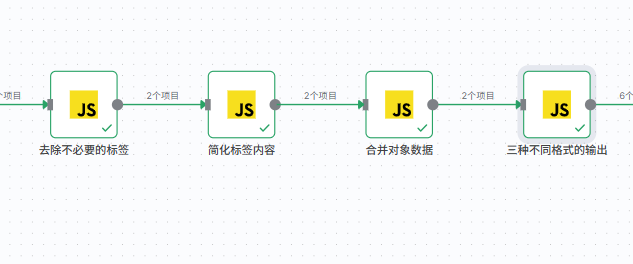
初步切割文章
去除不必要的标签
// 强制获取所有输入对象,for循环遍历无遗漏,过滤逻辑绝对精准
const allItems = $input.all();
for (let i = 0; i < allItems.length; i++) {
const item = allItems[i];
// 强制处理每个对象的class_list,排除空值/非数组情况
item.json.class_list = (item.json.class_list || []).filter(str => str && str.includes('category'));
}
return allItems;逐行解析
// 强制获取所有输入对象,for循环遍历无遗漏,过滤逻辑绝对精准
const allItems = $input.all();- 获取所有输入项并存储在
allItems变量中 $input.all()可能是某个框架或环境提供的API
for (let i = 0; i < allItems.length; i++) {
const item = allItems[i];- 使用传统的for循环遍历所有项目
- 获取当前遍历的项目
// 强制处理每个对象的class_list,排除空值/非数组情况
item.json.class_list = (item.json.class_list || []).filter(str =>
str && str.includes('category')
);核心处理逻辑:
item.json.class_list || []– 确保class_list存在,如果为null/undefined则使用空数组.filter(str => str && str.includes('category'))– 过滤条件:str– 确保字符串不为空str.includes('category')– 只保留包含”category”的字符串
return allItems;返回处理后的所有项目
简化标签内容
这段代码遍历所有数据项,移除class_list数组中每个字符串元素的"category-"前缀
// n8n 脚本:移除 class_list 中元素的 category- 前缀
items.forEach(item => {
if (item.json?.class_list && Array.isArray(item.json.class_list)) {
item.json.class_list = item.json.class_list.map(cls =>
typeof cls === 'string' ? cls.replace('category-', '') : cls
);
}
});
return items;逐行解析
items.forEach(item => {使用forEach方法遍历items数组中的所有项目
if (item.json?.class_list && Array.isArray(item.json.class_list)) {安全检查:
item.json?.class_list– 使用可选链操作符安全地访问嵌套属性Array.isArray(item.json.class_list)– 确保class_list确实是数组类型- 只有同时满足这两个条件才会执行后续处理
item.json.class_list = item.json.class_list.map(cls =>
typeof cls === 'string' ? cls.replace('category-', '') : cls
);核心处理逻辑:
- 使用
map方法遍历class_list数组中的每个元素 typeof cls === 'string'– 检查元素是否为字符串类型cls.replace('category-', '')– 如果是字符串,移除其中的"category-"前缀: cls– 如果不是字符串,保持原值不变
return items;返回处理后的所有项目
合并对象数据
这段代码将原始数据中的标题、分类和内容三个字段提取出来,按照特定格式拼接成一个结构化的文章内容。
// n8n 脚本:合并属性为统一文章结构,格式精准匹配需求
items.forEach(item => {
const originData = item.json;
// 提取标题(默认空值兜底)
const titleStr = originData.title?.rendered || '';
// 提取分类(数组转字符串,空数组兜底空值)
const classStr = Array.isArray(originData.class_list) ? originData.class_list.join(',') : '';
// 提取内容(默认空值兜底)
const contentStr = originData.content?.rendered || '';
// 构建目标结构:标题+分类+内容按顺序拼接,换行分隔
const articleContent = `[标题:${titleStr}]\n[分类:${classStr}]\n${contentStr}`;
// 覆盖原数据为最终格式
item.json = {
"文章": articleContent
};
});
return items;这个代码呢?没什么好讲的差不多我们讲他们的异同点。
循环遍历方式
// 脚本1:传统for循环
for (let i = 0; i < allItems.length; i++) {
const item = allItems[i];
// 处理逻辑
}
// 脚本2&3:现代forEach
items.forEach(item => {
// 处理逻辑
});- 脚本1使用索引访问,更底层但更繁琐
- 脚本2,3使用迭代器模式,代码更简洁
数据访问和安全处理
// 脚本1:使用 || 操作符
item.json.class_list = (item.json.class_list || []).filter(...)
// 脚本2:使用可选链 + 类型检查
if (item.json?.class_list && Array.isArray(item.json.class_list)) {
item.json.class_list = item.json.class_list.map(...)
}
// 脚本3:混合使用可选链和 ||
const titleStr = originData.title?.rendered || '';
const classStr = Array.isArray(originData.class_list) ? ... : '';数组处理方法
// 脚本1:filter - 过滤元素
.filter(str => str && str.includes('category'))
// 脚本2:map - 转换元素
.map(cls => typeof cls === 'string' ? cls.replace('category-', '') : cls)
// 脚本3:join - 数组合并为字符串
.join(',')- 脚本1:筛选 – 从数组中移除不符合条件的元素
- 脚本2:映射 – 将每个元素转换为新值
- 脚本3:归并 – 将整个数组合并为单个字符串
数据处理范围
// 脚本1&2:局部修改
item.json.class_list = ... // 只修改class_list字段
// 脚本3:完全重构
item.json = {
"文章": articleContent // 替换整个json对象
}- 脚本1&2:增量更新 – 保留其他字段,只修改目标字段
- 脚本3:完全替换 – 丢弃所有原始数据,创建新结构
字符串处理技术
// 脚本1:includes - 内容检查
str.includes('category')
// 脚本2:replace - 字符串替换
cls.replace('category-', '')
// 脚本3:模板字符串 + 连接
`[标题:${titleStr}]\n[分类:${classStr}]\n${contentStr}`代码结构复杂度
// 脚本1:单行链式操作
(item.json.class_list || []).filter(str => str && str.includes('category'))
// 脚本2:条件块 + 映射
if (条件) {
item.json.class_list = array.map(转换函数)
}
// 脚本3:多变量提取 + 复杂构建
const titleStr = ...
const classStr = ...
const contentStr = ...
const articleContent = `复杂模板`
item.json = {新结构}三种不同格式的输出
这个脚本的主要功能是:将结构化的文章内容解析成三种不同格式的输出(原始、扁平化、树状),用于文章内容的结构化分析和展示。
const items = $input.all();
const result = items.map(item => {
// 定义拆分函数
const splitArticle = (content) => {
if (!content || content.trim() === '') return [{ title: '无有效内容', content: '', hierarchy: '0' }];
const lines = content.split('\n').filter(line => line.trim() !== '');
const segments = [];
let currentSegment = null;
const levelCounters = [0, 0, 0, 0, 0];
let lastLevel = 0;
const parseTitleLevel = (titleStr) => {
const match = titleStr.match(/^(\d?)级?标题:/);
if (match) {
return match[1] === '' ? 1 : parseInt(match[1]);
}
return null;
};
lines.forEach(line => {
const titleMatch = line.match(/^\[(.*?标题:.+?)\]$/);
if (titleMatch) {
const level = parseTitleLevel(titleMatch[1]);
if (level !== null) {
if (currentSegment) segments.push(currentSegment);
if (level <= lastLevel) {
for (let i = level + 1; i < levelCounters.length; i++) {
levelCounters[i] = 0;
}
}
levelCounters[level]++;
lastLevel = level;
const hierarchy = levelCounters.slice(1, level + 1).join('.');
currentSegment = {
title: titleMatch[1],
content: '',
level: level,
hierarchy: hierarchy,
parent: level > 1 ? levelCounters.slice(1, level).join('.') : null
};
}
} else if (currentSegment) {
currentSegment.content += line + '\n';
}
});
if (currentSegment) segments.push(currentSegment);
return segments;
};
// 定义构建树函数
const buildTree = (flatSegments) => {
const map = new Map();
const roots = [];
flatSegments.forEach(segment => {
segment.children = [];
map.set(segment.hierarchy, segment);
});
flatSegments.forEach(segment => {
if (segment.parent) {
const parent = map.get(segment.parent);
if (parent) {
parent.children.push(segment);
} else {
roots.push(segment);
}
} else {
roots.push(segment);
}
});
return roots;
};
// 提取文章主标题作为文件名的一部分
const extractMainTitle = (content) => {
// 查找第一个标题
const firstTitleMatch = content.match(/\[(.*?标题:(.+?))\]/);
if (firstTitleMatch && firstTitleMatch[2]) {
// 清理标题,移除可能的不合法文件名字符
let cleanTitle = firstTitleMatch[2]
.replace(/[<>:"/\\|?*]/g, '') // 移除Windows不合法字符
.replace(/\s+/g, '_') // 空格替换为下划线
.substring(0, 50); // 限制长度
return cleanTitle || '未命名文章';
}
return '未命名文章';
};
// 主处理逻辑
const flatSegments = splitArticle(item.json.文章);
const treeStructure = buildTree(flatSegments);
// 提取文章主标题用于文件名
const mainTitle = extractMainTitle(item.json.文章);
// 1. 原始文章
const originalArticle = item.json.文章;
// 2. 扁平化结构文本
const flatText = flatSegments.map(segment =>
`${segment.hierarchy} ${segment.title}\n${segment.content.trim()}\n${'-'.repeat(50)}`
).join('\n\n');
// 3. 树形结构文本
const formatTree = (nodes, indent = '') => {
return nodes.map(node => {
let result = `${indent}${node.hierarchy} ${node.title}\n`;
if (node.content.trim()) {
result += `${indent} 内容: ${node.content.trim().replace(/\n/g, ' ')}\n`;
}
if (node.children && node.children.length > 0) {
result += formatTree(node.children, indent + ' ');
}
return result;
}).join('\n');
};
const treeText = formatTree(treeStructure);
// 返回三个文件,文件名包含文章标题
return [
{
json: {
fileName: `原始${mainTitle}.txt`,
content: originalArticle,
mimeType: 'text/plain'
}
},
{
json: {
fileName: `扁平${mainTitle}.txt`,
content: flatText,
mimeType: 'text/plain'
}
},
{
json: {
fileName: `树状${mainTitle}.txt`,
content: treeText,
mimeType: 'text/plain'
}
}
];
}).flat();
return result;详细代码解析
const items = $input.all();
const result = items.map(item => {
// 对每个输入项进行处理
}).flat();$input.all(): 获取所有输入项map(): 遍历每个项目进行处理flat(): 将嵌套数组展平(因为每个项目会生成3个输出文件)
核心拆分函数 splitArticle
const splitArticle = (content) => {
if (!content || content.trim() === '') return [{ title: '无有效内容', content: '', hierarchy: '0' }];
const lines = content.split('\n').filter(line => line.trim() !== '');
const segments = [];
let currentSegment = null;
const levelCounters = [0, 0, 0, 0, 0]; // 用于5级标题计数
let lastLevel = 0;关键数据结构:
levelCounters: 跟踪各级标题的编号(如1.1, 1.2, 2.1等)segments: 存储解析出的文章段落
标题级别解析函数
const parseTitleLevel = (titleStr) => {
const match = titleStr.match(/^(\d?)级?标题:/);
if (match) {
return match[1] === '' ? 1 : parseInt(match[1]);
}
return null;
};正则表达式解析:
^(\d?)级?标题:匹配类似"1级标题:"、"标题:"、"2级标题:"的格式- 如果没有数字,默认为1级标题
行处理逻辑
lines.forEach(line => {
const titleMatch = line.match(/^\[(.*?标题:.+?)\]$/);
if (titleMatch) {
const level = parseTitleLevel(titleMatch[1]);
if (level !== null) {
// 遇到新标题,保存当前段落
if (currentSegment) segments.push(currentSegment);
// 重置子级计数器(重要!)
if (level <= lastLevel) {
for (let i = level + 1; i < levelCounters.length; i++) {
levelCounters[i] = 0;
}
}
// 更新当前级别计数器
levelCounters[level]++;
lastLevel = level;
// 生成层级编号(如 "1.2.1")
const hierarchy = levelCounters.slice(1, level + 1).join('.');
// 创建新段落
currentSegment = {
title: titleMatch[1], // 完整标题文本
content: '', // 内容部分
level: level, // 标题级别(1-5)
hierarchy: hierarchy, // 层级编号 "1.2.3"
parent: level > 1 ? levelCounters.slice(1, level).join('.') : null // 父级编号
};
}
} else if (currentSegment) {
// 非标题行,添加到当前段落内容
currentSegment.content += line + '\n';
}
});层级编号生成示例:
1级标题 → hierarchy: "1", parent: null
2级标题 → hierarchy: "1.1", parent: "1"
3级标题 → hierarchy: "1.1.1", parent: "1.1"
2级标题 → hierarchy: "1.2", parent: "1" ← 注意这里计数器重置 树形结构构建函数 buildTree
const buildTree = (flatSegments) => {
const map = new Map(); // 用于快速查找节点
const roots = []; // 根节点数组
// 初始化所有节点,添加children属性
flatSegments.forEach(segment => {
segment.children = [];
map.set(segment.hierarchy, segment);
});
// 构建父子关系
flatSegments.forEach(segment => {
if (segment.parent) {
const parent = map.get(segment.parent);
if (parent) {
parent.children.push(segment);
} else {
roots.push(segment); // 父节点不存在,当作根节点
}
} else {
roots.push(segment); // 没有父节点,就是根节点
}
});
return roots;
};树形结构构建过程:
- 创建映射表,方便通过层级编号快速查找
- 为每个节点初始化子节点数组
- 根据parent属性建立父子关系
文件名提取函数 extractMainTitle
const extractMainTitle = (content) => {
const firstTitleMatch = content.match(/\[(.*?标题:(.+?))\]/);
if (firstTitleMatch && firstTitleMatch[2]) {
let cleanTitle = firstTitleMatch[2]
.replace(/[<>:"/\\|?*]/g, '') // 移除非法文件名字符
.replace(/\s+/g, '_') // 空格转下划线
.substring(0, 50); // 限制长度
return cleanTitle || '未命名文章';
}
return '未命名文章';
};三种输出格式生成
原始格式
const originalArticle = item.json.文章; // 保持原样扁平化格式
const flatText = flatSegments.map(segment =>
`${segment.hierarchy} ${segment.title}\n${segment.content.trim()}\n${'-'.repeat(50)}`
).join('\n\n');输出示例:
1 1级标题:引言
这是引言内容...
--------------------------------------------------
1.1 2级标题:背景
背景内容描述...
--------------------------------------------------树状格式
const formatTree = (nodes, indent = '') => {
return nodes.map(node => {
let result = `${indent}${node.hierarchy} ${node.title}\n`;
if (node.content.trim()) {
result += `${indent} 内容: ${node.content.trim().replace(/\n/g, ' ')}\n`;
}
if (node.children && node.children.length > 0) {
result += formatTree(node.children, indent + ' '); // 递归处理子节点
}
return result;
}).join('\n');
};输出示例:
1 1级标题:引言
内容: 这是引言内容...
1.1 2级标题:背景
内容: 背景内容描述...
1.2 2级标题:目标
内容: 目标描述...最终输出结构
每个输入项目生成3个输出文件:
return [
{ json: { fileName: `原始${mainTitle}.txt`, content: originalArticle, ... } },
{ json: { fileName: `扁平${mainTitle}.txt`, content: flatText, ... } },
{ json: { fileName: `树状${mainTitle}.txt`, content: treeText, ... } }
];连完线就长这样子,没什么好说的单行道
文件输出到本机
权限配置
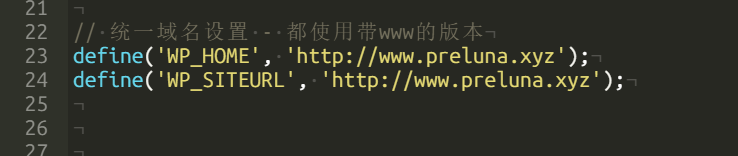
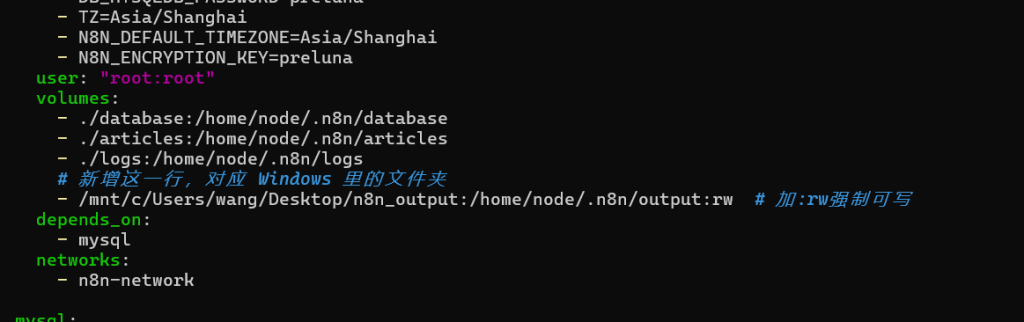
添加这一行对应windows系统里的文件夹(注意缩进)
user: "root:root"
- /mnt/c/Users/你的用户名/Desktop/n8n_output:/home/node/.n8n/output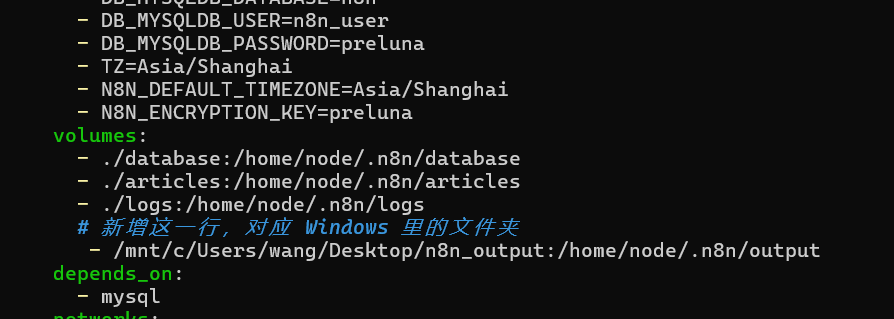
生效修改的命令
修改完 docker-compose.yml 后,执行下面的命令让配置生效:
# 停止并重新创建容器(保留数据)
docker-compose up -d --force-recreate
#如果不能生效的话,就采用这个
docker-compose up -d --build验证挂载成功
检查挂载是否成功,你可以分几步操作,从 WSL2 本地 到 Docker 容器内 依次验证:
步骤 1:先在 WSL2 里验证 Windows 路径的访问
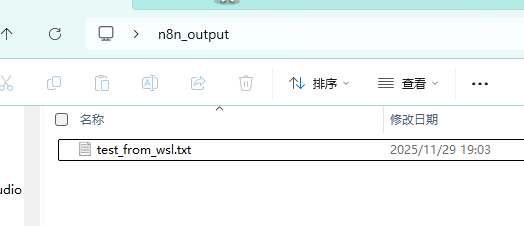
1. 执行命令进入你挂载的 Windows 文件夹:
cd /mnt/c/Users/wang/Desktop/n8n_output2. 创建一个测试文件:
touch test_from_wsl.txt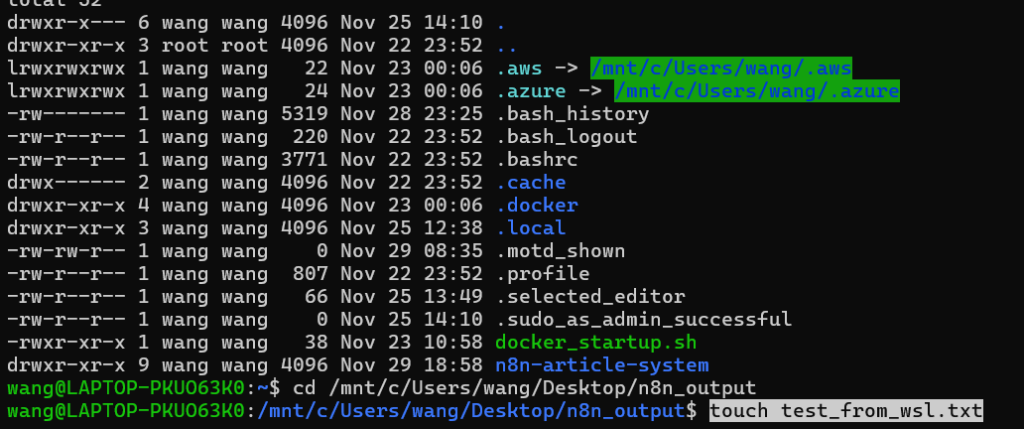
3. 去 Windows 的 C:\Users\wang\Desktop\n8n_output 里看,会出现 test_from_wsl.txt 文件,说明 WSL2 能正常访问 Windows 文件夹。
步骤 2:进入 Docker 容器内验证挂载
1. 先进入 n8n 容器:
docker exec -it n8n-article-system sh2. 进入容器内的挂载路径:
cd /home/node/.n8n/output3. 创建一个测试文件:
touch test_from_container.txt
4. 回到 WSL2 或 Windows 的 n8n_output 文件夹,会出现 test_from_container.txt 文件,说明容器内的挂载生效了。
步骤 3:验证 n8n 能写入文件
也可以在 n8n 里添加一个 Write Binary File 节点,配置路径为 /home/node/.n8n/output/test_from_n8n.txt ,写入一些内容后执行,然后去 Windows 文件夹里检查文件是否存在
1.添加“Write Binary File”节点
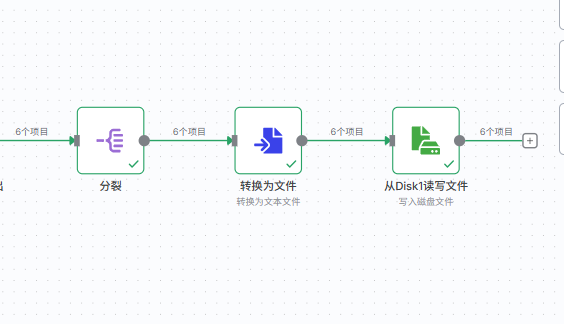
- 在你的工作流里,找到之前的“分裂”节点,点击它后面的“+”号,添加一个新节点。
- 搜索并选择 “Write Binary File”(如果没找到,也可以用“Local File”节点,功能类似)。
2.配置节点
- 文件路径:填写容器内的挂载路径,也就是 /home/node/.n8n/output/test_n8n_write.txt 。
- 数据:选择“Expression”模式,输入一段测试内容,比如 “这是来自n8n的测试内容” 。(或者直接选择之前节点的输出内容,比如 /home/node/.n8n/output/{{$binary.data.fileName}} 这样的变量)
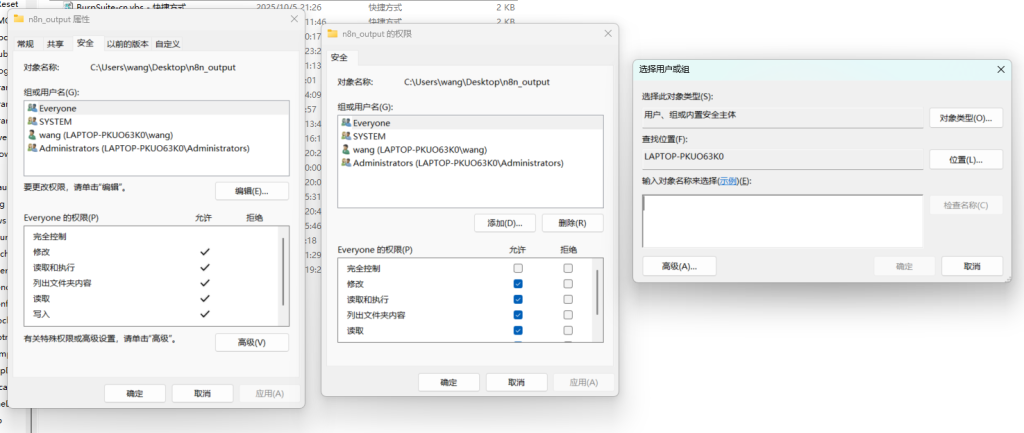
步骤4:Windows本机上文件夹权限
右键文件夹并点击属性,找到安全一栏并且点击编辑,再点击添加,添加对象Everyone,并添加权限可修改
节点设置
分裂
[
{
"fileName": "原始生效修改的命令.txt",
"content": "",
"mimeType": ""
},
{
"fileName": "扁平生效修改的命令.txt",
"content": "0",
"mimeType": ""
},
{
"fileName": "树状生效修改的命令.txt",
"content": "",
"mimeType": "text/plain"
},
{
"fileName": "原始标题拆分测试.txt",
"content": "",
"mimeType": "text/plain"
},
{
"fileName": "扁平标题拆分测试.txt",
"content": "",
"mimeType": "text/plain"
},
{
"fileName": "树状标题拆分测试.txt",
"content": "",
"mimeType": "text/plain"
}
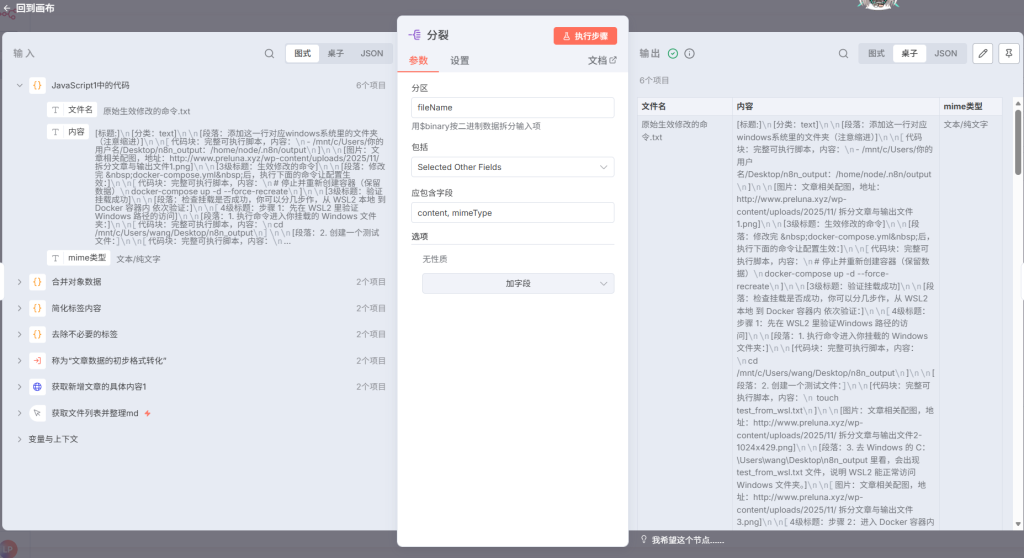
]你看我们之前提取过的脚本文件长这个样子,但是呢,我们到现在是相当于一个一口气说出6个对象,它是放在一个数组里面,所以他看起来会非常混乱,所以我们需要设置一点点把他们给拆开来,相当于拆成6个节点的输入,也实际上就是6个宿主,但是呢,每个数组里面只有一个对象,然后再进行输出。
Convert to File
Read/Write Files from Disk1
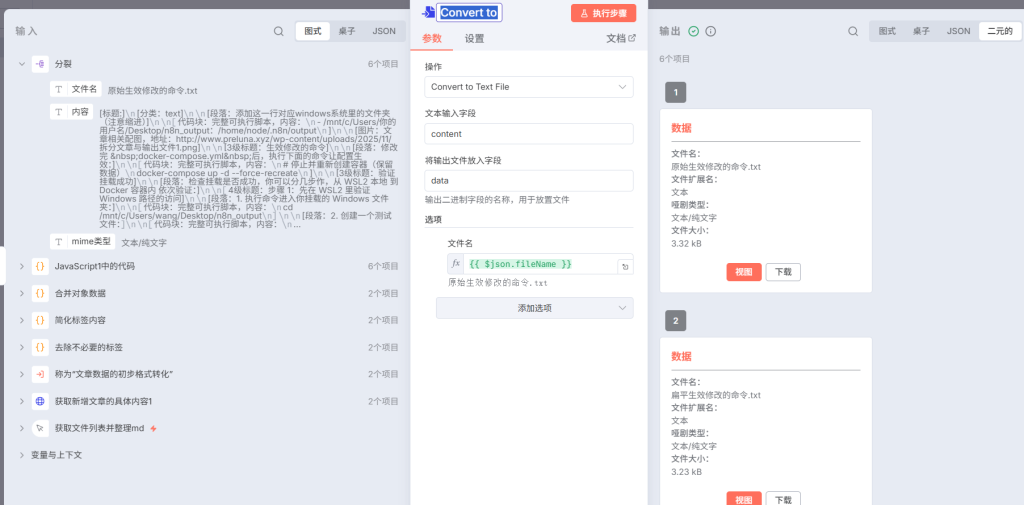
这里呢?除了在保证前面的那个权限配置要配置完成之后,这里搞特别注意的一点,由于我们转化文件输出的结果是在binary里面还能查到,所以说我们后续在设计这个标题的话我们就要采用这么一种方式{{$binary.data.fileName}}引入,而且你这边只能你进行手动输,因为n8n狗屎一样的傻逼数据传递机制,非常左右脑互补,我也不知道他们是怎么想的(这个我后续会专门出文章来讲n8n节点与节点之间到底是怎么进行通信的,由于这里受篇幅所限就不过多讲述了)
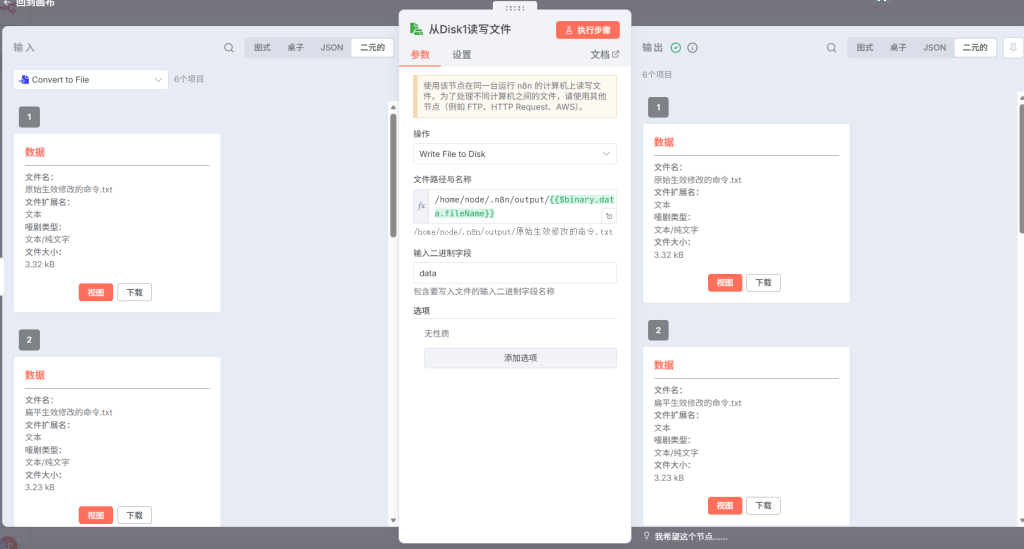
最后的结果应该是这个样子