在昨天晚上进行测试结果之后,虽然它可以进行文件输出呢,但是还有不少人反映它的结构还是太过于复杂了,大概有4kb左右,所以我就想能不能对他们进行再也不拆分,拆分成一个大文件夹,下面有好几份小文件,这样子他拆分过后的文章就简洁清晰明了易懂多了。
节点配置
数据整理
一个用于数据整理和文件导出的JavaScript脚本,但是,请注意,这个脚本本身并不创建文件夹和文件,它只是将输入数据转换成一种易于存储的格式。实际的文件存储操作需要由后续步骤完成。
// 用来记录每个 title 的当前计数
const titleCounter = {};
const outputItems = [];
for (const item of $input.all()) {
const currentTitle = item.json["title"].replace(/[\/\\:?*"<>|]/g, "_"); // 替换特殊字符
const currentBlockTitle = item.json["block_title"].replace(/[\/\\:?*"<>|]/g, "_");
// 给当前 title 初始化/递增计数
if (!titleCounter[currentTitle]) {
titleCounter[currentTitle] = 1;
} else {
titleCounter[currentTitle]++;
}
const currentCount = titleCounter[currentTitle];
// 生成文件夹名称(就是 title 替换特殊字符后)
const directory = currentTitle;
// 生成无特殊字符的 fileName(把计数放到前面)
const fileName = `${currentCount}_${currentBlockTitle}`;
// 清理 content 里重复的内容
const cleanContent = item.json["content"]
.replace(/\[标题:.*?\]\n?/g, "")
.replace(/\[分类:.*?\]\n?/g, "");
// 生成 mergedContent
const mergedContent = `Title: ${item.json["title"]}
Block Title: ${item.json["block_title"]}
Category: ${item.json["category"]}
Level: ${item.json["level"]}
Parent Title: ${item.json["parent_title"]}
Content: ${cleanContent || "-"}
`;
outputItems.push({
json: {
directory: directory, // 文件夹名称
fileName: fileName,
mergedContent: mergedContent
}
});
}
return outputItems;- 为每个title维护一个计数器
- 相同title的内容会获得递增编号
具体执行步骤
1. 输入数据处理
- 遍历所有输入项(
$input.all()) - 每个输入项包含:title, block_title, category, level, parent_title, content
2. 文件名安全处理
// 移除文件名中的非法字符
const currentTitle = item.json["title"].replace(/[\/\\:?*"<>|]/g, "_");3. 计数管理
const titleCounter = {};
for (const item of $input.all()) {
const currentTitle = item.json["title"].replace(/[\/\\:?*"<>|]/g, "_");
// 计数管理关键代码
if (!titleCounter[currentTitle]) {
titleCounter[currentTitle] = 1;
} else {
titleCounter[currentTitle]++;
}
const currentCount = titleCounter[currentTitle];
// 使用计数生成文件名
const fileName = `${currentCount}_${currentBlockTitle}`;
}第1步:初始化空对象
const titleCounter = {}; // 开始是空对象: {}第2步:处理第一个项目
假设第一个项目的 title 是 “aaaaa”:
const currentTitle = “aaaaa”; // 替换特殊字符后
检查是否存在:
// titleCounter["aaaaa"] 是 undefined
if (!titleCounter[currentTitle]) { // !undefined = true
titleCounter[currentTitle] = 1; // 现在 titleCounter = {"aaaaa": 1}
}获取当前计数:const currentCount = 1;
第3步:处理第二个项目
假设第二个项目也是 “aaaaa”:
const currentTitle = "aaaaa";
// 检查是否存在:
if (!titleCounter[currentTitle]) { // !1 = false,进入else分支
// 跳过...
} else {
titleCounter[currentTitle]++; // titleCounter["aaaaa"] 从1变成2
}
const currentCount = 2; // 现在计数是2第4步:处理不同title的项目
假设第三个项目的 title 是 “bbbbb”:
const currentTitle = "bbbbb";
// 检查是否存在:
if (!titleCounter[currentTitle]) { // !undefined = true
titleCounter[currentTitle] = 1; // titleCounter = {"aaaaa": 2, "bbbbb": 1}
}
const currentCount = 1; // 新title从1开始计数内存状态变化示例
假设输入数据顺序为:
- “aaaaa” – 变量声明
- “aaaaa” – 函数定义
- “bbbbb” – 基础语法
- “aaaaa” – 数组方法
titleCounter 的状态变化:
| 步骤 | currentTitle | 检查结果 | 执行操作 | titleCounter 状态 |
|---|---|---|---|---|
| 1 | aaaaa | 不存在 | 初始化为1 | {“aaaaa基础”: 1} |
| 2 | aaaaa | 存在(1) | 递增为2 | {“aaaaa基础”: 2} |
| 3 | bbbbb | 不存在 | 初始化为1 | {“aaaaa基础”: 2, “bbbbb教程”: 1} |
| 4 | aaaaa | 存在(2) | 递增为3 | {“aaaaa基础”: 3, “bbbbb教程”: 1} |
文件命名结果
基于上面的例子,生成的文件名为:
aaaaa基础/1_变量声明
aaaaa基础/2_函数定义
bbbbb教程/1_基础语法
aaaaa基础/3_数组方法4. 内容清理
// 移除content中的冗余信息
const cleanContent = item.json["content"]
.replace(/\[标题:.*?\]\n?/g, "")
.replace(/\[分类:.*?\]\n?/g, "");5. 输出结构生成
每个输出项包含:
directory: 文件夹名(基于title)fileName: 文件名(格式:序号_blockTitle)mergedContent: 整理后的完整内容
生成文件
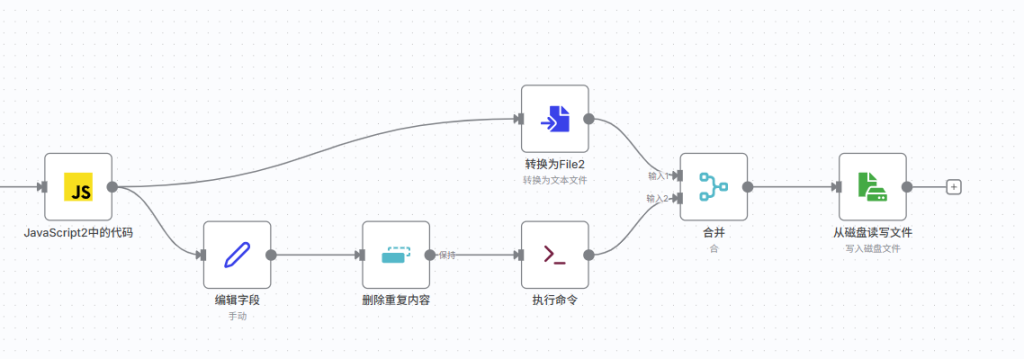
然后我们拉出一个分支节点,在数据转化里面选择转化为文件,按图中像我进行这样配置。
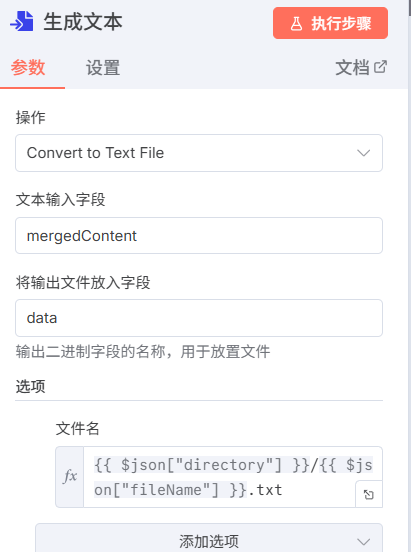
集合文章标题
然后拧出另外一条分支,选择编辑字段节点,像我进行这样配置。
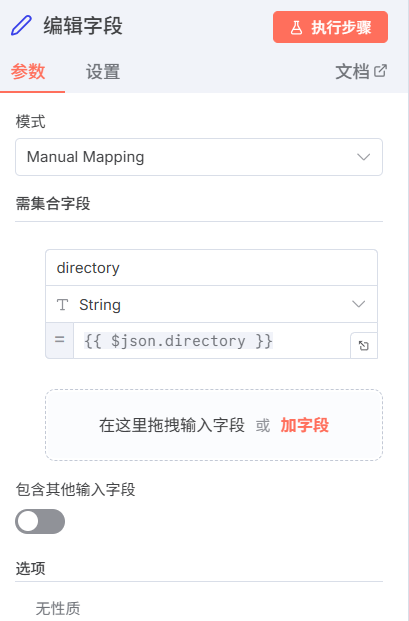
去除重复标题
然后继续沿着这个节点添加,删除重复内容节点,如图配置,
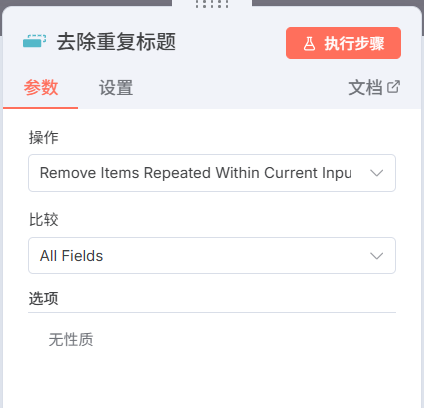
生成文件夹
接下来选择执行命令节点,进行如图配置(前提是你已经按照上一篇文章进行了同样的配置,没有也照着抄一下)
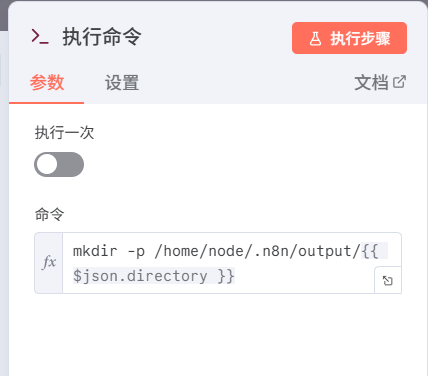
传递文本
现先照我做,至于为什么我节点配置完之后再讲。生产文本的结果作为输入1,生成文件夹的结果作为输入2
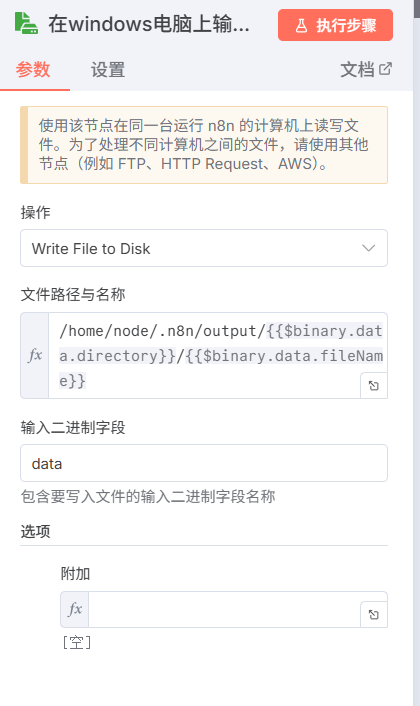
在windows电脑上输出文件
补充说明
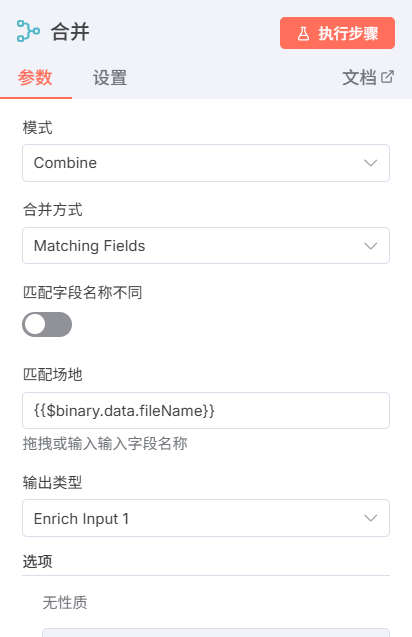
由于n8n抽象的对于分支任务的处理方式,如果你不能保证在向磁盘输入文件放在工作流程中最后一个处罚的时候,他就会有可能因为你的文件夹还没有创建好而就返回会找到该文件的问题,并且还有一点在n8n的最新版本中它部分去除了如果没有找到该文件夹,则就创建该文件夹的选项,真是越更新越回去了,所以我们为了解决上述的问题,我们就要想着让他在在创建文件夹完成之后再执行,我们可以利用n8n的另外一个机制,就是对于merge节点会等到所有输入端都有输入或者某一输入端传来报错的时候才开始执行,所以我们在merge节点里面选择在模式选将匹配的物品合并在一起,合并方式是将字段值相同的物品进行合并,选择{{$binary.data.fileName}},匹配场地输出类型选择所有输入1,将复合结果的输入二数据加入。
反正最后连完图应该是长这个样子。