逻辑使用;如果不匹配,则直接返回错误,防止非法数据进入后续流程。
编码
数据经过类型校验后,通常还需要进行编码,以解决特定场景下的传输安全或兼容性问题。编码解决的核心问题是:如何将二进制数据或特殊字符转换成适合在特定介质中传输的格式。生活中就像把贵重物品用泡沫包裹,防止运输途中损坏。
在系统结构中,编码位于数据表示层,通常在数据输出前(如生成HTML、URL)或存储前(如Base64存入数据库)。它与传输格式不同:传输格式定义数据结构,编码定义单个数据的表示方式。常见编码有:Base64(将二进制转成文本)、URL编码(将特殊字符转成%xx)、HTML实体编码(防止XSS)、Unicode归一化等。
具体工作流程:输入原始数据(可能包含二进制或特殊字符),编码器根据规则将其转换成安全字符串;接收方用解码器还原。为什么这样设计?因为有些传输通道只支持ASCII字符(如Email、某些JSON字段),或者特殊字符有语法含义(如URL中的&),必须转义以避免破坏结构或引发注入。
实际中最常用的编码是Base64和URL编码。下面是一个Python示例,演示如何对用户上传的图片进行Base64编码,嵌入JSON中传输:
import base64
import json
# 假设从文件读取二进制图片
with open("avatar.png", "rb") as f:
image_bytes = f.read()
# Base64编码
image_b64 = base64.b64encode(image_bytes).decode('ascii')
# 构建JSON
payload = {
"user_id": 123,
"avatar": image_b64 # 直接放入JSON字符串
}
# 发送JSON
json_data = json.dumps(payload)
print(json_data[:100]) # 输出前100字符这里base64.b64encode将二进制数据转换成只含ASCII字符的字符串,可以安全地放入JSON文本中。接收方再用base64.b64decode还原。
最容易踩的坑是双重编码或编码绕过。例如对用户输入先URL编码再HTML编码,可能导致某些攻击载荷被意外还原。或者攻击者利用编码绕过输入过滤(如用%3Cscript%3E绕过WAF,但后端未解码直接存入数据库,导致前端显示时被解码执行)。正确做法:理解上下文,只做一次正确的编码;在输出点根据上下文进行编码(如HTML输出用HTML实体编码,SQL拼接用参数化查询)。验证方法:用攻击向量测试各输出点,检查是否被正确转义。下一步操作建议:与“算法”模块联动,对敏感数据先加密再编码传输。
决策指南:必须使用编码的场景——数据需要放入特殊上下文(URL、HTML、JSON字符串)时;替代方案——如果数据全是ASCII且不含特殊字符,可以不编码直接传输,但安全编码总是好习惯。
Mermaid 图表:编码解码在请求响应中的位置
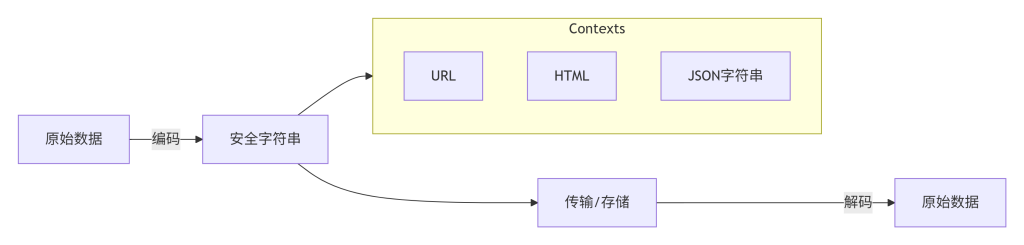
这张图展示了编码和解码的基本流程。原始数据经过编码成为安全字符串,然后进入特定的上下文(URL、HTML、JSON字符串等)传输或存储;接收方从上下文中提取安全字符串,再解码还原为原始数据。箭头方向表示数据流向,强调了编码是为了适应特定上下文而进行的必要转换。
算法
最后,为了确保数据在传输过程中的机密性和完整性,我们需要应用密码学算法。算法解决的核心问题是:如何防止数据被窃听、篡改或伪造。生活中就像给信件加上密码锁和防伪封条。
在系统结构中,算法位于安全层,通常与传输格式、编码结合。例如HTTPS在TCP层之上使用TLS协议,对HTTP报文进行加密和签名。常见算法分类:对称加密(AES)、非对称加密(RSA)、哈希(SHA-256)、消息认证码(HMAC)、数字签名等。
具体工作流程:发送方使用加密算法和密钥将明文转换成密文,接收方用对应密钥解密。为什么这样设计?因为网络传输路径不可信,加密确保即使数据被截获也无法读取;签名确保数据未被篡改且来源可信。
实际中最常用的算法组合是TLS协议,它协商加密套件、交换密钥、加密数据。对于应用层自定义加密,常用PyCryptodome、cryptography等库。下面是一个使用Python的cryptography库对数据进行AES加密的示例(注意密钥管理需安全):
from cryptography.hazmat.primitives.ciphers import Cipher, algorithms, modes
from cryptography.hazmat.backends import default_backend
import os
# 生成随机密钥和初始化向量
key = os.urandom(32) # AES-256密钥
iv = os.urandom(16) # 128位IV
# 明文数据
plaintext = b"Sensitive user data"
# 加密
cipher = Cipher(algorithms.AES(key), modes.CBC(iv), backend=default_backend())
encryptor = cipher.encryptor()
# 需要填充到块大小
from cryptography.hazmat.primitives import padding
padder = padding.PKCS7(128).padder()
padded_data = padder.update(plaintext) + padder.finalize()
ciphertext = encryptor.update(padded_data) + encryptor.finalize()
# 传输或存储时通常需要将iv和ciphertext一起发送
print("IV:", iv.hex())
print("Ciphertext:", ciphertext.hex())实际生产环境中,应使用更高级别的封装如Fernet,或直接使用TLS。永远不要自己实现密码学。
最容易踩的坑:弱算法(如DES、MD5)、硬编码密钥、密钥泄露、不正确的模式(如ECB)。正确做法:使用现代算法(AES-GCM、ChaCha20-Poly1305),密钥存储在安全硬件或密钥管理服务(KMS)中,遵循密码学最佳实践。验证方法:用已知测试向量验证实现是否正确,进行渗透测试检查密钥是否泄露。下一步操作建议:与传输格式联动,将加密后的数据放入JSON或Protobuf中传输。
决策指南:必须使用加密的场景——传输个人隐私、支付信息、商业机密等敏感数据;替代方案——如果数据不敏感且网络环境可信,可以不加密,但现代系统通常默认全链路加密(HTTPS)。
Mermaid 图表:加密通信流程
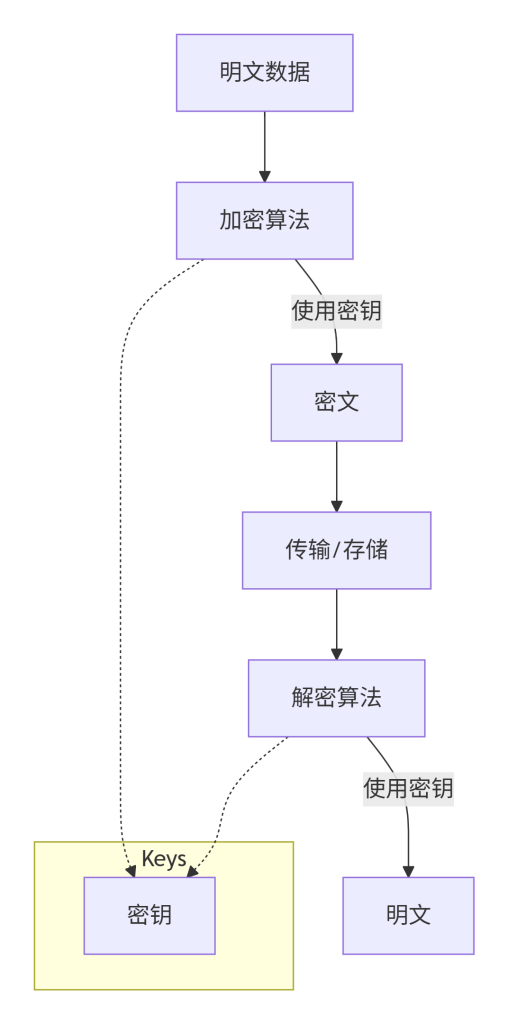
这张图展示了对称加密的基本流程。明文在加密算法和密钥的作用下变成密文,经过传输或存储后,接收方用相同的密钥解密恢复明文。虚线箭头表示密钥的使用关系,强调密钥在加密和解密中都是必需的,必须安全保管。实际中,密钥的协商通常通过非对称加密完成,但这里简化以突出核心概念。
通过以上四个模块的串联,你可以构建一条从数据定义到安全传输的完整链路:定义数据类型约束 → 选择合适的传输格式序列化 → 对特殊字段进行编码 → 对敏感数据加密。每一步都在为数据的正确性和安全性添砖加瓦。
密码存储&混淆-不可逆&非对称性
密码存储是系统安全中最关键的环节之一,处理不好会直接导致用户账号被盗。它的核心问题是:如何安全地保存用户的密码,使得即使数据库泄露,攻击者也难以还原出原始密码?生活中就像酒店保存房卡——他们不应该记住你的密码,而是每次刷卡时比对刷卡器生成的校验码,这样即使偷走校验码也开不了门。
在系统结构中,密码存储位于用户认证模块,与数据库紧密协作。当用户注册或修改密码时,系统对密码进行不可逆处理(哈希),将结果存入数据库;用户登录时,系统对输入的密码进行相同处理,并与数据库中的哈希值比对。这个过程中,哈希算法的单向性保证了即使数据库内容泄露,也无法逆向还原密码。为什么必须用不可逆哈希?因为如果使用可逆加密(如AES),一旦加密密钥泄露,所有密码都会被还原。而哈希没有密钥,天生无法反向计算,大大提高了安全性。
具体工作流程涉及两个核心设计:哈希算法(单向、抗碰撞)和盐(随机字符串,与密码一起哈希,防止彩虹表攻击)。注册时,系统为每个用户生成一个随机盐,将密码和盐拼接后送入哈希函数(如bcrypt),得到哈希值,然后将盐和哈希值一起存储。登录时,系统取出该用户的盐,将用户输入的密码与盐拼接,用相同哈希函数计算,比对结果是否与存储的哈希值一致。为什么引入盐?因为如果没有盐,相同密码会生成相同哈希,攻击者可预计算常用密码的哈希(彩虹表)快速匹配。盐使得即使密码相同,哈希结果也完全不同,迫使攻击者必须对每个盐单独计算,极大增加破解成本。
实际中最常用的密码存储工具是bcrypt、scrypt和Argon2。bcrypt诞生较早,内置盐和工作因子(可调整计算速度),广泛使用且容易实现;scrypt抗硬件加速(需要大量内存),适合对GPU/ASIC攻击敏感的场合;Argon2是2015年密码哈希竞赛的优胜者,设计先进,但普及度稍低。三者的共同点是自适应慢哈希,可以通过调整参数让破解成本随时间增长。
下面是一个使用Python的bcrypt库(主流版本3.2.0+)实现密码存储的完整示例:
import bcrypt
# 用户注册时
def hash_password(plain_password: str) -> str:
# 生成盐,默认成本因子12(可调整)
salt = bcrypt.gensalt()
# 哈希密码,返回包含盐和哈希的字符串
hashed = bcrypt.hashpw(plain_password.encode('utf-8'), salt)
# 返回的hashed是字节串,可直接存入数据库(通常转为字符串)
return hashed.decode('utf-8')
# 存储到数据库
hashed_password = hash_password("user_plain_password")
# 假设存入users表
# 用户登录验证时
def verify_password(plain_password: str, hashed_password: str) -> bool:
# 从数据库取出的哈希字符串需转回字节
return bcrypt.checkpw(plain_password.encode('utf-8'), hashed_password.encode('utf-8'))
# 验证示例
is_correct = verify_password("user_plain_password", hashed_password)
print("密码正确" if is_correct else "密码错误")bcrypt.gensalt()生成一个随机盐,并嵌入成本因子(默认为12)。bcrypt.hashpw()将密码和盐结合进行Blowfish加密,迭代次数为2^成本因子,结果是一个包含算法标识、成本因子、盐和哈希值的字符串(如$2b$12$...)。验证时checkpw提取存储字符串中的盐和成本,重新计算并比对,避免时序攻击。整个过程对开发者透明,只需调用API。
最容易踩的坑:使用过时哈希(MD5、SHA-1),无盐或盐固定,成本因子太低,自己拼接盐(可能引入格式错误),使用普通哈希函数(如SHA-256)不加慢迭代。正确做法:始终使用专门设计的密码哈希库(如bcrypt),成本因子根据服务器性能设为10~14(2025年建议12以上)。验证方法:检查数据库中相同密码的哈希值是否不同(证明盐起作用);登录时间是否在0.1~0.3秒左右(成本合适)。下一步操作建议:与认证授权模块联动,验证通过后生成JWT或Session,返回给客户端。
决策指南:任何时候存储用户密码,都必须使用不可逆的慢哈希加盐。没有替代方案——可逆加密绝对禁止,明文存储更不可接受。对于密码重置场景,应通过邮件发送临时链接,而非直接找回原密码,因为原密码不应被存储。
Mermaid 图表:密码注册与验证流程
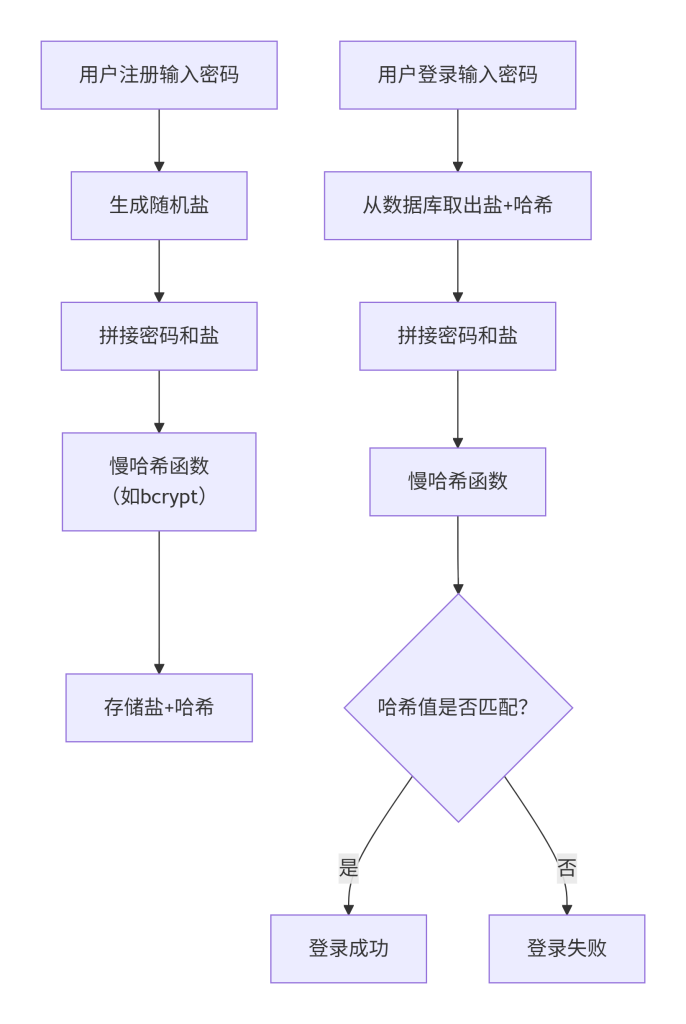
这张图展示了密码存储的两个关键阶段:注册(上半部分)和登录(下半部分)。注册时,系统生成随机盐,与用户密码拼接后送入慢哈希函数,将结果(包含盐和哈希)存储;登录时,系统取出存储的盐和哈希,将用户输入密码与盐拼接,再次执行相同的慢哈希,然后比对结果。箭头表示数据流动,其中盐和哈希始终结合,确保相同密码产生不同结果,且验证过程不暴露原密码。