在上一篇文章中,网站的提取与分类,我们虽然提取的文章的数据行了初步的的转换,但是呢,他看上去仍是有点复杂,为了能让他转化成封闭我们观看的格式,我们需要对它有个总体的大概:篇文章里面有什么样的结构?如果在他们的元数据里面他们是怎么标识的呢?这些东西如果呢,你是从头开始开发设计的话,你会有跟我一样有一个非常详细的理解,但是呢,如果你对前端对PHP代码理解没有那么深入的话,你也可以参照我我以下的文章对他们有一个初步的概念理解,你按照我的方法做也是可以把他们给进行提取完毕的
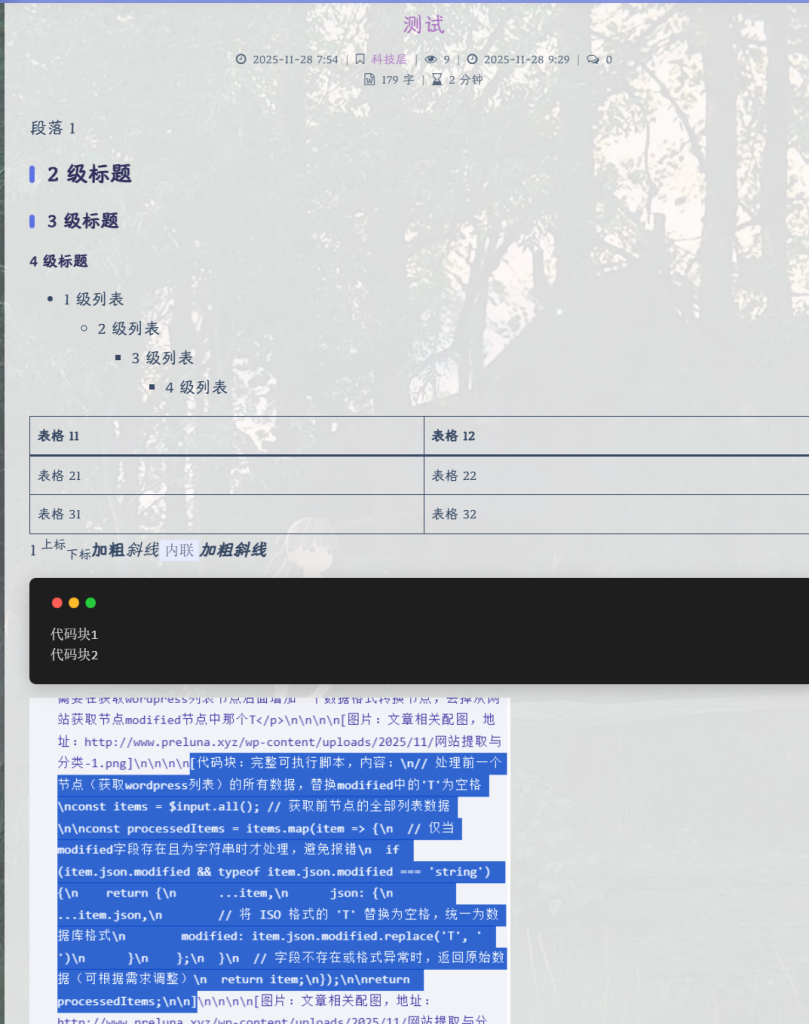
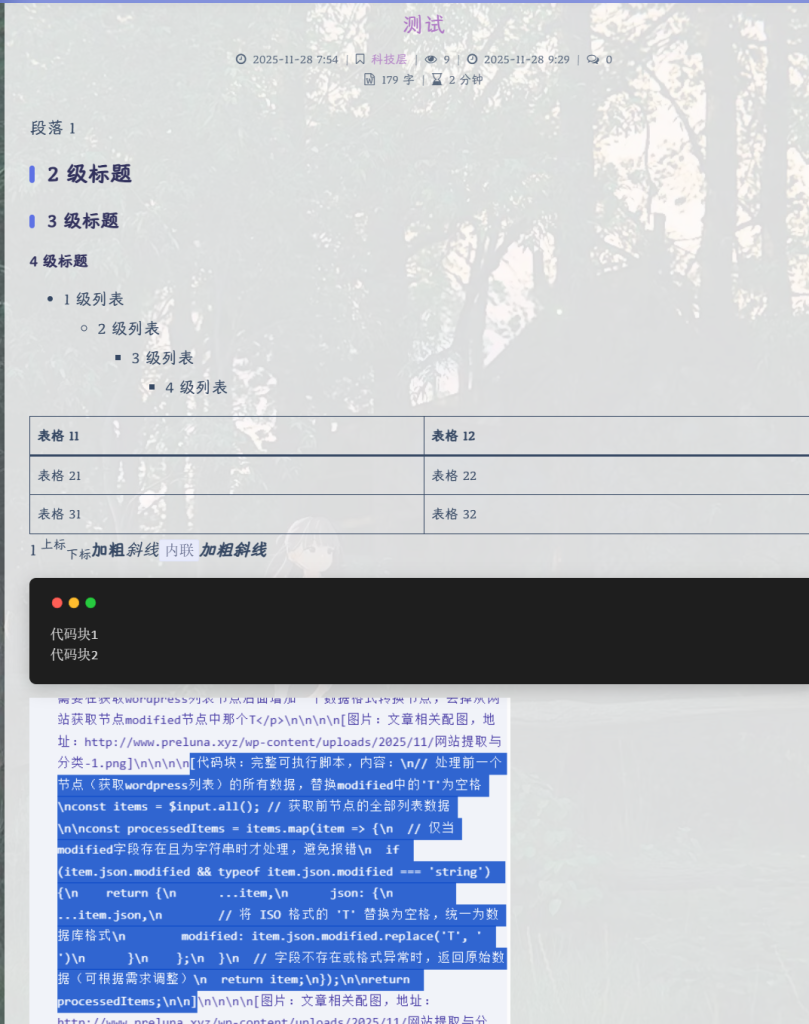
首先呢,我先创建了一个测试文章,那里面包含三个不同级别的标题1个段落,4层列表,1个2×2但是有表头的表格,1个上标,1个下标,1个加粗,1个斜线,1个内联,1个加粗斜线,1张图片,1个上标加粗斜线,1个下标加粗斜线,以及还有1个在后面会用重点测试的复杂的4层嵌套
创建数据处理节点
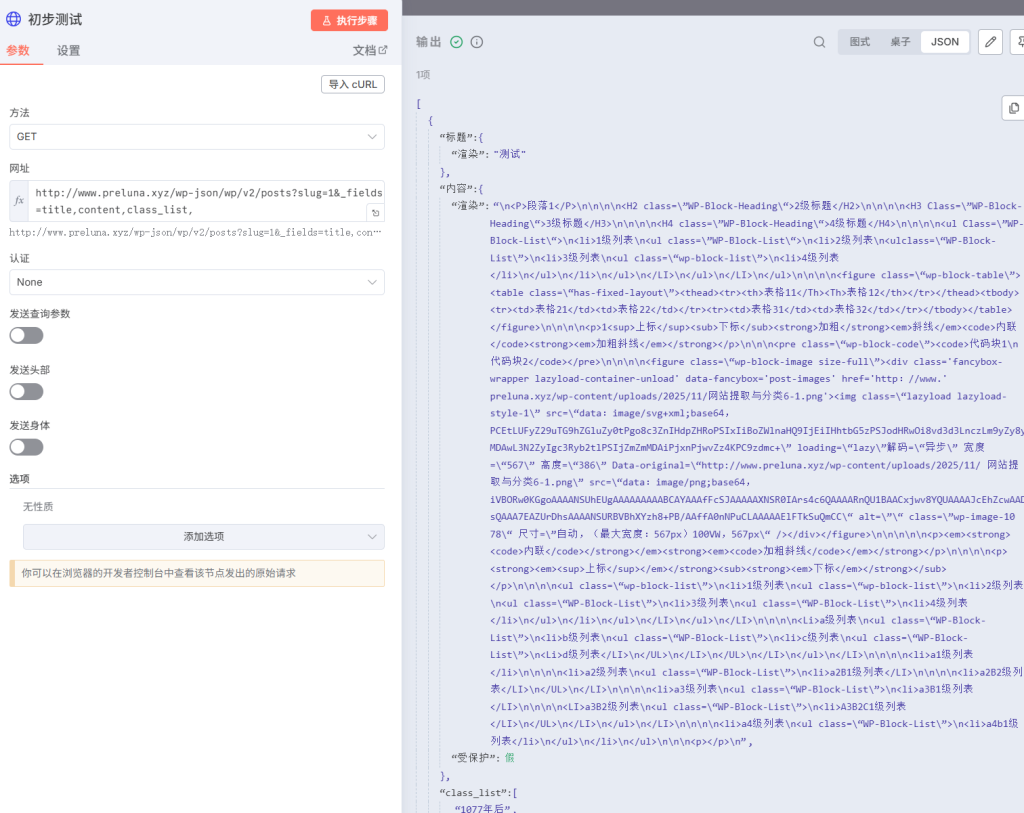
初步测试
http://www.preluna.xyz/wp-json/wp/v2/posts?slug=1&_fields=title,content,class_list,参数slug定向拉取test文章,参数_fields=title,content,class_list请拉取标题,内容,标签。
处理图片
首先呢,我们在拉取的数据里面寻找figure class=\“wp-block-image size-full和’post-images’ href=’http://www.’ preluna.xyz/wp-content/uploads/2025/11/网站提取与分类6-1.png这种含有image或png的标签,以及我们知道前端引用图片是根据是根据链接的,可以找到这种herf=xxxxxx这种内容
<figure class=\“wp-block-image size-full\”><div class='fancybox-wrapper lazyload-container-unload' data-fancybox='post-images' href='http://www.' preluna.xyz/wp-content/uploads/2025/11/网站提取与分类6-1.png'><img class=\“lazyload lazyload-style-1\” src=\“data:image/svg+xml;base64,PCEtLUFyZ29uTG9hZGluZy0tPgo8c3ZnIHdpZHRoPSIxIiBoZWlnaHQ9IjEiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyIgc3Ryb2tlPSIjZmZmMDAiPjxnPjwvZz4KPC9zdmc+\” loading=\“lazy\”解码=\“异步\” 宽度=\“567\” 高度=\“386\” Data-original=\“http://www.preluna.xyz/wp-content/uploads/2025/11/ 网站提取与分类6-1.png\” src=\“data:image/png;base64, iVBORw0KGgoAAAANSUhEUgAAAAAAAAABCAYAAAfFcSJAAAAAXNSR0IArs4c6QAAAARnQU1BAACxjwv8YQUAAAAJcEhZcwAADsQAAA7EAZUrDhsAAAANSURBVBhXYzh8+PB/AAffA0nNPuCLAAAAAElFTkSuQmCC\“ alt=\”\“ class=\”wp-image-10 78\“ 尺寸=\”自动,(最大宽度:567px)100VW,567px\“ /></div></figure>所以我们就基于此编写代码将里面的请求进行化简,以便后续进行处理。
// 获取输入数据
const inputData = $input.all();
// 处理每个条目
const outputData = inputData.map(item => {
let contentRendered = item.json.content.rendered;
// 更严格的正则:仅匹配class为wp-block-image的figure,且精准定位img的data-original
const imgRegex = /<figure class="wp-block-image(?: [^"]+)?"[^>]*>\s*<div[^>]*>\s*<img[^>]*data-original="([^"]+)"[^>]*>\s*<\/div>\s*<\/figure>/gi;
contentRendered = contentRendered.replace(imgRegex, (match, imgUrl) => {
// 保持AI易读的图片标记
return `[图片:文章相关配图,地址:${imgUrl}]`;
});
// 返回处理后的数据
return {
...item.json,
content: {
...item.json.content,
rendered: contentRendered
}
};
});
// 输出结果
return outputData;1.代码逐行解析
const inputData = $input.all();- $input.all() 是n8n特有的方法,获取所有输入数据
- 通常包含从上一节点传递过来的文章数据
2.数据处理循环
const outputData = inputData.map(item => {- 使用 map() 方法遍历每个数据项
- 对每篇文章进行独立的处理
3. 内容提取
let contentRendered = item.json.content.rendered;- 提取WordPress文章的HTML内容
- 假设数据结构为:
{json: {content: {rendered: "HTML内容"}}}
核心:正则表达式详解
正则表达式分解
/<figure class="wp-block-image(?: [^"]+)?"[^>]*>\s*<div[^>]*>\s*<img[^>]*data-original="([^"]+)"[^>]*>\s*<\/div>\s*<\/figure>/gi各部分解析:
<figure class="wp-block-image- 匹配以
<figure class="wp-block-image开头的标签
- 匹配以
(?: [^"]+)?(?: )非捕获组,只匹配不捕获[^"]+匹配除双引号外的任意字符?表示这个class扩展是可选的- 示例:匹配
wp-block-image或wp-block-image size-large
"[^>]*>"匹配class属性结束的双引号[^>]*匹配除>外的任意字符(其他属性)>匹配标签结束
\s*<div[^>]*>\s*\s*匹配任意空白字符(空格、换行等)<div[^>]*>匹配div标签及其属性
- 关键部分:图片URL提取:
<img[^>]*data-original="([^"]+)"[^>]>([^"]+)捕获组 – 这是我们真正要提取的内容- 匹配
data-original="图片URL"中的URL - 圆括号
()表示捕获,可以在替换时通过$1或回调参数引
\s*<\/div>\s*<\/figure>- 匹配闭合的div和figure标签
\s*处理可能的缩进和换行
- 标志位
- 匹配(找到所有符合的)
i:忽略大小写
替换逻辑详解
contentRendered = contentRendered.replace(imgRegex, (match, imgUrl) => {
return `[图片:文章相关配图,地址:${imgUrl}]`;
});replace函数参数
match:整个匹配到的字符串(完整的figure HTML)imgUrl:第一个捕获组的内容(即图片URL)
替换过程示例:
替换前:
<figure class="wp-block-image">
<div class="image-wrapper">
<img data-original="http://www.' preluna.xyz/wp-content/uploads/2025/11/网站提取与分类6-1.png" >
</div>
</figure>替换后:[图片:文章相关配图,地址:http://www.’ preluna.xyz/wp-content/uploads/2025/11/网站提取与分类6-1.png]
数据返回

- 使用扩展运算符保持原有数据结构
- 只更新
content.rendered字段 - 保持其他所有字段不变
处理代码块
<pre class=\“WP-Block-Code\”><code>代码块1\n代码块2</code></pre>
<preclass=\“wp-block-code\”><code>代码块1\n<strong>代码块2</strong>\n<em>代码块3</em>\n<strong><em>代码块4</em></strong></code></pre>在咱们对图片标签进行处理了之后,我们接下来要对代码块进行处理,我们为什么选择优先选择代码快呢?我觉得代码块的标签非常明显这样具有特色,pre class=\“WP-Block-Code\和code,pre如此具有特征的东西,在其他地方是不常见的。当代码扩充可能也会有斜体加粗换行,但是我为什么我现在进行处理呢,这个原因我待会再来讲
const inputData = $input.all();
const outputData = inputData.map(item => {
let contentRendered = item.json.content.rendered;
// 精准匹配你的wp-block-code代码块结构,不影响其他文案
const codeRegex = /<pre class="wp-block-code"><code>([\s\S]*?)<\/code><\/pre>/gi;
contentRendered = contentRendered.replace(codeRegex, (_, code) => {
// 还原转义字符(如>→>、&→&),再包装成AI易读格式
const decodedCode = code.replace(/>/g, '>').replace(/&/g, '&');
return `[代码块:完整可执行脚本,内容:\n${decodedCode}\n]`;
});
return {
...item.json,
content: { ...item.json.content, rendered: contentRendered }
};
});
return outputData;
代码逐行解析
1. 数据获取和初始化
const inputData = $input.all();
const outputData = inputData.map(item => {
let contentRendered = item.json.content.rendered;与前一个脚本相同,获取输入数据并开始处理每篇文章
核心:正则表达式详解
正则表达式分解
const codeRegex = /<pre class="wp-block-code"><code>([\s\S]*?)<\/code><\/pre>/gi;各部分解析:
<pre class="wp-block-code"><code>- 匹配WordPress代码块的固定HTML结构
- 精确匹配
<pre class="wp-block-code">后紧跟<code>标签
- 关键部分:代码内容捕获
([\s\S]*?)[\s\S]:\s匹配所有空白字符(空格、换行、制表符等)\S匹配所有非空白字符- 组合起来
[\s\S]就相当于匹配任何字符,包括换行符
*?:非贪婪匹配- 匹配尽可能少的字符,直到遇到后面的
</code></pre> - 如果不加
?会匹配到最后一个</code></pre>
- 匹配尽可能少的字符,直到遇到后面的
<\/code><\/pre>- 匹配代码块的结束标签
- 注意:
/需要转义为\/
- 标志位
g:全局匹配i:忽略大小写
替换逻辑详解
contentRendered = contentRendered.replace(codeRegex, (_, code) => {
// 还原转义字符
const decodedCode = code.replace(/>/g, '>').replace(/&/g, '&');
return `[代码块:完整可执行脚本,内容:\n${decodedCode}\n]`;
});replace函数参数:
_:整个匹配到的字符串(完整的pre-code HTML结构)code:第一个捕获组的内容(即代码块内的实际代码)
HTML实体解码过程
const decodedCode = code.replace(/>/g, '>').replace(/&/g, '&');为什么要解码?
在HTML中,特殊字符会被转义:
>→>&→&<→<"→"
解码示例:
原始HTML:
<pre class="wp-block-code"><code>if (a > b) {
console.log("Hello & Welcome");
}</code></pre>匹配到的 code 参数:
if (a > b) {
console.log("Hello & Welcome");
}最终替换结果:
[代码块:完整可执行脚本,内容:
if (a > b) {
console.log("Hello & Welcome");
}
]细节
为什么用 [\s\S]*? 而不是 .*?
.*?默认不匹配换行符- 代码块通常包含多行代码,必须匹配换行符
[\s\S]是匹配包括换行符在内的所有字符的常用技巧
非贪婪匹配 *? 的重要性
假设有多个代码块
<pre class="wp-block-code"><code>第一段代码</code></pre>
其他内容
<pre class="wp-block-code"><code>第二段代码</code></pre>- 贪婪匹配
([\s\S]*)会匹配从第一个<pre>到最后一个</pre>的所有内容 - 非贪婪匹配
([\s\S]*?)会正确匹配每个独立的代码块
转义字符处理
当前脚本只处理了两种转义字符
>→>&→&
处理加粗标签
<strong>加粗</strong>这个码没什么好说的,他处理起来比代码块还要简单,只需要进行一个严格的匹配,和一个非贪婪就行了。
const inputData = $input.all();
const outputData = inputData.map(item => {
let contentRendered = item.json.content.rendered;
// 精准匹配你的wp-block-code代码块结构,不影响其他文案
const codeRegex = /<pre class="wp-block-code"><code>([\s\S]*?)<\/code><\/pre>/gi;
contentRendered = contentRendered.replace(codeRegex, (_, code) => {
// 还原转义字符(如>→>、&→&),再包装成AI易读格式
const decodedCode = code.replace(/>/g, '>').replace(/&/g, '&');
return `[代码块:完整可执行脚本,内容:\n${decodedCode}\n]`;
});
return {
...item.json,
content: { ...item.json.content, rendered: contentRendered }
};
});
return outputData;
1. 数据输入阶段
const inputData = $input.all();- 作用: 获取从前一个n8n节点传递过来的所有数据
- 返回值: 数组格式,包含多个文章数据项
- n8n特性:
$input.all()是n8n平台特有的全局方法
2. 数据处理循环
const outputData = inputData.map(item => {map()方法: 对输入数组中的每个元素执行相同的处理- 函数式编程: 不修改原数组,返回新数组
- 遍历处理: 对每篇文章独立处理,互不影响
3. 内容提取
let contentRendered = item.json.content.rendered;数据结构假设:
{
json: {
content: {
rendered: "<p>这是一段<strong>加粗</strong>文本</p>"
// 可能还有其他属性如raw、protected等
},
// 其他文章属性如title、excerpt等
}
}目标字段: 专门处理WordPress文章的HTML渲染内容
核心:正则表达式深度解析
正则表达式代码
const strongRegex = /<strong>|<\/strong>/gi;表达式分解说明
- 模式结构
<strong>|<\/strong>|或操作符: 匹配两种模式中的任意一种- 两部分:
<strong>: 开始标签<\/strong>: 结束标签(注意/需要转义)
- 具体匹配内容
- 第一部分:
<strong>- 匹配字符串:
<strong> - 精确匹配: 只匹配标准的开始标签
- 不匹配变体: 如
<strong class="custom">等带属性的标签
- 匹配字符串:
- 第二部分:
<\/strong>- 匹配字符串:
</strong> - 转义处理:
/字符在正则中需要转义为\/ - 精确匹配: 只匹配标准的结束标签
- 匹配字符串:
- 第一部分:
- 标志位解析
g(global): 全局匹配- 找到所有匹配项,不仅仅是第一个
- 如果没有
g,只会替换第一个遇到的标签
i(case-insensitive): 忽略大小写- 匹配
<STRONG>、<Strong>、<strong>等各种大小写变体
- 匹配
替换逻辑详细分析
替换操作
contentRendered = contentRendered.replace(strongRegex, '');参数说明:
- 第一个参数: 正则表达式
strongRegex - 第二个参数: 空字符串
''
替换效果:
- 将所有匹配到的
<strong>和</strong>标签替换为空字符串 - 相当于直接删除这些标签
- 保留标签内的文本内容不变
处理机制示例
替换过程:
// 原始内容
"这是一个<strong>重要</strong>的说明"
// 匹配过程
// 找到: "<strong>" → 替换为 ""
// 找到: "</strong>" → 替换为 ""
// 最终结果
"这是一个重要的说明"完整处理流程示例
多个标签处理
输入内容:
<p>这是<strong>第一段</strong>加粗文本,这是<strong>第二段</strong>加粗文本。</p>处理过程:
- 匹配第一个
<strong>→ 删除 - 匹配内层
<strong>→ 删除 - 匹配内层
</strong>→ 删除 - 匹配外层
</strong>→ 删除
输出结果:外层内层外层
我考虑过以下三种情况,但是呢,我实在是没有从网上上提取到这样的数据,所以为了保证代码的简洁性以及易读性,我就没有将这些东西功能给处理了。
- 不处理带属性的标签: 如
<strong class="highlight">不会被匹配 - 可能误伤: 如果文本中包含
<strong>字符串(非标签),也会被删除 - 不处理自闭合标签:
<strong />不会被匹配
处理斜线标签
这个代码同上也只是简单的删除,这里呢,就不对代码进行解释了。
const inputData = $input.all();
const outputData = inputData.map(item => {
let contentRendered = item.json.content.rendered;
// 精准匹配 <em> 开标签和 </em> 闭标签,移除标签保留内容,兼容嵌套/单独场景
const emRegex = /<em>|<\/em>/gi;
contentRendered = contentRendered.replace(emRegex, '');
return {
...item.json,
content: { ...item.json.content, rendered: contentRendered }
};
});
return outputData;处理内联标签
同上
const inputData = $input.all();
const outputData = inputData.map(item => {
let contentRendered = item.json.content.rendered;
// 精准匹配 开标签和 闭标签,移除标签保留内容,兼容单独/嵌套场景
const codeRegex = /|<\/code>/gi;
contentRendered = contentRendered.replace(codeRegex, '');
return {
…item.json,
content: { …item.json.content, rendered: contentRendered }
};
});
return outputData;
替换下标签
这个呢?你只需要稍微注意一下嗯这里就是替换了而不是单纯的删除。
const inputData = $input.all();
const outputData = inputData.map(item => {
let contentRendered = item.json.content.rendered;
// 精准匹配 <code> 开标签和 </code> 闭标签,移除标签保留内容
const codeRegex = /<code>|<\/code>/gi;
contentRendered = contentRendered.replace(codeRegex, '');
// 匹配 <sub>标签内容</sub> 并替换为 (下标:标签内容)
const subRegex = /<sub>(.*?)<\/sub>/gi;
contentRendered = contentRendered.replace(subRegex, '(下标:$1)');
return {
...item.json,
content: { ...item.json.content, rendered: contentRendered }
};
});
return outputData;
替换上标签
const inputData = $input.all();
const outputData = inputData.map(item => {
let contentRendered = item.json.content.rendered;
// 匹配 <sup>标签内容</sup> 并替换为 (上标:标签内容)
const supRegex = /<sup>(.*?)<\/sup>/gi;
contentRendered = contentRendered.replace(supRegex, '(上标:$1)');
return {
...item.json,
content: { ...item.json.content, rendered: contentRendered }
};
});
return outputData;替换标题标签
const inputData = $input.all();
const outputData = inputData.map(item => {
let contentRendered = item.json.content.rendered;
// 严格匹配标题标签,只处理 h2-h4 且包含 wp-block-heading 类的标题
const headingRegex = /<(h[2-6])[^>]*class\s*=\s*["']wp-block-heading["'][^>]*>(.*?)<\/\1>/gi;
contentRendered = contentRendered.replace(headingRegex, (match, tagName, content) => {
const level = tagName.charAt(1); // 提取数字部分
return `[${level}级标题:${content}]`;
});
return {
...item.json,
content: { ...item.json.content, rendered: contentRendered }
};
});
return outputData;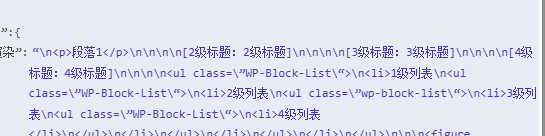
复杂正则表达式解析
const headingRegex = /<(h[2-4])[^>]*class\s*=\s*["']wp-block-heading["'][^>]*>(.*?)<\/\1>/gi;这是最复杂的正则表达式,我们来分层解析
- 开始标签匹配部分<(h[2-4])
<(: 匹配开始标签的尖括号,并开始第一个捕获组h[2-4]: 匹配h2、h3或h4标签): 结束第一个捕获组,捕获到的标签名可以在后面用\1引用
- 属性匹配部分
[^>]class\s=\s["']wp-block-heading["'][^>][^>]*: 匹配除>外的任意字符(其他属性)class\s*=\s*: 匹配class属性,允许等号前后有空格["']wp-block-heading["']: 匹配class值为wp-block-heading(支持单双引号)[^>]*: 继续匹配其他属性直到标签结束
- 内容捕获部分
(.*?)<\/\1>>: 开始标签结束(.*?): 第二个捕获组 – 非贪婪匹配标题内容<\/\1>: 使用反向引用匹配对应的结束标签
- 反向引用
\1的关键作用\1引用第一个捕获组(h[2-4])匹配到的内容- 如果开始标签匹配到
<h2>,那么\1就是h2 - 这样就确保了开始标签和结束标签的一致性
示例:
<!-- 匹配成功 -->
<h2 class="wp-block-heading">标题内容</h2>
<!-- 不会匹配(标签不匹配) -->
<h2 class="wp-block-heading">标题内容</h3> <!-- 开始h2,结束h3,不匹配 -->替换逻辑详细分析
替换函数结构
contentRendered.replace(headingRegex, (match, tagName, content) => {
const level = tagName.charAt(1); // 提取数字部分
return `[${level}级标题:${content}]`;
});回调函数参数:
match: 完整匹配的字符串(整个标题HTML)tagName: 第一个捕获组的内容(如"h2")content: 第二个捕获组的内容(标题文本)
标题等级提取逻辑
const level = tagName.charAt(1); // 提取数字部分提取过程:
tagName="h2"→charAt(1)="2"tagName="h3"→charAt(1)="3"tagName="h4"→charAt(1)="4"
输出格式:
return `[${level}级标题:${content}]`;替换文本标签
有什么好说的,只是替换文本,与一个的节点类似,但是更像是简化版
const inputData = $input.all();
const outputData = inputData.map(item => {
let contentRendered = item.json.content.rendered;
// 严格匹配 <p> 段落标签,确保只处理纯段落标签
const paragraphRegex = /<p\b[^>]*>(.*?)<\/p\s*>/gi;
contentRendered = contentRendered.replace(paragraphRegex, (match, content) => {
return `[段落:${content}]`;
});
return {
...item.json,
content: { ...item.json.content, rendered: contentRendered }
};
});
return outputData;
处理表格结构
这个码,就比较麻烦了,它不仅要进行替换,还要保证原有的层级结构不能变化。
const inputData = $input.all();
const outputData = inputData.map(item => {
let contentRendered = item.json.content.rendered;
// 精准匹配标准表格结构
const tableRegex = /<figure[^>]*class=["'].*WP-Block-Table.*["'][^>]*>[\s\S]*?<table[^>]*class=["']has-fixed-layout["'][^>]*>[\s\S]*?<thead><tr>([\s\S]*?)<\/tr><\/thead>[\s\S]*?<tbody>([\s\S]*?)<\/tbody>[\s\S]*?<\/table>[\s\S]*?<\/figure>/gi;
contentRendered = contentRendered.replace(tableRegex, (_, headerHtml, bodyHtml) => {
// 修复表头提取:修正正则表达式
const headerCells = [];
const thRegex = /<th[^>]*>([\s\S]*?)<\/th>/gi; // 修正:去掉多余的<
let thMatch;
while ((thMatch = thRegex.exec(headerHtml)) !== null) {
headerCells.push(thMatch[1].trim());
}
// 提取表格行
const tableRows = [];
const trRegex = /<tr>([\s\S]*?)<\/tr>/gi;
let trMatch;
while ((trMatch = trRegex.exec(bodyHtml)) !== null) {
const rowCells = [];
const tdRegex = /<td[^>]*>([\s\S]*?)<\/td>/gi;
let tdMatch;
while ((tdMatch = tdRegex.exec(trMatch[1])) !== null) {
rowCells.push(tdMatch[1].trim());
}
tableRows.push(rowCells);
}
// 生成 AI 易读的表格描述
return `[表格:列标题:${headerCells.join(', ')},内容行:\n${
tableRows.map(row => `- ${row.join(', ')}`).join('\n')
}\n]`;
});
return {
...item.json,
content: { ...item.json.content, rendered: contentRendered }
};
});
return outputData;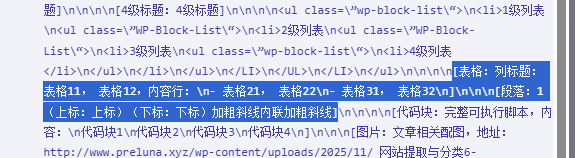
正则表达式分析
const tableRegex = /<figure[^>]*class=["'].*WP-Block-Table.*["'][^>]*>[\s\S]*?<table[^>]*class=["']has-fixed-layout["'][^>]*>[\s\S]*?<thead><tr>([\s\S]*?)<\/tr><\/thead>[\s\S]*?<tbody>([\s\S]*?)<\/tbody>[\s\S]*?<\/table>[\s\S]*?<\/figure>/gi;- 外层figure容器匹配
]class=["'].WP-Block-Table.["'][^>]><figure[^>]*: 匹配figure开始标签及其属性class=["'].*WP-Block-Table.*["']: 匹配包含WP-Block-Table的class- 这是WordPress Gutenberg表格块的典型外层结构
- 内层table结构匹配
[\s\S]*?<table[^>]*class=["']has-fixed-layout["'][^>]*>[\s\S]*?: 非贪婪匹配任意内容(跳过中间的HTML)<table[^>]*class=["']has-fixed-layout["'][^>]*>: 匹配具有特定class的table标签
- 表头捕获组
([\s\S]*?)<\/tr><\/thead>([\s\S]*?): 第一个捕获组 – 捕获thead中tr标签内的所有内容
- 表体捕获组
[\s\S]?([\s\S]?)<\/tbody>([\s\S]*?): 第二个捕获组 – 捕获tbody内的所有内容
替换函数结构
contentRendered.replace(tableRegex, (_, headerHtml, bodyHtml) => {
// 表头处理逻辑
// 表体处理逻辑
// 生成最终输出
});回调函数参数:
_: 完整匹配的字符串(整个表格HTML)headerHtml: 第一个捕获组的内容(表头tr内的HTML)bodyHtml: 第二个捕获组的内容(tbody内的HTML)
表头提取逻辑
const headerCells = [];
const thRegex = /<th[^>]*>([\s\S]*?)<\/th>/gi;
let thMatch;
while ((thMatch = thRegex.exec(headerHtml)) !== null) {
headerCells.push(thMatch[1].trim());
}表头提取过程:
- 使用
<th[^>]*>([\s\S]*?)<\/th>正则匹配所有th单元格 thMatch[1]获取捕获组内容(th标签内的文本)trim()去除前后空白- 存入
headerCells数组
表体提取逻辑
const tableRows = [];
const trRegex = /<tr>([\s\S]*?)<\/tr>/gi;
let trMatch;
while ((trMatch = trRegex.exec(bodyHtml)) !== null) {
const rowCells = [];
const tdRegex = /<td[^>]*>([\s\S]*?)<\/td>/gi;
let tdMatch;
while ((tdMatch = tdRegex.exec(trMatch[1])) !== null) {
rowCells.push(tdMatch[1].trim());
}
tableRows.push(rowCells);
}表体提取过程:
- 外层循环:匹配所有
<tr>...</tr>行 - 内层循环:对每行匹配所有
<td>...</td>单元格 - 逐级提取:tbody → tr → td
- 构建二维数组结构:
tableRows[row][cell]
最终输出生成
return `[表格:列标题:${headerCells.join(', ')},内容行:\n${
tableRows.map(row => `- ${row.join(', ')}`).join('\n')
}\n]`;处理列表
这个脚本是最复杂的,它包含了多层嵌套处理、状态管理、递归模拟、动态计数
const inputData = $input.all();
const outputData = inputData.map(item => {
let contentRendered = item.json.content.rendered;
// 彻底清理所有HTML标签,只保留纯文本内容
const stripHtml = (html) => {
return html.replace(/<[^>]+>/g, '').trim();
};
// 提取所有列表项文本和它们的缩进级别
const extractListItems = (html) => {
const items = [];
// 使用正则表达式匹配所有<li>标签及其内容
const liRegex = /<li>([\s\S]*?)<\/li>/gi;
let liMatch;
while ((liMatch = liRegex.exec(html)) !== null) {
const itemHtml = liMatch[1];
const text = stripHtml(itemHtml);
// 计算缩进级别 - 通过计算前面的<ul>标签数量
const beforeText = html.substring(0, liMatch.index);
const ulCount = (beforeText.match(/<ul class="wp-block-list">/g) || []).length;
const closeUlCount = (beforeText.match(/<\/ul>/g) || []).length;
const indentLevel = ulCount - closeUlCount;
items.push({
text: text,
level: indentLevel
});
}
return items;
};
// 根据缩进级别重建层级编号
const rebuildNumbering = (items) => {
let result = '';
let counters = []; // 用于跟踪每一级的计数器
items.forEach((item) => {
const level = item.level;
// 确保counters数组足够长
while (counters.length <= level) {
counters.push(0);
}
// 重置更低级别的计数器
for (let i = level + 1; i < counters.length; i++) {
counters[i] = 0;
}
// 增加当前级别的计数器
counters[level]++;
// 构建编号 - 只取到当前级别
const numbers = [];
for (let i = 0; i <= level; i++) {
numbers.push(counters[i]);
}
const numberPrefix = numbers.join('.');
result += `${numberPrefix} ${item.text}\n`;
});
return result;
};
// 处理列表的独立函数
const processList = (listHtml, listIndex) => {
// 提取这个列表中的所有项目
const listItems = extractListItems(listHtml);
// 重建层级编号
const listContent = rebuildNumbering(listItems);
return `[列表${listIndex}:${listContent}]`;
};
// 只处理列表标签,其他内容保持不变
const processOnlyLists = (html) => {
let result = html;
let listCount = 0;
// 使用更精确的方法来匹配顶级列表
const topLevelLists = [];
let startIndex = 0;
while (startIndex < html.length) {
// 查找下一个顶级列表的开始
const listStart = html.indexOf('<ul class="wp-block-list">', startIndex);
if (listStart === -1) break;
// 查找匹配的结束标签
let depth = 1;
let currentIndex = listStart + 25; // 25是'<ul class="wp-block-list">'的长度
let listEnd = -1;
while (currentIndex < html.length && depth > 0) {
const nextUlOpen = html.indexOf('<ul class="wp-block-list">', currentIndex);
const nextUlClose = html.indexOf('</ul>', currentIndex);
// 确定下一个遇到的标签是开始还是结束
if (nextUlOpen !== -1 && (nextUlOpen < nextUlClose || nextUlClose === -1)) {
// 遇到开始标签
depth++;
currentIndex = nextUlOpen + 25;
} else if (nextUlClose !== -1) {
// 遇到结束标签
depth--;
currentIndex = nextUlClose + 5;
// 如果深度为0,说明找到了顶级列表的结束
if (depth === 0) {
listEnd = currentIndex;
break;
}
} else {
// 没有更多标签
break;
}
}
if (listEnd !== -1) {
// 提取列表HTML
const listHtml = html.substring(listStart, listEnd);
topLevelLists.push({
start: listStart,
end: listEnd,
html: listHtml
});
startIndex = listEnd;
} else {
// 如果没有找到匹配的结束标签,跳过这个开始标签
startIndex = listStart + 25;
}
}
// 从前往后替换,确保顺序正确
let offset = 0;
topLevelLists.forEach((list, index) => {
listCount++;
const processedList = processList(list.html, listCount);
// 计算调整后的位置
const adjustedStart = list.start + offset;
const adjustedEnd = list.end + offset;
// 替换列表部分
result = result.substring(0, adjustedStart) + processedList + result.substring(adjustedEnd);
// 更新偏移量
offset += processedList.length - (list.end - list.start);
});
return result;
};
// 执行处理 - 只处理列表,其他内容保持不变
const finalContent = processOnlyLists(contentRendered);
return {
...item.json,
content: {
...item.json.content,
rendered: finalContent
}
};
});
return outputData;整体架构设计思想
1. 模块化分层架构
主处理流程
├── stripHtml() - HTML标签清理层
├── extractListItems() - 列表项提取层
├── rebuildNumbering() - 编号重建层
└── processOnlyLists() - 列表处理协调层
└── processList() - 单个列表处理2. 核心处理理念
- 选择性处理: 只处理列表,保持其他内容不变
- 结构保持: 将视觉缩进转换为逻辑编号
- 状态追踪: 动态维护层级计数器
逐层深度解析
第一层:HTML标签清理
const stripHtml = (html) => {
return html.replace(/<[^>]+>/g, '').trim();
};正则解析:
/<[^>]+>/g: 匹配所有HTML标签[^>]+: 匹配除>外的任意字符一次或多次- 效果:
<li>项目</li>→项目
设计思想: 提供纯净的文本提取基础功能
第二层:列表项提取与层级分析
const extractListItems = (html) => {
const items = [];
const liRegex = /<li>([\s\S]*?)<\/li>/gi;
let liMatch;
while ((liMatch = liRegex.exec(html)) !== null) {
const itemHtml = liMatch[1];
const text = stripHtml(itemHtml);
// 层级计算核心算法
const beforeText = html.substring(0, liMatch.index);
const ulCount = (beforeText.match(/<ul class="wp-block-list">/g) || []).length;
const closeUlCount = (beforeText.match(/<\/ul>/g) || []).length;
const indentLevel = ulCount - closeUlCount;
items.push({ text: text, level: indentLevel });
}
return items;
};层级计算算法详解
核心公式: indentLevel = ulCount - closeUlCount
计算原理:
ulCount: 当前li标签之前的所有<ul>开始标签数量closeUlCount: 当前li标签之前的所有</ul>结束标签数量- 差值: 表示当前嵌套深度
示例分析(我之前那个测试结构生成的太过于复杂了)
<ul> <!-- ulCount=1, closeUlCount=0, level=1 -->
<li>项目1</li> <!-- level = 1-0 = 1 -->
<ul> <!-- ulCount=2, closeUlCount=0, level=2 -->
<li>子项目1</li> <!-- level = 2-0 = 2 -->
</ul> <!-- ulCount=2, closeUlCount=1, level=1 -->
<li>项目2</li> <!-- level = 2-1 = 1 -->
</ul>使用标签计数差值而非复杂的嵌套分析
第三层:编号重建算法
const rebuildNumbering = (items) => {
let result = '';
let counters = []; // 多级计数器状态管理
items.forEach((item) => {
const level = item.level;
// 动态扩展计数器数组
while (counters.length <= level) {
counters.push(0);
}
// 重置下级计数器 - 关键状态管理
for (let i = level + 1; i < counters.length; i++) {
counters[i] = 0;
}
// 递增当前级计数器
counters[level]++;
// 构建编号路径
const numbers = [];
for (let i = 0; i <= level; i++) {
numbers.push(counters[i]);
}
const numberPrefix = numbers.join('.');
result += `${numberPrefix} ${item.text}\n`;
});
return result;
};状态机设计思想
状态机设计思想
counters[0]: 一级标题计数器counters[1]: 二级标题计数器counters[2]: 三级标题计数器
状态转移规则:
- 进入新层级: 扩展计数器数组
- 重置下级: 清除所有更深层级的计数器
- 递增当前级: 当前层级计数器+1
- 构建路径: 从根到当前层级的完整编号
处理示例:
原始结构:
- 项目1
- 子项目1
- 子项目2
- 项目2
状态变化:
项目1: counters=[1] → 1 项目1
子项目1: counters=[1,1] → 1.1 子项目1
子项目2: counters=[1,2] → 1.2 子项目2
项目2: counters=[2,0] → 2 项目2第四层:列表边界检测与处理
const processOnlyLists = (html) => {
let result = html;
let listCount = 0;
const topLevelLists = [];
// 深度优先的列表边界检测
let startIndex = 0;
while (startIndex < html.length) {
const listStart = html.indexOf('<ul class="wp-block-list">', startIndex);
if (listStart === -1) break;
// 嵌套深度追踪算法
let depth = 1;
let currentIndex = listStart + 25;
let listEnd = -1;
while (currentIndex < html.length && depth > 0) {
const nextUlOpen = html.indexOf('<ul class="wp-block-list">', currentIndex);
const nextUlClose = html.indexOf('</ul>', currentIndex);
// 优先处理开始标签还是结束标签?
if (nextUlOpen !== -1 && (nextUlOpen < nextUlClose || nextUlClose === -1)) {
depth++;
currentIndex = nextUlOpen + 25;
} else if (nextUlClose !== -1) {
depth--;
currentIndex = nextUlClose + 5;
if (depth === 0) {
listEnd = currentIndex;
break;
}
} else {
break;
}
}
if (listEnd !== -1) {
topLevelLists.push({
start: listStart,
end: listEnd,
html: html.substring(listStart, listEnd)
});
startIndex = listEnd;
} else {
startIndex = listStart + 25;
}
}
// 偏移量管理的替换策略
let offset = 0;
topLevelLists.forEach((list, index) => {
listCount++;
const processedList = processList(list.html, listCount);
const adjustedStart = list.start + offset;
const adjustedEnd = list.end + offset;
result = result.substring(0, adjustedStart) + processedList + result.substring(adjustedEnd);
offset += processedList.length - (list.end - list.start);
});
return result;
};嵌套深度追踪算法
算法原理: 模拟栈的深度优先遍历
- 遇到
<ul>:depth++(入栈) - 遇到
</ul>:depth--(出栈) depth === 0: 找到匹配的结束位置
处理复杂嵌套:
<ul> <!-- depth=1 -->
<li>1</li>
<ul> <!-- depth=2 -->
<li>1.1</li>
</ul> <!-- depth=1 -->
<li>2</li>
</ul> <!-- depth=0 → 匹配结束 -->偏移量管理策略
问题: 替换后字符串长度变化,后续索引失效
解决方案: 动态维护偏移量
offset += processedList.length - (list.end - list.start);计算原理:
- 原长度:
list.end - list.start - 新长度:
processedList.length - 长度差: 需要调整的偏移量
第五层:处理协调与集成
const processList = (listHtml, listIndex) => {
const listItems = extractListItems(listHtml);
const listContent = rebuildNumbering(listItems);
return `[列表${listIndex}:${listContent}]`;
};设计模式: Facade模式
- 封装复杂的内部处理
- 提供简洁的外部接口
- 协调各子模块协作
本脚本所考虑的的技术:
// 1. 状态机设计
let counters = []; // 多级计数器状态
// 2. 递归模拟
while (depth > 0) { ... } // 模拟递归栈
// 3. 动态偏移管理
let offset = 0; // 处理字符串长度变化
// 4. 复杂边界检测
// 嵌套标签的精确匹配算法处理换行符
这个可比那个处理列表简单多了
const inputData = $input.all();
const outputData = inputData.map(item => {
let contentRendered = item.json.content.rendered;
// 优化换行符的函数
const optimizeNewlines = (text) => {
// 将3个或更多连续换行符替换为2个
text = text.replace(/\n{3,}/g, '\n\n');
// 确保结构块之间有明确分隔(如果存在结构标记)
text = text.replace(/(【[^】]+】)\n+/g, '$1\n\n');
return text;
};
// 只进行换行符优化,不处理列表
contentRendered = optimizeNewlines(contentRendered);
return {
...item.json,
content: {
...item.json.content,
rendered: contentRendered
}
};
});
return outputData;
为什么这么设计?
这里呢?由于我所有的节点处理都是通过非贪婪进行匹配的,而且我在匹配的时候是要求较高的精度,所以我们在我们在列表之前的所有所有节点的希望顺序都可以任意替换,因为我们保证在进行格式结构转换的时候尽量不破坏其他的结构,所以可以进行替换,而我们在对列表的进行处理的时候,也是尽量保证不进行替换,但是呢,这个列表太过于特殊了,他这匹配要求太过于严苛了,理论上也可以进行前后顺序打乱,但是呢,我们还是尽量的把它放到最后一块进行处理。
WordPress内容处理流程设计总结
整体流程架构设计
1. n8n函数节点的标准范式
const inputData = $input.all();
const outputData = inputData.map(item => {
let contentRendered = item.json.content.rendered;
// 处理逻辑...
return {
...item.json,
content: {
...item.json.content,
rendered: contentRendered
}
};
});
return outputData;为什么采用这个范式:
$input.all(): n8n平台强制要求的数据获取方式.map(item => {}): 处理多个数据项的标准化模式item.json.content.rendered: WordPress内容的标准化路径- 扩展运算符
...: 保持数据结构完整性的最佳实践
2. 渐进式处理策略
我们采用了分阶段、渐进式的处理方法:
原始HTML
↓
图片处理 → 代码块处理 → 格式标签清理 → 标题处理 → 表格处理 → 列表处理 → 换行优化
↓
结构化文本输出各阶段处理成果
阶段1:复杂结构提取
- 图片:
复杂HTML→[图片:地址:URL] - 代码块:
<pre><code>...</code></pre>→[代码块:内容:...] - 表格:
复杂table结构→[表格:列标题:...,内容行:...]
阶段2:内联格式简化
- 加粗:
<strong>文本</strong>→文本 - 下标:
<sub>H2O</sub>→(下标:H2O) - 内联代码:
<code>console.log</code>→console.log
阶段3:层级结构标记化
- 标题:
<h2 class="...">标题</h2>→[2级标题:标题] - 列表:
嵌套ul/li结构→[列表1:1 项目\n 1.1 子项目]
阶段4:格式优化
- 换行清理: 确保结构清晰、内容紧凑
最终数据结构分析
对于我们测试数据的最终结果,Ai分析应该是这样子的
文档结构
├── 段落块 [段落:段落1]
├── 标题层级
│ ├── [2级标题:2级标题]
│ ├── [3级标题:3级标题]
│ └── [4级标题:4级标题]
├── 列表结构
│ ├── 列表1 (简单层级)
│ └── 列表2 (复杂嵌套层级)
├── 表格数据 [表格:列标题...]
├── 代码内容 [代码块:...]
└── 媒体资源 [图片:...]1. 文档大纲结构
// AI可以提取的文档大纲
const documentOutline = {
title: "未知", // 需要从其他字段获取
sections: [
{ type: "paragraph", content: "段落1" },
{ type: "heading", level: 2, content: "2级标题" },
{ type: "heading", level: 3, content: "3级标题" },
{ type: "heading", level: 4, content: "4级标题" },
// ...
]
}2. 数据提取能力
// AI可以提取的各类数据
const extractedData = {
images: [
"http://www.preluna.xyz/wp-content/uploads/2025/11/网站提取与分类6-1.png",
"http://www.preluna.xyz/wp-content/uploads/2025/11/文章数据的初步格式转化4-1.png",
"http://www.preluna.xyz/wp-content/uploads/2025/11/文章数据的初步格式转化2-736x1024.png"
],
codeBlocks: [
"代码块1\n代码块2\n代码块3\n代码块4"
],
tables: [
{
headers: ["表格11", "表格12"],
rows: [
["表格21", "表格21", "表格22"],
["表格31", "表格32"]
]
}
],
lists: [
{
items: [
{ number: "0.1", text: "1级列表", children: [...] }
// 完整的层级结构
]
}
]
}3. 语义理解支持
// AI可以进行的语义分析
const semanticAnalysis = {
contentTypes: {
technical: ["代码块", "列表2的复杂结构"],
explanatory: ["段落", "简单列表"],
structural: ["标题层级"],
illustrative: ["图片", "表格"]
},
complexity: {
simple: ["段落1", "2级标题"],
moderate: ["列表1", "表格"],
complex: ["列表2的嵌套结构", "代码块"]
}
}结论
我们成功的将复杂的WordPress HTML内容转换为了AI友好的结构化文本格式。通过标准化的标记系统和清晰的内容分层,AI能够准确识别文档的各个组成部分,理解内容之间的逻辑关系,并为后续的智能分析、内容重组、自动化处理等任务提供了理想的数据基础。最终的输出数据不仅保留了原始内容的完整信息,更重要的是以机器可理解的方式重新组织了这些信息,这正是我们整个处理流程设计的核心价值所在。
附:子工作流程
随着我们创建的节点越来越多,这些流程也不免复杂起来,目前我们还创建了很多个对于测试节点,为了后续方便debug就不进行删除了,当然同样,我们有些节点本来也是可以合并的,但是呢,为了方便以后而增加更多的功能,或者进行修改。我们也没有进行合并,最后导致节点以后占据了整个屏幕,为了让这些节点都给表示出来,然后又会进行缩小,他的那个幕布移动机制是真的很难评价,很容易啊,就点到删除之类的东西,我也不知道为什么他删除节点要跟那些其他功能都摆在一起
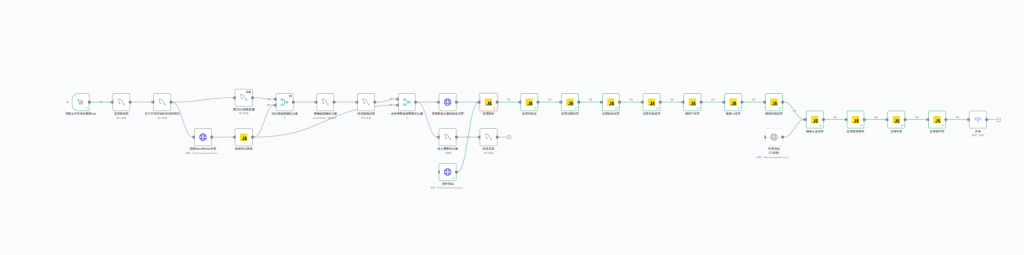
所以这个时候我们就必须得考虑一个操作—–打包,当然在n8n中把它给命名为:创建子工作流程
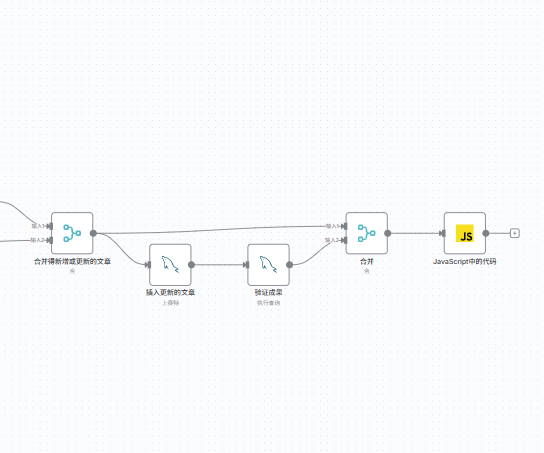
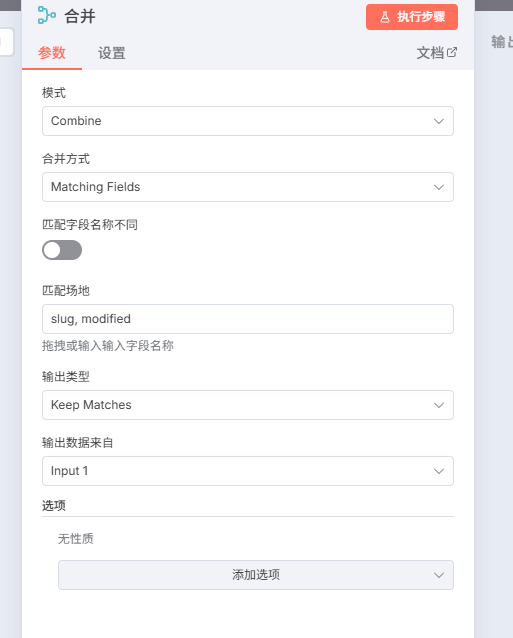
首先呢,我们根据功能拆分出两个大致的流程,一个是创建数据库,对网站进行查询,新增了哪些文章?哪些文章进行了更新?哪些文章进行了删除?我们通过一个数据库,再利用merge节点的合并特性然后就可以得出需要变更的内容,然后在合并得新增文章节点之后再引出一条工作链,通过HTTP请求获取文章的具体内容,另外一个就是本篇文章的主要内容:对提取文章内容进行初步处理。
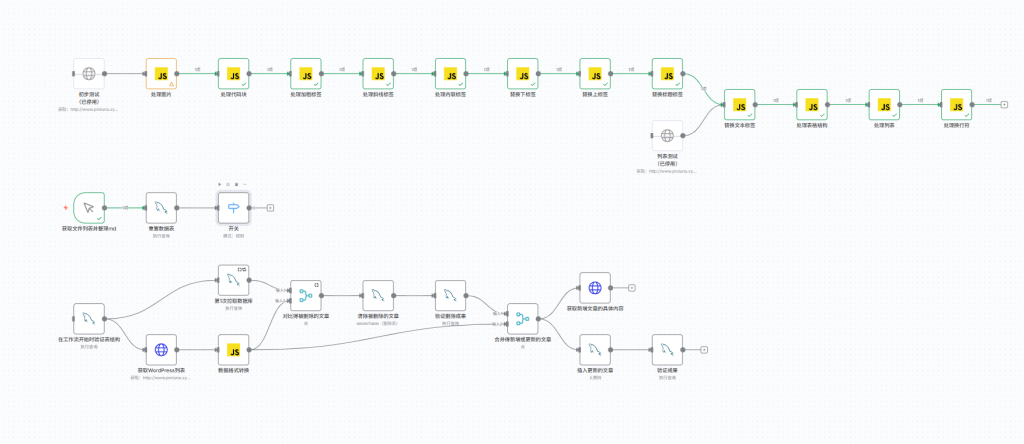
我们只要先框选出我们要将其转换成子工作流程的节点,然后ctrl+x就可以将指定节点转化成子工作流程
当然各位在完成打包子工作流程之后,也不要忘了一件事情,就是N 8n中默认将最后一个节点输出作为他们传递的参数。还记得我们当初的目的是什么吗?对于新增或更新的文章进行提取文件并进行初步格式转换,所以我们后续还要进行这么一个设计。将合并得新增或更新的文章节点与验证成果的节点通过merge节点进行只输出,当然我们选择新增或更新的文章作为输入1,将验证成果作为输入2
然后再在后面补充一个code节点
// 读取左边 Merge 节点的输入数据
const inputData = $input.all();
// 直接返回这些数据,完成“复制粘贴”
return inputData;最后所有节点处理完之后,并且连完线应该是这个样子。